计算引擎的发展
了解Spark
Spark核心理念
数据应用Spark-sql
-
- Spark四大组件
-
- Spark-sql使用与优化
-
-
- Spark中的基本概念
-
-
-
- 使用Spark-sql
-
-
-
- 参数优化
-
-
- 问题点
本文主要是认识、了解Spark,并在实际应用中进行优化。文章内容主要参数网络与工作实践,有不足之处欢迎指出探讨
计算引擎的发展
大数据计算引擎的发展历程可分为四个阶段,目前主流的计算引擎是第三代Spark以及19年开始火起来的Flink。
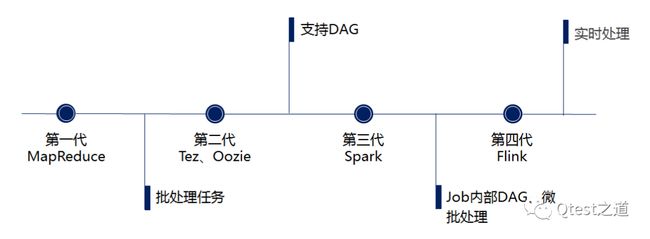
- 第一代:hadooo框架下成熟、稳定的MR计算,适用于大批量数据处理。高延迟是最大的短板
- 第二代:Tez、Oozie对于MR的优化,使用DAG方式减少map、reduce阶段的数据落盘,提升执行效率
- 第三代:job内部的DAG,此时强调实时处理过程。
- 第四代:对流计算的支持,以及更一步的实时性:Flink
了解Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
与MR相比,Spark基于内存,而MR基于HDFS。Spark处理数据的能力一般是MR的十倍以上,除了能基于内存之外,还能对对任务进行优化,通过内部DAG(有向无环图)的方式执行。
Spark核心理念
- Spark Session
在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点,SparkSession封装了SparkConf、SparkContext、SQLContext和HiveContext。SQLContext用于操作sql,HiveContext用于操作hive,计算实际上是由SparkContext按成。
- 提供一个统一的切入点使用Spark 各项功能
- 允许用户通过它调用 DataFrame 和 Dataset 相关 API 来编写程序
- 减少了用户需要了解的一些概念,可以很容易的与 Spark 进行交互
- DataFrames
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化
- RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。它代表一个不可变、可分区、里面的元素可并行计算的元素集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
- RDD依赖:RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算
- 分片(Partition):RDD由多个分片组成,每个分片都会被一个计算任务处理(Task)。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目
- Partitioner(分片函数):一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner;Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量
- 位置列表:存储每个Partition的优先位置(preferred location),如HDFS文件,保存的就是每个Partition所在的块的位置。Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置
- RDD依赖与运行
RDD之间形成类似流水线的前后依赖关系,可以分为宽、窄依赖。如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。
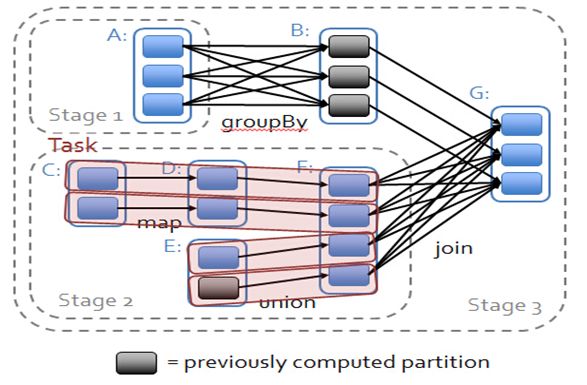
Spark根据RDD之间的依赖关系将DAG划分为不同的阶段。
- 窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中;
- 宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算;
Spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在图2中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。
- Spark任务
ShuffleMapTask:将stage计算的结果以shuffle到下一个stage中。【上图中的stage1和stage2,类似MR中的mapper】
ResultTask:最后一个stage将父stage的partition生成一个ResultTask【上图中的stage3,类似MR中的reducer】。每个Stage里面的Task的数量是由最后一个Stage中最后一个RDD的Partition的数量所决定的。
- Spark实例
依赖包:groupid=org.apache.spark;artifactId=spark-sql_2.12;version=2.4.4 / groupid=org.apache.hadoop;artifactId=hadoop-client;version=2.7.3
