term与match的区别:
term查询:只匹配指定的字段中包含指定的词的文档,terms可指定多个字段
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个
match查询会先对搜索词进行分词,分词完毕后再逐个对分词结果进行匹配,因此相比于term的精确搜索,match是分词匹配搜索
must,must_not,should,filter
must 返回的文档必须满足must子句的条件,并且参与计算分值
must_not返回的文档必须不满足must_not定义的条件
filter 【filter以前时单独的query DSL,现在归入bool query】;
子句(查询)必须出现在匹配的文档中。然而,不同于must查询的是——它不参与分数计算。
Filter子句在过滤器上下文(filter context)中执行,这意味着score被忽略并且子句可缓存【所以filter可能更快】
should “权限”比must/filter低。
如果没有must或者filter,有一个或者多个should子句,那么只要满足一个就可以返回。
minimum_should_match参数定义了至少满足几个子句。
match_all,match,match_phrase,match_phrase_prefix,multi_match,multi_mutch
match_all
能够匹配索引中的所有文件。
可以在查询中使用boost包含加权值,它将赋给所有跟它匹配的文档,计算score时用到。

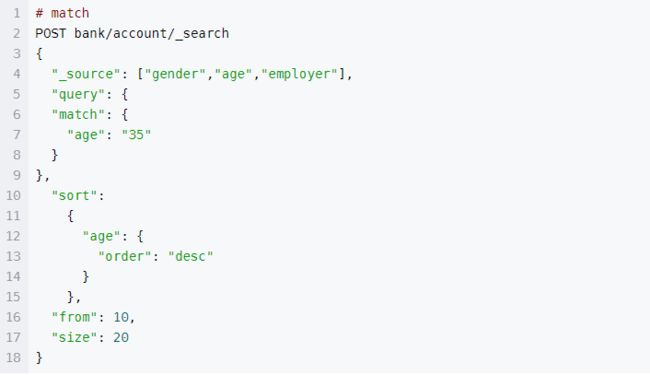
match
match查询相当于模糊匹配,只包含其中一部分关键词就行
match_phrase
match_phrase 短语匹配查询,要求必须全部精确匹配,且顺序必须与指定的短语相同。
match_phrase查询首先解析查询字符串来产生一个词条列表。然后会搜索所有的词条,但只保留包含了所有搜索词条的文档。
slop参数slop参数告诉match_phrase查询词条能够相隔多少个单次时将文档视为匹配。
尽管在使用了slop的短语匹配中,所有的单词都需要出现,但是单词的出现顺序可以不同。如果slop的值足够大,那么单词的顺序可以是任意的。
match_phrase_prefix

与match_phrase不同之处在于,match_phrase_prefix中的短语,在最后一个词时,将其视为其他词的前缀,允许对其进行“扩展”,也就是说,620 National D**也许可以匹配**620 National Drive

multi_mutch
multi_mutch可以进行跨字段查询,也就是说,对于”query“:“这是需要检索的”
可以在指定的多个字段中检索之,介于全文检索和单个字段检索字间
还可以指定“权重”
tie_breaker等很多的其他参数
tie_breaker作用:除best_fields 指定的字段,其他字段的得分需要×tie_breaker的值
