一.安装虚拟机环境
虚拟机版本:VMware Workstation Pro
LInux版本:CentOS-6.10-x86_64-bin-DVD1.iso
(下载地址:https://developer.aliyun.com/mirror 或者 https://tuna.moe/)
二.搭建集群
1.集群分配
两个节点:主节点(master-192.168.31.160),从节点(follower-192.168.31.160)【为啥不用slaver,,,,,个人不喜欢这个单词。。。。。】
网络配置需要注意,借鉴我之前写的文档
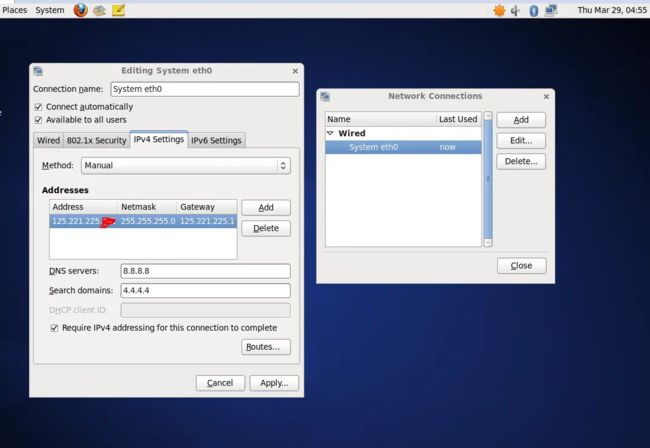
注意:配置网络使用桥接模式,与主机相同的网关和掩码,(Windows查询主机地址命令:ipconfig;Linux命令:ifconfig),红标位置可自行选择。curl命令查询是否联网成功,也可以用Windows命令行ping主机地址。
2.集群搭建
安装一下可能需要的环境:yum -y install autoconf automake libtool cmake ncurses-devel openss-devel lzo-devel zlib-devel gcc gcc-c++
(1)修改hostname
将HOSTNAME修改成对应主机名,记得修改其他节点,重启生效,重启生效,重启生效。
(2)添加host节点

每个节点都需要修改,其中的间距用Tab键控制。
(3)关闭防火墙和selinux
关闭防火墙命令:chkconfig iptables off
关闭selinux

(4)ssh免密登录
命令:ssh-keygen -t rsa 然后四下回车键,然后拷贝公钥,借我之前的图。
主节点配置完成后,通过命令:scp -r /root/.ssh/ follower:/root。然后就好了各个节点之间可以通过(ssh+主机名)登录


(5)安装JDK
个人习惯把软件都放在(/home)目录下,所以目录可以自己选,按照习惯来。
解压JDK到softwares目录下(tar -zxf jdk-8u151-linux-x64.tar.gz -C ../softwares/),打开jdk目录,并打印路径(pwd),复制待用。(vim /etc/profile)修改环境变量,使修改后的环境变量生效(source /etc/profile),只需配置JAVA_HOME,如图(参考)。java -version 查看是否安装成功及版本


(6)安装Hadoop
下载hadoop包(http://archive.apache.org/dist/)apache的软件里面都有,自己找一下,锻炼一下。下的tar包,比较大的那个,当然也可以下载src的源码包,自行编译或者睡前阅读。上传至主节点,并解压到安装目录(tar -zxvf 需解压文件 -C 安装目录)
先在主节点上操作,到修改完配置文件再分发到其余节点。

把hadoop的写入环境变量,方便操作。vim修改,source生效

(7)配置Hadoop
需要配置如下文件(/home/softwares/hadoop-2.6.1/etc/hadoop)可以使用notepad链接虚拟机进行操作,查一下操作就行。
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
hadoop-env.sh
添加JAVA路径,找到并修改。

yarn-env.sh
添加JAVA路径,找到并修改。

core-site.xml
需要添加:注释是我方便理解加的,不需要添加

hdfs-site.xml

mapred-site.xml
配置前需要将mapred-site.xml.template重命名为 .xml的文件

yarn-site.xml
配置一些端口和resourcemanager的节点

slaves
配了几个节点就写几个

配置完成后,分发到其余节点(scp -r /home/softwares/hadoop-2.6.1/ follower:/home/softwares/hadoop-2.6.1)
并修改从节点的环境变量,添加hadoop路径到环境变量,并生效。
三.启动集群
1、初始化NameNode
进入到hadoop安装目录(/home/softwares/hadoop-2.6.1),命令:bin/hdfs namenode -format。
在最后部分看到:INFO common.Storage: Storage directory /home/softwares/hadoop-2.7.3/data/tmp/dfs/name has been successfully formatted 才是初始化成功。
2、启动集群
命令:start-all.sh
查看进程命令:jps
主节点的NameNode和DataNode,和从节点的DataNode都启动成功,表示安装成功。


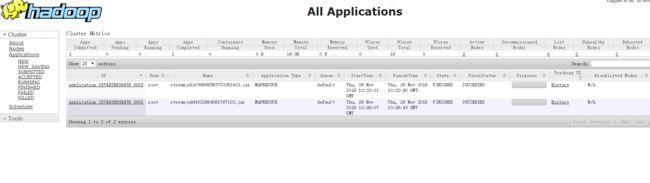
启动成功后,登录页面192.168.31.160:50070(主节点IP地址:50070)

Yarn的界面192.168.31.161:8088