目录

目录.png
分布式定时任务系列
- 分布式定时任务elastic-job(一)
- 分布式定时任务elastic-job(二)
- 分布式定时任务elastic-job(三)
- 分布式定时任务elastic-job(四)
选举
- 主节点作用: 分配作业分片项,调解分布式作业不一致状态。因为elastic-job-lite是无中心化,通过jar提供的,所以需要主节点处理一些事情。这里不通过分布式锁处理这些问题,是为了避免每次操作都需要获取锁解锁,避免性能损耗。不同的作业是有可能有不同的主节点的。
- 失效转移使用zk分布式锁,是因为希望集群一起负载失效的分片。
-
选主时序图
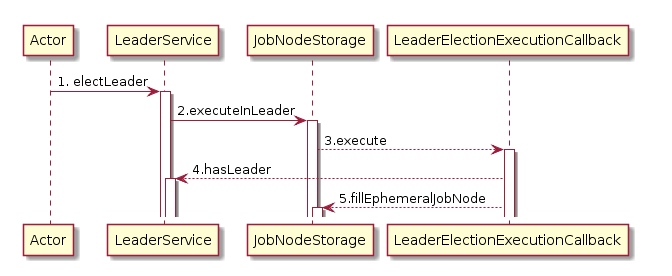 选主时序图.png
选主时序图.png - 这里用分布式锁防止并发,回调时判断hasLeader是因为一台服务选完主节点后释放锁,另外的服务拿到锁后还是会执行回调代码, 所以要加这个判断
// LeaderService.java
// 选举主节点
public void electLeader() {
// 通过回调的机制实现抽象公共代码部分
jobNodeStorage.executeInLeader(LeaderNode.LATCH, new LeaderElectionExecutionCallback());
}
// JobNodeStorage.java
public void executeInLeader(final String latchNode, final LeaderExecutionCallback callback) {
// try with resource, LeaderLatch实现closable, 完成后会自动调用close
try (LeaderLatch latch = new LeaderLatch(getClient(), jobNodePath.getFullPath(latchNode))) {
latch.start();
latch.await();
callback.execute();
} catch (final Exception ex) {
handleException(ex);
}
}
// LeaderElectionExecutionCallback 回调
class LeaderElectionExecutionCallback implements LeaderExecutionCallback {
@Override
public void execute() {
// 当前无主节点
if (!hasLeader()) {
jobNodeStorage.fillEphemeralJobNode(LeaderNode.INSTANCE, JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
}
}
}
- 选取成功后会填充节点/${JOB_NAME}/leader/electron/instance
选主时机
- 初始化注册作业启动
public void registerStartUpInfo(final boolean enabled) {
// 选举主节点
leaderService.electLeader();
}
- 节点数据变化时, 主节点下线
class LeaderElectionJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
if (!JobRegistry.getInstance().isShutdown(jobName) && (isActiveElection(path, data) || isPassiveElection(path, eventType))) {
leaderService.electLeader();
}
}
}
等待主节点选举完成
- 有些必须要主节点操作的任务,会等待主节点完成再继续
// LeaderService
public boolean isLeaderUntilBlock() {
// 不存在主节点 && 有可用的服务器节点
while (!hasLeader() && serverService.hasAvailableServers()) {
log.info("Leader is electing, waiting for {} ms", 100);
// 等待
BlockUtils.waitingShortTime();
if (!JobRegistry.getInstance().isShutdown(jobName)
&& serverService.isAvailableServer(JobRegistry.getInstance().getJobInstance(jobName).getIp())) {
// 当前服务器节点可用
electLeader();
}
}
// 返回当前节点是否是主节点
return isLeader();
}
zk节点数据结构
-
推荐使用zooInspector连接zk查看数据
 ZK数据节点.png
ZK数据节点.png - com.seeger.demo.service.MySimpleJob是job的名称,每个job都会有类似这种目录,但是目录底下子目录leader, servers, config, instances, sharding这种结构是一样的
config
- config节点是存放配置的,就是存一些比如分片总数之类的总体配置
servers
- 各个服务实例ip
leader
-
包括一些分布式锁,分片之类的信息
 leader.png
leader.png
instances
- 实例节点
sharding
-
分片相关,一个任务分片后,不同分片可能存在不同服务上
 sharding.png
sharding.png
分片
分片策略
- JobShardingStrategy策略接口
public interface JobShardingStrategy {
Map> sharding(List jobInstances, String jobName, int shardingTotalCount);
}
默认策略AverageAllocationJobShardingStrategy
- 基于平均分配算法的分片策略, 如果有3台作业节点
- 分成9片,则每台作业节点分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
- 分成8片,则每台作业节点分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
- 感兴趣可以深入源码看看
OdevitySortByNameJobShardingStrategy
- 根据哈希值奇偶数确定ip升降序算法,奇数升序,偶数降序
- 如果有3台作业节点, 分成2片, 作业名称的哈希值为奇数, 则每台作业节点分到的分片是: 1=[ ], 2=[1], 3=[0].
