导言:对于大多数前端开发者而言,谈到命令行工具,大家肯定都用过。但是谈到开发命令行工具,估计就没几人有了解了。本文旨在用最短的时间内,帮您开发一个实用(斜眼笑)的图片爬虫命令行应用。
想追求更好的阅读体验,请移步拓跋的前端客栈。同时把项目地址放在显眼的位置
Puppeteer 简介
什么是 Puppeteer?
Puppeteer 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具。Chrome 作为浏览器市场的领头羊,Chrome Headless 将成为 web 应用 自动化测试 的行业标杆。所以我们很有必要来了解一下它。
Puppeteer 可以做什么?
Puppeteer 可以做的事情有很多,包括但不限于:
- 利用网页生成 PDF、图片
- 可以从网站抓取内容
- 自动化表单提交、UI 测试、键盘输入等
- 帮你创建一个最新的自动化测试环境(chrome),可以直接在此运行测试用例
- 捕获站点的时间线,以便追踪你的网站,帮助分析网站性能问题
Puppeteer 有什么优势?
- 相对于真实浏览器而言,少了加载 css,js 以及渲染页面的工作。无头浏览器要比真实浏览器快的多。
- 可以在无界面的服务器或 CI 上运行,减少了外界的干扰,更稳定。
- 在一台机器上可以模拟运行多个无头浏览器,方便进行并发运行。
如何安装 Puppeteer?
安装 Puppeteer 很简单,如下:
npm i --save puppeteer
or
yarn add puppeteer
需要注意的是,由于用到了 ES7 的 async/await 语法 ,node 版本最好是 v7.6.0 或以上。
如何使用 Puppeteer?
由于本文不是专门讲 Puppeteer 的文章,故这部分暂且略过,大家可以去看下面的链接学习。
Puppeteer Github
Puppeteer Api Doc
Puppeteer 中文 Api Doc
说了这么多,Puppeteer 与我们要开发的命令行应用有什么关系呢?我们准备制作一个抓图命令行工具,不使用传统的请求式爬虫,我们使用 Puppeteer 这种无头浏览器,从 DOM 里抓图,这样能有效规避部分爬虫防御手段。
Puppeteer 简单应用
case 1. 屏幕截图
直接上代码,很好理解:
const puppeteer = require("puppeteer");
const getScreenShot = async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto("https://baidu.com");
await page.screenshot({ path: "baidu.png" });
await browser.close();
};
getScreenShot();
这段代码的意思就是以 headless(无头)模式打开浏览器,然后打开一个新标签页,跳转到百度网址, 并且进行屏幕截图,保存为 baidu.png 为名的图片,最后关闭浏览器。
执行结果如下。

case 2. 抓取网站信息
接下来学习如何用 Puppeteer 抓取网站信息了。
这次我们来抓取 jd 书单信息。
// book info spider
const puppeteer = require("puppeteer");
const fs = require("fs");
const spider = async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://search.jd.com/Search?keyword=javascript");
const result = await page.evaluate(() => {
let elements = document.querySelectorAll(".gl-item");
const data = [...elements].map(i => {
return {
name: i.querySelector(".p-name em").innerText,
description: i.querySelector(".p-name i").innerText,
price: i.querySelector(".p-price").innerText,
shop: i.querySelector(".p-shopnum").innerText,
url: i.querySelector(".p-img a").href
};
});
return data; // 返回数据
});
browser.close();
return result;
};
spider().then(value => {
fs.writeFile(`${__dirname}/javascript.json`, JSON.stringify(value), err => {
if (err) {
throw err;
}
console.log("file saved!");
});
console.log(value); // Success!