注意事项:hadoop在windows运行出现的bug,需要安装winutils.exe,并指定hadoop.home.dir参数
以java8进行编译运行【支持lambda函数】
public class SimpleRDD {
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "D:\\tools\\hadoop-home\\");
SparkConf conf = new SparkConf();
conf.setAppName("WortCount");
// 如果提交到集群,则注释下面的设定
conf.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//如果是集群环境,可以设置为: "/user/sunhuajian/input/0000000_0"
JavaRDD fileRDD = sc.textFile("G:\\test_xqlm2_user_info_his_ddl.sql");
// 每个单词由","隔开,将每行拆分为每个单词的RDD
JavaRDD wordRdd = fileRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
// 将每个单词转为key-value的RDD,并给每个单词计数为1
JavaPairRDD wordOneRDD = wordRdd.mapToPair(word -> new Tuple2<>(word, 1));
// 统计每个单词出现的次数
JavaPairRDD wordCountRDD = wordOneRDD.reduceByKey((x, y) -> x + y);
// 因为只能对key进行排序,所以需要将wordsCountRDD进行key-value倒置,返回新的RDD
JavaPairRDD count2WordRDD = wordCountRDD.mapToPair(tuple -> new Tuple2<>(tuple._2, tuple._1));
// 对count2WordRDD进行排序,降序desc
JavaPairRDD sortRDD = count2WordRDD.sortByKey(false);
// key -value倒置
JavaPairRDD resultRDD = sortRDD.mapToPair(tuple -> new Tuple2<>(tuple._2, tuple._1));
// 将结果保存到文件中(如果是集群的话,可以为:"/user/sunhuajian/output_1")
resultRDD.saveAsTextFile("G:\\result");
}
}
提交到集群:spark-submit --class com.datacenter.SimpleRDD --master yarn /home/hadoop/develop/sun/dev/project/simpleapp/target/simpleapp-1.0-SNAPSHOT.jar
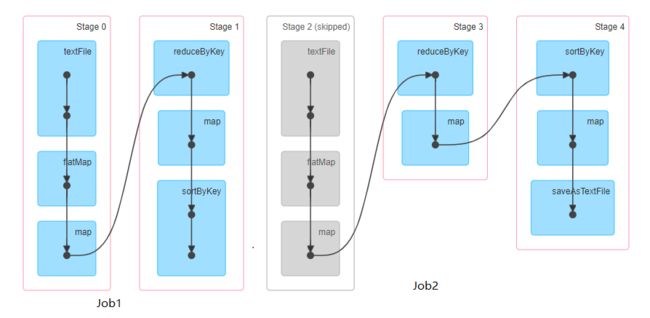
执行的stage和RDD顺序情况
数仓应用Spark Sql
Spark四大组件
Spark基于Spark Core实现基·本功能,包括任务调度、内存管理、错误恢复、与存储系统交互、RDD API的定义等,并提供一系列面向不同应用需求的组件,主要有Spark SQL、Spark Streaming、MLlib、GraphX。
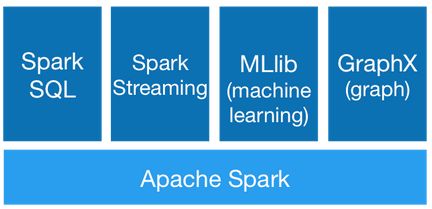
Spark Streaming :基于DStream微批量方式的计算和处理,可用于处理实时的流数据。与日志采集工具Flume、消息处理Kafka等可集成使用
MLib :一个可扩展的Spark机器学习库,由通用的学习算法和工具组成,提供多种学习算法,包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等功能
GraphX :用于图计算和并行图计算的新的(alpha)Spark API。扩展了RDD API功能,用来创建一个顶点和边都包含任意属性的有向图。支持针对图的各种操作,如图的分割subgraph、操作所有的顶点mapVertices、三角计算等
Spark SQL:通过JDBC API将Spark数据集暴露出去,用户可使用sql来操作结构化数据。
Spark sql使用与优化
Spark中的基本概念
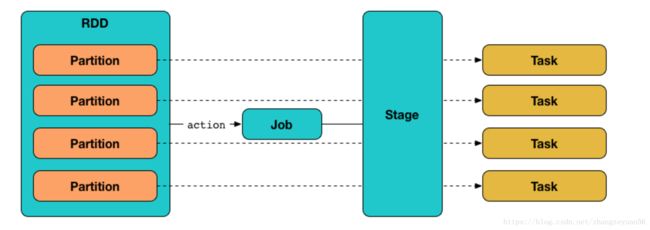