- 如果有3台作业节点, 分成2片, 作业名称的哈希值为偶数, 则每台作业节点分到的分片是: 1=[0], 2=[1], 3=[ ]
- 优点: 可以根据作业名称重新分配作业节点负载, 不同的作业平均分配负载至不同的作业节点
RotateServerByNameJobShardingStrategy
- 根据作业名哈希值进行轮转的分片策略
- 如果有3台作业节点,分成2片,作业名称的哈希值为奇数,则每台作业节点分到的分片是:1=[0], 2=[1], 3=[]
- 如果有3台作业节点,分成2片,作业名称的哈希值为偶数,则每台作业节点分到的分片是:3=[0], 2=[1], 1=[]
- 优点分片更均衡, 不同的作业平均分配负载至不同的作业节点,确定分片数小于作业作业节点数时, 作业将永远分配至IP地址靠前的作业节点, 导致IP地址靠后的作业节点空闲
自定义实现
- 当然也可以自定义实现,实现时,@Bean传入自定义实现的配置,原理跟listen自定义实现一样。
分片条件
设置重新分片代码
- 设置要重新分片标记,zk上面的节点数据是/${JOB_NAME}/leader/sharding/necessary
// ShardingService.java
// 设置需要重新分片的标记.
public void setReshardingFlag() {
jobNodeStorage.createJobNodeIfNeeded(ShardingNode.NECESSARY);
}
// JobNodeStorage.java
// 如果存在则创建作业节点
public void createJobNodeIfNeeded(final String node) {
if (isJobRootNodeExisted() && !isJobNodeExisted(node)) {
regCenter.persist(jobNodePath.getFullPath(node), "");
}
}
- 判断是否需要重新分片, 判断/${JOB_NAME}/leader/sharding/necessary节点存不存在
// ShardingService.java
// 判断是否需要重分片 判断/${JOB_NAME}/leader/sharding/necessary节点存不存在
public boolean isNeedSharding() {
return jobNodeStorage.isJobNodeExisted(ShardingNode.NECESSARY);
}
需要重新分片的情况
- 作业启动时
// SchedulerFacade.java
public void registerStartUpInfo(final boolean enabled) {
// 设置 需要重新分片的标记
shardingService.setReshardingFlag();
}
- 分片总数变化时
- 在监听器章节,介绍了监听器相关,分片总数变化时会触发ShardingTotalCountChangedJobListener监听器
// ShardingTotalCountChangedJobListener
class ShardingTotalCountChangedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
if (configNode.isConfigPath(path) && 0 != JobRegistry.getInstance().getCurrentShardingTotalCount(jobName)) {
int newShardingTotalCount = LiteJobConfigurationGsonFactory.fromJson(data).getTypeConfig().getCoreConfig().getShardingTotalCount();
if (newShardingTotalCount != JobRegistry.getInstance().getCurrentShardingTotalCount(jobName)) {
// 分片总数变化时设置需要重新分片
shardingService.setReshardingFlag();
JobRegistry.getInstance().setCurrentShardingTotalCount(jobName, newShardingTotalCount);
}
}
}
}
- 服务器变化,服务器变化时触发服务器变化监听器
// ShardingListenerManager.java
class ListenServersChangedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
if (!JobRegistry.getInstance().isShutdown(jobName)
&& (isInstanceChange(eventType, path)
|| isServerChange(path))) {
// 设置需要重新分片
shardingService.setReshardingFlag();
}
}
private boolean isInstanceChange(final Type eventType, final String path) {
return instanceNode.isInstancePath(path) && Type.NODE_UPDATED != eventType;
}
private boolean isServerChange(final String path) {
return serverNode.isServerPath(path);
}
}
- 自诊断修复时也会触发,具体在自诊断修复章节
作业分片
-
作业分片时序图
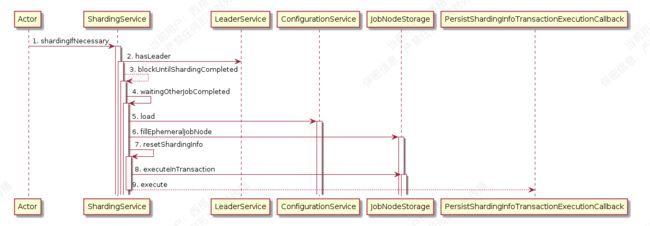 作业分片时序图.png
作业分片时序图.png
// ShardingService.java
// 如果需要分片且当前节点为主节点, 则作业分片 如果当前无可用节点则不分片
public void shardingIfNecessary() {
// 获取可用job实例
List availableJobInstances = instanceService.getAvailableJobInstances();
// 判断是否需要重新分片
if (!isNeedSharding() || availableJobInstances.isEmpty()) {
return;
}
// 非主节点等待作业分片项分配完成 主节点则继续
if (!leaderService.isLeaderUntilBlock()) {
blockUntilShardingCompleted();
return;
}
// 主节点继续,但是等待其他运行中的作业运行完
