高可用架构-限流如何实现
What is 限流?
限流顾名思义,限制流量或者说叫流量管制。
很形象的比喻如老式电闸都安装了保险丝,一旦有人使用超大功率的设备,保险丝就会烧断以保护各个电器不被强电流给烧坏。
Why use 限流?
理论上一个完整的对外提供服务的系统架构在设计初期,就要基于上游流量,流速,高峰期时间点,峰值 qps,还有自身系统的负载能力,评估系统的吞吐量,并且进行入口流量的管制。
当超出限流阈值时,系统可以采取拒绝服务,排队或者引流等机制, 保证自身一直在健康的负载下。
如果系统没有限流策略,对于突发性的超自身负载的流量,系统只能被动的无奈接受,系统内各个子服务逐渐解体,最后服务整体雪崩。

小概念 Review
QPS
Queries Per Second (每秒查询率),每秒查询率 QPS 是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
RPS
Requests Per Second (每秒发送请求数 /吞吐率),指客户端每秒发出的请求数。阿里云 PTS 对于这个词的解释为 RPS 有些地方也叫做 QPS,在不单独讨论“事务”的情况下可以近似对应到 Loadrunner/jmeter 的 TPS ( Transaction Per Second, 每秒事务数)。
TPS
Transactions Per Second (每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS 一般包括一条消息入和一条消息出,加上一次用户数据库访问。(业务 TPS = CAPS × 每个呼叫平均 TPS )
限流粒度
- 集群限流
- 单机限流
集群限流
集群限流方式可以归纳为两种
- 网关层
- 应用层
网关层
网关层常见设计,基于 nginx lua module 实现整体管控。下面是简单 lua demo 。
local locks = require "resty.lock"
local function limiter()
-- ngx dict
local limiter = ngx.shared.limiter
-- limiter lock
local lock = locks:new("limiter_lock")
local key = gx.var.host..ngx.var.uri
-- add lock
local elapsed, err =lock:lock("ngx_limiter:"..key)
if not elapsed then
return fail("failed to acquire the lock: ", err)
end
-- limit max value
local limit = 5
-- current value
local current =limiter:get(key)
-- 限流
if current ~= nil and current + 1> limit then
lock:unlock()
return 0
end
if current == nil then
limiter:set(key, 1, 1) -- 初始化
else
limiter:incr(key, 1) -- +1
end
lock:unlock()
return 1
end
ngx.print(limiter())
了解 lua-resty-lock: https://github.com/openresty/lua-resty-lock
Nginx.conf
http {
……
lua_shared_dict limiter_lock 10m;
lua_shared_dict limiter 10m;
}
应用层
应用层常见通过业务代码实现,基于 Redis 计数, 通过 lua script 保证 redis 执行原子性.
local key = "limiter:" .. KEYS[1]
local limit = tonumber(ARGV[1])
local expire_time = tonumber(ARGV[2])
local is_exists = redis.call("EXISTS", key)
if is_exists == 1 then
if redis.call("INCR", key) > limit then
return 0
else
return 1
end
else
redis.call("SET", key, 1)
redis.call("EXPIRE", key, expire_time)
return 1
end
单机限流
单兵作战,自生自灭,我不倒集群不倒。不依赖存储中间件,基于 local cache 就可以实现简单的本地计数限流,宏观角度观察,只要网关层负载均衡服务高可用,每个节点流量差别不大,只需要关心单个节点的流量管控就可以。
以上是限流粒度分类,下面说说具体的限流算法模型。
限流模型
以上 Demo 都是基于简单的固定时间窗口模型实现限流,但是当出现临界点瞬间大流量冲击,。
