Druid io总体设计
1.Druid模块架构
1.1 Druid简介
最新版本的Druid采用了位图索引、字典编码、列式存储、倒排索引、压缩算法等关键技术,列式存储和倒排索引能加快查询的速度,而位图索引可以加快过滤和聚合的速度,采用字典编码则是可以减小空间占用,因此Druid的性能十分出色,理论上可以在毫秒内,完成海量的过滤和聚合,加速Olap分析过程的钻取操作。
多种数据的支持也是Druid的最重要的特点。与传统的Olap框架不一样的地方在于,他们大多采用的是批量导入静态数据进行分析的方式,而Druid兼容了实时流数据和静态数据,让不同的数据都能即席可查,实时索引过程中采了在HBase里面大放异彩的LSM(Long structure merge)-Tree(日志结构生成合并树)结构,使得Druid拥有极高的实时写入性能,同时利用内存映射机制,实现了实时数据的即席可查[1]。
另外Druid内部提供了丰富的分析API,在社区的大力支持下,Druid已经可以利用方解石进行类Sql的查询(有些功能还没有完全支持),使得Druid的可用性大大提高。
Druid的高可用性和高可拓展性也是一个很大的亮点,所有节点宕机都不会影响其他节点,以为Druid的节点都不与其他节点直接通讯,节点互不依赖,据有极高的容错和容灾性。同时拓展也十分的方便直接加节点就行了。
Druid IO的特性和历史:
自从Google的GFS、BigTable、MapReduce的三大论文发布以来,开源的大数据技术蓬勃发展,其中最具代表性的肯定就是Hadoop了吧,几乎就是Google的开源技术实现,现在Hadoop有着庞大的家族。Hadoop主要有两架马车,一架是解决海量文件存储的HDFS,另一架就是分布式计算框架MapReduce。Hive就是基于HDFS和MapReduce技术实现的Hadoop数据仓库,而Hbase则是基于HDFS技术实现的K-V列式数据库,之所以没用MapReduce完全是跟产品的定位有关,因为MapReduce处理机制并不能保证时效性,虽然有Spark-Sql这个最优化MapReduce解,但是对于一个数据库来说,还是太慢了。Hive和Hbase的出现虽然解决了海量数据的存储和查询问题,但是对于Olap领域的多维数据分析其实并没有很好的解决,虽然Apache Kylin采用将预Cube的数据放到Hbase中来解决Olap的时效性问题,但是Apache Kylin的并发稳定性和实时数据领域的Olap还是没有很好的解决方案(虽然像Google这种技术性很强的公司在内部有自己的一套框架,但是人家不开源也没有办法)。
HDFS虽然解决了海量数据的存储问题,稳定性和容错性都非常的高,但是对于查询中需求的随机读取性能并不高,于是乎工程师们设计了一种全新的数据结构(segment),能够满足Olap的高时效的要求,采用了位图索引、字典编码、列式存储、倒排索引、压缩算法等关键技术,最重要是Olap基本上都是根据时间轴分组,而segment正好利用了这一点,将其设计为一个时序结构,查询时通过时间跨度来快速找到对应的segment,大大降低了搜索和读取文件的范围,同时也避免使用了时效性很差的Map/Reduce批处理技术。而采用这种时序结构的segment又完美的和实时流数据相结合,使其可以实现实时流数据的即席查询,解决了Kylin的不足。设计Druid的工程师们,利用Zookeeper给集群的每个节点都实现了高稳定的特点,整个集群又十分的稳定,每个节点宕机挂掉都不会影响其他的节点,从而保证集群的高稳定性。
Druid于2011年开始研发设计,当时的Nosql数据库在人们看来都不能完全解决人们的需求,所以Druid从设计之初就有高并发、高稳定性、可拓展、速度快、兼容性强的特点,内部采用精心设计的segment数据结构,与Olap完美配合[1]。
如果你有海量的数据(PB级别的数据),对高并发、高稳定性、可拓展、速度快、兼容性有很高的要求,又想做实时数据分析,同时有需要对数据进行高速的聚合和查询。那么Druid真的是再适合你不过了,现在Druid部署已经扩展到数万亿次事件和数以PB级数据,大量的实际运用,已经证明了它在流式Olap领域的取得了巨大的成功。
1.2 Druid组件
1.2.1 Broker节点