waitingOtherJobCompleted();
// 从zk获取配置
LiteJobConfiguration liteJobConfig = configService.load(false);
int shardingTotalCount = liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount();
// 重新分片标记设置
jobNodeStorage.fillEphemeralJobNode(ShardingNode.PROCESSING, "");
// 重置作业分片项信息
resetShardingInfo(shardingTotalCount);
// zk事务执行多条语句
JobShardingStrategy jobShardingStrategy = JobShardingStrategyFactory.getStrategy(liteJobConfig.getJobShardingStrategyClass());
jobNodeStorage.executeInTransaction(new PersistShardingInfoTransactionExecutionCallback(jobShardingStrategy.sharding(availableJobInstances, jobName, shardingTotalCount)));
}
3. blockUntilShardingCompleted
- 非主节点等待作业分片项分配完成 主节点则继续
4. waitingOtherJobCompleted
- 主节点继续,但是等待其他运行中的作业运行完,作业是否则运行中需要作业设置LiteJobConfiguration.monitorExecution = true才可以监控到
5. load
- 从zk获取配置而不走缓存,需要获取最新的数据
6. fillEphemeralJobNode
- 设置正在重新分片标记 /${JOB_NAME}/leader/sharding/processing
7. resetShardingInfo
- 重置分片信息
private void resetShardingInfo(final int shardingTotalCount) {
// 重置 有效的作业分片项
for (int i = 0; i < shardingTotalCount; i++) {
// 移除 `/${JOB_NAME}/sharding/${ITEM_ID}/instance`
jobNodeStorage.removeJobNodeIfExisted(ShardingNode.getInstanceNode(i));
// 创建 `/${JOB_NAME}/sharding/${ITEM_ID}`
jobNodeStorage.createJobNodeIfNeeded(ShardingNode.ROOT + "/" + i);
}
// 移除 多余的作业分片项
int actualShardingTotalCount = jobNodeStorage.getJobNodeChildrenKeys(ShardingNode.ROOT).size();
if (actualShardingTotalCount > shardingTotalCount) {
for (int i = shardingTotalCount; i < actualShardingTotalCount; i++) {
// 移除 `/${JOB_NAME}/sharding/${ITEM_ID}`
jobNodeStorage.removeJobNodeIfExisted(ShardingNode.ROOT + "/" + i);
}
}
}
8. executeInTransaction zk提供的事务执行
- JobShardingStrategy.sharding 分配分配策略前文介绍过了,
9. execute执行
- 设置 /JOB_NAME/sharding/ITEM_ID/instance 分片节点数据
// PersistShardingInfoTransactionExecutionCallback.java
class PersistShardingInfoTransactionExecutionCallback implements TransactionExecutionCallback {
// 作业分片项分配结果缓存
private final Map> shardingResults;
@Override
public void execute(final CuratorTransactionFinal curatorTransactionFinal) throws Exception {
// 设置 每个节点分配的作业分片项 真正设置数据进去
for (Map.Entry> entry : shardingResults.entrySet()) {
for (int shardingItem : entry.getValue()) {
curatorTransactionFinal.create().forPath(jobNodePath.getFullPath(ShardingNode.getInstanceNode(shardingItem))
, entry.getKey().getJobInstanceId().getBytes()).and();
}
}
// 移除 作业需要重分片的标记、作业正在重分片的标记
curatorTransactionFinal.delete().forPath(jobNodePath.getFullPath(ShardingNode.NECESSARY)).and();
curatorTransactionFinal.delete().forPath(jobNodePath.getFullPath(ShardingNode.PROCESSING)).and();
}
}
获取作业分片上下文集合
-
时序图
 获取作业分片上下文集合.png
获取作业分片上下文集合.png - 图中2, 6部分在失效转移章节介绍
- 具体代码
// LiteJobFacade.java
@Override
public ShardingContexts getShardingContexts() {
// 失效转移部分,先跳过
boolean isFailover = configService.load(true).isFailover();
if (isFailover) {
List failoverShardingItems = failoverService.getLocalFailoverItems();
if (!failoverShardingItems.isEmpty()) {
