参考资料:
standfore cs131 Lecture 13: k-means and mean-shi4 clustering
A review of mean-shift algorithms for clustering
斯坦福CS131-1718作业5
At the high level, we can specify Mean Shift as follows :
- Fix a window around each data point.
- Compute the mean of data within the window.
- Shift the window to the mean and repeat till convergence.
-
K-means
公式推导很通俗:K-means Clustering
将多种颜色汇集成几种

随机分配几个cluster centers,计算每个点跟这些cluster center的距离,然后选择最小的距离进行站队,重新根据站同一队的点计算均值得到新的cluster center,直到没有新的点重新换队。

问题:选择几个cluster centers?任意得到局部最优解而不是全局最优(可以多进行几次,然后投票得到结果)。
公式推导:
下图大意,我们首先定K,表示聚合的中心,用J来表示损耗函数,我们要将其降到最小,注意式中r的含义。在聚合点固定的时候,计算点离哪个比较近,选择站队,可以使得J减小。在站队固定的时候,根据导数的计算,可知战队的点的均值作为聚合点J最小。

程序大致流程:
预处理:
Kmeans函数输入的是一个矩阵,每一行是一个向量,原始图像有多少个点就有多少个向量。以一个3733633通道的彩色图片为例,需要转化为135399*3,其中135399代表原始图像的点数,3代表每个点的颜色空间的位置。然后还要转化为浮点数。
Mat image = imread("F:\\cv\\cv-pictures\\hands.jpg"); //373*363
Mat reshapedImage = image.reshape(1, image.cols * image.rows); //135399*3(代表有135399个,每个都对应颜色空间的一个值)
Mat reshaped_image32f;
reshapedImage.convertTo(reshaped_image32f, CV_32FC1, 1.0 / 255.0);
Kmeans:
iterals:是重新开始的次数,因为怕得到局部最优解,所以需要每次随机重新初始化。centers是计算出来的k个中心,labels的大小是135399*1,1代表是第几个center。
int k = 9;
int iterals = 1;
Mat labels; // 用来存放输入向量计算后对应的cluster的序号
cv::Mat centers; //cluster centers
TermCriteria criteria{TermCriteria::COUNT,100,1}; //迭代100次
kmeans(reshaped_image32f, k, labels, criteria, iterals, KMEANS_RANDOM_CENTERS, centers);
后处理:
将中心点转化为CV_8UC3,记住计算后的是浮点型的。
Mat centers_u8c3;
centers.convertTo(centers_u8c3, CV_8UC3, 255.0);
重新计算得到图像,新的图像只有对应centers的几种颜色了,
typedef Vec3b Pixel;
//typedef Point3_ Pixel;
Mat rgb_image(image.rows, image.cols,CV_8UC3);
MatIterator_ rgb_first = rgb_image.begin();
MatIterator_ rgb_end = rgb_image.end();
MatConstIterator_ labes_first = labels.begin();
while (rgb_first != rgb_end) {
Pixel& rgb = centers_u8c3.ptr(*labes_first)[0];
(*rgb_first) = rgb;
++labes_first;
++rgb_first;
}
最后结果:
颜色被规整化了,相近颜色只剩下一种,可以很轻松地划分区域

cluster是窗口名字的两倍,可以看到颜色越多越近。

-
特征空间(Feature Space)
我们上面的例子用的是三种颜色RGB的三维特征空间,如果是黑白图片,只有一维的特征空间。
特征空间为 texture

还可以是 空间加强度,这样的特征空间强加了空间维度,通常没有意义。
Clusters don’t have to be spatially coherent

-
怎么选择聚合点?
用验证集进行测试,一般情况下聚合点越多越好。
-
k-means优缺点


-
k-means具体实现
产生4堆数据

# Cluster 1
mean1 = [-1, 0]
cov1 = [[0.1, 0], [0, 0.1]]
X1 = np.random.multivariate_normal(mean1, cov1, 100)
# Cluster 2
mean2 = [0, 1]
cov2 = [[0.1, 0], [0, 0.1]]
X2 = np.random.multivariate_normal(mean2, cov2, 100)
# Cluster 3
mean3 = [1, 0]
cov3 = [[0.1, 0], [0, 0.1]]
X3 = np.random.multivariate_normal(mean3, cov3, 100)
# Cluster 4
mean4 = [0, -1]
cov4 = [[0.1, 0], [0, 0.1]]
X4 = np.random.multivariate_normal(mean4, cov4, 100)
# Merge two sets of data points
X = np.concatenate((X1, X2, X3, X4))
# Plot data points
plt.scatter(X[:, 0], X[:, 1])
plt.axis('equal')
plt.show()
K-means效果与实现

