论文笔记:Accurate Causal Inference on Discrete Data
小白准备讨论班而看的论文,《Causality for Machine Learning》太长了有空再看着玩吧。
惯例先上文献:K. Budhathoki and J. Vreeken, "Accurate Causal Inference on Discrete Data," 2018 IEEE International Conference on Data Mining (ICDM), 2018, pp. 881-886, doi: 10.1109/ICDM.2018.00105.
摘要:
这篇文章主要是对ANM(加性噪声模型)的优化。
ANM模型可以在只知道少量样本的前提下找到随机变量的因果方向。ANM的关键假设是 变量之间的影响可以表示成因的函数 和 噪声是和因无关的,很多情况下ANM表现较好,但是他们的表现与1. 选用的(用于判断无关的)测度 和 2.我们对于真实的分布的假设 有关。这篇论文中运用香农熵

量化ANM中的无关性,这样可以有一个不需要假设真实分布的方法,也不需要在优化期间执行明确的显著性检验。
显著性检验(significance test)就是事先对总体(随机变量)的参数或总体分布形式做出一个假设,然后利用样本信息来判断这个假设(备择假设)是否合理,即判断总体的真实情况与原假设是否有显著性差异。或者说,显著性检验要判断样本与我们对总体所做的假设之间的差异是纯属机会变异,还是由我们所做的假设与总体真实情况之间不一致所引起的。 显著性检验是针对我们对总体所做的假设做检验,其原理就是“小概率事件实际不可能性原理”来接受或否定假设。
信息论公式为我们提供了一种通用、高效、可识别且如实验所示的高度准确的方法,用于对离散变量对进行因果推断——在合成数据和真实数据上均实现(接近)100% 的准确度。
Introduction
我们能知道X,Y相关,但是我们无法确定具体是X→Y还是Y→X,这篇论文就是干介个的。
之前在因果方面有一些模型。比如Structural Causal Model[2]
Structural model:[2]
Causal Structural Model:[2]


和Additive Noise Model(ANM)。ANM模型:假设结果是原因的函数,附加噪声与原因无关。 如果存在函数 f 和一个独立于 X 的随机噪声变量 N_Y,即 N_Y ⊥⊥ X,则称具有联合分布 P(X, Y) 的两个随机变量 X 和 Y 满足从 X 到 Y 的 ANM ,使得 Y = f(X) + N_Y ,如果 P(X, Y) 允许从 X 到 Y 的 ANM,但不能在相反的方向上,则该模型是可识别的,在这种情况下,我们认为在ANM下X可能是Y的因。简单来说就是在研究变量之间的关系的时候在因变量上加一个噪声,使其更加符合现实情况(系统本身和观测产生的误差)。ANM模型具体可以看参考文献[3][4][5],知乎上查到关于ANM的简短理解:(侵删)
通常我们对于一个真实的系统和状态建模都会用一个确定性的部分加上一个随机性的部分,这也符合我们的直觉的,因为对于一个系统来说,系统本身和观测都是带有误差的。那么对于这样一个问题,最简单的数学建模是什么呢?