常用的模型分类有两种:
- 时间模型
- 桶模型
时间模型
时间模型分两种:
- 固定窗口模型
- 滑动窗口模型
固定时间模型

上面聊到的各粒度限流模式的 code demo 都是这种方式。
如图(图片来源网络),拉长 timeline,以 QPS 为例,限流 1000QPS,我们会讲 timeline 按照固定间隔分窗口,每个窗口有一个独立计数器,每个计数器统计窗口内的 qps,如果达到阈值则拒绝服务,这是一种最简单的限流模型,但是缺点比较明显,当在临界点出现大流量冲击,就无法满足流量控制。

如图(图片来源网络),在 900ms 和 1100ms 都出现 1000QPS 并发,虽然单个窗口内是符合限流要求,但是实际上临界点处的 QPS 已经打到 2000,服务过载。
滑动时间模型
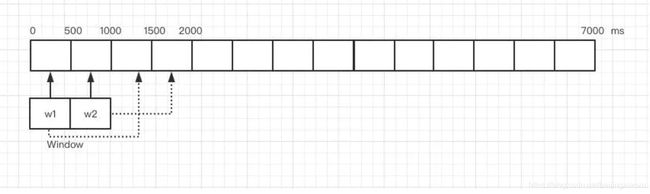
如图(图片来源网络),为了规避临界点大流量冲击,滑动时间模型会将每个窗口切分成 N 个子窗口,每个子窗口独立计数。这样用w1+w2计数之和来做限流阈值校验,就可以解决此问题。
桶模型
桶模型也分两种:
- 令牌桶
- 漏桶
令牌桶模型
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。不过令牌桶还是允许一定程度的突发传输,这样解决了在实际上的互联网应用中,流量经常是突发性的问题。
Ref: https://en.wikipedia.org/wiki/Token_bucket
如下图(图片来源网络):
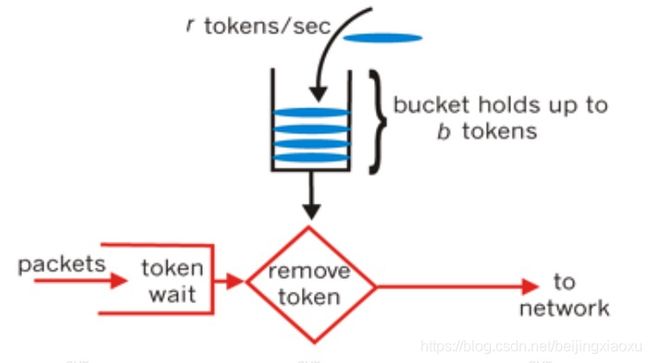
算法实现方式有两种:
- Ticker
定义一个 Ticker,持续生成令牌并导入桶中。这样问题是会极大的消耗系统资源。如果基于某一维度进行限流,会创建多桶,对应多 Ticker,资源消耗很可怕。 - Inert Fill
惰性填充,定义一个 inert fill 函数。该函数会在每次获取令牌之前调用,其实现思路为,若当前时间晚于 lastAccessTime,则计算该段时间内可以生成多少令牌,将生成的令牌加入令牌桶中并更新数据。这样一来,只需要在获取令牌时计算一次即可。
桶内令牌数计数方式
桶内令牌数 = 剩余的令牌数 + (本次取令牌的时刻-上一次取令牌的时刻)/放置令牌的时间间隔 * 每次放置的令牌数
常用令牌桶如: github.com/juju/ratelimit 2K Star
多种填充令牌方式:
func NewBucket(fillInterval time.Duration, capacity int64) *Bucket
默认令牌桶,fillInterval 每过多⻓时间向桶⾥放⼀个令牌,capacity 是桶的容量,超过桶容量的部分会被直接丢弃。
func NewBucketWithQuantum(fillInterval time.Duration, capacity, quantum int64) *Bucket
和默认方式一样,唯一不同是每次填充的令牌数是 quantum,而不是 1 个。
func NewBucketWithRate(rate float64, capacity int64) *Bucket
按照使用方定义的⽐例,每秒钟填充令牌数。比如 capacity 是 100,⽽ rate 是 0.1,那么每秒会填充 10 个令牌。
多种领取令牌方式:
func (tb *Bucket) Take(count int64) time.Duration {
}
func (tb *Bucket) TakeAvailable(count int64) int64 {
}
func (tb *Bucket) TakeMaxDuration(count int64, maxWait time.Duration) (
time.Duration, bool,
) {
}
func (tb *Bucket) Wait(count int64) {
}
func (tb *Bucket) WaitMaxDuration(count int64, maxWait time.Duration) bool {
}
如下,我简单实现了一个极简的令牌桶, 速率默认为 QPS 。
TokenBucket Demo
Struct 结构
// object
type TbConfig struct {
QPS int64 // 限制 qps e.g 200
MaxCap int64 // 桶最大容量 e.g:1000
}
type TokenBucket struct {
*TbConfig
m sync.Mutex // 读写锁
available int64 // 可用令牌
lastTime time.Time // 最后一次获取令牌时间
}
Inert Fill
func (tb *TokenBucket) fill() error {
n := time.Now()