return executionContextService.getJobShardingContext(failoverShardingItems);
}
}
// 作业分片, 如果需要分片且当前节点为主节点
shardingService.shardingIfNecessary();
// 获取分配在本机的作业分片项
List shardingItems = shardingService.getLocalShardingItems();
// 失效转移部分,先跳过
if (isFailover) {
shardingItems.removeAll(failoverService.getLocalTakeOffItems());
}
// 移除被禁用的作业分片项
shardingItems.removeAll(executionService.getDisabledItems(shardingItems));
// 获取当前作业服务器分片上下文
return executionContextService.getJobShardingContext(shardingItems);
}
4. shardingIfNecessary
- 作业分片, 如果需要分片且当前节点为主节点则分片
5. getLocalShardingItems
- 获取分配在本机的作业分片项,即 /JOB_NAME/sharding/${ITEM_ID}/instance
// ShardingService.java
// 获取运行在本作业实例的分片项集合
public List getLocalShardingItems() {
if (JobRegistry.getInstance().isShutdown(jobName) || !serverService.isAvailableServer(JobRegistry.getInstance().getJobInstance(jobName).getIp())) {
return Collections.emptyList();
}
return getShardingItems(JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
}
// 获取作业运行实例的分片项集合.
public List getShardingItems(final String jobInstanceId) {
JobInstance jobInstance = new JobInstance(jobInstanceId);
if (!serverService.isAvailableServer(jobInstance.getIp())) {
return Collections.emptyList();
}
List result = new LinkedList<>();
int shardingTotalCount = configService.load(true).getTypeConfig().getCoreConfig().getShardingTotalCount();
for (int i = 0; i < shardingTotalCount; i++) {
// `/${JOB_NAME}/sharding/${ITEM_ID}/instance` 如果是本机则添加
if (jobInstance.getJobInstanceId().equals(jobNodeStorage.getJobNodeData(ShardingNode.getInstanceNode(i)))) {
result.add(i);
}
}
return result;
}
7. shardingItems.removeAll
- 移除被禁用的作业分片项
// ExecutionService.java
// 获取禁用的任务分片项
public List getDisabledItems(final List items) {
List result = new ArrayList<>(items.size());
for (int each : items) {
// /${JOB_NAME}/sharding/${ITEM_ID}/disabled
if (jobNodeStorage.isJobNodeExisted(ShardingNode.getDisabledNode(each))) {
result.add(each);
}
}
return result;
}
getJobShardingContext获取分片上下文
- 移除 正在运行中的作业分片项,monitor开启才会记录运行中分片,才能有效移除正在运行的分片
// ExecutionContextService.java
public ShardingContexts getJobShardingContext(final List shardingItems) {
LiteJobConfiguration liteJobConfig = configService.load(false);
// 移除 正在运行中的作业分片项,monitor开启才会记录运行中分片
removeRunningIfMonitorExecution(liteJobConfig.isMonitorExecution(), shardingItems);
if (shardingItems.isEmpty()) {
return new ShardingContexts(buildTaskId(liteJobConfig, shardingItems), liteJobConfig.getJobName(), liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount(),
liteJobConfig.getTypeConfig().getCoreConfig().getJobParameter(), Collections.emptyMap());
}
// 解析分片参数
Map shardingItemParameterMap = new ShardingItemParameters(liteJobConfig.getTypeConfig().getCoreConfig().getShardingItemParameters()).getMap();
// 创建 分片上下文集合
return new ShardingContexts(buildTaskId(liteJobConfig, shardingItems), //
liteJobConfig.getJobName(), liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount(),
liteJobConfig.getTypeConfig().getCoreConfig().getJobParameter(),