答案就是加性噪声模型:y=x+\epsilon.这里 \epsilon ~ N(\miu,\sigma^2) , 而x,y分别是真实的状态和与我们能观测到的状态。
通常我们并不能知道噪声满足什么样的一个分布,但是事实证明,往往用高斯分布建模会得到很好的效果。
一个比较直接的应用就是在图像处理领域,如果我们把y,x 分别看成是被污染后的图像和原始的图像,那么图像去噪或者说图像复原问题,本质上就是对于加性模型求解反问题。
作者:Caliber
链接:https://www.zhihu.com/question/408126141/answer/1388641389
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ANM脱胎于LiNGAM[3],关于讲LiNGAM的参考文献[3],看到28页傻眼了,好在知乎专栏有一位老哥写的很好[1.6]。关于ANM,CSDN上有一个老哥一句一句翻译的讲解[1.7]参考文献[4][5]后面再补吧。
参考文献[5]中证明了对于离散的数据,ANM一般地是可识别的。
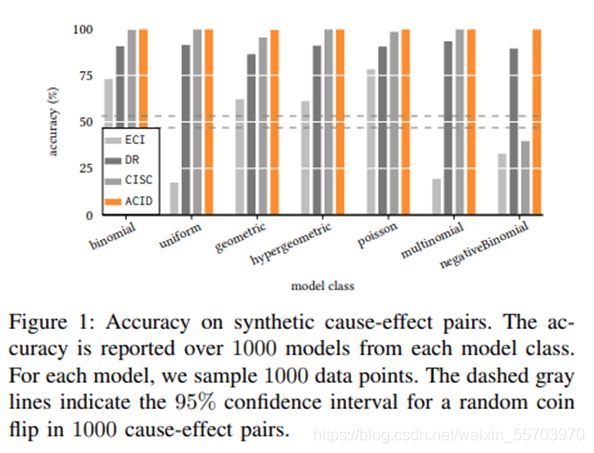
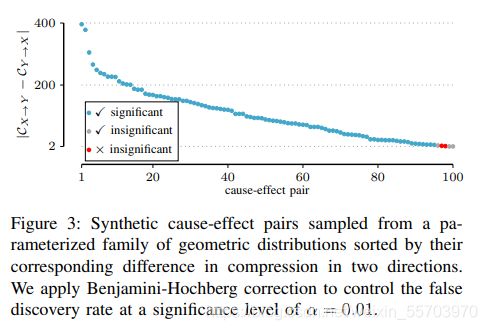
在本论文中提出了ACID,一个基于信息论的、针对离散数据的、因果推论的可识别方法;具体来说是运用香农熵计算X N_Y之间的相关性。我们认为X导致Y如果H(X)+H(Y) 有点卡顿 ,明天再看吧,感觉还是要补知乎专栏、[4]、[5]这三个,先放放等这周讲完讨论班回来看。6/15/23:25 设 X 和 Y 是两个离散的随机变量。多元数据的传统统计分析涉及从联合分布中观察到的样本进行推断。然而,因果推理需要对感兴趣的变量进行操作(干预、政策、处理等)。要推断 X 是否导致 Y ,我们必须比较在 X 的不同操作下 Y 的分布。特别是,如果 P(Y | 操作 X 到 x1) != P(Y | 操作 X 到 x),则 X 会导致 Y。 为了搞明白Thm3.2.5也算是费了一番功夫,先看看Thm本身: 有一个由马尔可夫模型生成的因果图(有向网络图,点表示事件,线从因指向果)G,在G中的变量子集V是可测的,则P(y|do(x))是可识别的,当X,Y和所有X的直接因(direct cause或parents)都是可测的。 再看看可识别的: 3.2.3是模型Q的可识别的概念,我们更需要的是3.2.4提到的: 顺便我们再了解下parent的概念,先看Thm中提到的式(3.13): parent在Pearl的这本书里面是个很常见的概念, 大概讲讲1.4里面关于counterfactual的一个例子,可以方便理解。 如果我们想研究一个关于给药(x)和治愈率(y)的关系,我们只知道对于任何x和y的组合, p(x,y)=0.25,定义测度Q表示“接受治疗但是死掉的人没接受治疗活下来的概率”。 模型一: u_1 u_2是无关的,且都是1/2的概率,也就是说死活和是否治疗无关。此时Q=0。 模型二: 这样条件下,Q=1。 可以看出,同一Q在不同模型下可能是不一样的.这个例子的第一课是随机因果模型不足以计算反事实的概率; 计算需要了解 P(y|x) 背后的实际过程。第二个教训是,函数因果模型构成了足以计算(和定义)此类概率的数学对象。在Q_2中,我们得出结论”如果不接受治疗,已故的接受治疗的对象 (y_1, x_1) 会康复“的方式涉及三个心理步骤。 首先,我们将手头的证据 e : {y _1, x_1) 应用于模型并得出结论,e 仅与 U1 和 U2 的一个实现兼容——即 {u1 = 1,u2 = 1}。 其次,为了模拟“他或她没有接受治疗”的假设条件,我们将 x=0 代入(1.48),同时忽略第一个方程 x=u1。 最后,我们对y(假设x=0且u2=1)求解(1.48),得到y=0,由此得出在考虑的假设条件下恢复概率(y=0)为1的结论。一般化到普遍方法如下图: 在某些条件下,我们可以从观测数据中识别出 P(Y | do(x))。 粗略地说,P(Y | do(x)) 可以从联合分布 P(X, Y, Z) 中抽取的观察样本中识别出来,给出马尔可夫模型的因果图 X ← Z → Y,只要所有常见原因(混杂因素)Z, X 和 Y 都被测量。 