基于迭代模糊核修正的盲超分辨方法

本文解读一篇由港中文(深圳)与哈工大合作发表在CVPR2019的超分辨方向的论文,该工作与几篇近年的文章密切相关,相关部分我已在文中做了必要的说明和解释,更多细节可点击此处深入了解。
1.研究动机
超分辨研究旨在用低分辨图片恢复其对应的高分辨图片,它的反过程是图像从高分辨到低分辨的降级或者说退化,这一过程一般被抽象为:
其中LR代表低分辨图像,HR代表高分辨图像。该模型中有3个重要的组件:1) 模糊核k. 2)下采样操作s. 3)加性噪声n。低分辨图像可以看做低分辨图像被模糊核k做卷积之后再经下采样和噪声干扰后得到。现有的大多数超分辨方法都假设模糊核是已知的、固定的,甚至为了简化问题直接舍去,然而真实场景下的模糊核往往是未知而又复杂的。正确的模糊核估计对于超分方法至关重要,模糊核的假设偏差会使超分模型的性能大幅下降,产生过平滑或过锐利的结果,如图1所示。
预测本就未知的模糊核是一个病态的问题,直接预测的难度相当大。为此,作者提出了一种迭代式的预测方法IKC(Iterative Kernel Correction),该方法用超分辨的中间结果修正模糊核k,并重复多次直至收敛,图2的实验结果表明了多次迭代的优越性。

该论文的工作可总结为以下两点:
提出了一个迭代式的模糊核预测框架IKC
提出一种能够处理多种模糊核的新型超分模型SFTMD
2.方法
2.1 IKC整体框架
IKC框架由3部分组成,分别是:
超分辨模型F: 输入低分辨图片和模糊核,输出超分图片
预测器P: 输入低分辨图片,输出初始的模糊核
修正器C: 输入当前epoch的模糊核与超分辨图片,输出模糊核的修正残差
为了在超分模型中考虑模糊核与噪声的影响,【文献1】(本文作者所属团队之前的工作)提出了一种维度扩张方法,可以将模糊核与噪声特征变换成与输入图像大小相同的特征图,方便在CNN中使用,其过程如图3所示。实验证明该方法是有效的,计算性能也不错。
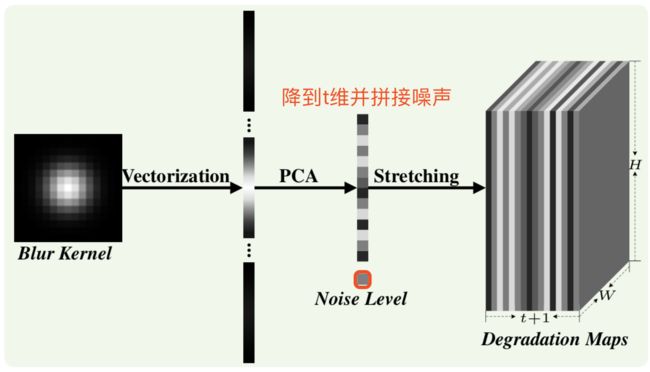
为了简化模糊核的预测和计算过程,作者参考了【文献1】的方法对模糊核空间进行PCA降维,用降维后的向量h表征原始的模糊核k,该过程可描述为:

作者使用h表征模糊核k,使用维度扩张方法将其结合到网络中。其中,初始的模糊核表征由预测器P生成,并据此产生第一轮的超分图像:

此后每一步均按下述过程迭代:

其中,第一个式子表示修正器C将根据上一轮的超分结果和模糊核预测核的修正量,第二个式子给出新的核,第三个式子利用新的核产生超分图像。当迭代循环至修正量\Delta hΔh足够小,表明对核的预测已足够准确,此时便可停止迭代。在本文中,超分模型F、预测器P和修正器C都是参数化的神经网络。
2.2 超分辨模型
SRMD是一个能够处理多种模糊核的超分辨网络,作者对它的缺点进行了改进并提出SFTMD网络,它们的架构如下图