Broker Node类似于Spring Mvc中的Controler层,是整个集群中查询的入口,Broker Node会定期的同步Zookeeper中的segment元信息,用来获取segment在每个Historical Node(除了实时时间窗口之内的数据)中的分布情况,Broker节点根据查询协议中的dataSource和interval以及Zookeeper集群里面的timeline,将请求转发到对应的若干个Historical节点(如果是实时的数据可能会转发给Real-Time节点),Historical节点根据查询协议在segment里面取出满足查询条件的数据,然后将数据发送给Broker节点(本地默认使用LRU缓存,所有的Broker节点共享一个memcached缓存,只有本地缓存和memcached缓存都未命中的情况下,才会查询对应的数据节点),broke节点接受到数据经过merge合并操作后放回到用户[10]。
1.2.2 Historical节点
Historical Node负责从Deep Storage下载Segment到本地,Historical Node不与其他的Historical Node通信,也不与Druid集群中的其他类型的节点进行通信,它只定期到Zookeeper对应的目录下获取任务,并同步到Zookeeper,Historical Node下载的都是历史segment(在实时摄入任务的时间窗口之外)
集群中的Coordinator Node会定期到元数据库中去同步元数据(集群的元数据库一般是mysql这样的关系型数据库)来获取由Index Service生成的新的segment,一旦有新的segment生成Coordinator Node会根据算法在集群的Historical Node列表里面选出一个,然后将该待加载的segment的信息放在Zookeeper对应的Historical Node的 load队列目录下,Historical Node会定期的扫描Zookeeper对应的目录。一旦Historical Node在目录中捕获新的加载任务,会首先在本地扫描,看有无对应的segment数据(为了防止宕机恢复后重复加载的问题,以及一些其他可能会导致重复加载的问题),如果Historical Node没有在本地找到对应的segment,就会将Zookeeper中的segment的元信息下载到本地,然后利用该元信息去Deep Storage(一般在实际生产环境是HDFS)中下载该segment到本地中来,然后利用JAVA内存映射机制,映射到内存中来,当下载完成后,Zookeeper中的目录状态会声明为已完成,这样一个新生成的segment就可以被高速查询了。
1.2.3 Coordinator节点
Coordinator Node负责管理Druid集群里面的segment,但是它在集群里面一般只存在一个,不像数据节点和Broker节点可以存在很多,如果存在多个Coordinator Node,Zookeeper会根据选举算法(一致性算法避免脑裂)产生一个Leader,其余的当Follower,当Leader遇到问题宕机时,Zookeeper会在Follower中再次选取一个Leader,从而维持集群segment的正常服务。就算遇到一种最可怕的情况,集群中所有的Coordinator Node都宕机停止服务了,整个集群依然可以对外提供查询能力,已经加载到Historical Node的segment依然可以被查询到,只不过整个集群的segment都不会有任何变化了。一旦有新的Coordinator Node上线,整个集群就会立即恢复加载segment的能力。
Coordinator Node管理segment的职责主要包括,在Zookeeper对应的目录中给Historical Node下达加载新的segment的指令、在Zookeeper对应的目录中给Historical Node下达丢弃segment的指令、在Zookeeper对应的目录中给Historical Node下达加载副本segment的指令、选择合适的Historical Node去加载新的segment维持集群的负载均衡(默认每分钟同步一次Zookeeper,来获取整个集群segment的加载情况,来确定下一步要分发的指令,如果单个Historical Node负载过大,Coordinator Node会及时的调整,让别的Historical Node去加载新的segment,但是为了避免这种这种情况,Coordinator Node会将Historical Node列表中的剩余容量进行倒排,剩余容量大的Historical Node会优先加载新segment,从而保持segment的负载均衡,当然排序的算法可以根据实际生产环境的情况进行自定义编写)。