在实践中,我们往往不知道真正的因果图。我们试图从观察数据中发现它:为此,我们可以使用条件独立性测试来部分识别马尔可夫模型对观察数据的因果图。也就是说,如果给定 Z,X 和 Y 是条件独立的,即 X ⊥Y | Z, 那么我们可以推断出 X—Z—Y(注意,在 Z 存在的情况下,X 和 Y 之间没有直接联系)。但是,我们无法绘制有向边,因为 X ← Z → Y 、X → Z → Y 和 X ← Z ← Y 是马尔可夫等价的——它们编码相同的条件独立性。问题缩减到求因果方向。也就是: 为了解决这个问题,我们应用了Structural Causal Modelling(SCM)。 首先作者给了一下模型定义,以之前Introduction查到的为基础 注意,这里用的是赋值而不是=,是因为赋值具有因果意义:操纵 X 会导致 Y 的值发生变化。 为了表示诸如 do(x) 之类的操作,我们只需替换等式中的赋值 X := x。 然后修改后的 SCM 需要在 X 上进行 Y 后操作的分布,即 P(Y | do(x))。 然而,对于对噪声分布或函数形式没有限制的一般 SCM,我们无法判断从联合分布 P(X, Y ) 中抽取的样本是否是由来自 X → Y 或 Y → X 的 SCM 诱导的,因为我们总是可以在两个方向上构建一个合适的函数和噪声 [7, Prop. 4.1]。 换句话说,从一般的 SCM 来看,两个变量的因果结构无法从联合分布中识别出来; 我们需要额外的假设来确定因果方向。 SCM 的一种特殊情况,称为加性噪声模型,具有我们所寻求的可识别性。 加性噪声模型 (ANM) (之前也讲过)是一类 SCM模型,其约束条件是噪声是加性的,并且独立于外生变量(其值与系统中其他变量的状态无关的变量)。 给定因果图 X → Y ,ANM 将数据生成过程表示为 Y = f(X) + NY ,其中 NY ⊥⊥ X。 在设置对函数形式和噪声分布的一些限制的条件下,我们可以根据观测数据在 ANM 下识别因果方向。 可识别性要求在数据生成过程中具有某种不对称性。 在 ANM 中,在噪声和外生变量的独立性中观察到不对称性。 如果 P(X, Y ) 承认 ANM 从 X 到 Y ,则由 ANM 引起的因果方向 X → Y 是可识别的,但反之则不然。 关于这个“承认”,原文中用词是:admit。具体句子如下: 而网上查到关于admit的定义 也就是说X→Y能表示成ANM的形式。 Shimizu et al. [3]表明如果函数是线性的,并且噪声是非高斯的,则 ANM 是可识别的。 Hoyer et al. [4] 表明,即使函数是非线性的(对噪声分布没有任何限制),ANMs 通常也是可识别的。 我们特别感兴趣的是 Peters 等人的工作。 [5] 这表明 ANM 在离散情况下通常是可识别的。 因此,对于离散情况,我们有以下陈述: 为了在实践中确定因果方向,我们在两个方向上拟合 ANM,并选择具有独立性的方向作为因果方向。 因此,ANM 方法取决于依赖性度量的选择。 大多数相关性度量要么假设检验统计量的抽样分布类型,要么需要内核。 或者,信息论提供香农熵作为测量依赖性的非常直观但功能强大的工具。 在这项工作中,我们对 ANM 采取信息理论方法,并使用熵作为依赖性度量。 因此,我们避免使用 p 值进行显式零假设检验。 此外,我们可以简单地使用经验分布。 请注意,虽然(差分)熵已经在实值数据 [8]、[9] 的 ANM 的背景下进行了研究,但香农熵在离散数据的 ANM 上看似简单的应用却被忽略了。 为了得出 ANM 的信息理论公式,我们必须使用香农熵对从具有图形结构 X → Y 和 Y → X 的 ANM 下的联合分布 P(X, Y) 中抽取的样本中包含的信息进行量化。 对于由 ANM 建模的图形结构 X → Y,由于 ANM 建模的判别性质,我们有 P(Y | X) = P(N_Y | X)。 因此,假设 X → Y 作为使用 ANM 的底层图形结构的样本的总熵是 H(X) + H(N_Y | X)。 将此观察结果与联合香农熵的性质相结合,我们可以证明以下结果。 为了使用因果推断规则来推断因果方向,我们需要两个方向上的噪声变量。 因此,在每个方向上,我们必须找到一个最小化残差熵的函数。 换句话说,我们需要一种离散回归的方法。 