Activity启动流程(五)请求并创建目标Activity进程
请求并创建目标Activity进程
Android四大组件源码实现详解系列博客目录:
Android应用进程创建流程大揭秘
[Android四大组件之bindService源码实现详解
Android四大组件之Activity启动流程源码实现详解概要
Activity启动流程(一)发起端进程请求启动目标Activity
Activity启动流程(二)system_server进程处理启动Activity请求
Activity启动流程(三)-Activity Task调度算法复盘分析
Activity启动流程(四)-Pause前台显示Activity,Resume目标Activity
Activity启动流程(五)请求并创建目标Activity进程
Activity启动流程(六)注册目标Activity进程到system_server进程以及创建目标Activity进程Application
Activity启动流程(七)初始化目标Activity并执行相关生命周期流程
本篇博客编写思路总结和关键点说明:
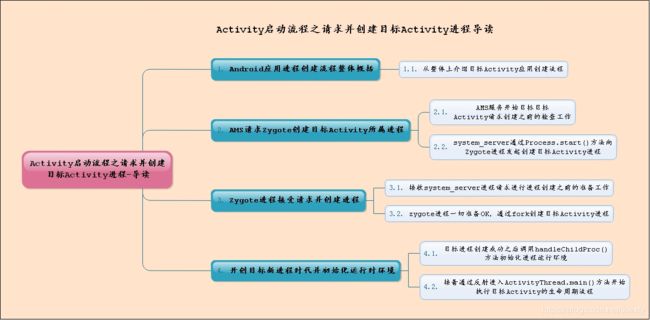
为了更加方便的读者阅读博客,通过导读思维图的形式将本博客的关键点列举出来,从而方便读者取舍和阅读!
引言
还记得我们在前面博客Activity启动流程(四)Pause前台显示Activity,Resume目标Activity以及更前面一系列博客中做的艰苦卓越的斗争吗!这些战役之惨烈,战况之持久前所未有!虽然过程是疼苦的,但是战果也是显赫和令人满意的,通过上述战役我们不仅消灭了启动目标Activity落上的各种拦路虎圆满完成了启动目标Activity请求阶段的重任,并且更是取得了如下的阶段性成果(不是老王卖瓜自卖自夸啊!):
- 为目标Activity创建了ActivityRecord,从而在AMS中目标Activity有了相关的信息档案
- 为目标Activity安排好了TaskRecord任务栈以及Stack栈,并且为其在上述结构中安排好了合适的位置
- Pause好了前台相关的Activity
但是上述的努力远远不过,如果我们把Activity的启动比喻为万里长征的话,我们还只完成了Activity的请求阶段,在本篇博客中我将会带领小伙们一起分析目标Activity所属进程的启动流程,其主要包括如下的相关子流程:
- AMS请求Zygote创建目标Activity所属进程
- Zygote孵化目标Activity所属进程
- 初始化目标Activity所属进程
- 注册目标Activity所属进程到system_server
- 目标Activity所属进程创建Application实例对象
注意:本篇的介绍是基于Android 7.xx平台为基础的,其中涉及的代码路径如下:
frameworks/base/services/core/java/com/android/server/am/
--- ActivityManagerService.java
--- ProcessRecord.java
--- ActivityRecord.java
--- ActivityResult.java
--- ActivityStack.java
--- ActivityStackSupervisor.java
--- ActivityStarter.java
--- TaskRecord.java
frameworks/base/services/core/java/com/android/server/pm/
--- PackageManagerService.java
frameworks/base/core/java/android/content/pm/
--- ActivityInfo.java
frameworks/base/core/java/android/app/
--- IActivityManager.java
--- ActivityManagerNative.java (内部包含AMP)
--- ActivityManager.java
--- AppGlobals.java
--- Activity.java
--- ActivityThread.java(内含AT)
--- LoadedApk.java
--- AppGlobals.java
--- Application.java
--- Instrumentation.java
--- IApplicationThread.java
--- ApplicationThreadNative.java (内部包含ATP)
--- ActivityThread.java (内含ApplicationThread)
--- ContextImpl.java
frameworks/base/core/java/com/android/internal/os/*
---ZygoteConnection.java
---Zygote.java
---ZygoteInit.java
---RuntimeInit.java
frameworks/base/core/java/android/os/Process.java
frameworks/base/core/jni/include/android_runtime/AndroidRuntime.h
frameworks/base/core/jni/AndroidRuntime.cpp
frameworks/base/cmds/app_process/App_main.cpp
libcore/libart/src/main/java/java/lang/Daemons.java
libcore/dalvik/src/main/java/dalvik/system/ZygoteHooks.java
art/runtime/native/dalvik_system_ZygoteHooks.cc
art/runtime/runtime.cc
frameworks/base/core/jni/com_android_internal_os_Zygote.cpp
bionic/libc/bionic/fork.cpp
bionic/libc/bionic/pthread_atfork.cpp
art/runtime/native/dalvik_system_ZygoteHooks.cc
art/runtime/runtime.cc
art/runtime/signal_catcher.cc
并且在后续的源码分析过程中为了简述方便,会将做如下简述:
- ApplicationThreadProxy简称为ATP
- ActivityManagerProxy简称为AMP
- ActivityManagerService简称为AMS
- ActivityManagerNative简称AMN
- ApplicationThreadNative简称ATN
- PackageManagerService简称为PKMS
- ApplicationThread简称为AT
- ActivityStarter简称为AS,这里不要和ActivityServices搞混淆了
- ActivityStackSupervisor简称为ASS
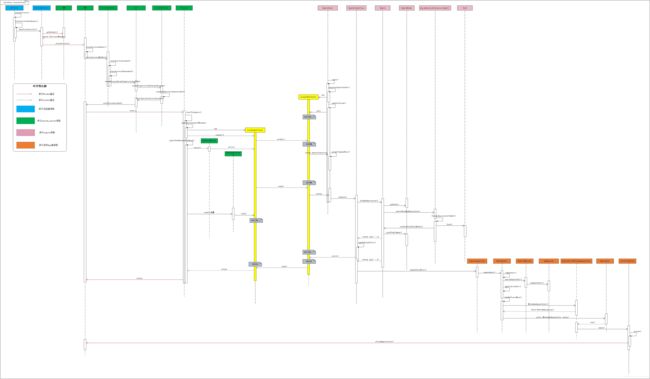
在正式开始今天博客相关源码分析前,还是先奉上Activity启动调用的整体时序图以便小伙们先从整体上有个清晰的概括,然后再从细节开撸!

一. Android应用进程创建流程整体概括
关于Android应用进程创建我有写过一个专门的博客Android应用进程创建流程大揭秘 ,但是是以Android 9为原型开展的,虽然创建流程和Android 7的源码逻辑相差不是很大,但是其中还是有些差异的,并且本文是一个一系列的专题文章,所以感觉还是关于这部分还是花点时间对Android 7的版本重新梳理,花点时间重新来一遍。在这里先来奉上一张Android应用冷启动进程创建的完整流程图,内容比较多,有兴趣的可以跟着图走一圈看看。
上图是Android应用进程创建的整个详细流程图,东西有点多!好吗,我们还是简化一下,从整体架构上入手来分析,这样可能会容易一些,也容易开啃一些!
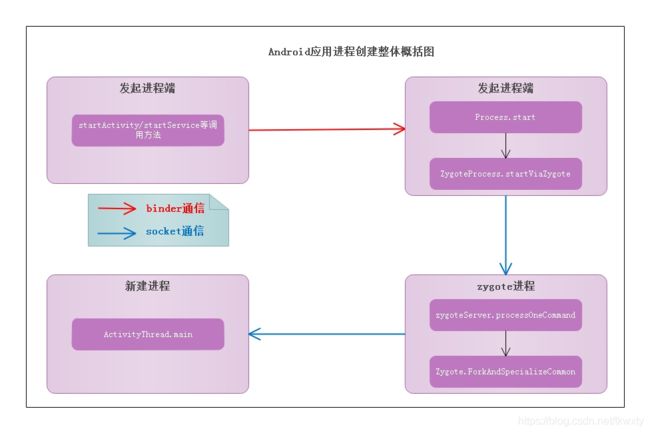
上面的图示涉及到了几个中要的角色,下面我们来分别介绍介绍:
-
发起进程端:这里的的发起端通常指代我们的桌面Launhcer,如果是从某App内启动远程进程,则发送进程便是该App所在进程。发起进程先通过Binder关联AMS服务发送消息给system_server进程
-
system_server进程:system_server进程在收到启动Activity/Service以后,其中的AMS服务经过一系列的处理,最终调用Process.start开启进程创建的流程,在这个阶段主要是和zygote进程建立socket连接,将要创建的进程的相关数据发送过去,在这个阶段system_server对于发起端进程来说扮演的是服务端,而对于zygote进程来说system_server扮演的客户端角色
-
zygote进程:通过前面的篇章分析我们知道,在Android终端启动过程中,Zygote进程就已经早早的启动了,然后会创建LocalServerSocket服务端等待客户端的请求,然后在runSelectLoop开启了一个死循环静候accept客户端的连接,当system_server进程收到发起端进程的请求之后,就会创建LocalSocket和zygote进程的LocalServerSocket通信从而进行send/recev数据了,此时将相关数据发送给LocalServerSocket告知我要创建一个进程。进程fork完成之后,返回结果给system_sever进程的AMS。
-
新建进程:Zygote进程把进程fork出来之后,需要做进程的初始化操作,比如设置进程异常的捕获方式,开始Binder线程池等等,最后进入了ActivityThread的main方法,从而到这里一个有血有肉的进程正式被启动了
二. AMS请求Zygote创建目标Activity所属进程
在前面的博客Activity启动流程(四)- Pause前台显示Activity,Resume目标Activity最后我们知道,在Resume目标Activity时如果目标Activity所在的App进程还没有创建,则会调用startSpecificActivityLocked来发起创建目标进程,让我们朝着目标发起猛烈跑火开干!
