简介
在上一篇文章《手写一个全连接神经网络用于MNIST数据集》中,我们使用少于100行代码实现了一个3层的全连接网络,并且在MNIST数据集上取得了95%以上的准确率。相信读过这篇文章的读者对全连接网络如何使用梯度下降算法来学习自身的权值和偏置的原理已经有所了解(如果你没读过,建议先看一下再阅读本文)。但是上篇文章留下了一个问题,就是我们没有讨论如何计算损失函数的梯度,在本文中,我会详细解释如何计算这些梯度。
本文会涉及到较多的数学公式,要求读者了解微积分的基本知识,尤其是链式法则。
反向传播概览
先引用一下维基百科中对于反向传播的定义:
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
反向传播的核心是对损失函数关于任何权重(或偏置)的偏导数(或)的表达式。这个表达式告诉我们在改变权重和偏置时,损失函数变化的快慢。由于是一个叠加了多种运算的多元函数,所以对网络的某一层的某一个权重的偏导数可能会变得很复杂,不过这也让我们直观的看到了某一个权重的变化究竟会如何改变网络的行为。
神经网络参数的表示
通过上一篇文章,我们知道神经网络是由多个S型神经元构成的,每个S型神经元有输入,权重,偏置,以及输出。那么当它们组合在一起形成复杂的神经网络结构的时候,参数会变得异常的多。这个时候我们需要先约定一下如何来表示这些参数,以便数学描述和基于矩阵的运算。先以一个简单的神经网络结构为例:

可以看到上述网络一共有3层,第一层是输入层,第二层是隐层,第三层是输出层。接下来我会在这张图上标注权重 ,偏置 ,激活值 等参数,并且会引入若干个符号来表示这些参数。

令表示从层的个神经元到层的个神经元上的权重。这个表示看起来有点奇怪,也不容易理解,因为这个表达式里面虽然带有一个,但是实际上它表示的是第层到第层的之间的权重关系。以上图的蓝色箭头所指的线段为例,代表的含义是,第2层的第4个神经元到第3层的第2个神经元之间的权重。
其实如果你仔细看过上一篇文章中的代码,你会发现权重向量和偏置向量只是第二层和第三层才会有,而输入层是没有这些参数的。在上图中,我们是用带箭头的线段来表示的权重,故代表的并不是第层指出去的线段,而指的是第层指向它的线段,这个有点违反直觉,但是接下来你会看到这么做的好处。
令表示在第层的第个神经元的偏置,如上图表示第2层的第3个神经元上的偏置。
令表示在第层的第个神经元的激活值,如上图代表第2层的第4个神经元上的激活值。
有了这些表示,层的第个神经元的激活值就和层的激活值通过方程关联起来了:
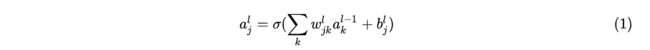
其中求和是在层的全部个神经元之间进行的。为了用矩阵的形式重写这个表达式,我们对每一层都定义了一个权重矩阵。权重矩阵的元素是连接到第层的神经元的权重(即指向第层神经元的全部箭头)。同理,对每一层定义一个偏置向量,向量中的每一个元素就是。最后定义每一层的激活向量,向量中的每个元素是。
也许你还不明白这个怎么计算的,让我以上图的来描述一下它的计算过程。我用橙色的线段来代表所有指向第2层第4个神经元的权重,可以看到一共有3条线段指向了它,其代表的权重分别是,,,由于这是第一层,故它的激活向量就是输入向量,代表的是这个神经元的偏置值,那么完整的计算过程描述如下:
上面的公式(1)还是太麻烦了,我们注意到(1)式中的参数、、其实都是向量,故我们可以将其改写成矩阵形式,如下:
这个式子看着更加简洁,它描述了第层的激活值与第层的激活值之间的关系。我们只需要将本层的权重矩阵作用在上一层的激活向量上,然后加上本层的偏置向量,最后通过函数,便得到了本层的激活向量。
如果将(2)式写的更详细一点,其实我们是先得到了中间量,然后通过函数。我们称为第层神经元的带权输入。故为了本文后面描述方便,我们也会将(2)式写成以下形式:
注意是一个向量,代表了第层的带权输入。它的每一个元素是,其中就是第层的第个神经元的激活函数的带权输入。
注意,在本文中,只带了上标而没有带下标的表达式,都是指的向量。
损失函数
还记得我们在上一篇文章中,使用了均方差损失函数,定义如下:其中是训练样本的总数,求和运算遍历了每个训练样本,是每个样本对应的标签,代表网络的层数,代表的是输入为时网络输出的激活向量(在MNIST任务中,输出是一个10维的向量)。
在上式中,对于一个特定的输入样本集,和都是固定的,所以我们可以将看做是的函数。
本文将会继续使用此损失函数来描述如何进行反向传播算法的应用。
Hadamard乘积
反向传播算法基于常规的线性代数运算 —— 诸如向量加法,向量矩阵乘法等。但是有一个运算不大常⻅。特别地,假设和是两个同样维度的向量。那么我们使用来表示按元素的乘积。所以的元素就是。举个例子如下:

这种类型的按元素乘法有时候被称为Hadamard乘积,具体定义可以参考百度百科。
反向传播
定义神经元误差
反向传播其实是对权重和偏置变化影响损失函数过程的理解,最终的目的就是计算偏导数和。为了计算这些值,我们首先引入一个中间量,我们称之为在第层的第个神经元上的误差。
为了理解误差是如何定义的,假设在神经网络上有一个调皮⻤:

这个调皮鬼在第 层的第 个神经元上。当输入进来的时候,这个调皮鬼对这个输入增加了很小的变化 ,使得神经元输出由原本的 变成了 。这个变化会依次向网络后面的层进行传播,最终导致整个损失函数产生 的变化(具体可以参考全微分的定义)。
现在加入这个调皮鬼改邪归正了,并且试着帮你优化损失函数,它试着找到可以让损失函数更小的 。假设 有一个很大的值,或正或负。那么这个调皮鬼可以通过选择适当的 来降低损失函数的值。相反,如果 接近0,那么无论怎么调整 都不能改善太多损失函数的值。因此,在调皮鬼看来,这时神经元已经接近最优了。所以这里有一种启发式的认识, 可以认为是神经元误差的度量。
按照上面的描述,我们定义第层的第个神经元上的误差为:
反向传播的四个方程
反向传播基于4个基本方程,这些方程指明了计算误差和损失函数梯度的方法。先列举出来:

1. 输出层误差的方程
结合(3)式,我们简单证明一下第一个方程: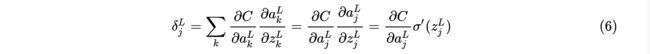
因为上式中的求和是在输出层的所有个神经元上运行的,由于这里是求损失函数对第层的第个神经元的输出激活值求导,故当都为0。
上式右边第一个项表示损失函数随着输出激活值的变化而变化的速度。假如不依赖特定的神经元,那么就会比较小,这也是我们期望的效果。右边第二项表达的是在激活函数在处的变化速度。
对于第一项,它依赖特定的损失函数的形式,如果我们使用均方差损失函数,那么其实很容易就可以算出来,如下:

如果我们令代表损失函数对激活值向量的偏导数向量,那么(6)式可以被写成矩阵的形式:
(7)式就是反向传播4个方程中的第一个方程。对于均方差损失函数,,所以(7)式可以写成如下形式:
写成上述向量的形式是为了方便使用numpy之类的库进行矩阵计算。
2. 使用下一层的误差来更新当前层的误差
第一个方程描述了输出层的误差,那么如何求得前一层的误差呢?我们还是可以从(5)式出发,对其运用链式法则,如下:
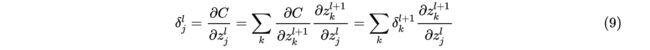
又根据上文,我们知道,,因此可以得到:
上式对微分的结果如下:

其中代表第层的权重矩阵的转置。这个公式看起来挺复杂,但是每一项都有具体的意义。假如第层的误差是,当我们使用同一层的转置权重矩阵去乘以它时,直观感觉可以认为它是沿着网络反向地移动误差,这给了我们度量在第层输出的误差方法(还记得上文,我们使用带箭头的线段来表明权重么,这里这么做,相当于把第层第个神经元指向第层的所有神经元的箭头线段全部逆向了)。
接着我们进行Hadamard乘积运算,这会让误差通过第层的激活函数反向传递回来,并给出在第层的带权输入误差。
我估计你看到这里会很懵逼,我当时学习的时候也是非常迷惑,感觉脑子一团糟,不过我将会以第二层第4个神经元的误差为例,来展示误差的反向传播过程,根据式(12),可以得出以下计算过程:
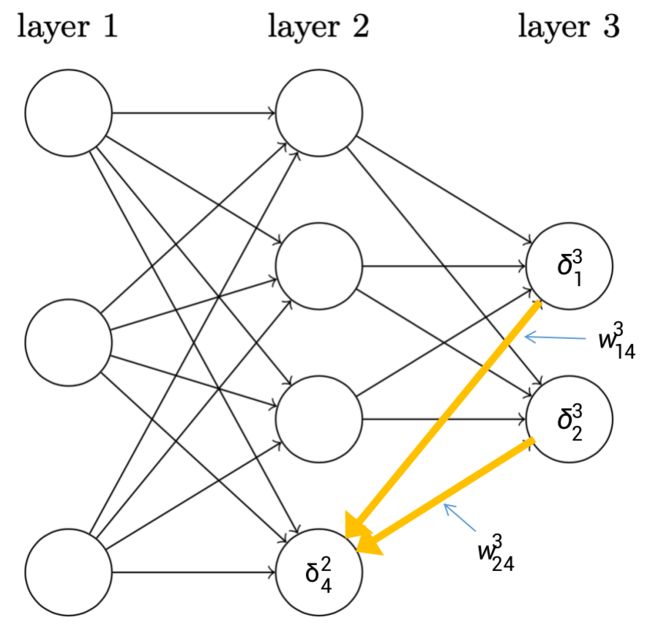
其实这个也很符合直觉,因为第2层第4个神经元连接到了第3层的全部神经元,故误差反向传播的时候,应该是与其连接的所有神经元的误差之和传递给此神经元。
有了前两个方程之后,我们就可以计算任何层的误差。首先使用方程(7)计算当前层误差,然后使用式(13)来计算得到,以此类推,直到反向传播完整个网络。
3. 损失函数关于任意偏置的变化率
由上面内容可知,,对求偏导得。则有:
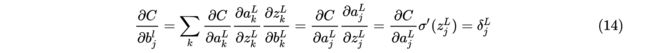
故可知,误差和偏导数完全一致。
写成向量的形式如下:
其中和偏置都是针对同一个神经元。
4. 损失函数对于任意一个权重的变化率
由上面内容可知,,对求偏导得。又:
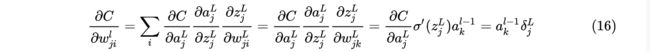
其中是上一层的激活输出向量,是当前层的误差,可以使用下图来描述:
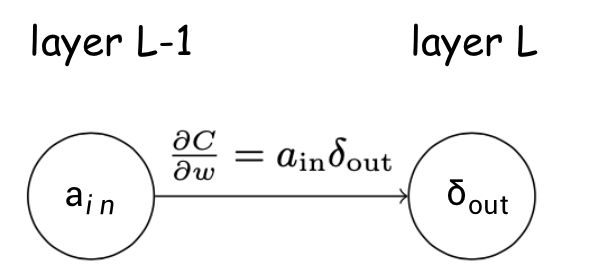
上图说明,当上一层的激活值 很小的时候,梯度 也会很小,这意味着在梯度下降算法过程中,这个权重不会改变很多。这样导致的问题就是来自较低激活值的神经元的权重学习会非常缓慢。
另外观察一下前两个方程,可以看到它们的表达式中都包含 ,即要计算 函数的导数。回忆一下上一篇文章中Sigmoid函数的图像,可以看到,当输入非常大或者非常小的时候, 函数变得非常平坦,即导数趋近于0,这会导致梯度消失的问题,后面会专门写文章讨论。
总结一下,如果输入神经元激活值很低,或者神经元输出已经饱和了,那么权重学习的过程会很慢。
反向传播的算法流程
反向传播的4个方程给出了一种计算损失函数梯度的方法,下面用算法描述出来:
- 输入,为输入层设置对应的激活值。
- 前向传播: 对每一层,计算相应的权重输入和。
- 输出层的误差: 计算向量
- 误差反向传播:对于每一层,计算
- 输出: 损失函数的梯度分别由 和 得出。
很多人在一开始学习的时候,分不清梯度下降和反向传播之间的关系,我最开始也是。不过从上面的流程中应该可以了解一点。梯度下降法是一种优化算法,中心思想是沿着目标函数梯度的方向更新参数值以希望达到目标函数最小(或最大)。而这个算法中需要计算目标函数的梯度,那么反向传播就是在深度学习中计算梯度的一种方式。
代码解析
这里只列举了代码中反向传播部分,若需完整代码,请在https://github.com/HeartbreakSurvivor/FCN下载。
我对代码中关键步骤,都添加了详细的注释,读者再对着文章内容,应该能够看明白。
def update_mini_batch(self, mini_batch, eta):
"""
通过小批量随机梯度下降以及反向传播来更新神经网络的权重和偏置向量
:param mini_batch: 随机选择的小批量
:param eta: 学习率
"""
nabla_b = [np.zeros(b.shape) for b in self._biases]
nabla_w = [np.zeros(w.shape) for w in self._weights]
for x, y in mini_batch:
# 反向传播算法,运用链式法则求得对b和w的偏导
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