网络设计的核心问题是如何有效利用模糊核的信息,SFTMD通过在卷积层之间插入SFT层实现这一目的。SFT层是【文献2】提出的一种将先验信息整合进CNN的一种方法,它把先验信息对特征图的影响建模为仿射变换,仿射变换可以看做缩放、平移、旋转、翻转和剪切等基本变换的复合体。在SFTMD中,先验信息指的是模糊核的特征图H,此时SFT层可表示为:
其中表示逐元素乘积、和分别表示缩放参数和平移参数,它们由小型的CNN学习产生,详见图5。
对比SRMD与SFTMD,二者主要有以下4点不同:
SFT的网络主体架构从单纯的CNN升级到残差网络(采用了【文献3】中的SRResNet网络骨架)
SFTMD的模糊核是学习得来的(Blind SR),而SRMD的模糊核是输入时指定的(Non-Blind SR)
SFTMD中模糊核会输入到每个中间层,而在SRMD中只会输入到第一层
SRMD使用卷积同时处理输入图像和降级图,而SFTMD使用一个子分支建模降级图的影响,并通过仿射变换影响超分辨过程。
第3、4点是SFTMD针对SRMD的局限性而做的改进。对于第3点,由于降级图对卷积层的影响会随网络的加深而越来越小,所以SFTMD将模糊核的信息输入到多个中间层来解决这个问题。对于第4点,由于模糊核特征图本身的信息与图像无关,所以将图像通道与模糊核通道拼接后一起做卷积处理可能会对图像特征提取产生干扰,为此SFTMD采用子分支单独建模模糊核对超分辨的影响,以更合理的仿射变换的形式影响超分辨的特征提取过程。
2.3 预测器和修正器
预测器Predictor与修正器Corrector均由参数化的CNN实现,如图6。

预测器由4个普通的卷积层和一个全局池化层组成,4个卷积层利用低分辨图像预测模糊核特征图,全局池化层对特征图进行平均池化得到模糊核向量h。卷积层用来提取低分辨图片中的模糊特征,而全局池化可以在从空间上平均整体的模糊程度。
修正器分别对超分辨图像和模糊核进行特征变换得到各自的特征图,然后将它们拼接在一起并利用多层卷积预测模糊核修正量的特征如,最后使用全局平均池化得到其向量表示。超分辨的中间结果会因为模糊核的假设偏差而产生过平滑或者过锐化的特征,这些偏差特征由5个卷积层来提取;在作者的假设中,h是模糊核的PCA低维表示,所以每个维度的相关性应该越低越好,所以这里通过2个全连接层来学习h的内部相关性,修正器隐式的认为h的内部相关性就是核的假设偏差(个人理解)。以上两种偏差拼接后使用与预测器相同的方法将其转换成全局的向量表示。
3.实验
实验用的高分辨图片来自DIV2K和Flickr2K数据集,训练用的低分辨图片使用不同参数的高斯核从高分辨图片生成,即训练集中的每一个LR图像的真实图像和模糊核是已知的。训练时,先使用人造的数据集单独训练超分辨网络SFTMD,目标函数是MSE;训练好SFMD网络后,再交替训练预测器P和修正器C,此时SFTMD的参数固定。交替训练是指在每一轮中,先更新预测器P的参数,再更新修正器C的参数,更新其中某一个的参数时另外一个的参数是固定的,它们的更新函数如下:
3.1 SFTMD的有效性验证
SFTMD的核心贡献是使用仿射变换建模模糊核对超分辨过程的影响,为此作者对照了几种设计方案 (直接拼接 vs SFT,第一层插入vs每一层插入) 的组合对照实验,实验结果如图7。结果显示SFTMD的信噪比最高,这验证了作者对SRMD的两处核心改造的有效性。