### Clustering Methods
def kmeans(features, k, num_iters=100):
""" Use kmeans algorithm to group features into k clusters.
K-Means algorithm can be broken down into following steps:
1. Randomly initialize cluster centers
2. Assign each point to the closest center
3. Compute new center of each cluster
4. Stop if cluster assignments did not change
5. Go to step 2
Args:
features - Array of N features vectors. Each row represents a feature
vector.
k - Number of clusters to form.
num_iters - Maximum number of iterations the algorithm will run.
Returns:
assignments - Array representing cluster assignment of each point.
(e.g. i-th point is assigned to cluster assignments[i])
"""
N, D = features.shape
assert N >= k, 'Number of clusters cannot be greater than number of points'
# Randomly initalize cluster centers
idxs = np.random.choice(N, size=k, replace=False)
centers = features[idxs]
assignments = np.zeros(N)
for n in range(num_iters):
distances_to_centers = []
### YOUR CODE HERE
for i in range(k):
ds = np.sum(np.square(features - centers[i]), axis=1, keepdims=True)
distances_to_centers.append(ds)
distances_to_centers = np.concatenate(distances_to_centers, axis=1)
assignments = np.argmin(distances_to_centers, axis=1)
new_centers = []
for i in range(k):
new_centers.append(np.mean(features[assignments == i],axis=0))
if np.allclose(centers,new_centers):
break
else:
centers = new_centers
### END YOUR CODE
assert np.size(assignments) == N,"返回的结果数量不对"
return assignments
-
HAC(hierarchical agglomerative clustering algorithm)
算法介绍具体看注释和代码,很简单
def hierarchical_clustering(features, k):
""" Run the hierarchical agglomerative clustering algorithm.
The algorithm is conceptually simple:
Assign each point to its own cluster
While the number of clusters is greater than k:
Compute the distance between all pairs of clusters
Merge the pair of clusters that are closest to each other
We will use Euclidean distance to define distance between two clusters.
Recomputing the centroids of all clusters and the distances between all
pairs of centroids at each step of the loop would be very slow. Thankfully
most of the distances and centroids remain the same in successive
iterations of the outer loop; therefore we can speed up the computation by
only recomputing the centroid and distances for the new merged cluster.
Even with this trick, this algorithm will consume a lot of memory and run
very slowly when clustering large set of points. In practice, you probably
do not want to use this algorithm to cluster more than 10,000 points.
Args:
features - Array of N features vectors. Each row represents a feature
vector.
k - Number of clusters to form.
Returns:
assignments - Array representing cluster assignment of each point.
(e.g. i-th point is assigned to cluster assignments[i])
"""
N, D = features.shape
assert N >= k, 'Number of clusters cannot be greater than number of points'
# Assign each point to its own cluster
assignments = np.arange(N)
centers = np.copy(features)
n_clusters = N
from scipy.spatial.distance import pdist
while n_clusters > k:
### YOUR CODE HERE
distances = pdist(centers)
matrixDistances = squareform(distances)
matrixDistances = np.where(matrixDistances != 0.0, matrixDistances, 1e10)
minValue = np.argmin(matrixDistances)
min_i = minValue // n_clusters
min_j = minValue - min_i * n_clusters
if min_j < min_i:
min_i, min_j = min_j, min_i
for i in range(N):
if assignments[i] == min_j:
assignments[i] = min_i
for i in range(N):
if assignments[i] > min_j:
assignments[i] -= 1
centers = np.delete(centers, min_j, axis = 0)
centers[min_i] = np.mean(features[assignments == min_i], axis = 0)
n_clusters -= 1
### END YOUR CODE
return assignments
-
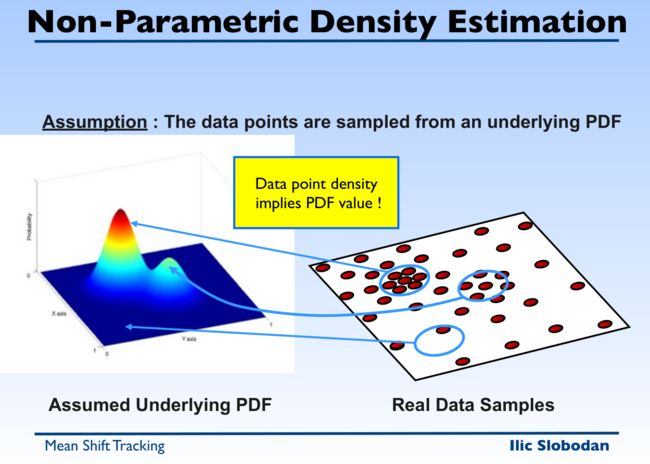
核密度估计(kernel density estimation)
quora回答?What is kernel density estimation?
An introduction to kernel density estimation
直方图估计概率分布的缺点:
1.不平滑
2.跟端点有关
3.跟柱子的宽度有关
不平滑
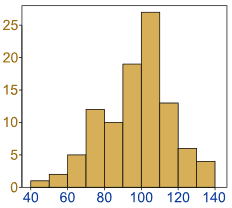
首先直方图是分段不变的,柱子边缘跟相邻柱子的边缘应该是要接近的,而不是跟所在柱子的另外一端一样。
端点
同样的数据,同样的间隔,因为端点不同,一个单峰的,一个是双峰的
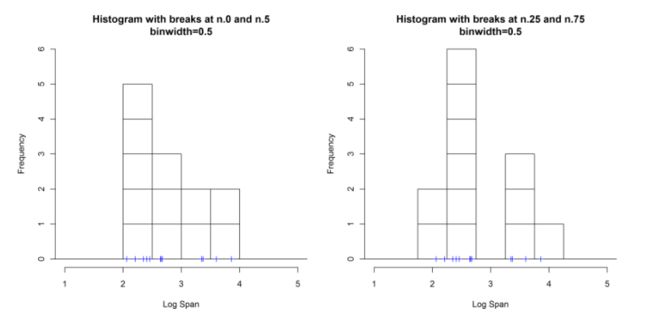
柱子宽度
显而易见
解决方案
为了解决上述问题,我们可以在之前直方图的基础上增加分辨率,得到下面更精细的结构,虽然还是不连续的。这叫做box-car内核,差不多就是平滑滤波。其他的一些内核也不过是平滑滤波的广义化。一般来说点附近会更大,而不是整个柱子都是一样大。

