这几天闲的无聊看了一下有关于OCR方面的要点,主要还是详细了解基于CTPN+CRNN进行OCR检测。并且也看了内部代码,在这里想梳理一下论文要点以及代码逻辑。
首先给一下论文地址及代码地址:
1.论文地址:Detecting Text in Natural Image with Connectionist Text Proposal Network
- 代码地址(pytorch): [https://github.com/opconty/pytorch_ctpn(https://github.com/opconty/pytorch_ctpn)
3.代码地址(pytorch+tensorflow+keras): https://github.com/xiaofengShi/CHINESE-OCR]
一、 原理解释
1. CTPN(Connectionist Text Proposal Network])
(一)网络提出的出发点
这个网络的出发点可以从一下几个方面来介绍下。
- 文本检测与一般目标检测是区别的,文本检测本身是具有序列性质的。例如一些文本是有多个字以及字符构成,而不仅仅是一个个字符目标。所以我们认为这即是难点也是优势,难点在于我们需要检测出一个完整的文本线,同一文本线字符可能差异大,距离远,要作为一个整体的目标难度大。但是优点,我们可以利用统一文本线上的不同字符之间的上线文关系。
- Top-down(先检测文本区域,再找出文本线)的文本检测方法比传统的bottom-up的检测方法(先检测字符,再串成文本线)更好。自底向上的方法的缺点在于(这点在作者的另一篇文章中说的更清楚),总结起来就是没有考虑上下文,不够鲁棒,系统需要太多子模块,太复杂且误差逐步积累,性能受限。
- RNN和CNN的无缝结合可以提高检测精度。CNN用来提取深度特征,RNN用来序列的特征识别(2类),二者无缝结合,用在检测上性能更好。
(二)网络结构图
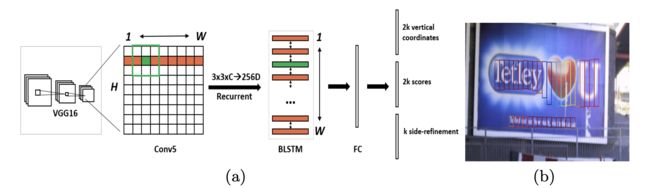
如上图所示,此图就是我们CTPN的网络示意图,即:
提取特征 ➡️ 卷积层 ➡️ Bi-LSTM层 ➡️ FC层 ➡️ 输出层
1)基于VGG层提取特征
因为此模型是2016年在faster-rcnn网络提出之后出来的网络,当时提取网络的backbone采用的是vgg16。因此首先用vgg16的前5个Conv stage得到feature map。
我们输入图片大小为()通过vgg得到大小的feature map。
2)卷积
这里输入输出chanel以及feature map保持不变。 用3*3的滑动窗口在前一步得到的feature map上提取特征,利用这些特征来对多个anchor进行预测,这里anchor定义与之前faster-rcnn中的定义相同,也就是帮我们去界定出目标待选区域。
3)Bi-LSTM层
将我们上述的得到的特征图像输入到Bi-LSTM网络中去。这里的feature map可以在两个维度上理解。在H上可以理解为是每一个batch,在W这个维度上可以理解为是Bi-LSTM的每一个输入。我们设置输出chanel为128,因为是Bi-LSTM,所以输出通道数目是256()。
4)FC层
通过卷积得到chanel为512的fc层()。
5) 输出层
最后通过分类或回归得到的输出主要分为三部分,根据上图从上到下依次为2k vertical coordinates:表示选择框的高度和中心的y轴的坐标;2k scores:表示的是k个anchor的类别信息,说明其是否为字符;k side-refinement表示的是选择框的水平偏移量。本文实验中anchor的水平宽度都是16个像素不变,也就是说我们微分的最小选择框的单位是 “16像素”。
第一个分支是对k个auchor的纵坐标,每一个anchor的纵坐标有两个,分别是盒子的y坐标中心和高度,因此,总共的维度是2k。具体表示如下:
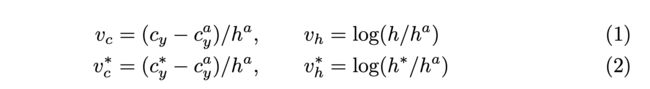
其中,、
分别是预测的坐标和真实的坐标,和分别是一个anchor的y坐标中心和高度,和分别是预测出来的y坐标中心和高度,和分别是真实的y坐标中心和高度。
第二个分支是对k个anchor的score进行预测,即该盒子是否包含文本的概率,每个盒子对应一个二分类,因此,总共是2k个维度。当score>0.7时,认为该anchor包含文本。
第三个分支是对k个anchor的横坐标进行预测,可以在每个anchor盒子的左侧或右侧的横坐标,因此,k个盒子对应的维度就是k。之所以需要这个分支主要是为了修正anchor的水平位置。坐标的具体表示如下:
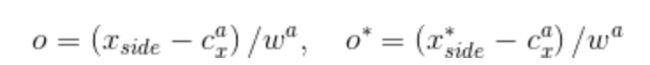
其中,是预测出来的距离anchor水平坐标(左或右坐标)最近的坐标,是真实的x坐标,是anchor的x坐标中心,是anchor的宽度,也就是16。
(三) CTPN网络贡献
This section presents details of the Connectionist Text Proposal Network (CTPN). It includes three key contributions that make it reliable and accurate for text localization: detecting text in fine-scale proposals, recurrent connectionist text proposals, and side-refinement.