与连续回归不同,在离散情况下,不存在过拟合的风险; 对于 X 的每个值,Y 可能取不同的值,因此不需要正则化。 因此,我们可以简单地考虑所有可能的函数,并取损失函数的最小值。 作为损失函数,我们考虑离散香农熵。 因此,我们的目标是找到一个最小化残差熵的函数。 然而,即使函数的范围在目标变量的域内,我们也会有成倍数的函数选择,从而使问题变得棘手。 因此,我们采用启发式方法。 具体算法: SCM:结构因果模型根据观察到的和未观察到的变量的函数来表达因果关系。 ANM 假设未观察到的变量(噪声)是可加的。彼得斯等人。 [5] 将 ANM 扩展到离散数据,并提出 DR 算法。 DR 使用卡方独立性检验,这比香农熵的计算成本更高。进一步的 ACID 不需要在每次迭代中进行 p 值测试。此外,ACID 是确定性的,而 DR 是非确定性的。 Algorithmic Independence:马尔可夫核的算法独立性假设:如果 X 导致 Y ,则 P(X) 和 P(Y | X) 在算法上是独立的 [11], [12]。由于 Kolmogorov 复杂度是不可计算的,基于算法独立性的因果推理方法必须定义一个可计算的依赖度量。 与其他算法的比较结果: 1.合成的因果变量: 以多种分布生成X,Y,始终满足X→Y,一段解释:(公式太多英文太容易懒得写了) 准确度:文章从每个类型里抽样了1000个模型,每个模型里面1000个输出,然后运行程序得到各个算法的准确度。 尽管 CISC 在所有模型类中始终表现良好,但在负二项式模型类中表现非常差。请注意,CISC 将X给定下的的 Y 的条件随机复杂度定义为以 X 值为条件的 Y 的预期随机复杂度,所以S(Y|X)< ECI 的性能可以归因于我们的数据生成模型的差异,以及 ECI 的建模假设。 ANM 假设噪声本质上是可加性的,而 ECI 假设噪声可以是任意类型的。 样本量:在图 2 中,我们比较了不同样本量的 ACID 与 ECI、DR 和 CISC 的准确性。 我们观察到 ACID 在所有情况下都能达到 98% 到 100% 的准确率。 DR 在小样本上表现不佳,对于大样本,其性能逐渐提高。 CISC 的准确率始终保持在 94% 左右,而 ECI 的表现仅略好于随机抛硬币。 因果方向判断准确度:区分 X → Y 和 Y → X 的问题可以转化为身份测试问题。 文章的方法基于压缩,因此使用 Ryabko & Astola [15] 提出的基于压缩的身份测试框架来评估推断结果的重要性。 框架大致可以描述如下: 该框架的测试统计量由δ = − log P(xn) + log Q(x n) 给出。由于无超压缩不等式 [16,Chap3.3],测试统计量的 p 值为 2−δ,这给出了任意分布 Q 比分布 P 更好地压缩数据 δ 位的概率在数据上的上限。从 ACID 做出决定(例如 X → Y )的因果对 (X, Y ) 中,我们想评估该决定是否重要。为此,我们的原假设 H0 将是替代方向 (Y → X) 下的联合分布。那么备择假设 H1 将是在推断方向下的假设。由于熵给出了样本中每个结果的平均位数,使用 ANM 从 X → Y 的样本压缩大小由 CX→Y = nHX→Y 给出,从 Y → X 给出的是 CY →X = nHY → X。我们的检验统计量将是 δ = CY →X − CX→Y 。如果 δ > − log α,我们拒绝 H0。为了控制多重假设检验的错误发现率,我们使用 Benjamini-Hochberg 程序 [17]。让 H10, H20, . . . , Hm0是测试的零假设,并且 p1, p2, . . . , pm 对应的 p 值。我们按升序对 pvalue 进行排序。对于 α 的显着性水平,我们找到最大的 k,使得 pk ≤ km α。我们拒绝所有 hi 的原假设,其中 i = 1, 。 . . ,k。 为了进行评估,我们从几何分布的参数化族中抽取了 100 个模型。 对于每个模型,我们采样了 350 个结果。 在图 3 中,我们通过它们在两个方向上的相应压缩差异 (δ) 对因果对进行排序。 这也对应于以升序方式按 p 值对配对进行排序。 在 α = 0.01 的显着性阈值下,应用 Benjamini-Hochberg 校正后,五个推断是不显着的,其中两个不正确的推断。 