注意,注意,注意:
Activity的启动过程中,存在一种特殊情况就是假如目标Activity在AndroidManifest.xml中配置了android:process相关的属性,那怕目标Activity所属进程已经创建了依然会走startSpecificActivityLocked流程创建Activity专有的Process,这个一定要注意!
<activity
android:name="com.example.test.BActivity"
android:process=":process"
>
activity>
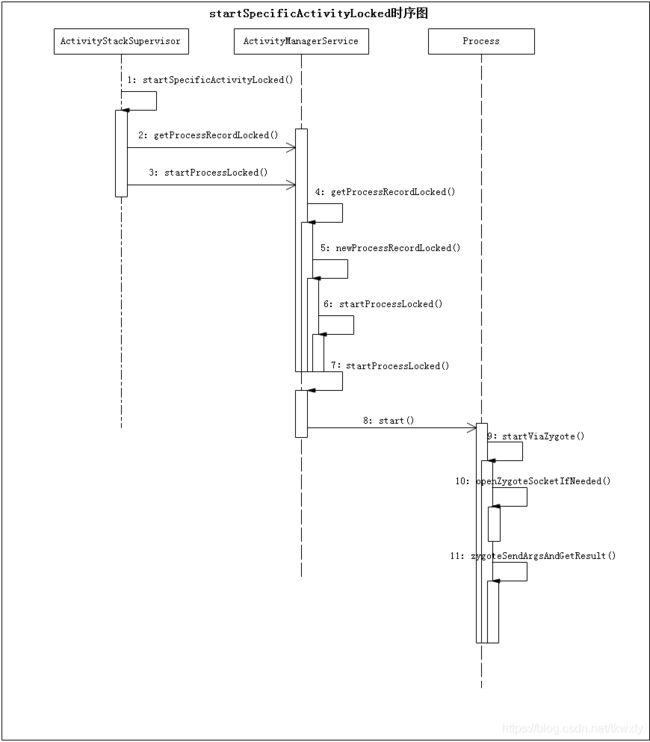
2.1 ASS.startSpecificActivityLocked(…)
当我们第一次启动目标Activity时,其所对应的进程肯定还没有创建则会进入此方法中。此方法命名很霸气啊Specific,那就让我们看看它有啥Specific的,难不成它是内裤外穿不成。
//[ActivityStackSupervisor.java]
void startSpecificActivityLocked(ActivityRecord r, //目标Activity相关信息
boolean andResume, //此时传递的参数值为true
boolean checkConfig) //此时传递的参数值为false
{
//检查目标Activity所属的应用进程是否创建,假如是冷启动的情况当然是木有创建的
ProcessRecord app = mService.getProcessRecordLocked(r.processName,
r.info.applicationInfo.uid, true);
r.task.stack.setLaunchTime(r);
/*
当目标Activity对应的App进程和进程对应的ApplicationThread被创建时,进入此分支,此时的我们是木有机会了
*/
if (app != null && app.thread != null) {
//
try {
/*
判断此Activity是否携带FLAG_MULTIPROCESS或者其对应的进程名是"android"
那"android"对应的进程到底是啥呢,其实它是system_server,这个是在zygote孵化它时指定的
*/
if ((r.info.flags&ActivityInfo.FLAG_MULTIPROCESS) == 0
|| !"android".equals(r.info.packageName)) {
app.addPackage(r.info.packageName, r.info.applicationInfo.versionCode,
mService.mProcessStats);
}
//正式启动目标Activity,开启生命周期
realStartActivityLocked(r, app, andResume, checkConfig);
return;
} catch (RemoteException e) {
...
}
}
//调用AMS开启startProcess处理流程
mService.startProcessLocked(r.processName, r.info.applicationInfo, true, 0,
"activity", r.intent.getComponent(), false, false, true);//详见章节2.2
}
分析一番下来,该方法并没有内裤外穿仅仅是做了一些常规检查和处理,其主要逻辑如下:
- 在开启创建目标Activity对应的进程之前,再次检查目标Activity对应的ProcessRecord是否创建,如果已经创建则直接启动目标Activity
- 如若木有,则交由AMS的startProcessLocked方法继续处理下一流程
2.2 AMS.startProcessLocked(String processName,…)
在AMS中startProcessLocked方法被重载了很多次,所以在接下来的分析中一定得注意不要搞错了!而且startProcessLocked涉及的参数也很多,说实话其中有些参数的作用很多我也没有整明白,但是这并不妨碍我们对整体流程的分析!
//[ActivityManagerService.java]
final ProcessRecord startProcessLocked(String processName,//目标Activity对应的进程名,通常上是包名
ApplicationInfo info, //Activity所属App的Application信息
boolean knownToBeDead, //这个参数具体意义不明,传递过来的值为true
int intentFlags,//参数的值为0
String hostingType, //这个参数意义不明,参数值为"activity"
ComponentName hostingName, //启动目标Activity时解析intent时得到的ComponentName值
boolean allowWhileBooting,//是否允许在开启启动时,参数未false
boolean isolated, //参数为false,这个值的意思是该进程是否是以隔离模式启动
boolean keepIfLarge) //参数意义不明,传递的值为true
{
return startProcessLocked(processName, info, knownToBeDead, intentFlags, hostingType,
hostingName, allowWhileBooting, isolated, 0 /* isolatedUid */, keepIfLarge,
null /* ABI override */, null /* entryPoint */, null /* entryPointArgs */,
null /* crashHandler */);
}
此方法很懒,啥也没有干直接调用了另外一个重载的startProcessLocked方法!
//[ActivityManagerService.java]
//这个参数够多的,真是够多的
final ProcessRecord startProcessLocked(String processName, //目标Activity对应的进程名,通常上是包名
ApplicationInfo info,//Activity所属App的Application信息
boolean knownToBeDead, //这个参数具体意义不明,传递过来的值为true
int intentFlags, //参数的值为0
String hostingType, //这个参数意义不明,参数值为"activity"
ComponentName hostingName,//启动目标Activity时解析intent时得到的
boolean allowWhileBooting, //是否允许在开启启动时,参数未false
boolean isolated, //参数为false,这个值的意思是该进程是否是隔离的
int isolatedUid, //指定隔离进程的UID
boolean keepIfLarge,//参数意义不明,传递的值为true
String abiOverride, //是否覆盖目标Activity所属app安装时的abi,abi通常影响so库的选择,取值为null
String entryPoint, //参数意义不明,取值为null
String[] entryPointArgs, //参数意义不明,取值为null
Runnable crashHandler) //参数意义不明,取值为null
{
...
ProcessRecord app;
if (!isolated) {
//当不是隔离进程时
/*
获取AMS中是否存在目标Activity所属进进程的ProcessRecord记录,在非isolated模式下AMS可以重用先前的ProcessRecord记录
这里小伙们肯定有个疑问就是为啥startSpecificActivityLocked中检查了一次,这里又检查一次,
而和startSpecificActivityLocked处理不同的是这里并没有因为ProcessRecord的存在而停止后续的脚步呢
好吗,此处的逻辑感觉有点不是很清晰啊
*/
app = getProcessRecordLocked(processName, info.uid, keepIfLarge);
// 启动参数中,带有FLAG_FROM_BACKGROUND标志,表示进程需要后台启动
if ((intentFlags & Intent.FLAG_FROM_BACKGROUND) != 0) {
// 后台启动一个BadProcess,直接退出
if (mAppErrors.isBadProcessLocked(info)) {
return null;
}
} else {
//清理进程Crash消息
mAppErrors.resetProcessCrashTimeLocked(info);
if (mAppErrors.isBadProcessLocked(info)) {
// 前台启动,则需要将宿主进程从坏的进程中剔除
mAppErrors.clearBadProcessLocked(info);
if (app != null) {
app.bad = false;
}
}
}
} else {
app = null;
}
/*
此处涉及到了超自然现象,看注释的意思是对于大小核的架构的设备的话,此时使用cpuset将前台任务迁移到大核上
这个已经超过本人的能力范畴之外了,pass
*/
nativeMigrateToBoost();
mIsBoosted = true;
...