我们根据论文key contribution大致分成以下几个:
1⃣️ detecting text in fine-scale proposals 2⃣️ recurrent connectionist text proposals 3⃣️ side-refinement
1) detecting text in fine-scale proposals
这里作者主要介绍了基于faster-rcnn的思想,将文本区域切分成若干个长方形预选框,这里预选框的宽度固定为16个像素,高度从11~283像素变化(每次乘以1.4),也就是说k的值设定为10,通过下面代码可以看出我们的anchor设置大小。
heights = [11, 16, 23, 33, 48, 68, 97, 139, 198, 273]
widths = [16, 16, 16, 16, 16, 16, 16, 16, 16, 16]
2)side-refinement
这里是将我们预测出来的anchor连接成一个完整的文本线。作者在这里称做为side-refinement算法。其思想如下:
首先对于第i个text proposal,记为, 寻找其配对的邻居,记配对后的关系➡️, 这其中满足一下条件
1⃣️ 距离的长度在50个像素点以内,并且其score最大
2⃣️ 与在垂直方向的重合度必须大于0.7
接着,对进行反向寻找近邻,当其近邻也刚好是时,则和的文本线构建成功。
(五)损失函数

2. CRNN(Convolutional Recurrent Neural Network)
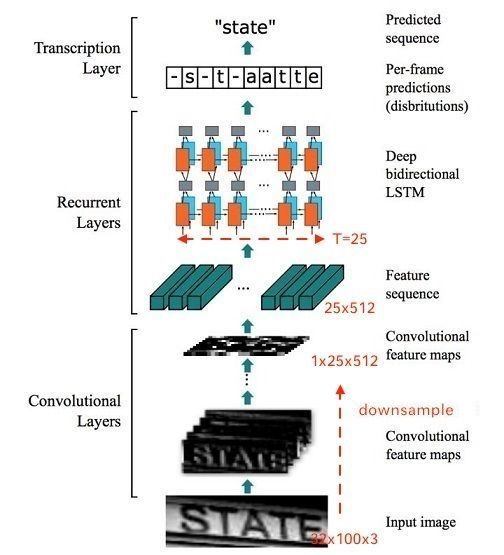
上面我们通过CTPN网络已经得出来了文本区域位置,此时我们需要将文本信息的crop image作为我们CRNN网络的输入, 如上图所示。
首先我们先输入一个一张图片,再经过卷积网络,注意此时的卷积网络的下采样的stride宽高不是一致的,这是为了适应我们的BI-LSTM网络。这是怎么理解的呢?比如说我通过卷积网络得到100×32(height×width)的feature map, 此时我的stride在宽度的下采样程度高于高度,因此经过几次下采样之后我们的feature map大小变为25×1, 并且通道数为512。此时我们将这个结果作为输如到Bi-LSTM中。
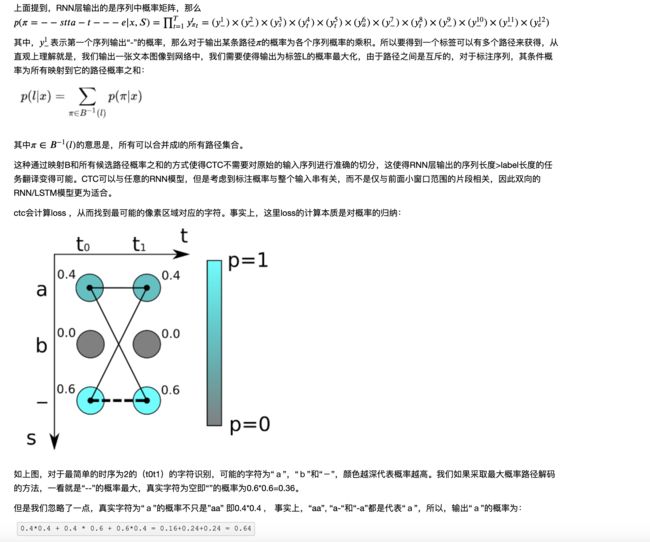
2. CTC(Connectionist Temporal Classification)
CRNN中需要解决的问题是图像文本长度是不定长的,所以会存在一个对齐解码的问题,所以RNN需要一个额外的搭档来解决这个问题,这个搭档就是著名的CTC解码。我们知道,CRNN中RNN层输出的一个不定长的序列,比如原始图像宽度为W,可能其经过CNN和RNN后输出的序列个数为S,此时我们要将该序列翻译成最终的识别结果。RNN进行时序分类时,不可避免地会出现很多冗余信息,比如一个字母被连续识别两次,这就需要一套去冗余机制,但是简单地看到两个连续字母就去冗余的方法也有问题,比如cook,geek一类的词,所以CTC有一个blank机制来解决这个问题。这里举个例子来说明
我们25×1的feaure 输入到LSTM中, 但是假如我的预测label为‘hello’, 那肯定会出现, 多个feaure unint表示一个字母,如:‘hhhhhhhheeeelllllloooooo’, 我们可以将重复的字母用blank填充, 如: -------h----h----l--l--o--。
这篇博客觉得解释的很形象

二、 pytorch代码实现与理解
参考
- 场景文本检测—CTPN算法介绍
- 【OCR技术系列之七】端到端不定长文字识别CRNN算法详解