});
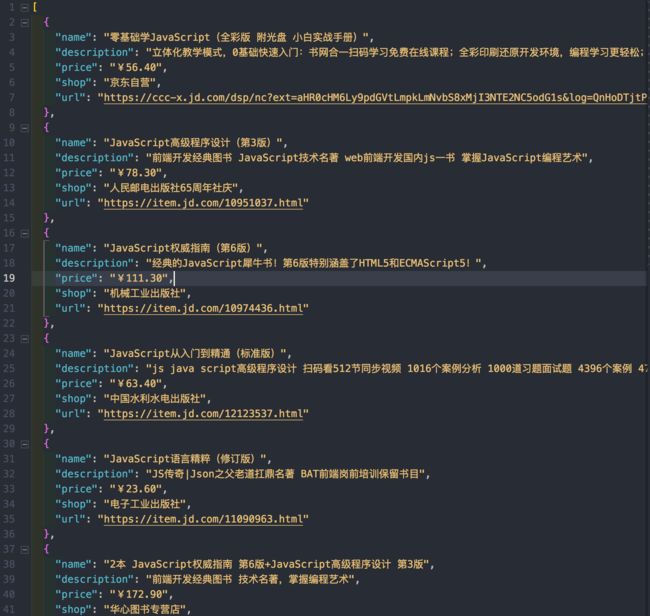
我们做的就是跳转到关键字是 javascript 的页面,然后对页面的 dom 结构进行分析,找到图书列表所对应的书名、描述、价格、出版社、网页链接信息,然后把数据写入到 javascript.json 文件里去,方便我们保存浏览。
逻辑很简单。这已经是一个爬虫的雏形了,最后得到如下图所示的 json 文件,非常给力。
case 3. 图片爬虫
图片爬虫,这就是我们要做的命令行应用的主题了。
一个最基本的思路是这样的:
打开浏览器 —> 跳转到百度图片 —> 获取 input 框的焦点 —> 输入 keywords —> 点击搜索按钮 —> 跳转至结果列表页 —> 下拉到底部 —> 操作 dom,获取所有图片的 src 备用 —> 根据 src 将对应图片保存到本地 —> 关闭浏览器
代码实现之:
首先是浏览器操作部分
const browser = await puppeteer.launch(); // 打开浏览器
const page = await browser.newPage(); // 打开新tab页
await page.goto("https://image.baidu.com"); // 跳转到百度图片
console.log("go to https://image.baidu.com"); // 获取input框的焦点
await page.focus("#kw"); // 把焦点定位到搜索input框
await page.keyboard.sendCharacter("猫咪"); // 输入关键字
await page.click(".s_search"); // 点击搜索按钮
console.log("go to search list"); // 提示跳转到搜索列表页
然后是图片处理部分
page.on("load", async () => {
await autoScroll(page); // 向下滚动加载图片
console.log("page loading done, start fetch...");
const srcs = await page.evaluate(() => {
const images = document.querySelectorAll("img.main_img");
return Array.prototype.map.call(images, img => img.src);
}); // 获取所有img的src
console.log(`get ${srcs.length} images, start download`);
for (let i = 0; i < srcs.length; i++) {
await convert2Img(srcs[i], target);
console.log(`finished ${i + 1}/${srcs.length} images`);
} // 保存图片
console.log(`job finished!`);
await browser.close();
});
因为百度图片是往下滚动就可以继续懒加载。因此,我们想要加载更多图片,可以先往下滚动一会儿。然后通过分析 dom 结构来获取列表里所有图片的 src,最后进行下载。
执行以下,就能得到一系列猫咪的图片:

图片下载的地方只写了主函数,更详细的代码可以去参见github.
至此,我们用 Node 和 Puppeteer 开发出了一个最基本的图片爬虫工具。
如何优化?
这个图片爬虫工具目前还有点 low 啊,我们的目标是要开发一个交互式的命令行应用,肯定不能止于此。有哪些可以进一步优化的点呢?经过简单的思考,我列了一下:
- 下载图片的内容可以自定义
- 可以支持用户选择图片下载张数
- 支持命令行传参
- 支持命令行交互
- 交互界面美观
- 支持双击直接运行
- 支持全局命令行调用
使用 commander.js 支持命令行传参
Commander 是一款重量轻,表现力和强大的命令行框架。提供了用户命令行输入和参数解析强大功能。
const program = require("commander");
program