# 对小批量训练数据集中的每一个求得的偏导数进行累加
nabla_b = [nb + dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw + dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
# 使用梯度下降得出的规则来更新权重和偏置向量
self._weights = [w - (eta / len(mini_batch)) * nw
for w, nw in zip(self._weights, nabla_w)]
self._biases = [b - (eta / len(mini_batch)) * nb
for b, nb in zip(self._biases, nabla_b)]
def backprop(self, x, y):
"""
反向传播算法,计算损失对w和b的梯度
:param x: 训练数据x
:param y: 训练数据x对应的标签
:return: Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``.
"""
nabla_b = [np.zeros(b.shape) for b in self._biases]
nabla_w = [np.zeros(w.shape) for w in self._weights]
# 前向传播,计算网络的输出
activation = x
# 一层一层存储全部激活值的列表
activations = [x]
# 一层一层第存储全部的z向量,即带权输入
zs = []
for b, w in zip(self._biases, self._weights):
# 利用 z = wt*x+b 依次计算网络的输出
z = np.dot(w, activation) + b
zs.append(z)
# 将每个神经元的输出z通过激活函数sigmoid
activation = sigmoid(z)
# 将激活值放入列表中暂存
activations.append(activation)
# 反向传播过程
# 首先计算输出层的误差delta L
delta = self.cost_derivative(activations[-1], y) * sigmoid_prime(zs[-1])
# 反向存储 损失函数C对b的偏导数
nabla_b[-1] = delta
# 反向存储 损失函数C对w的偏导数
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# 从第二层开始,依次计算每一层的神经元的偏导数
for l in range(2, self._num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
# 更新得到前一层的误差delta
delta = np.dot(self._weights[-l + 1].transpose(), delta) * sp
# 保存损失喊出C对b的偏导数,它就等于误差delta
nabla_b[-l] = delta
# 根据第4个方程,计算损失函数C对w的偏导数
nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())
# 返回每一层神经元的对b和w的偏导数
return (nabla_b, nabla_w)
参考
- http://neuralnetworksanddeeplearning.com/chap2.html
- https://zh.wikipedia.org/wiki/%E5%8F%8D%E5%90%91%E4%BC%A0%E6%92%AD%E7%AE%97%E6%B3%95
- https://baike.baidu.com/item/%E5%93%88%E8%BE%BE%E7%8E%9B%E7%A7%AF/18894493?fr=aladdin
- https://www.jianshu.com/p/25f0139637b7