// 当进程已经被分配了PID时
if (app != null && app.pid > 0) {
// 进程还处于启动的过程中
if ((!knownToBeDead && !app.killed) || app.thread == null) {
app.addPackage(info.packageName, info.versionCode, mProcessStats);
return app;
}
/*
这个地方要怎么理解呢,可能前面目标Activity所属App进程被创建过
但是已经over了再启动时需要对其做一些清理工作
*/
killProcessGroup(app.uid, app.pid);
handleAppDiedLocked(app, true, true);
}
String hostingNameStr = hostingName != null
? hostingName.flattenToShortString() : null;
if (app == null) {
//在AMS中创建ProcessRecord信息记录
app = newProcessRecordLocked(info, processName, isolated, isolatedUid);//详见章节2.3
if (app == null) {
return null;
}
//设置crashHandler
app.crashHandler = crashHandler;
} else {
app.addPackage(info.packageName, info.versionCode, mProcessStats);
}
// 如果系统还未启动,则需要将待启动进程先保持住,等系统启动后,再来启动这些进程
//final ArrayList mProcessesOnHold = new ArrayList();
if (!mProcessesReady
&& !isAllowedWhileBooting(info)
&& !allowWhileBooting) {
if (!mProcessesOnHold.contains(app)) {
mProcessesOnHold.add(app);
}
return app;
}
//又调用另外一个重载的startProcessLocked
startProcessLocked(
app, hostingType, hostingNameStr, abiOverride, entryPoint, entryPointArgs);//详见章节2.4
return (app.pid != 0) ? app : null;
}
这里可以看到上述方法的处理逻辑主要体现在三个方面:
-
首先判断是否是以isolated模式启动的目标Activity所属App进程,那么这个solated模式是什么意思呢,网上说通过isolated来判断要启动的进程是否是隔离的,当为true时意味着这是一个隔离的进程(虽然这么说,但是本人是没有搞明白,这个隔离到底隔离的是啥,如果对此处有比较深入的小伙们可以告诉我)。
对于隔离的进程而言,每次启动都是独立的,不能复用已有的进程信息。如果要启动一个非隔离的进程,那么就需要区分进程是在前台启动还是后台启动,这是用户体验相关的设计。在AMS中维护了一个badProcesses的结构体,用于保存一些“坏进程”,什么才是“坏进程”呢?如果一个进程在一分钟内连续崩溃两次,那就变成了一个“坏进程”。对于后台启动的进程而言(即启动参数中带有FLAG_FROM_BACKGROUND标识),如果进程崩溃了,会造成用户使用的困惑,因为进程崩溃时,会弹出一个对话框,而后台启动的进程是没有任何操作界面的,这时候弹一个框,用户会觉得自己什么都没干,却弹出了一个对话框。所以,后台启动一个“坏进程”时,会直接退出。
当进程是在前台启动时,即便是一个"坏进程",那也应该宽恕这个进程以前的不良记录,因为这通常是用户通过界面主动要唤起的进程。本着用户是上帝的原则,还是得让用户达到启动进程的目的,即便这个进程可能再次崩溃。 -
接着判断目标Activity所对应的ProcessRecord是否创建,如果还没有创建这时候会调用AMS.newProcessRecord来创建一个新的ProcessRecord
-
接着调用AMS的另一个重载方法startProcessLocked继续目标Activity对应进程创建的处理流程
2.3 AMS.newProcessRecordLocked(…)在AMS中创建目标Activity对应的Process记录
//[ActivityManagerService.java]
final ProcessRecord newProcessRecordLocked(ApplicationInfo info, String customProcess,
boolean isolated, int isolatedUid) {
String proc = customProcess != null ? customProcess : info.processName;
//电量统计相关
BatteryStatsImpl stats = mBatteryStatsService.getActiveStatistics();
final int userId = UserHandle.getUserId(info.uid);
int uid = info.uid;
//根据isolated模式调整uid,至于怎么具体调整的这块我还没有整明白,就忽略了
if (isolated) {
if (isolatedUid == 0) {
int stepsLeft = Process.LAST_ISOLATED_UID - Process.FIRST_ISOLATED_UID + 1;
while (true) {
if (mNextIsolatedProcessUid < Process.FIRST_ISOLATED_UID
|| mNextIsolatedProcessUid > Process.LAST_ISOLATED_UID) {
mNextIsolatedProcessUid = Process.FIRST_ISOLATED_UID;
}
uid = UserHandle.getUid(userId, mNextIsolatedProcessUid);
mNextIsolatedProcessUid++;
if (mIsolatedProcesses.indexOfKey(uid) < 0) {
break;
}
stepsLeft--;
if (stepsLeft <= 0) {
return null;
}
}
} else {
uid = isolatedUid;
}
}
//根据传入的参数和获取到的uid信息构建ProcessRecord
final ProcessRecord r = new ProcessRecord(stats, info, proc, uid);
if (!mBooted && !mBooting
&& userId == UserHandle.USER_SYSTEM
&& (info.flags & PERSISTENT_MASK) == PERSISTENT_MASK) {
r.persistent = true;
}
addProcessNameLocked(r);//将ProcessRecord信息在AMS中存储起来
/*************************************************/
private final void addProcessNameLocked(ProcessRecord proc) {
ProcessRecord old = removeProcessNameLocked(proc.processName, proc.uid);
if (old == proc && proc.persistent) {
} else if (old != null) {
}
UidRecord uidRec = mActiveUids.get(proc.uid);
if (uidRec == null) {
uidRec = new UidRecord(proc.uid);
mActiveUids.put(proc.uid, uidRec);
noteUidProcessState(uidRec.uid, uidRec.curProcState);
enqueueUidChangeLocked(uidRec, -1, UidRecord.CHANGE_ACTIVE);
}
proc.uidRecord = uidRec;
uidRec.numProcs++;
mProcessNames.put(proc.processName, proc.uid, proc);
if (proc.isolated) {
mIsolatedProcesses.put(proc.uid, proc);
}
}
/*************************************************/
return r;
}
该方法无需动脑,逻辑也比较简单:
- 根据isolated的情况,调试uid的取值(这个地方先忽略了)
- 根据ApplicaitonInfo,uid等相关参数创建一个ProcessRecord,并将ProcessRecord加入AMS的管理范围,与此同时,与进程相关的电量统计也是在这一步被绑定上的
2.4 AMS.startProcessLocked(ProcessRecord app,…)依然范特西
注意将此处的方法startProcessLocked和2.2章节中的区分开来,其参数是完全不同的!此时表示目标Activity对应的rocessRecord已经构建好了,但是仅此而已,此时只是在AMS中有了相关Process的记录但是对应的进程是没有创建的,所以革命尚未成功同志仍需努力啊!继续干!
//[ActivityManagerService.java]
private final void startProcessLocked(ProcessRecord app,
String hostingType,
String hostingNameStr,
String abiOverride,
String entryPoint,
String[] entryPointArgs) {
if (app.pid > 0 && app.pid != MY_PID) {
// 新启动进程了,清除超时消息设置
synchronized (mPidsSelfLocked) {
mPidsSelfLocked.remove(app.pid);
mHandler.removeMessages(PROC_START_TIMEOUT_MSG, app);
}
app.setPid(0);
}
// 在HoldProcess中移除app
mProcessesOnHold.remove(app);
updateCpuStats();
...
try {
try {
// gid与进程的访问权限相关处理
//获取userId,通常为0
final int userId = UserHandle.getUserId(app.uid);
// 检查应用的package状态
AppGlobals.getPackageManager().checkPackageStartable(app.info.packageName, userId);
} catch (RemoteException e) {
}
int uid = app.uid;
int[] gids = null;
int mountExternal = Zygote.MOUNT_EXTERNAL_NONE;
if (!app.isolated) {
...
}
...
int debugFlags = 0;
// debugFlags相关的处理,与进程的调试选项相关处理,不过多分析
//我们为了调试通常会在AndroidManifest中配置android:debuggable="true"的参数
if ((app.info.flags & ApplicationInfo.FLAG_DEBUGGABLE) != 0) {
debugFlags |= Zygote.DEBUG_ENABLE_DEBUGGER;
debugFlags |= Zygote.DEBUG_ENABLE_CHECKJNI;
}
//primaryCpuAbi的值在应用安装的时候已经确定了,这个牵涉到应用的安装解析apk包的问题了
String requiredAbi = (abiOverride != null) ? abiOverride : app.info.primaryCpuAbi;
if (requiredAbi == null) {
/*
如果requiredAbi为null,使用系统支持的CPUABI列表中的第一个
public static final String[] SUPPORTED_ABIS = getStringList("ro.product.cpu.abilist", ",");
XXX:/ # getprop | grep abi
[ro.product.cpu.abi]: [armeabi-v7a]
[ro.product.cpu.abi2]: [armeabi]
[ro.product.cpu.abilist]: [armeabi-v7a,armeabi]
[ro.product.cpu.abilist32]: [armeabi-v7a,armeabi]
[ro.product.cpu.abilist64]: []
*/
requiredAbi = Build.SUPPORTED_ABIS[0];
}
String instructionSet = null;
if (app.info.primaryCpuAbi != null) {
// 查找CPUABI对应的指令集
// armeabi => arm
// armeabi-v7a => arm
// arm64-v8a => arm64
instructionSet = VMRuntime.getInstructionSet(app.info.primaryCpuAbi);
}
/*
关于CpbAbi感兴趣的,可以参见微信官方的文章https://mp.weixin.qq.com/s?__biz=MzA3NTYzODYzMg==&mid=2653577702&idx=1&sn=1288c77cd8fc2db68dc92cf18d675ace&scene=4#wechat_redirect
有非常精辟的讲解
*/
// 将相关的信息赋值给ProcessRecord
app.gids = gids;
app.requiredAbi = requiredAbi;
app.instructionSet = instructionSet;
boolean isActivityProcess = (entryPoint == null);
//设置App进程Java世界的入口,ActivityThread应该是我们的老熟人了,这个后续详细分析
if (entryPoint == null) entryPoint = "android.app.ActivityThread";
//调用Porcess.start继续处理余下逻辑
Process.ProcessStartResult startResult = Process.start(entryPoint,
app.processName, uid, uid, gids, debugFlags, mountExternal,
app.info.targetSdkVersion, app.info.seinfo, requiredAbi, instructionSet,
app.info.dataDir, entryPointArgs);//详见章节2.5
if (app.isolated) {
mBatteryStatsService.addIsolatedUid(app.uid, app.info.uid);
}
// 通知BatteryStatsService进程启动
mBatteryStatsService.noteProcessStart(app.processName, app.info.uid);
...