选择内核主要有两个参数:形状和带宽,带宽描述了曲线下降的速度,如果你使用的是平的内核,那么带宽就是其宽度,带宽经验上比形状更重要。
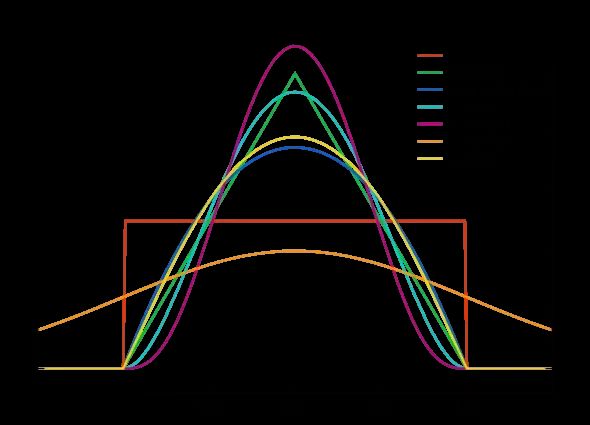

怎么选择合适的带宽?
看不懂...
-
Mean shift
需要有这篇文章前面的知识。
1. 大致介绍得很明白,但怎么移动没有说明白
2. Meanshift Algorithm for the Rest of Us (Python)
3. Introduction To Mean Shift Algorithm
基本操作
kmeans的点是固定的,聚集点不断地向点密集的地方移动,而Means shift是先计算KDE,然后点根据梯度的方向移动(梯度上升,直接到达梯度为0的点),聚集到几个点上。
Using Mean-Shift on Color Models 两种方法:
[Lecture 29: Video Tracking: Mean-shift]
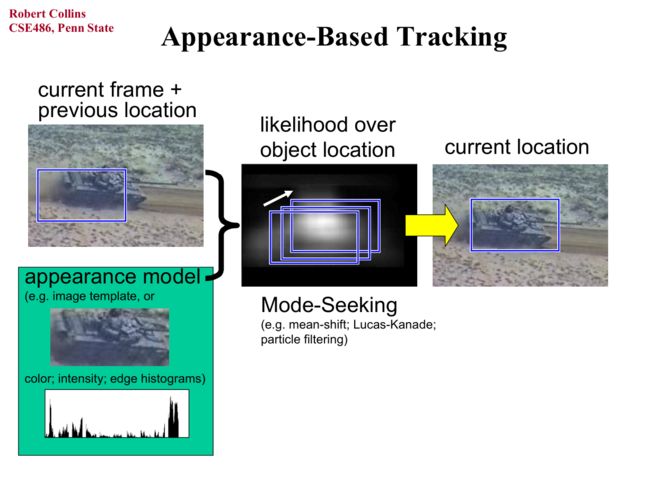