.version("0.0.1")
.description("a test cli program")
.option("-n, --name ", "your name", "zhl")
.option("-a, --age ", "your age", "22")
.option("-e, --enjoy [enjoy]")
.action(option => {
console.log('name: ', option.name);
console.log('age: ', option.age);
console.log('enjoy: ', option.enjoy);
});
program.parse(process.argv);
Commander十分容易上手,上面这一段代码仅用了寥寥数行,就定义了一个命令行的输入与输出。其中:
- version 定义版本号
- description 定义描述信息
- option 定义输入选项,传3个参数,如
option("-n, --name,第一项是传参的值,-n是简写形式,--name是全称形式,", "your name", "GK") 表示输入的参数,<>是必填项,如果是[],则是选填项。第二项“your name"是求助help时的提示信息,告诉用户应该输入的内容,最后一项"GK"是默认值。 - action 定义执行的操作,是一个回调函数,入参是前文输入的option选项,如果没有输入option,则使用定义的默认值。
要查询更详细的api,请参考Commander Api文档。
执行一下上述脚本,可以得到:
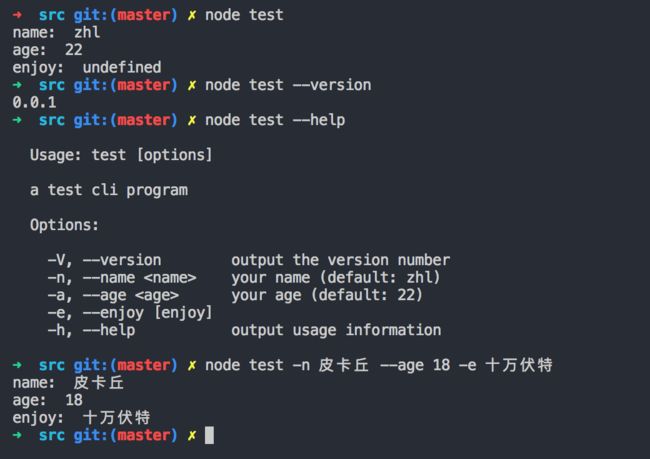
这样命令行就可以做到简单的交互效果了。但是有没有觉得不够好看呢,别急,继续往下看。
使用inquirer制作可交互命令行应用
inquirer可以为Node制作可嵌入式的美观的命令行界面。
可以提供问答式的命令输入:
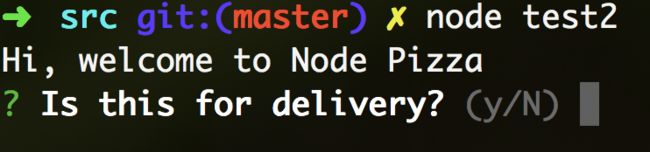
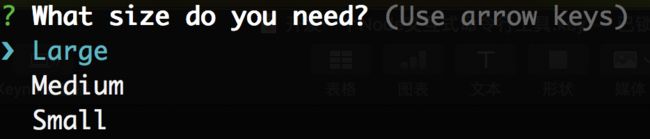
可以提供多种形式的选择界面:
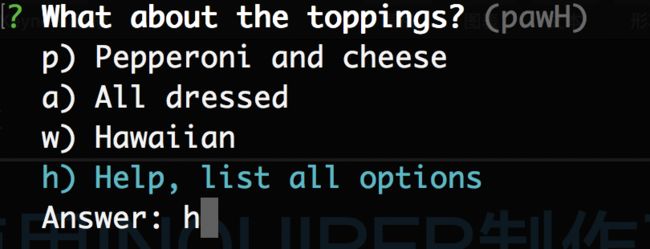
可以对输入信息进行校验:

最后可以对输入信息进行处理:
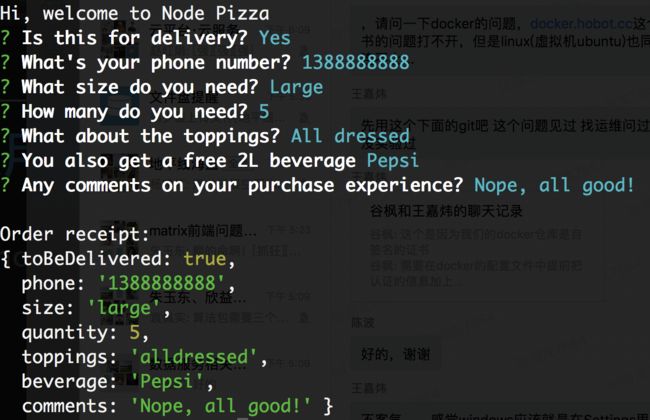
上面的例子是inquirer的官方例子,可以参考pizza.js
inquirer的文档可以查看inquirer documents
有了inquirer,我们就可以制作更为精美的交互式命令行工具了。
使用 chalk.js来让交互界面更美观
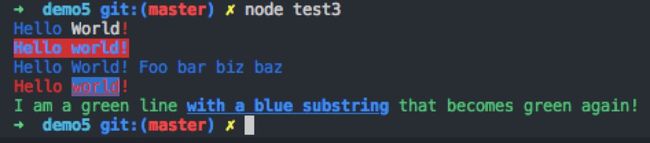
chalk的语法非常简单:
const chalk = require('chalk');
const log = console.log;
// Combine styled and normal strings
log(chalk.blue('Hello') + ' World' + chalk.red('!'));
// Compose multiple styles using the chainable API
log(chalk.blue.bgRed.bold('Hello world!'));
// Pass in multiple arguments
log(chalk.blue('Hello', 'World!', 'Foo', 'bar', 'biz', 'baz'));
// Nest styles
log(chalk.red('Hello', chalk.underline.bgBlue('world') + '!'));
// Nest styles of the same type even (color, underline, background)
log(chalk.green(
'I am a green line ' +
chalk.blue.underline.bold('with a blue substring') +
' that becomes green again!'