//如果目标进程是perisitent类型,则watchdog监听它,其主要的目的是为了当persistent类型的app崩溃时将其拉起来
if (app.persistent) {
Watchdog.getInstance().processStarted(app.processName, startResult.pid);
}
...
// 设置ProcessRecord新进程信息
app.setPid(startResult.pid);
app.usingWrapper = startResult.usingWrapper;
app.removed = false;
app.killed = false;
app.killedByAm = false;
...
synchronized (mPidsSelfLocked) {
this.mPidsSelfLocked.put(startResult.pid, app);//此处将ProcessRecord数据put到mPidsSelfLocked中,注意其key为pid,这个会在后续用到
if (isActivityProcess) {
// 设置应用进程attach到ActivityManagerService的超时检测
Message msg = mHandler.obtainMessage(PROC_START_TIMEOUT_MSG);
msg.obj = app;
mHandler.sendMessageDelayed(msg, startResult.usingWrapper
? PROC_START_TIMEOUT_WITH_WRAPPER : PROC_START_TIMEOUT);
}
}
} catch (RuntimeException e) {
//异常处理
...
}
}
上述的源码关于进程创建启动相关设置的参数处理这部分的逻辑就不展开了(主要就是一些uid权限调整和debugFlags参数的设置),不然那就完全陷入源码中不能自拔了。总之在这个方法中对于传递过来的相关参数一顿处理,然后调用Process类的start方法继续进程的创建!
2.5 Process.start(…)
//[Porcess.java]
public static final ProcessStartResult start(
final String processClass,
final String niceName,
int uid,
int gid,
int[] gids,
int debugFlags,
int mountExternal,
int targetSdkVersion,
String seInfo,
String abi,
String instructionSet,
String appDataDir,
String[] zygoteArgs) {
try {
return startViaZygote(processClass, niceName, uid, gid, gids,
debugFlags, mountExternal, targetSdkVersion, seInfo,
abi, instructionSet, appDataDir, zygoteArgs);//详见章节2.6
} catch (ZygoteStartFailedEx ex) {
throw new RuntimeException(
"Starting VM process through Zygote failed", ex);
}
}
该方法是个"狠人",做事毫不拖泥带水直接调用startViaZygote进行下一步处理,但是其中涉及的参数我们还是先梳理梳理,以便在后面使用到的时候不认识它,得先混个脸熟不!
| 参数类型 | 参数名称 | 参数含义 |
|---|---|---|
| String | processClass | 目标进程入口类名全称,通常App进程的对应的入参为"android.app.ActivityThread" |
| String | niceName | 进程名(通常对应启动App进程的包名) |
| int | uid | 进程uid |
| int | gid | 进程group uid(通常等于uid) |
| int[] | gids | 进程所属额外的group ids |
| int | debugFlags | 进程调试相关标志位 |
| int | mountExternal | 不好意思,我也没有搞清楚这个是啥意思,官方注释都没有给一个注释 |
| int | targetSdkVersion | App进程目标SDK版本 |
| String | seInfo | 进程SELinux相关的信息 |
| String | abi | 目标App进程将会以什么abi运行 |
| String | instructionSet | 进程运行的指令集 |
| String | appDataDir | 应用的数据路径(/data/user/0/xxx) |
| String | zygoteArgs | 提供给zygote进程的附加信息 |
如果对上面的参数还是感到有点抽象的话,可以使用如下命令查看进程相关内容,我们这里下面的列子为例说明,这下小伙们应该明白了。
adb shell dumpsys activity processes
*APP* UID 10046 ProcessRecord{
9d37710 6506:com.example.test/u0a46}
user #0 uid=10046 gids={
50046, 9997, 1015, 1023}
requiredAbi=armeabi-v7a instructionSet=null
dir=/data/app/com.example.test-1/base.apk publicDir=/data/app/com.example.test-1/base.apk data=/data/user/0/com.example.test
packageList={
com.example.test}
compat={
320dpi}
thread=android.app.ApplicationThreadProxy@786195d
pid=6506 starting=false
lastActivityTime=-34s770ms lastPssTime=-1m23s971ms nextPssTime=+35s933ms
adjSeq=676 lruSeq=0 lastPss=13MB lastSwapPss=0.00 lastCachedPss=0.00 lastCachedSwapPss=0.00
cached=false empty=false
oom: max=1001 curRaw=0 setRaw=0 cur=0 set=0
curSchedGroup=2 setSchedGroup=2 systemNoUi=false trimMemoryLevel=0
vrThreadTid=0 curProcState=2 repProcState=2 pssProcState=2 setProcState=2 lastStateTime=-1m43s128ms
hasShownUi=true pendingUiClean=true hasAboveClient=false treatLikeActivity=false
reportedInteraction=true time=-34s771ms
hasClientActivities=false foregroundActivities=true (rep=true)
lastRequestedGc=-1m43s130ms lastLowMemory=-1m43s130ms reportLowMemory=false
Activities:
- ActivityRecord{
7542801 u0 com.example.test/.MainActivity t7}
Connected Providers:
- c76b1b9/com.android.providers.settings/.SettingsProvider->6506:com.example.test/u0a46 s1/1 u0/0 +1m43s29ms
2.6 Process.startViaZygote(…)
此方法的名称,我喜欢,很贴切现实接地气,但是吗用中文表述吗有没有那个味道了,小伙们自行体会下该方法名称吗! 我们知道zygote是Android世界的孵化大师,当Android终端在启动过程中创建了zygote进程之后,历史的重任就赋予在zygote身上了。zygote的重任主要就是孵化,而zygote进程对于孵化有两种不同的处理逻辑:
-
第一种就是zygote感觉自身担子太重了,所以必须得培养一个得力干将,从而zygote主动孵化了system_server进程来处理一些重要的事务,这个就是我们在章节系统启动之SystemServer大揭秘中重点介绍的。
-
第二种情况就是zygote主动孵化完system_server进程之后,进入runSelectLoop循环中被动接受等待客户端的请求(通常是AMS服务),进而孵化进程,这个是最常见的。此时的App进程的创建就是属于这个的套路
而这里的startViaZygote方法正是开启通向zygote进程的钥匙,让我们看看它是如何和zygote进程"勾搭上的"。
//[Porcess.java]
private static ProcessStartResult startViaZygote(final String processClass,
final String niceName,
final int uid, final int gid,
final int[] gids,
int debugFlags, int mountExternal,
int targetSdkVersion,
String seInfo,
String abi,
String instructionSet,
String appDataDir,
String[] extraArgs)
throws ZygoteStartFailedEx {
synchronized(Process.class) {
//通过列表argsForZygote保存传递给zygote进程的参数
ArrayList<String> argsForZygote = new ArrayList<String>();
argsForZygote.add("--runtime-args");
argsForZygote.add("--setuid=" + uid);
argsForZygote.add("--setgid=" + gid);
...
/*
该方法花开两朵各表一枝,谷歌的工程师玩的满满的都是套路啊!
这两朵花,详见章节2.7和章节2.8
*/
return zygoteSendArgsAndGetResult(openZygoteSocketIfNeeded(abi), argsForZygote);
}
该方法平谈无奇,没有什么难点的知识点主要就是将传递参数封装到argsForZygote列表中,该列表主要保存了uid,gid,nice-name等相关的信息。经过如上一番封装以后接着调用zygoteSendArgsAndGetResult请求Zygotefork进程。
2.7 Process.openZygoteSocketIfNeeded(…)
在开始该源码相关的分析前,我们要先有一个概念就是由于现在的Android设备处理器存在32位和64位两种情况(并且绝大都是64位的设备终端了)。但是由于Android的碎片化太严重了,应用的适配通常是没有跟上时代的脚步,所以Android为了照顾这种情况还是允许在64位终端上以32位的情况运行App进程,而决定这个就是abi的取值(即在64位终端上App即可以32位运行也可以以64位运行,这个需要根据实际情况决定:)!