job:一个典型的Job:从数据源(Data blocks)加载生成RDD,经过一系列转换(Transformation和shuffle),由Action触发,得到计算结果(result),再将结果汇总到driver端。每个Action对应一个Job;stage:每个Job会被拆分很多组Task,由一组或多组Task组成的,可并行计算的实体,其名称为StageDriver:运行Application的main()函数,并且创建/关闭SparkContext的那台机器。SparkContext是为了准备Spark应用程序的运行环境,负责与ClusterManager通讯,进行资源的申请,任务的分配和监控等Executor:某个Application运行在Worker节点上的一个进程,该进程负责运行一个或多个task,并且负责将数据存在内存或者磁盘上。在Spark on Yarn模式下,其进程名称为 CoarseGrainedExecutor Backend,一个CoarseGrainedExecutor Backend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task,这样,每个CoarseGrainedExecutorBackend能并行运行Task的数据就取决于分配给它的CPU的个数
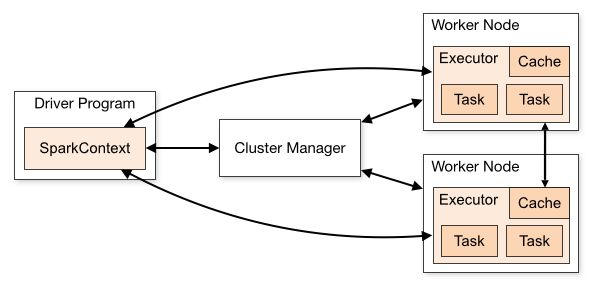
Task:分为ShuffleMapTask 和 ResultTask 两种 Taskshuffle:stage之间存在shuffle,与MR的shuffle具有很多类似之处Partition:RDD是一种分布式的数据集,由于数据量很大,因此要它被切分并存储在各个结点的分区当中。从而当我们对RDD进行操作时,实际上是对每个分区中的数据并行操作
使用Spark sql
- spark-sql --help 查询使用参数
......
usage: hive
-d,--define Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database Specify the database to use
-e SQL from command line
-f SQL from files
-H,--help Print help information
--hiveconf Use value for given property
--hivevar Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
- sqark-sql 执行sql脚本/脚本
1. spark-sql -e "select count(*) from dw_db.dw_xqlm2_base_log where p_dt='2020-01-01'"
// 对于参数的定义,也可以使用spark的方式 -d dealDate=2020-01-01
2. spark-sql --name sunhuajian_test --queue root.xqlm2 -define dealHours=09 -define project=shoujilm -define dealDate=2020-01-01 --conf spark.sql.codegen=true --conf spark.executor.cores=4 --conf spark.executor.memory=8g --conf spark.sql.shuffle.partitions=200 --conf spark.hadoop.mapreduce.input.fileinputformat.split.maxsize=67108864 --conf spark.hadoop.mapreduce.input.fileinputformat.split.minsize=33554432 --conf spark.sql.adaptive.enabled=true --conf spark.sql.adaptive.shuffle.targetPostShuffleInputSize=128000000 -f test.sql
这种情况下启动的spark应用,使用的是默认的参数。默认参数通过查看spark-defaults.conf 文件或者在spark-sql客户端使用set -v查看
参数优化
官方提供的spark参数及说明
a. 提升Spark运行
spark.sql.adaptive.enabled=true
spark的自适应执行,启动Adaptive Execution
spark.dynamicAllocation.enabled=true
开启动态资源分配,Spark可以根据当前作业的负载动态申请和释放资源
spark.dynamicAllocation.maxExecutors=${numbers}
开启动态资源分配后,同一时刻,最多可申请的executor个数。task较多时,可适当调大此参数,保证task能够并发执行完成,缩短作业执行时间
spark.dynamicAllocation.minExecutors=3
某一时刻executor的最小个数。平台默认设置为3,即在任何时刻,作业都会保持至少有3个及以上的executor存活,保证任务可以迅速调度
spark.sql.shuffle.partitions
JOIN或聚合等需要shuffle的操作时,设定从mapper端写出的partition个数。类似于MR中的reducer,当partition多时,产生的文件也会多
spark.sql.adaptive.shuffle.targetPostShuffleInputSize=67108864