));
可以输出如下信息,一看便懂:
再让我们做点有意思的事情...
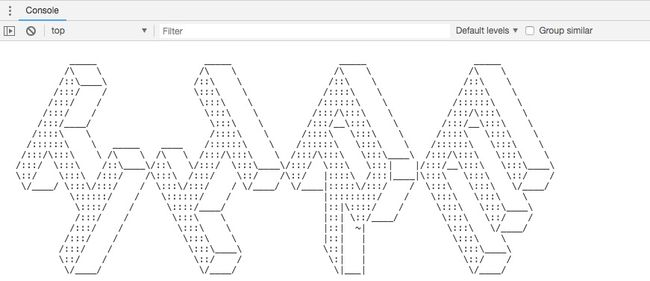
想必有人看到过下面知乎的控制台效果,既然要做点有意思的事情,今天我们不妨也把这种效果加到命令行程序里面,提升一下逼格。
首先我们准备一副ASCII码用来打印,各位可以自行搜索text转ASCII,网上的转化方案不要太多。我们准备制作的命令行image spider就制作一个IMG SPD的ASCII码字符串吧~
经过挑选,效果如图:

这种复杂的字符串怎么打印出来呢?直接保存为string一定是不行的,格式会乱的一塌糊涂。
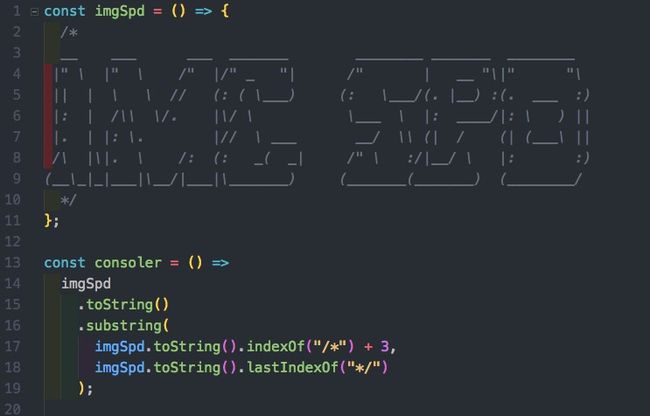
想要能完整的打印出格式来,有一个取巧的方法,以注释的形式打印出来。什么能保存注释呢?~~ function。
所以事情就简单到了打印一个function。但是直接打印函数还是不行的,这时候就用到了可以怼天怼地的toString()方法,我们只需要把注释中间的部分用正则匹配出来就行了,easy~
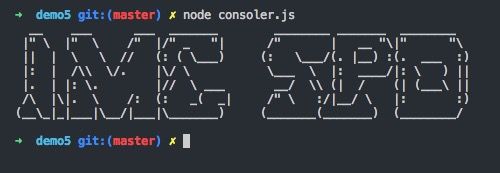
最后看一看效果,铛铛铛铛~
支持双击运行
这里使用一种叫做Shebang的技术。
Shebang(也称为 Hashbang )是一个由#和!构成的字符序列 #! ,其出现在文本文件的第一行的前两个字符。 在文件中存在 Shebang 的情况下,类 Unix 操作系统的程序加载器会分析 Shebang 后的内容,将这些内容作为解释器指令,并调用该指令,并将载有 Shebang 的文件路径作为该解释器的参数。
node下我们使用#! /usr/bin/env node即可
这时候我们便可以取消文件的扩展名.js了。
加入环境变量,支持全局调用
package.json里面配置
"bin": {
"img-spd": "app"
},
执行npm link,它将会把img-spd这个字段复制到npm的全局模块安装文件夹node_modules内,并创建符号链接(symbolic link,软链接),也就是将 app 的路径加入环境变量 PATH。
这时,在任意目录下,直接命令行输入img-spd即可运行此命令行
尾声
至此,要改进的地方已经全部修改完毕,快来看看我们的成品吧~
看着一整个文件夹的gakki,感觉满满的幸福要溢出来了
最后用动图来展示一下:
附录
项目地址
项目地址
Install
npm install -g img-spd
Usage
img-spd
or
Usage: img-spd [options]
img-spd is a spider get images from image.baidu.com
Options:
-v --version output the version number
-k, --key [key] input the image keywords to download
-i, --interval [interval] input the operation interval(ms,default 200)
-n, --number [number] input the operation interval(ms,default 200)
-m, --headless [headless] choose whether the program is running in headless mode
-h, --help output usage information