有的时候Historical Node会宕机离线,这个时候Coordinator Node会将该Historical Node上所有加载的segment当作失效,会让集群中其他的Historical Node去加载失效的segment,这样的策略看上去好像没有问题,但是在实际生产环境中,很多机器会临时的重启,服务重启的时间间隔会很短,如果这种情况让别的Historical Node去加载该Historical Node已经加载的所有segment无疑会做很多无用功,同时整个集群的网络负载会加重不少。所以Coordinator Node 会为segment设置一个lifetime,在lifetime内,如果该segment重新出现在集群中,那么就不会让其他的Historical Node去加载这个segment,如果过了 lifetime还没重新上线,那么Coordinator Node会让集群中其他的Historical Node去加载这个segment。
1.2.4 Indexing Service
Indexing Service顾名思义就是指索引服务,分为Ingest阶段 、Persist阶段、 Merge阶段 、Handoff阶段 。在实际生成索引服务生成segment的过程中,由Overlord Node接收加载任务,然后生成索引任务(Index Service)并将任务分发给多个MiddleManager节点,MiddleManager节点根据索引协议生成多个Peon,Peon将完成数据的索引任务并生成segment,并将segment提交到分布式存储里面(一般是HDFS),然后Coordinator节点感知到segment生成,给Historical节点分发下载任务,Historical节点从分布式存储里面下载segment到本地。
Overlord
Overlord Node负责segment生成的任务,并提供任务的状态信息,当然原理跟上面类似,也在Zookeeper中对应的目录下,由实际执行任务的最小单位在Zookeeper中同步更新任务信息,类似于回调函数的执行过程。跟Coordinator Node一样,它在集群里面一般只存在一个,如果存在多个Overlord Node,Zookeeper会根据选举算法(一致性算法避免脑裂)产生一个Leader,其余的当Follower,当Leader遇到问题宕机时,Zookeeper会在Follower中再次选取一个Leader,从而维持集群生成segment服务的正常运行。Overlord Node会将任务分发给MiddleManager Node,由MiddleManager Node负责具体的segment生成任务。
MiddleManager
Overlord Node会将任务分发给MiddleManager Node,所以MiddleManager Node会在Zookeeper中感知到新的索引任务。一但感知到新的索引任务,会创建Peon(segment具体执行者,也是索引过程的最小单位)来具体执行索引任务,在多线程环境中,一个MiddleManager Node会运行很多个Peon的实例。
Peon
Peon(segment具体执行者,也是索引过程的最小单位),所有的Peon都会在Zookeeper对应的目录中实时更新自己的任务状态。
1.2.5 Real-Time 节点
在最新的Druid版本中,已经不存在单独的Real-Time Node的概念,但是它并没有消失,而是整合到了其他的服务中,功能还是一样的。在Druid流式摄入中,提供了两种方式,一种是Push,另一种是Pull。
Pull 顾名思义就是拉,与Kafka的push-and-pull模式完美配合,我们只需要在Kafka对应的topic写入数据,Druid根据自己的情况,到合适的时间到对应的topic里面pull出数据。
Push的意思就是推,这个时候Druid不能据自己的情况,到合适的时间去取出数据,而是数据会直接推入Druid中,但是如果Druid消费不及时可能会导致数据丢失,需要做好容错机制,启用这种模式需要Tranquility,Tranquility可以连接流式数据。