XXX:/ # ps | grep zygote
root 754 1 2172496 83288 poll_sched 7f8775ca10 S zygote64
root 755 1 1599324 71032 poll_sched 00f6e306d4 S zygote
//[Process.java]
/**
如果还没有创建Socket通信通道,则会创建Socket用于与Zygote通信
ZygoteState用于管理与Zygote通信的状态
通常在arm64系统中,通常primaryZygoteState与secondaryZygoteState分别对应zygote和zygote_secondary
进程Zygote64与Zygote(取决于*.rc文件配置)
**/
private static ZygoteState openZygoteSocketIfNeeded(String abi) throws ZygoteStartFailedEx {
if (primaryZygoteState == null || primaryZygoteState.isClosed()) {
try {
//向主zygote发起connect()连接操作
primaryZygoteState = ZygoteState.connect(ZYGOTE_SOCKET);//详见章节2.7.1
} catch (IOException ioe) {
throw new ZygoteStartFailedEx("Error connecting to primary zygote", ioe);
}
}
// 检查abi是否匹配primaryZygoteState
if (primaryZygoteState.matches(abi)) {
return primaryZygoteState;
}
if (secondaryZygoteState == null || secondaryZygoteState.isClosed()) {
try {
//退而求其次,如果主zygote没有匹配成功的话,向次zygote发起connect()操作,备胎计划
secondaryZygoteState = ZygoteState.connect(SECONDARY_ZYGOTE_SOCKET);
} catch (IOException ioe) {
throw new ZygoteStartFailedEx("Error connecting to secondary zygote", ioe);
}
}
//检查abi是否匹配secondaryZygoteState
if (secondaryZygoteState.matches(abi)) {
return secondaryZygoteState;
}
throw new ZygoteStartFailedEx("Unsupported zygote ABI: " + abi);
}
openZygoteSocketIfNeeded方法主要通过传递进来的abi判断当前是要和zygote进程还是和zygote64进程通信(我们先不对其中涉及的重要方法ZygoteState.connect做讨论,这个后面的小章节分析),其主要的处理逻辑如下:
-
先判断是否已经和主zygote进程建立了连接,如果已经建立了连接不做任何处理
-
如果传递进来的abi和已经建立的primaryZygoteState匹配上了,那么就返回该primaryZygoteState
-
接下来判断是否和次zygote进程建立了连接,如果已经建立了连接不做任何处理
-
如果传递进来的abi和已经建立的secondaryZygoteState 匹配上了,那么就返回该secondaryZygoteState
总之通过上述的方法我们建立了和zygote进程的socket通信的通道,为后续的参数传递和数据的接收打好了基础,至于这个通道是怎么建立的我们接着往下分析!
2.7.1 ZygoteState.connect(…)
在开始该方法的分析前,如果小伙们对LocalSocket通信和Zygote的孵化和通信交互还没有一个基本的概念的话,强烈建议小伙们先阅读一下 Android LocalSocket通信实战和Android Zygote进程启动源码分析指南等相关博客。总之我们需要知道zygote进程启动成功之后会创建如下的两个LocalSocket通信端口,然后在runSelectLoop不断主动监听是否有客户端的请求连接:
XXX:/dev/socket # ls -la | grep zygote
srw-rw---- 1 root system 0 2020-10-23 15:08 zygote
srw-rw---- 1 root system 0 2020-10-23 15:08 zygote_secondary
好了,叽歪了大半天了,是时候进入正题了分析相关的源码了!
//[Porcess.java]
public static final String ZYGOTE_SOCKET = "zygote";
public static final String SECONDARY_ZYGOTE_SOCKET = "zygote_secondary";
public static class ZygoteState {
final LocalSocket socket;//和zygote通信的socket套接字
final DataInputStream inputStream;//输入数据流
final BufferedWriter writer;//输出数据流
final List<String> abiList;//abi列表
...
public static ZygoteState connect(String socketAddress) throws IOException {
DataInputStream zygoteInputStream = null;
BufferedWriter zygoteWriter = null;
final LocalSocket zygoteSocket = new LocalSocket();
try {
//和zygote中的localsocketserver端通信,建立和其通信的socket连接
zygoteSocket.connect(new LocalSocketAddress(socketAddress,
LocalSocketAddress.Namespace.RESERVED));
//创建输入数据流
zygoteInputStream = new DataInputStream(zygoteSocket.getInputStream());
//创建输出数据流
zygoteWriter = new BufferedWriter(new OutputStreamWriter(
zygoteSocket.getOutputStream()), 256);
} catch (IOException ex) {
try {
zygoteSocket.close();
} catch (IOException ignore) {
}
throw ex;
}
String abiListString = getAbiList(zygoteWriter, zygoteInputStream);
Log.i("Zygote", "Process: zygote socket opened, supported ABIS: " + abiListString);
//将上述相关的数据封装起来放在ZygoteState中返回回去
return new ZygoteState(zygoteSocket, zygoteInputStream, zygoteWriter,
Arrays.asList(abiListString.split(",")));
}
...
}
我们知道当zygote进程启动之后,会创建localsocketserver,然后在会在runSelectLoop中不断监听客户端的请求,然后进一步处理客户端的请求,而我们此时的AMS就是客户端会请求和zygote对应的socket建立通信。
2.8 Process.zygoteSendArgsAndGetResult(…)
花开两朵各表一枝,其中的一枝我们已经分析完结了,是时候分析另外一枝花了(当然不是如花)!这不就安排上了。
//[Process.java]
private static ProcessStartResult zygoteSendArgsAndGetResult(
ZygoteState zygoteState, ArrayList<String> args)
throws ZygoteStartFailedEx {
try {
int sz = args.size();
for (int i = 0; i < sz; i++) {
//检测传递的参数是否符合规则
if (args.get(i).indexOf('\n') >= 0) {
throw new ZygoteStartFailedEx("embedded newlines not allowed");
}
}
//注意这里的zygoteState就是在2.7.1章节里面保存的和zygote进行socket通信的相关数据
final BufferedWriter writer = zygoteState.writer;
final DataInputStream inputStream = zygoteState.inputStream;
//将要发送给zygote进程的数据通过BufferedWriter发送出去
writer.write(Integer.toString(args.size()));
writer.newLine();
for (int i = 0; i < sz; i++) {
String arg = args.get(i);
writer.write(arg);
writer.newLine();
}
writer.flush();
ProcessStartResult result = new ProcessStartResult();
//等待socket服务端(即zygote)返回新创建的进程pid,这里是没有超时机制的,意思是zygote进程端没有返回的话会一直等待在此
result.pid = inputStream.readInt();
result.usingWrapper = inputStream.readBoolean();
if (result.pid < 0) {
throw new ZygoteStartFailedEx("fork() failed");
}
return result;
} catch (IOException ex) {
zygoteState.close();
throw new ZygoteStartFailedEx(ex);
}
}
这个方法主要是通过前面在2.7章节中和Zygote进程建立连接的socket通道向Zygote进程发送创建进程需要的相关信息参数列表,然后此方法进入阻塞等待的状态,等待远端Zygote进程的socket服务端将发送回来新创建的进程pid才继续往下执行。在获取到返回的pid之后,会判断pid是否有效即判断进程是否创建成功(假如返回的pid小于0则肯定是创建失败了),如果创建失败则抛出异常!
这里需要注意的一个问题就是,如果Zygote进程fork进程超时,AMS这端迟迟不能get到返回结果,然后阻塞在独去端会引起什么后果呢?这个是非常严重!
地球人应该知道zygote进程和system_server进程是休戚与共,一荣俱荣一损俱损。试想一下,当 AMS 需要创建进程时, 会通过Socket与zygote 进程通信, 当zygote接收到请求后会fork出一个子进程,并将其 pid 返回给 AMS。需要注意的是,在收到pid之前,AMS会一直持锁等待,而且这里持有的是AMS大锁, 所以就会block其他重要线程, 导致系统卡死,甚至进而Android重启zygote进程,用户反馈内容也会主要围绕 “系统卡死”, “按键没有反应” ,“重启”等等。
那如何解决这个问题?google其实有注意到,准备加一个超时机制,但是一直没有加上,但是这种情况也是治标不治本,解决这种问题还是要具体分析,是内存碎片严重导致fork进程申请page失败,还是其他原因,需要根据Log具体对待。本人在实际的工作中暂时还没有遇到过这种情况,各位可以留意一下在实际中有么有遇到过这种情况。
2.9 AMS请求Zygote创建目标Activity所属进程小结
至此AMS请求zygote创建目标Activity所属进程就告一段落了!而从Activity启动的整个大局观来说AMS的相关处理流程也基本完结了,后续的就是zygote进程fork出来Activity所属进程,然后目标进程启动进行相关的初始化等相关的工作了!我们下面通过重要的伪代码来看看AMS请求Zygote创建目标Activity所属进程的流程如下:
ASS.startSpecificActivityLocked(...)
// 再次查找进程有没有启动
ProcessRecord app = mService.getProcessRecordLocked(r.processName,
r.info.applicationInfo.uid, true);
if (app != null && app.thread != null) {
realStartActivityLocked(...); // 这里会真正地startActivity
}
AMS.startProcessLocked(r.processName,...)
app = newProcessRecordLocked(info, processName, isolated, isolatedUid);.//在AMS中创建目标Activity所属进程相关记录
AMS.startProcessLocked(app,hostingType,...)