getAssignedShardingItemParameterMap(shardingItems, shardingItemParameterMap)); // 获得当前作业节点的分片参数
}
失效转移
- 失效转移,指的是,别的服务宕机,这时候本服务运行完时会主动拉取失效转移的,当然也有被动触发的
- 失效转移会调用quartz的trigger 会再次触发一次 等执行完再次触发,多次触发确实是串行执行的,因为设置了org.quartz.threadPool.threadCount设置quartz线程数为1,可以在自定义任务里面sleep然后多线程调用trigger做测试,可以发现是串行执行
- 失效转移涉及别的服务宕机之类的,涉及重新分片更复杂,所以是在重新执行任务的时候做错过转移,而不像错过执行一样,是具备运行完马上再执行的
作业节点崩溃监听
- 根据上问的监听器介绍,作业节点崩溃是在JobCrashedJobListener做监听,如果开启失效转移 并且/JOB_NAME/instances/INSTANCE_ID节点被移除,先获取/JOB_NAME/sharding/ITEM_ID/failover节点数据,如果没有的话获取/JOB_NAME/sharding/ITEM_ID/instance节点数据
// JobCrashedJobListener.java
class JobCrashedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
// 开启失效转移 并且${JOB_NAME}/instances/${INSTANCE_ID}节点被移除
if (isFailoverEnabled() && Type.NODE_REMOVED == eventType
&& instanceNode.isInstancePath(path)) {
String jobInstanceId = path.substring(instanceNode.getInstanceFullPath().length() + 1);
if (jobInstanceId.equals(JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId())) {
return;
}
// 先获取${JOB_NAME}/sharding/${ITEM_ID}/failover节点数据
List failoverItems = failoverService.getFailoverItems(jobInstanceId);
if (!failoverItems.isEmpty()) {
for (int each : failoverItems) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
} else {
// 没有的话获取/${JOB_NAME}/sharding/${ITEM_ID}/instance节点数据
for (int each : shardingService.getShardingItems(jobInstanceId)) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
}
}
}
}
- 两个节点其中一个有数据时, 设置fail转移标识
public void setCrashedFailoverFlag(final int item) {
if (!isFailoverAssigned(item)) {
// /${JOB_NAME}/leader/failover/items/${ITEM_ID}
jobNodeStorage.createJobNodeIfNeeded(FailoverNode.getItemsNode(item));
}
}
private boolean isFailoverAssigned(final Integer item) {
return jobNodeStorage.isJobNodeExisted(FailoverNode.getExecutionFailoverNode(item));
}
作业失效转移
- 如果需要进行失效转移,利用分布式锁,然后回调机制实现
// FailoverService.java
public void failoverIfNecessary() {
if (needFailover()) {
jobNodeStorage.executeInLeader(FailoverNode.LATCH, new FailoverLeaderExecutionCallback());
}
}
private boolean needFailover() {
// `${JOB_NAME}/leader/failover/items/${ITEM_ID}` 有失效转移的作业分片项而且当前作业不在运行中
return jobNodeStorage.isJobNodeExisted(FailoverNode.ITEMS_ROOT) && !jobNodeStorage.getJobNodeChildrenKeys(FailoverNode.ITEMS_ROOT).isEmpty()
&& !JobRegistry.getInstance().isJobRunning(jobName);
}
- FailoverLeaderExecutionCallback回调逻辑, 最后需要的话会调用jobScheduleController.triggerJob()重新触发任务,这里参数设置了串行执行,所以不会有并发问题,因为失效转移比错过执行更复杂,往往涉及重分片,所以失效转移是重新出发任务,而错过执行是执行任务完马上再执行,而不重新触发新任务执行
class FailoverLeaderExecutionCallback implements LeaderExecutionCallback {
@Override
public void execute() {
// 判断需要失效转移
if (JobRegistry.getInstance().isShutdown(jobName) || !needFailover()) {
return;
}
// 获得一个 `${JOB_NAME}/leader/failover/items/${ITEM_ID}` 作业分片项
int crashedItem = Integer.parseInt(jobNodeStorage.getJobNodeChildrenKeys(FailoverNode.ITEMS_ROOT).get(0));
// 设置这个 `${JOB_NAME}/sharding/${ITEM_ID}/failover` 作业分片项 为 当前作业节点
jobNodeStorage.fillEphemeralJobNode(FailoverNode.getExecutionFailoverNode(crashedItem), JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