当mapper端两个partition的数据合并后数据量小于targetPostShuffleInputSize时,Spark会将两个partition进行合并到一个reducer端进行处理。默认64m
spark.sql.adaptive.minNumPostShufflePartitions=50
当spark.sql.adaptive.enabled参数开启后,有时会导致很多分区被合并,为了防止分区过少而影响性能。设置该参数,保障至少的shuffle分区数
spark.hadoop.mapreduce.input.fileinputformat.split.maxsize=134217728
控制在ORC切分时stripe的合并处理。当几个stripe的大小大于设定值时,会合并到一个task中处理。适当调小该值以增大读ORC表的并发 【最小大小的控制参数spark.hadoop.mapreduce.input.fileinputformat.split.minsize】
- b. 提升Executor执行能力
spark.executor.memory=4g
用于缓存数据、代码执行的堆内存以及JVM运行时需要的内存。设置过小容易导致OOM,而实际执行中需要的大小可以通过文件来估算
spark.yarn.executor.memoryOverhead=1024
Spark运行还需要一些堆外内存,直接向系统申请,如数据传输时的netty等
spark.executor.cores=4
单个executor上可以同时运行的task数,该参数决定了一个executor上可以并行执行几个task。几个task共享同一个executor的内存(spark.executor.memory+spark.yarn.executor.memoryOverhead)。适当提高该参数的值,可以有效增加程序的并发度,是作业执行的更快。不过同时也增加executor内存压力,容易出现OOM
-
c. 其他参数
参数名称 当前 说明/含义 spark.sql.autoBroadcastJoinThreshold 64mb 使用BroadcastJoin时候表的大小阈值(-1 则取消使用) spark.sql.broadcastTimeout 300s BroadcastJoin的等待超时的时间 spark.default.parallelism 24 指定每个stage默认的并行task数量,处理RDD时才会起作用,对Spark SQL的无效 spark.speculation true 执行任务的推测执行。这意味着如果一个或多个任务在一个阶段中运行缓慢,它们将被重新启动 spark.speculation.quantile 在特定阶段启用推测之前必须完成的部分任务。推荐0.75/0.95 spark.kryoserializer.buffer.max 64m Kryo串行缓冲区的最大允许大小(以MiB为单位)。它必须大于您尝试序列化的任何对象,并且必须小于2048m。如果在Kryo中收到“超出缓冲区限制”异常,请增加此值。推荐1024m spark.sql.hive.metastorePartitionPruning true spark.sql.hive.caseSensitiveInferenceMode INFER_AND_SAVE 不太了解,推荐使用NEVER_INFER spark.sql.optimizer.metadataOnly true 启用仅使用表的元数据的元数据查询优化来生成分区列,而不是表扫描
- d. 常见问题
- OOM内存溢出
Spark根据 spark.executor.memory+spark.yarn.executor.memoryOverhead的值向RM申请一个容器,当executor运行时使用的内存超过这个限制时,会被yarn kill掉。失败信息为:Container killed by YARN for exceeding memory limits. XXX of YYY physical memory used. Consider boosting spark.yarn.executor.memoryOverhead。合理的调整这两个参数
- 小文件数过多
当spark执行结束后,如果生成较多的小文件可以通过hive对文件进行合并。
rc/orc文件: ALTER TABLE table_name CONCATENATE ;
其他文件:指定输出文件大小并重写表(insert overwrite table _name_new select * from table_name)
- spark结果与hive结果不一致
- 数据文件字段中存在特殊字符带来的错行错列,剔除特殊字符,如: regexp_replace(name,'\n|\r|\t|\r\n|\u0001', '')
- spark为了优化读取parquet格式文件,使用自己的解析方式读取数据。将该方式置为false
set spark.sql.hive.convertMetastoreParquet=false- hive中对于null和空值与spark的差异。已知的办法是调整hive的参数:serialization.null.format 如:
alter table table_name set serdeproperties('serialization.null.format' = '');