// 新进程的进入java世界的入口类
final String entryPoint = "android.app.ActivityThread";
AMS.startProcess(...)
Process.start(entryPoint,...)
Process.startViaZygote(...)
Process.zygoteSendArgsAndGetResult(openZygoteSocketIfNeeded(abi), argsForZygote)
而对于上述流程,我们也可以通过如下的时序图来表示:
Android应用进程的创建相关流程在system_server进程中的工作到此要暂时告一段落了,system_system进程通过zygoteSendArgsAndGetResult已经和zygote进程之间通过socket发送了进程创建的请求和相关参数,这时候就要轮到Zygote进程登场了,此时Zygote进程会被唤醒响应客户端的请求(即system_server进程),接下来我们就要重点介绍的是Zygote创建进程的流程了。
三. Zygote进程接受请求并创建进程
关于此处的逻辑,本来是不准备花费时间进行相关解读的,而是直接从Zygote进程创建完目标进程之后,通过反射调用ActivityThread开启目标进程的入口类开始分析开来!但是想着吗,这个是一个完整的系列博客还是分析讲述一下!
如果对zygote进程fork子进程处理逻辑有深入了解的小伙们,第三章节就可以不用看了!
在正式开始本章节相关的相关逻辑处理前,我们还是要隆重介绍下 Zygote! Zygote含义为受精卵,是人的第一个细胞,其他细胞都是由其分裂出来的。对于Android来说,它是Android Java世界的第一个进程,其他所有Java进程都是由其fork出来的。Java进程也是普通的Linux进程,只不过它运行的是Java虚拟机,所以称为Java进程。一般来说fork都是Linux进程的行为,Java进程是不会也不能调用fork的。Android的Zygote进程起来的时候,已经启动了ART虚拟机,其他参数也初始化好了。前面说了这么多好像没有看出来Zygote进程有啥作用是不!这不就来了,Android会利用Zygote进程然后通过fork机制克隆出一个和原来Zygote进程几乎完全相同的进程(此进程包继承Zygote进程相关的资源和财产),新进程不用再进行初始化操作,只需要修改一些关键参数就可以了,如上的逻辑极大地加快了新建进程的速度和资源的调度。总之一句话Zygote进程会孵化新的进程,新进程会继承自己的资源和财产,然后新进程根据自己的需要定制化的差异成长!
梦里寻他千百度那人却在灯火阑珊处,我们终于来到了Zygote进程的地盘了。通过我们前面的篇章Android Zygote进程启动源码分析指南我们知道zygote进程是由init进程启动的,并且在zygote进程调用ZygoteInit.main()方法完成相关的初始化工作和创建完system_server进程之后会通过runSelectLoop()方法进入无限循环等待客户端的请求,而此时此刻生意已经上门来了,我们的system_server发来了请求我们要处理了。
并且由于Zygote进程接受请求并创建进程的逻辑有点复杂,这里先放上Zygote进程接受客户端AMS请求fork创建目标Activity进程整体时序图,这样小伙们先心里有个谱!
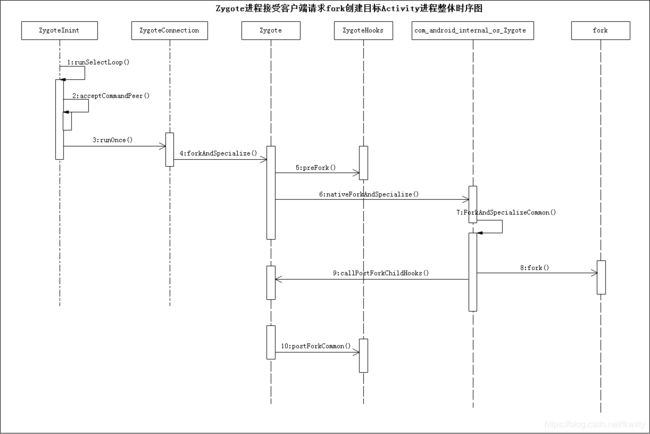
3.1 ZygoteInit.main(…)
//[ZygoteInit.java]
public static void main(String argv[]) {
...
try {
...
//创建zygote通信服务端
registerZygoteSocket(socketName);//详见章节3.2
...
//此处zygote进程开始进入runSelectLoop无限死循环,等待客户端的请求
runSelectLoop(abiList);//详见章节3.3
closeServerSocket();//关闭通信socket通信通道
} catch (MethodAndArgsCaller caller) {
caller.run();//子进程中调用MethodAndArgsCaller的run方法,详见章节3.4
} catch (Throwable ex) {
closeServerSocket();
throw ex;
}
}
还是让我们炒炒冷饭,虽然前面的相关博客已经有分析过了!这里我们只关注三个点:
- Zygote进程调用registerZygoteSocket方法开启LocalSocket通信通道,通道客户端fork进程的请求,而这里的客户端通常是system_server进程
- Zygote进程调用runSelectLoop方法,进入无限死循环等待客户端的请求
- 最后在异常捕获方法中子进程中调用MethodAndArgsCaller的run方法
此处有几点需要注意:
- 在Android O及其之前版本runSelectLoop()方法会抛出异常MethodAndArgsCaller,从而进入caller.run()方法。但是Android P及之后都不是通过抛异常的方法来运行caller.run了而是直接在子进程返回执行,这个是各位需要关注的点
- 还有一点就是不要迷糊着说不是说zygote进程在runSelectLoop中已经无限循环了吗,怎么又跑到后续执行caller.run了,此时执行caller.run不是zygote进程了而是创建的子进程了,各位一点要记住这点
3.2 ZygoteInit.registerZygoteSocket(…)
我们知道Zygote进程需要通过socket通道接受客户端进程的请求,而建立socket通信的的逻辑就在registerZygoteSocket中,其核心代码如下:
//[ZygoteInit.java]
private static final String ANDROID_SOCKET_PREFIX = "ANDROID_SOCKET_";
private static void registerZygoteSocket(String socketName) {
if (sServerSocket == null) {
int fileDesc;
final String fullSocketName = ANDROID_SOCKET_PREFIX + socketName;
try {
//从环境变量获取socket端的服务名
String env = System.getenv(fullSocketName);
fileDesc = Integer.parseInt(env);
} catch (RuntimeException ex) {
throw new RuntimeException(fullSocketName + " unset or invalid", ex);
}
try {
FileDescriptor fd = new FileDescriptor();
fd.setInt$(fileDesc);
//LocalServerSocket,本地socket这个是谷歌改良版本的socket通信方式不同于传统的socket
sServerSocket = new LocalServerSocket(fd);
} catch (IOException ex) {
throw new RuntimeException(
"Error binding to local socket '" + fileDesc + "'", ex);
}
}
}
上述的逻辑并不是很复杂,逻辑主要分为两部分:
- 先从环境变量中获取获取socket端的服务名
- 然后通过获取的服务名,创建LocalServerSocket,这里有一点需要注意的是这里的LocalServerSocket和通常的socket是有区别的,LocalSocket比Java本身的socket效率要高,没有经过协议栈,是Android自己实现的类似共享内存一样的东东,在传输大量数据的时候就需要用到,比如Rild电话,,在创建应用进程和zygote通信,在应用安装过程中和installd通信等等就不一一枚举了。具体参见博客Android Framework层LocalSocket实现通信。
3.3 ZygoteInit.runSelectLoop(…)
在上述的socket通信通道建立之后,Zygote进程就进入runSelectLoop无限循环之中了,Zygote进程已经迫不及待的在等待客户端进程的请求,这不system_server进程的AMS服务发过来了请求,我们看看它究竟是怎么处理的。
//[ZygoteInit.java]
private static void runSelectLoop(String abiList) throws MethodAndArgsCaller {
//注意此处的fds虽然是方法内的list,但是由于while无限循环可以认为fds是一个全局变量
ArrayList<FileDescriptor> fds = new ArrayList<FileDescriptor>();
ArrayList<ZygoteConnection> peers = new ArrayList<ZygoteConnection>();
//sServerSocket是socket通信中的服务端,即zygote进程。保存到fds[0]
fds.add(sServerSocket.getFileDescriptor());
peers.add(null);
while (true) {
//每次循环,都重新创建需要监听的pollFds
StructPollfd[] pollFds = new StructPollfd[fds.size()];
for (int i = 0; i < pollFds.length; ++i) {
pollFds[i] = new StructPollfd();
pollFds[i].fd = fds.get(i);
//关注事件的到来
pollFds[i].events = (short) POLLIN;
}
try {
//处理轮询状态,当pollFds有事件到来则往下执行,否则阻塞在这里
Os.poll(pollFds, -1);
} catch (ErrnoException ex) {
throw new RuntimeException("poll failed", ex);
}
/*
注意这里是倒序处理的,网上有的博客说是优先处理已建立连接的信息,后处理新建连接的请求
我觉得这个表述不是很正确,我觉得采用倒序是为了先处理已经建立连接的请求,但是这个优先反而是后面建立连接的请求有数据到来是优先处理了
然后接着最后处理sServerSocket,此时即有新的客户端要求建立连接
*/
for (int i = pollFds.length - 1; i >= 0; --i) {
//采用I/O多路复用机制,当接收到客户端发出连接请求 或者数据处理请求到来,则往下执行;
// 否则进入continue,跳出本次循环。
if ((pollFds[i].revents & POLLIN) == 0) {
continue;
}
if (i == 0) {
//即fds[0],代表的是sServerSocket因为它最先加入,则意味着有客户端连接请求;
// 则创建ZygoteConnection对象,并添加到fds。
ZygoteConnection newPeer = acceptCommandPeer(abiList);//详见章节3.4
//加入到peers和fds,下一次也开始监听
peers.add(newPeer);
fds.add(newPeer.getFileDesciptor());
}
/*
我想这个方法的难点,小伙们应该是想怎么进入这个分支执行的吗
注意i == 0的时候会fds.add, 从而使fds长度发生改变再次循环时会进入i > 0的分支
*/
else {
//i>0,则代表通过socket接收来自对端的数据,并执行相应操作
boolean done = peers.get(i).runOnce();//详见章节3.5
if (done) {
peers.remove(i);//处理完则从fds中移除该文件描述符
fds.remove(i);
}
}
}
}
}
从上面的代码可以看出,Zygote采用高效的I/O多路复用机制,保证在没有客户端连接请求或数据处理时休眠,否则响应客户端的请求。而接下来的代码就分两条分支进行了,其逻辑分别如下:
-
在最开始的时候fds中仅有server socket,因此当有数据到来时,将执行i等于0的分支。此时,显然是需要创建新的通信连接,因此acceptCommandPeer将被调用。让我们接着分析看看它究竟干了些啥!