// 移除这个 `${JOB_NAME}/leader/failover/items/${ITEM_ID}` 作业分片项
jobNodeStorage.removeJobNodeIfExisted(FailoverNode.getItemsNode(crashedItem));
// 触发作业执行
JobScheduleController jobScheduleController = JobRegistry.getInstance().getJobScheduleController(jobName);
if (null != jobScheduleController) {
jobScheduleController.triggerJob();
}
}
}
- 核心代码executor, 执行完任务时会主动进行failoverIfNecessary的方法,有需要则执行FailoverLeaderExecutionCallback回调,并设置失效转移/JOB_NAME/sharding/ITEM_ID/failover节点。所以getFailoverItems获取失效转移分片时是先获取/JOB_NAME/sharding/ITEM_ID/failover节点顺序,因为这个是执行完任务设置的
// AbstractElasticJobExecutor
public final void execute() {
// 执行 普通触发的作业
execute(shardingContexts, JobExecutionEvent.ExecutionSource.NORMAL_TRIGGER);
// 执行 被跳过触发的作业
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
// 执行 作业失效转移
jobFacade.failoverIfNecessary();
}
- failoverIfNecessary只会抓取一个失效分片,这样集群就能一起处理失效分片,而不是所有任务都打到某台负载
获取作业分片上下文集合
-
时序图
获取作业分片上下文集合.png - 失效转移时获取上下文,分片介绍了大部分流程,这里只介绍2,6, 2在作业节点崩溃监听章节介绍过了,执行完任务时有需要会设置失效转移/JOB_NAME/sharding/ITEM_ID/failover节点。所以getFailoverItems获取失效转移分片时是先获取/JOB_NAME/sharding/ITEM_ID/failover节点顺序。 6是移除失效转移分片
// LiteJobFacade.java
@Override
public ShardingContexts getShardingContexts() {
// 获得 失效转移的作业分片项
boolean isFailover = configService.load(true).isFailover();
if (isFailover) {
// 2. 获取失效转移分片
List failoverShardingItems = failoverService.getLocalFailoverItems();
if (!failoverShardingItems.isEmpty()) {
// 跳过因为在分片章节介绍过了
return executionContextService.getJobShardingContext(failoverShardingItems);
}
}
// 跳过因为在分片章节介绍过了
shardingService.shardingIfNecessary();
// 跳过因为在分片章节介绍过了
List shardingItems = shardingService.getLocalShardingItems();
// 6. 移除失效转移分片
if (isFailover) {
shardingItems.removeAll(failoverService.getLocalTakeOffItems());
}
// 移除 被禁用的作业分片项
shardingItems.removeAll(executionService.getDisabledItems(shardingItems));
// 跳过因为在分片章节介绍过了
return executionContextService.getJobShardingContext(shardingItems);
}
-
- 移除失效转移分片,这么做是因为有可能: 作业节点A持有作业分片项(0, 1),此时断网,导致(0, 1)被作业节点B失效转移抓取,此时若作业节点A恢复,作业分片项(0, 1)依然属于作业节点A,但是可能已经在作业节点B执行,因此需要进行移除,避免多节点运行相同的作业分片项
shardingItems.removeAll(failoverService.getLocalTakeOffItems());
// 获取运行在本作业服务器的被失效转移的序列号
public List getLocalTakeOffItems() {
List shardingItems = shardingService.getLocalShardingItems();
List result = new ArrayList<>(shardingItems.size());
for (int each : shardingItems) {
if (jobNodeStorage.isJobNodeExisted(FailoverNode.getExecutionFailoverNode(each))) {
result.add(each);
}
}
return result;
}
错过执行
- 错过任务执行指的是: 任务时间间隔小于任务执行时间,比如时间间隔10秒,但是任务执行本身花了15秒,这个时候下个任务触发时,因为有任务在执行,就会被表过错过
- 错过执行本身quartz会支持,但是elastic-job设置quartz处理逻辑交还到ealstic-job本身,错过执行是在执行完正常的任务之后,立马执行错过任务,而不是重新执行任务时,执行错过执行任务。executor方法开始时防御性判是否有错过任务,应该只是防御性的判断这块。当然错过执行执行时也会判断任务是否在运行中
- 错过执行只是涉及自己机器而且是在运行中才会错过,具备运行完马上再执行的条件。但是失效转移涉及别的服务宕机之类的,涉及重新分片更复杂,所以是在重新执行任务的时候做错过转移,而不像错过执行一样,是具备运行完马上再执行的
参考文章
- 脑裂是什么?Zookeeper是如何解决的?
- Kafka研究系列之kafka 如何避免脑裂?如何选举leader
- 如何防止ElasticSearch集群出现脑裂现象
- elastic-job调度模型
- 芋道源码-elastic-job
- Quartz原理解密
- 分布式定时任务调度系统技术选型