方法1:
基于mean-shift的跟踪主要是通过直方图的反向投影来获得目标在图像中位置的概率估计,从概率估计图中使用均值漂移到概率最大点。反向投影(backproject请看我另外一篇文章)会得到一张灰度图片,越亮的区域说明该区域的颜色在追踪的图像中占的比例越大,从而说明该区域为追踪区域的可能性越大(颜色上相关性比较大)。然后可能会阈值化?大于阈值的点说明极有可能为追踪区域的点,然后用均值漂移进行聚类,将点聚集在追踪区域。也可以不阈值化,将大小当作系数加到公式上,见下面。mean-shift就是用来追踪密集区域的。

下面公式的w(a)是上面说到的不阈值化,直接用参数。a是泛指所有的点,K(a-x)*(a-x)是梯度((a-x)是二次方求导出来的),下面公式推导就知道了。

??

应用:


方法2:
用直方图表示目标的颜色分布,然后用mean-shift找到直方图分布最相似的分布。具体可能是以每个点为中心,圈出一片区域,得到对应直方图,每个直方图计算出来一个向量,跟目标进行比较相似度(余弦相似性),然后就在图片的每个点上有一个对应的相似度。接下来用mean-shift了,找到系数比较大,分布比较密集的区域。

数学原理
最重要是要先看下本文的 核密度估计(kernel density estimation) 部分,
K是核函数,实践中有时也用下面两个近似,用一维的核函数相乘近似模拟多维(比如高斯一维相乘模拟高维,之前看到这样是要有两个维度独立的假设得到,同时一维相乘不能完全模拟高维,一维相乘可以得到圆,但是不能得到椭圆),或者用向量长度的函数。
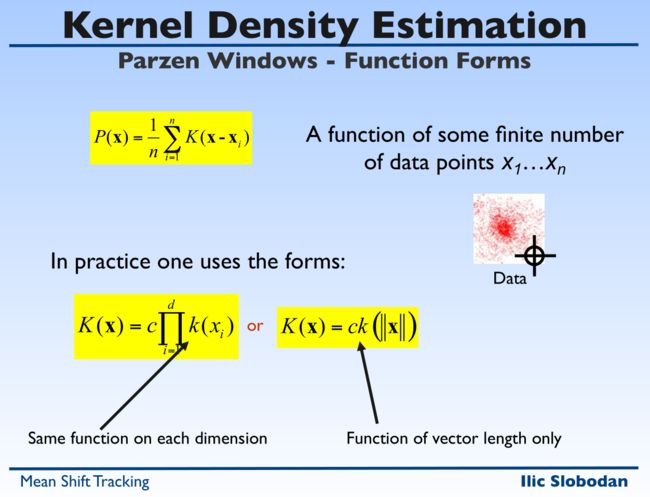
正经核函数

整篇文章的推导最容易看懂:
https://zhuanlan.zhihu.com/p/31183313

经过以上你应该可以看懂 这篇文章(Mean Shift Clustering)的程序了,只看更新的表达式。
for p in copied_points:
while not at_kde_peak:
p = shift(p, original_points)
def shift(p, original_points):
shift_x = float(0)
shift_y = float(0)
scale_factor = float(0)
for p_temp in original_points:
# numerator
dist = euclidean_dist(p, p_temp)
weight = kernel(dist, kernel_bandwidth)
shift_x += p_temp[0] * weight
shift_y += p_temp[1] * weight
# denominator
scale_factor += weight
shift_x = shift_x / scale_factor
shift_y = shift_y / scale_factor
return [shift_x, shift_y]