2.1 Druid io Demo项目架构
2.1.1查询流程
查询流程图如图2-1所示。
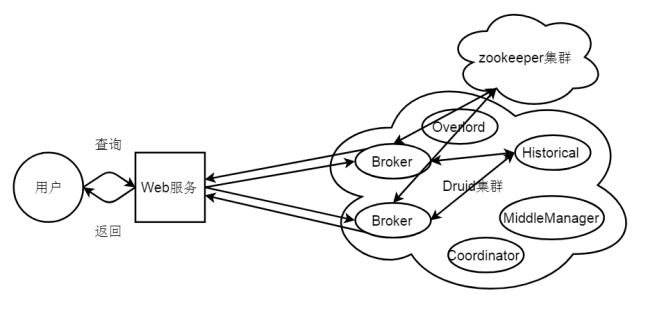
本项目主体采用Druid为内核,spring boot web框架为入口,接收外部用户的请求,当Web服务接收到用户的查询请求,会在在服务内部将查询协议进行转化,然后将查询协议转发到Druid集群的多个Broker节点中的一个(轮转算法),Broker节点根据查询协议中的dataSource和interval以及Zookeeper集群里面的timeline,将请求转发到对应的若干个Historical节点(如果是实时的数据可能会转发给Real-Time节点),Historical节点根据查询协议在segment里面取出满足查询条件的数据,然后将数据发送给broker节点,broke节点接受到数据经过merge合并操作后放回到用户。
2.1.2静态文件导入流程
静态文件导入流程图如图2-2所示。
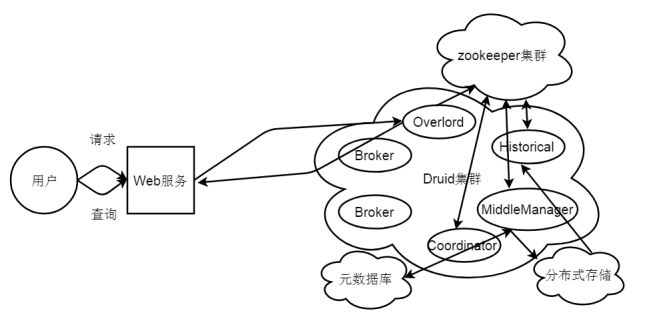
图2-2静态文件导入流程图
当Web服务接收外部用户的静态文件导入的请求时,会接收用户配置好的conf文件和data文件,然后将配置文件转发到Druid集群的多个Overload节点中的一个(轮转算法)同时将data数据上传(也可以不上传通过远程ftp),Overload节点根据配置文件中相关配置信息,生成索引任务(Index Service)并将任务分发给多个MiddleManager节点,MiddleManager节点根据索引协议生成多个Peon,Peon将完成数据的索引任务并生成segment,并将segment提交到分布式存储里面(一般是HDFS),然后Coordinator节点感知到segment生成,给Historical节点分发下载任务,Historical节点从分布式存储里面下载segment到本地,导入的数据就可以被查询了。
2.1.3数据流导入流程
数据流导入流程图如图2-3所示。
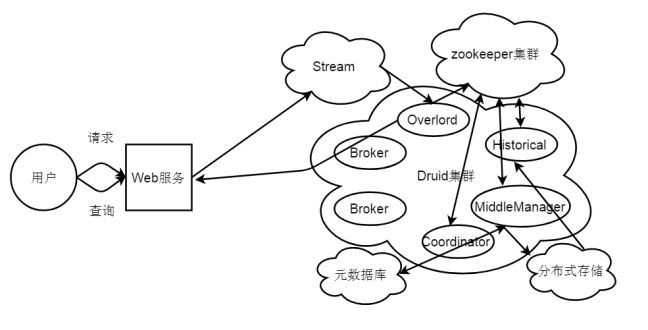
图2-3数据流导入流程图
当Web服务接收外部用户的数据流导入的请求时,会接收用户填写的dataSource和data(一般是json格式)数据,然后将dataSource和data解析并转发到Stream,同时Stream会将流式data数据push到Druid集群的Overload节点,Overload节点根据Server配置文件中相关配置信息,生成索引任务(Index Service)并将任务分发给多个MiddleManager节点,MiddleManager节点根据索引协议生成多个Peon,Peon将完成数据的索引任务并生成segment,并将segment提交到分布式存储里面(一般是HDFS),然后Coordinator节点感知到segment生成,给Historical节点分发下载任务,Historical节点从分布式存储里面下载segment到本地,导入的数据就可以被查询了。(数据流Index Service还未完成之前,可以通过Real-Time节点对外提供查询能力)。
2.1.4 Kafka数据流导入流程
Kafka数据流导入流程图如图2-4所示。
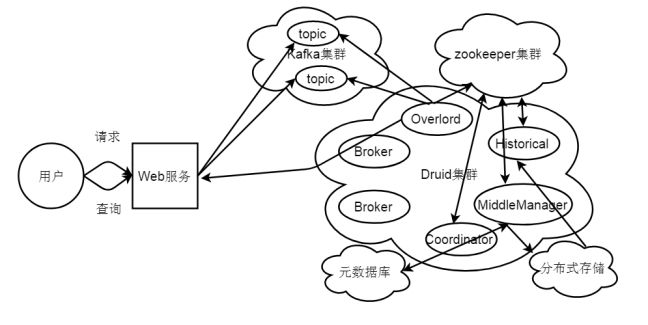
图2-4Kafka数据流导入流程图
当Web服务接收外部用户的Kafka数据流导入的请求时,会接收用户填写的topic和data(一般是json格式)数据,然后将topic和data解析,服务内部将data数据写入Kafka集群对应的topic里面,Overload节点根据Kafka配置文件中相关配置信息,从不同发的topic里面pull数据,然后生成索引任务(Index Service)并将任务分发给多个MiddleManager节点,MiddleManager节点根据索引协议生成多个Peon,Peon将完成数据的索引任务并生成segment,并将segment提交到分布式存储里面(一般是HDFS),然后Coordinator节点感知到segment生成,给Historical节点分发下载任务,Historical节点从分布式存储里面下载segment到本地,导入的数据就可以被查询了。(数据流Index Service还未完成之前,可以通过Real-Time节点对外提供查询能力)。