我们也观察到其他模型类的类似行为。 2.实际的因果数据: 为了研究 ACID 是否在现实世界数据中发现有意义的方向,我们考虑了三个数据集。 Horse Colic:该数据集也可从 UCI 机器学习存储库中获得,其中包含具有 28 个属性和 368 个实例的马的医疗记录。我们特别感兴趣的是两个属性:腹部状态 (X) 有 5 个可能的值,手术病变 (Y) 有 2 个可能的值,表明病变(问题)是否是外科手术的。我们删除了缺失值的实例,最终总共有 225 个实例。据领域专家介绍,大肠扩张和小肠扩张两种腹部状态表示手术病变。因此,将腹部状态视为手术病变的原因之一是合理的。因此,我们将 X → Y 视为基本事实。 ACID 和 ECI 都恢复了基本事实。尽管 DR 仍然优柔寡断,但 CISC 以非常高的置信度(δ = 85.73 位)推断出错误的指令。 我们提出了一个使用 ANM 对离散数据进行因果推断的信息理论框架。实验表明,所提出的算法 ACID 在合成数据上具有很高的准确度,对于各种源分布和样本大小的准确度达到或接近 100%,而定性案例研究证实结果是合理的。 ACID 进行了几次迭代才能收敛,并在我们的实验中在几秒钟内完成。此外,可以使用基于压缩的假设检验框架来评估 ACID 结果的统计显着性。结果表明,香农熵是一个相当不错的选择,作为使用来自离散数据的 ANM 进行因果推断的依赖度量。首先,边际香农熵的计算成本更低。此外,与其他统计独立性测试框架不同,我们不必在每次迭代中使用 p 值明确测试零假设。如果需要,可以使用基于压缩的身份测试框架来评估最终结果的重要性。 参考文献:(其余笔记中提到的参考文献对应找[1]的reference) [1]K. Budhathoki and J. Vreeken, "Accurate Causal Inference on Discrete Data," 2018 IEEE International Conference on Data Mining (ICDM), 2018, pp. 881-886, doi: 10.1109/ICDM.2018.00105. [2] J. Pearl, Causality: Models, Reasoning, and Inference. Cambridge University Press, 2000. [3] S. Shimizu, P. O. Hoyer, A. Hyvarinen, and A. Kerminen, “A linear non-gaussian acyclic model for causal discovery,” JMLR, vol. 7, pp. 2003–2030, 2006. [4] P. Hoyer, D. Janzing, J. Mooij, J. Peters, and B. Scholkopf, “Nonlinear causal discovery with additive noise models,” in NIPS, 2009, pp. 689– 696. [5] J. Peters, D. Janzing, and B. Scholkopf, “Identifying cause and effect on discrete data using additive noise models,” in AISTATS, 2010, pp. 597–604. [1.6]https://zhuanlan.zhihu.com/p/369720949 [1.7]https://blog.csdn.net/weixin_26752075/article/details/108259154#:~:text=Additive%20noise%20model%20%28ANM%29%3A%20The%20joint%20distribution%20P_,%3D%20F_Y%20%28X%29%20%2B%20N_Y%2C%20N_Y%20%E2%9F%82%20X.CAUSAL INFERENCE