timeUnit := n.Sub(tb.latestTime).Seconds()
fillCnt := int64(timeUnit) * tb.QPS // 见文下描述
if fillCnt <= 0 {
return nil
}
tb.available += fillCnt
// 防止过大溢出
if tb.MaxCap > 0 && tb.available > tb.MaxCap {
tb.available = tb.MaxCap
}
tb.latestTime = n
return nil
}
桶内令牌数 = 剩余的令牌数**
tb.available** + (本次取令牌的时刻**n** - 上一次取令牌的时刻**tb.latestTime) / 放置令牌的时间间隔速率为 qps,所以此处是1** * 每次放置的令牌数**tb.QPS**
漏桶模型
漏桶算法思路很简单,如下图(图片来源网络),水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
简单的说: 调用方只能严格按照预定的间隔顺序进行消费调用。
Ref: https://en.wikipedia.org/wiki/Leaky_bucket

常用漏桶: https://github.com/uber-go/ratelimit 2.4k Star
对于很多应用场景来说,除了要求能够限制流量的平均传输速率外,还要求允许某种程度的突发传输。
传统的 Leaky Bucket,关键点在于漏桶始终按照固定的速率运行,但是它并不能很好的处理有大量突发请求的场景。
对于这种情况,uber-go 对 Leaky Bucket 做了一些改良,引入了最大松弛量 (maxSlack) 的概念。
当请求间隔时间小于固定的速率时,可以把间隔比较长的请求多余出来的时间 buffer,匀给后面的使用,保证每秒请求数。如果间隔时间远远超出固定速率,那会给后续请求增加超大的 buffer,以至于即使后面大量请求瞬时到达,也无法抵消完这个时间,那这样就失去了限流的意义。所以 maxSlack 会限制这个 buffer 上限。
LeakyBucket Demo
如下,实现了一个极简的非阻塞漏桶。
Struct 结构
// object
type LbConfig struct {
Rate float64 // 速率 e.g 200: 每秒 200 次请求
MaxSlack int64 // 最大松弛量,可以理解 buffer 时间内最大放行的 qps 。默认为 0 表示不开启松弛量 e.g 10: 如果松弛量大于 10,则松弛量强制为 10
}
type LeakyBucket struct {
*LbConfig
m sync.Mutex // 读写锁
perRequest time.Duration // 速率
bufferTime time.Duration // 多余时间
slackTime time.Duration // 最大松弛时间
lastTime time.Time // 最后一次获取令牌时间
}
无松弛量实现
即严格按照预定时间间隔获取令牌。
func (lb *LeakyBucket) withoutSlack() error {
n := time.Now()
lb.bufferTime = lb.perRequest - n.Sub(lb.lastTime)
// 多余时间如果为正数: 证明前后时间间隔超过预期速率,需要拒绝服务
if lb.bufferTime > 0 {
return ErrNoTEnoughToken
} else {
lb.lastTime = n
}
return nil
}
有松弛量实现
即多余时间匀给后面获取令牌使用。
func (lb *LeakyBucket) withSlack() error{
n := time.Now()
// 此处为+= 表示要累计多余时间
lb.bufferTime += lb.perRequest - n.Sub(lb.lastTime)
// 多余时间如果为正数: 证明前后时间间隔超过预期速率,需要拒绝服务
if lb.bufferTime > 0 {
return ErrNoTEnoughToken
} else {
lb.lastTime = n
}
// 允许抵消的最长时间
if lb.bufferTime < lb.slackTime {
lb.bufferTime = lb.slackTime
}
return nil
}
Demo 源码
源码可见 github.com/xiaoxuz/limiter
相关文章
https://www.cyhone.com/articles/analysis-of-uber-go-ratelimit/
https://en.wikipedia.org/wiki/Token_bucket
https://en.wikipedia.org/wiki/Leaky_bucket
收工
打完收工,感谢支持
CSDN不定期更新,公众号持续更新,欢迎关注。