-
当socket通信通道建立连接之后,就可以跟客户端通信,进入runOnce()方法来接收并处理客户端数据,并执行进程创建工作。
3.4 ZygoteInit.acceptCommandPeer(…)
让我们接着分析这段代码,如下:
//[ZygoteInit.java]
private static ZygoteConnection acceptCommandPeer(String abiList) {
try {
/*
socket编程中,accept()调用主要用在基于连接的套接字类型,比如SOCK_STREAM和SOCK_SEQPACKET
它提取出所监听套接字的等待连接队列中第一个连接请求,创建一个新的套接字,并返回指向该套接字的文件描述符
新建立的套接字不在监听状态,原来所监听的套接字的状态也不受accept()调用的影响,这个就是套接字编程的基础了
注意这里的返回类型ZygoteConnection ,它和我们前面章节2.7.1的ZygoteState有类似之处
*/
return new ZygoteConnection(sServerSocket.accept(), abiList);
} catch (IOException ex) {
...
}
}
接着让我们看看ZygoteConnection是何方神圣!
//[ZygoteConnection .java]
class ZygoteConnection {
...
//还是原来的配方,还是熟悉的味道
private final LocalSocket mSocket;//zygote localsocket建立之后accept后的socket套接字
private final DataOutputStream mSocketOutStream;//输出数据流
private final BufferedReader mSocketReader;//输入数据流
private final Credentials peer;
private final String abiList;
...
ZygoteConnection(LocalSocket socket, String abiList) throws IOException {
mSocket = socket;
this.abiList = abiList;
//创建输出数据流
mSocketOutStream
= new DataOutputStream(socket.getOutputStream());
//创建输入数据流
mSocketReader = new BufferedReader(
new InputStreamReader(socket.getInputStream()), 256);
mSocket.setSoTimeout(CONNECTION_TIMEOUT_MILLIS);//设置超时时间
try {
peer = mSocket.getPeerCredentials();
} catch (IOException ex) {
Log.e(TAG, "Cannot read peer credentials", ex);
throw ex;
}
}
}
通过上面的代码我们可以看到,acceptCommandPeer主要是基础的socket套接字编程,调用了server socket的accpet函数等待客户端的连接,在后面客户端就能调用write()写数据,Zygote进程能调用read()读数据。当有新的连接建立时,zygote进程将会创建出一个新的socket与其通信,并将该socket加入到fds中,所以一旦和客户端进程的通信连接建立后,fds中将会有多个socket至少会有两个。
这里我们可以看到直接new创建了ZygoteConnection对象,而在该对象中封装了mServerSocket的输入流mSocketReader与输出流mSocketOutStream,这个与Clinet端的ZygoteState中封装的zygoteInputStream和zygoteWriter是对应起来的。
当poll监听到这一组sockets上有数据到来时,就会从阻塞中恢复。于是,我们需要判断到底是哪个socket收到了数据
3.5 ZygoteConnection.runOnce(…)
经过上述一顿猛如虎的操作,此时Zygote进程的localserver服务端已经建立并且已经和AMS端建立了socket套接字连接,接着回到章节2.8在AMS和Zygote的socket服务端建立连接之后会继续通过socket通道写入相关目标进程相关信息,此时zygote服务端poll监听到这一组sockets上有数据到来时,就会从阻塞中恢复继续处理。
//[ZygoteConnection.java]
boolean runOnce() throws ZygoteInit.MethodAndArgsCaller {
String args[];
Arguments parsedArgs = null;
FileDescriptor[] descriptors;
try {
//读取socket客户端发送过来的参数列表
args = readArgumentList();
...
} catch (IOException ex) {
...
}
...
try {
//将socket客户端传递过来的参数,解析成Arguments对象格式
parsedArgs = new Arguments(args);
// 处理客户端查询abiList请求(客户端socket创建时)
if (parsedArgs.abiListQuery) {
return handleAbiListQuery();
}
...
//权限检测
applyUidSecurityPolicy(parsedArgs, peer);
applyInvokeWithSecurityPolicy(parsedArgs, peer);
applyDebuggerSystemProperty(parsedArgs);
applyInvokeWithSystemProperty(parsedArgs);
...
//核心处理方法,根据传递过来的参数fork目标进程
pid = Zygote.forkAndSpecialize(parsedArgs.uid, parsedArgs.gid, parsedArgs.gids,
parsedArgs.debugFlags, rlimits, parsedArgs.mountExternal, parsedArgs.seInfo,
parsedArgs.niceName, fdsToClose, parsedArgs.instructionSet,
parsedArgs.appDataDir);//详见章节3.7
} catch (ErrnoException ex) {
...
} catch (IllegalArgumentException ex) {
...
} catch (ZygoteSecurityException ex) {
...
}
try {
if (pid == 0) {
//子进程会进入此分支
...
//处理子进程创建后的相关逻辑
handleChildProc(parsedArgs, descriptors, childPipeFd, newStderr);//详见章节5.1
return true;
} else {
//zygote进程中执行
...
return handleParentProc(pid, descriptors, serverPipeFd, parsedArgs);//详见章节3.9
}
} finally {
...
}
}
上述的源码逻辑总结起来,无外乎如下两点点(但是扩展开来就多了额):
- 首先解析socket客户端即AMS传递过来的参数,然后调用Zygote.forkAndSpecialize创建目标进程
- 目标进程创建成功之后,上述源码执行逻辑会被割裂成两部分,即在创建的子进程中会执行pid == 0部分的逻辑handleChildProc继续子进程处理相关的逻辑,而父进程zygote则会执行handleParentProc的逻辑
上述逻辑中的forkAndSpecialize涉及到的知识点比较多,主要是怎么fork目标进程然后复用zygote进程的相关资源,这部分如果读者朋友有想比较深入的了解最好找一本专门的书籍深入学习(主要是Linux中fork相关的执行逻辑)。
3.6 Zygote.forkAndSpecialize(…)
重点,该章节以后的篇章很多都是参见gityuan大神的理解Android进程创建流程来写的,这里为什么是参考他的,因为他的确实是太经典了,实在是绕不过他。各位见谅!并且这部分的内容非常多,如果小伙们对此章节不想深入的话,可以跳过只需要知道此章节会fork目标进程,对该章节感兴趣的小伙们可以该上厕所的先上厕所,该喝水的喝水,然后一鼓作气将其拿下!
//[Zygote.java]
private static final ZygoteHooks VM_HOOKS = new ZygoteHooks();
public static int forkAndSpecialize(int uid, int gid, int[] gids, int debugFlags,
int[][] rlimits, int mountExternal, String seInfo, String niceName, int[] fdsToClose,
String instructionSet, String appDataDir) {
//开始fork之前的准备工作
VM_HOOKS.preFork();//详见章节3.7
//画重点,调用nativeForkAndSpecialize创建子进程
int pid = nativeForkAndSpecialize(
uid, gid, gids, debugFlags, rlimits, mountExternal, seInfo, niceName, fdsToClose,
instructionSet, appDataDir);//详见章节
if (pid == 0) {
//对于子进程,开启trace跟踪
Trace.setTracingEnabled(true);
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "PostFork");
}
//fork之后的工作
VM_HOOKS.postForkCommon();//详见3.10章节
return pid;
}
forkAndSpecialize方法遵循三步曲原则:
- 第一曲: VM_HOOKS.preFork进行fork之间的准备工作
- 第一曲: nativeForkAndSpecialize正式开始fork子进程
- 第一曲: VM_HOOKS.postForkCommon进行fork之后的收尾工作
接下来我们就来看看上面的三步曲是如何奏响的。想必是串啦弹唱,样样不少!由于上述三步曲牵涉的内容不少,这里先奉上整体的时序图!
