Zab也是一个强一致性算法,也是(multi-)Paxos的一种,全称是Zookeeper atomic broadcast protocol,是Zookeeper内部用到的一致性协议。相比Paxos,也易于理解。其保证了消息的全局有序和因果有序,拥有着一致性。Zab和Raft也是非常相似的,只是其中有些概念名词不一样。
Role(or Status)
节点状态:
Leading:说明当前节点为Leader
Following:说明当前节点为Follower
Election:说明节点处于选举状态。整个集群都处于选举状态中。
Epoch逻辑时钟
Epoch相当于paxos中的proposerID,Raft中的term,相当于一个国家,朝代纪元。
Quorums:
多数派,集群中超过半数的节点集合。
节点中的持久化信息:
history: a log of transaction proposals accepted; 历史提议日志文件
acceptedEpoch: the epoch number of the last NEWEPOCH message accepted; 集群中的最近最新Epoch
currentEpoch: the epoch number of the last NEWLEADER message accepted; 集群中的最近最新Leader的Epoch
lastZxid: zxid of the last proposal in the history log; 历史提议日志文件的最后一个提议的zxid
在 ZAB 协议的事务编号 Zxid 设计中,Zxid 是一个 64 位的数字,
低 32 位是一个简单的单调递增的计数器,针对客户端每一个事务请求,计数器加 1;
高 32 位则代表 Leader 周期 epoch 的编号,每个当选产生一个新的 Leader 服务器,就会从这个 Leader 服务器上取出其本地日志中最大事务的ZXID,并从中读取 epoch 值,然后加 1,以此作为新的 epoch,并将低 32 位从 0 开始计数。
epoch:可以理解为当前集群所处的年代或者周期,每个 leader 就像皇帝,都有自己的年号,所以每次改朝换代,leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 leader 崩溃恢复之后,也没有人听他的了,因为 follower 只听从当前年代的 leader 的命令。
ZAB协议
Zab协议分为四个阶段


Phase 0: Leader election(选举阶段,Leader不存在)
节点在一开始都处于选举阶段,只要有一个节点得到超半数Quorums节点的票数的支持,它就可以当选prospective leader。只有到达 Phase 3 prospective leader 才会成为established leader(EL)。
这一阶段的目的是就是为了选出一个prospective leader(PL),然后进入下一个阶段。
协议并没有规定详细的选举算法,后面我们会提到实现中使用的 Fast Leader Election。
Phase 1: Discovery(发现阶段,Leader不存在)
在这个阶段,PL收集Follower发来的acceptedEpoch(或者),并确定了PL的Epoch和Zxid最大,则会生成一个NEWEPOCH分发给Follower,Follower确认无误后返回ACK给PL。
这个一阶段的主要目的是PL生成NEWEPOCH,同时更新Followers的acceptedEpoch,并寻找最新的historylog,赋值给PL的history。
这个阶段的根本:发现最新的history log,发现最新的history log,发现最新的history log。
一个 follower 只会连接一个 leader,如果有一个节点 f 认为另一个 follower 是 leader,f 在尝试连接 p 时会被拒绝,f 被拒绝之后,就会进入 Phase 0。
1PL Followers
2|<---------X--X--X FOLLOWERINFO(F.acceptedEpoch)
3X--------->|->|->| NEWEPOCH(e′)
4|<---------X--X--X ACKEPOCH(F.currentEpoch, F.history, F.lastZxid),接着PL寻找所有Follower和PL中最新的history赋值给PL.history
Phase 2: Synchronization(同步阶段,Leader不存在)
同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。只有当 quorum 都同步完成,PL才会成为EL。follower 只会接收 zxid 比自己的 lastZxid 大的提议。
这个一阶段的主要目的是同步PL的historylog副本。
1PL Followers
2X--------->|->|->| NEWLEADER(e′ , L.history)
3|<---------X--X--X ACKNEWLEADER(e′,L.history)
4X--------->|->|->| COMMIT message,Follow Deliver ⟨v, z⟩,PL->L
Phase 3: Broadcast(广播阶段,Leader存在)
到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
这个一阶段的主要目的是接受请求,进行消息广播
值得注意的是,ZAB 提交事务并不像 2PC 一样需要全部 follower 都 ACK,只需要得到 quorum (超过半数的节点)的 ACK 就可以了。
1Client Leader Followers
2| | | | |
3 X-------->| | | | write Request
4| X--------->|->|->| sent Propose ⟨e′, ⟨v, z⟩⟩
5| |<---------X--X--X Append proposal to F.history,Send ACK(⟨e′, ⟨v, z⟩⟩) to L
6| X--------->|->|->| COMMIT(e′, ⟨v, z⟩),F Commit (deliver) transaction ⟨v, z⟩
zookeeper中zab协议的实现
协议的 Java 版本实现跟上面的定义有些不同,选举阶段使用的是 Fast Leader Election(FLE),它包含了 Phase 1 的发现职责。因为 FLE 会选举拥有最新提议历史的节点作为 leader,这样就省去了发现最新提议的步骤。实际的实现将 Phase 1 和 Phase 2 合并为 Recovery Phase(恢复阶段)。所以,ZAB 的实现只有三个阶段:

Phase 1:Fast Leader Election(快速选举阶段,Leader不存在)
前面提到 FLE 会选举拥有最新提议历史(lastZixd最大)的节点作为 leader,这样就省去了发现最新提议的步骤。这是基于拥有最新提议的节点也有最新提交记录的前提。
每个节点会同时向自己和其他节点发出投票请求,互相投票。
选举流程:
选epoch最大的
epoch相等,选 zxid 最大的
epoch和zxid都相等,选择serverID最大的(就是我们配置zoo.cfg中的myid)
节点在选举开始都默认投票给自己,当接收其他节点的选票时,会根据上面的条件更改自己的选票并重新发送选票给其他节点,当有一个节点的得票超过半数,该节点会设置自己的状态为 leading,其他节点会设置自己的状态为 following。
Phase 2:Recovery Phase(恢复阶段,Leader不存在)
这一阶段 follower 发送它们的 lastZixd 给 leader,leader 根据 lastZixd 决定如何同步数据。这里的实现跟前面 Phase 2 有所不同:Follower 收到 TRUNC 指令会中止 L.lastCommittedZxid 之后的提议,收到 DIFF 指令会接收新的提议。
1L Followers
2X----------------- L.lastZxid ← ⟨L.lastZxid.epoch + 1, 0⟩
3|<---------X--X--X FOLLOWERINFO(F.lastZxid)
4X--------->|->|->| NEWEPOCH(L.lastZxid)
5X--------->|->|->| SNAP,DIFF or TRUNC指令
6|<---------X--X--X if TRUNC notAccept L.lastZxid else(DIFF) accept,commit proposal else(SNAP) ...
Phase 3:Broadcast Election(广播阶段,Leader存在)
同上
Leader故障
如果是Leader故障,首先进行Phase 1:Fast Leader Election,然后Phase 2:Recovery Phase,恢复阶段保证了如下两个问题,这两个问题同时也和Raft中的Leader故障解决的问题是一样的,总之就是要保证Leader操作日志是最新的:
已经被处理的消息不能丢
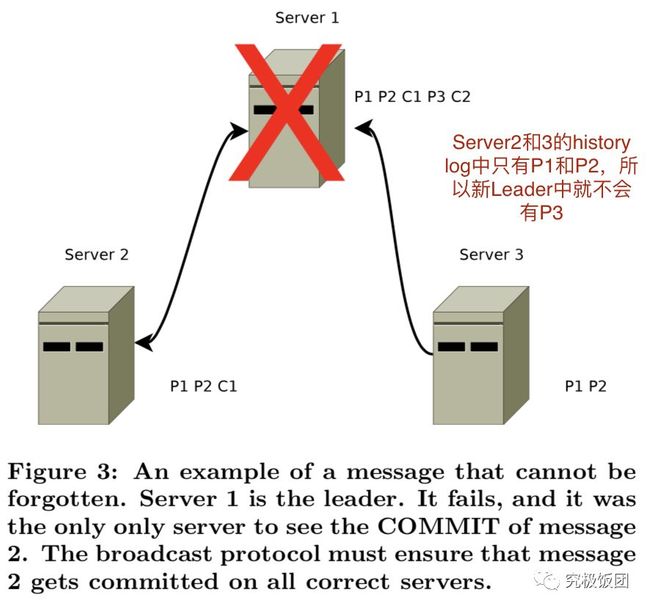
被丢弃的消息不能再次出现

总结
Zab和Raft都是强一致性协议,但是Zab和Raft的实质是一样的,都是mutli-paxos衍生出来的强一致性算法。简单而言,他们的算法都都是先通过Leader选举,选出一个Leader,然后Leader接受到客户端的提议时,都是先写入操作日志,然后再与其他Followers同步日志,Leader再commit提议,再与其他Followers同步提议。如果Leader故障,重新走一遍选举流程,选取最新的操作日志,然后同步日志,接着继续接受客户端请求等等。过程都是一样,只不过两个的实现方式不同,描述方式不同。实现Raft的核心是Term,Zab的核心是Zxid,反正Term和Zxid都是逻辑时钟。