注意 P(Y | 操作 X 到 x1) 与 P(Y | X = x) 不同;前者代表 Y 在 X 上的后处理分布,而后者只是我们观察到 X = x 的情况下观察到的 Y 分布。 do-calculus [2,Chap. 3] 提供了一种数学语言来表达这种处理后的分布。我们使用 do 演算将 P(Y | 操作 X 到 x) 表示为 P(Y | do(X = x)),简称 P(Y | do(x))。
在实践中,操纵变量(设置实验)通常非常昂贵、不合伦理或根本不可能;确定吸烟是否会导致肺癌就是这样一个例子。因此,需要从观察数据中识别变量之间的因果关系。粗略地说,如果我们可以仅从观察数据中估计 P(Y | do(x)) 是可识别的。
Pearl的开创性工作 [2, Thm. 3.2.5]表明,


 这个定义看that is后面的条件比较好理解,但是还是有点点绕。需要理解quantity和这些notation的意思,可以看后面[1]1.4的讨论。(主要意思是:任何两个满足因果图都是G、概率公式也一样的模型里计算的这个do-概率都是一样的的模型M1 M2,计算得到的P(X|Y)都是一样的。)这个可识别的作用是:
这个定义看that is后面的条件比较好理解,但是还是有点点绕。需要理解quantity和这些notation的意思,可以看后面[1]1.4的讨论。(主要意思是:任何两个满足因果图都是G、概率公式也一样的模型里计算的这个do-概率都是一样的的模型M1 M2,计算得到的P(X|Y)都是一样的。)这个可识别的作用是:








Structural Causal Modelling




INFORMATION-THEORETIC ANM





RELATED WORK
Kocaoglu et al. [10] 最近提出了两个离散变量的因果推理框架 (ECI),假设未观察到的变量在真实方向上更简单(就 Renyi´ 熵而言)。特别地,推测如果 X 导致 Y ,H_α(X)+H_α(E) < H_α(Y)+H_α(E^~) 其中 H_α 是Renyi熵,其中Y = f(X, E), X ⊥⊥ E; X = f(Y, E^~), X ⊥⊥ E^~。与假设噪声为加性类型的 ANM 不同,未观察到的变量在 ECI 中可以是任意类型。
CISC [13] 使用精制 MDL(an approximation from above to Kolmogorov complexity w.r.t. a model class)从离散数据进行因果推断。可识别性是因果推理的一个重要方面,因为它区分了概率条件 P(Y | X = x) 和因果条件 P(Y |do(X = x))。根据 ANM 对离散数据的可识别性,ACID 是可识别的,而 CISC 则不是。
Liu & Chan [14] (DC) 建议使用距离相关性作为依赖性度量。为了推断因果方向,DC 计算两个方向上的经验边际分布和条件分布之间的距离相关性。On account of the performance of DC against the state-of-the-art [13], we do not consider it for comparison.EXPERIMENTS



鲍鱼:该数据集可从 UCI 机器学习存储库中获得, 包含 4177 只鲍鱼(大型可食用海螺)的物理测量结果。我们根据长度 (Y1)、直径 (Y2) 和高度 (Y3) 。我们考虑鲍鱼的性别 (X)。鲍鱼的性别是单一的(雄性、雌性或婴儿),而长度、直径和高度均以毫米为单位,分别具有 70、57 和 28 个唯一值。在[5]之后,我们将数据视为离散的。由于性别决定了鲍鱼的大小,而不是相反,我们将 X → Y1、X → Y2 和 X → Y3 视为基本事实。我们在表 I 中报告了结果。 ACID 在所有三对中推断出正确的方向,两个方向之间的得分差异很大。 CISC 和 ECI 也在所有三对中识别正确的方向。另一方面,DR 在第三种情况下仍然犹豫不决。
NLSchools 该数据集是图宾根因果基准对中的第 99 对。3 它包含语言测试
131 所学校 132 个班级 2287 名八年级学生的得分(X)和学生家庭社会经济状况(Y)
荷兰人。语言测试成绩有 47 个唯一值,学生家庭的社会经济地位有 21 个唯一值。我们将 Y → X 视为基本事实,因为学生家庭的社会经济地位是语言考试成绩的原因之一。所有方法都恢复了基本事实。CONCLUSIONS