3.2 IKC的有效性验证
图8展示了IKC超分辨的中间结果,可以发现,超分图像的视觉观感随迭代次数的增加明显提升。这说明了IKC使用多轮迭代的正当性和必要性。

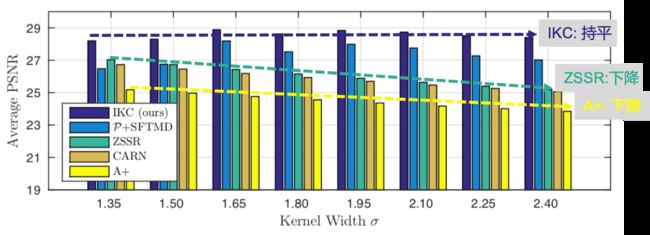
此外,作者也将IKC与State-of-the-art的方法进行了对比,采用CARN作为NonBlind SR的代表模型,ZSSR作为Blind SR的代表模型。为了对比公平,作者组合使用去模糊模型Pan和CARN,并将其作为对比项之一。为了再次强调多轮迭代修正(修正器)的重要性,作者添加了P+SFTMD为对比项。实验结果如图9,结果显示IKC及其弱化变种均优于对比模型。

此外,额外的实验表明IKC对模糊核参数的变化具有一定的适用性,如图10所示。这得益于网络学习PCA降维后的模糊核的策略,由于IKC建模的是PCA特征(而不是模糊核的直接参数)与超分辨图片的关系,所以具有一定的泛化能力。
以上对比都是在已知真实图片情况下进行的,为了验证IKC在更加真实场景下的表现,作者使用HR图像未知的图片在模型上测试,各模型的超分辨结果如图11和图12。


两个样例对比中,IKC的效果看起来都是最好的。值得注意的是,在样例2对比中,SRMD采用网格搜索的方式人工为低分辨图像构造模糊核,得到了更好的效果。同样是“猜”模糊核,SRMD用的是一种“暴力破解”的方法,IKC用的是迭代式学习的方法,在这个样例上二者的效果看起来差不多,IKC只是略高一筹。不过显然,在实际应用中IKC的计算效能高于网格搜索。
4.总结
本文的工作给超分辨带来的指导和启发可以总结为以下4点:
1.使用迭代式修正的方法能够更加精准地预测模糊核
2.在超分辨过程中使用SFT(仿射变换)能够更有效地利用模糊核信息
3.在网络的中间层插入模糊核信息能够有效提高网络对模糊核信息的利用效率
4.使用PCA表征模糊核不仅能降低计算成本,还能提高模型对模糊核参数的泛化能力
IKC为模糊核预估提供了一种可行的方法,提高了超分辨模型的实用性,在盲超分辨问题上迈进了一大步。SFTMD使用SFT层以仿射变换的形式将模糊核信息整合进网络,是一次有效、成功的应用。
IKC是有效的,但是也有一些不如人意之处。比如,迭代轮数需要人为设定,并且引入了额外的计算,这会影响它的实用性,应该对其进行衡量并想办法优化。另外,个人认为超分辨的视觉观感十分重要,PSNR指标具有局限性已经广为人知,应该基于真实图像做更多可视化对比以增强信服力。本文工作的重点在于模糊核的预测和模糊核信息的利用,所以没有专门考虑对于图像细节纹理的恢复或生成。从图8的鸟尾巴样例上可以看出,即使在多轮迭代后,网络也依然无法恢复出羽毛的纹理细节。或许,我们可以将其他SISR方法恢复纹理的经验结合到SFTMD中来,让IKC中的超分模型更加强大从而获得更好的效果。此外,关于模糊核预测的部分,不妨尝试各种新兴的训练方法,比如课程学习和GAN。
相关文献
文献1 :Learning a Single Convolutional Super-Resolution Network for Multiple Degradations (CVPR 2018 | SRMD模型)
文献2 :Recovering Realistic Texture in Image Super-Resolution by Deep Spatial Feature Transform (CVPR 2018 | SFT层)
文献3 :Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (CVPR 2017 | SRGAN模型/SRResNet架构)
以上解读为 @月本诚 在AI研习社CVPR小组原创首发,文中若有不足之处欢迎大家批评指正,所有方法的解释权归论文作者所有。
为了更加方便沟通交流,已经给大家准备好了微信群,想要加群的扫描添加 “AI研习社小助手” 的微信号吧!欢迎来撩~