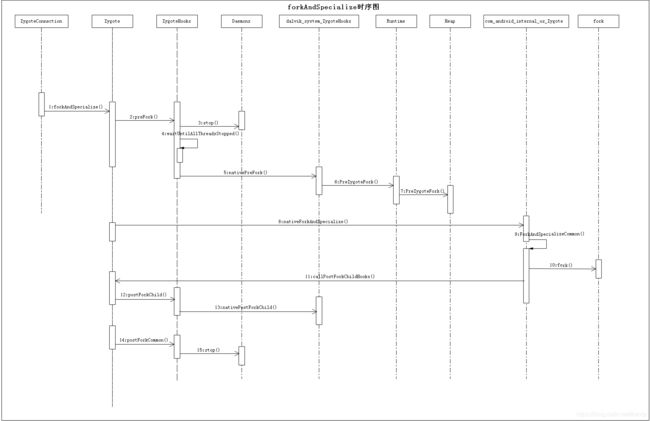
3.6.1 浅说Zygote进程
在开始后续篇章的分析前,我们还是得来说下Zygote进程(至于是zygote64还是zygote得根据实际情况来定):

从图中可知Zygote进程有4个Daemon子线程分别是ReferenceQueueDaemon,FinalizerDaemon,FinalizerWatchdogDaemon,HeapTaskDaemon。图中线程名显示的并不完整是由于底层的进程结构体task_struct是由长度为16的char型数组保存,超过15个字符便会截断。可能大伙要问这4个线程都是什么干什么的呢,这4个线程主要是ART的GC的守护线程,下面分别对其进行简单的介绍一番,因为GC要深入太难了,有兴趣的可以看看罗升阳的ART GC回收相关的比较详细ART运行时垃圾收集(GC)过程分析。
- ReferenceQueueDaemon:引用队列守护进程。我们知道,在创建引用对象的时候,可以关联一个队列。当被引用对象所引用的对象被GC回收的时候,被引用对象就会被加入到其创建时关联的队列去。这个加入队列的操作就是由ReferenceQueueDaemon守护线程来完成的。这样应用程序就可以知道那些被引用对象引用的对象已经被回收了
- FinalizerDaemon:析构守护线程。对于重写了成员函数finalize的对象,它们被GC决定回收时,并没有马上被回收而是被放入到一个队列中,等待FinalizerDaemon守护线程去调用它们的成员函数finalize,然后再被回收
- FinalizerWatchdogDaemon:析构监护守护线程。用来监控FinalizerDaemon线程的执行。一旦检测了那些重写了成员函数finalize的对象在执行成员函数finalize时超出一定的时候,那么就会退出VM。
- HeapTrimmerDaemon:堆裁剪守护线程。用来执行裁剪堆的操作,也就是用来将那些空闲的堆内存归还给系统。
并且上述几个Daemon子线程我们不仅可以通过ps -t验证其存在,也可以通过生成trace文件来进行验证,如下:
XXX:/data/anr # debuggerd -b 529
Sending request to dump task 529.
----- pid 529 at 2020-10-22 10:51:09 -----
Cmd line: zygote
ABI: 'arm'
"main" sysTid=529
#00 pc 000486d0 /system/lib/libc.so (__ppoll+16)
#01 pc 0001ceb7 /system/lib/libc.so (poll+46)
#02 pc 0001abd1 /system/lib/libjavacore.so
#03 pc 72d48dcd /data/dalvik-cache/arm/system@[email protected] (offset 0x2837000)
"ReferenceQueueD" sysTid=10061
#00 pc 000176b8 /system/lib/libc.so (syscall+28)
#01 pc 000b6e49 /system/lib/libart.so (_ZN3art17ConditionVariable16WaitHoldingLocksEPNS_6ThreadE+92)
#02 pc 0029f17b /system/lib/libart.so (_ZN3art7Monitor4WaitEPNS_6ThreadExibNS_11ThreadStateE+514)
#03 pc 002a09ab /system/lib/libart.so (_ZN3art7Monitor4WaitEPNS_6ThreadEPNS_6mirror6ObjectExibNS_11ThreadStateE+258)
#04 pc 002af23f /system/lib/libart.so (_ZN3artL11Object_waitEP7_JNIEnvP8_jobject+32)
#05 pc 7287f537 /data/dalvik-cache/arm/system@[email protected] (offset 0x2837000)
"FinalizerDaemon" sysTid=10062
#00 pc 000176b8 /system/lib/libc.so (syscall+28)
#01 pc 000b6e49 /system/lib/libart.so (_ZN3art17ConditionVariable16WaitHoldingLocksEPNS_6ThreadE+92)
#02 pc 0029f17b /system/lib/libart.so (_ZN3art7Monitor4WaitEPNS_6ThreadExibNS_11ThreadStateE+514)
#03 pc 002a09ab /system/lib/libart.so (_ZN3art7Monitor4WaitEPNS_6ThreadEPNS_6mirror6ObjectExibNS_11ThreadStateE+258)
#04 pc 002af26b /system/lib/libart.so (_ZN3artL13Object_waitJIEP7_JNIEnvP8_jobjectxi+36)
#05 pc 7287f635 /data/dalvik-cache/arm/system@[email protected] (offset 0x2837000)
"FinalizerWatchd" sysTid=10063
#00 pc 000176b8 /system/lib/libc.so (syscall+28)
#01 pc 000b6e49 /system/lib/libart.so (_ZN3art17ConditionVariable16WaitHoldingLocksEPNS_6ThreadE+92)
#02 pc 0029f17b /system/lib/libart.so (_ZN3art7Monitor4WaitEPNS_6ThreadExibNS_11ThreadStateE+514)
#03 pc 002a09ab /system/lib/libart.so (_ZN3art7Monitor4WaitEPNS_6ThreadEPNS_6mirror6ObjectExibNS_11ThreadStateE+258)
#04 pc 002af23f /system/lib/libart.so (_ZN3artL11Object_waitEP7_JNIEnvP8_jobject+32)
#05 pc 7287f537 /data/dalvik-cache/arm/system@[email protected] (offset 0x2837000)
"HeapTaskDaemon" sysTid=10064
#00 pc 000176b8 /system/lib/libc.so (syscall+28)
#01 pc 000b6e49 /system/lib/libart.so (_ZN3art17ConditionVariable16WaitHoldingLocksEPNS_6ThreadE+92)
#02 pc 001b4de5 /system/lib/libart.so (_ZN3art2gc13TaskProcessor7GetTaskEPNS_6ThreadE+288)
#03 pc 001b545d /system/lib/libart.so (_ZN3art2gc13TaskProcessor11RunAllTasksEPNS_6ThreadE+44)
#04 pc 72ca9727 /data/dalvik-cache/arm/system@[email protected] (offset 0x2837000)
----- end 529 -----
可能会有小伙伴说zygote进程不是还有system_server,com.android.systemui等子线程存在吗,怎么会只有4个呢?那是因为这些并不是Zygote的子线程,而是Zygote的子进程。在图中用红色圈起来的是进程的 VSIZE,virtual size),代表的是进程虚拟地址空间大小。线程与进程的最为本质的区别便是是否共享内存空间,图中VSIZE和Zygote进程相同的才是Zygote的子线程,否则就是Zygote的子进程。
3.7 ZygoteHooks.preFork(…)进程创建"一步曲"前期准备
//[ZygoteHooks.java]
public void preFork() {
//将Zygote进程的四个Daemon线程暂时停止,注意这里的措辞是暂时,后续还是会将其启动的
Daemons.stop();//详见章节[3.7.1]
//等待上述子线程都停止
waitUntilAllThreadsStopped();//详见章节[3.7.2]
//完成GC堆的初始化工作
token = nativePreFork();//详见章节[3.7.3]
}
preFork先不多言,整体逻辑见注释!对于其中的逻辑我们一一分析,各个突破!
3.7.1 Daemons.stop(…)暂停守护线程
//[Daemons.java]
public static void stop() {
HeapTaskDaemon.INSTANCE.stop();//停止Java堆整理线程
ReferenceQueueDaemon.INSTANCE.stop();//停止引用队列线程
FinalizerDaemon.INSTANCE.stop();//停止析构守护线程
FinalizerWatchdogDaemon.INSTANCE.stop();//停止析构监护守护线程
}
此处主要是暂停Zygote进程的四个守护线程,而守护线程stop的方式是先调用目标线程interrrupt()方法,然后再调用目标线程join()方法,等待线程执行完成。
3.7.2 ZygoteHooks.waitUntilAllThreadsStopped(…)等待所有守护线程停止
//[ZygoteHooks.java]
private static void waitUntilAllThreadsStopped() {
File tasks = new File("/proc/self/task");
//好吗,这个有点专业了牵涉到内核相关的东西了不是很明白,从注释来解释就是当/proc中线程数大于1,就出让CPU直到只有一个线程,才退出循环
while (tasks.list().length > 1) {
Thread.yield();
}
}
上述这个有点专业了牵涉到内核相关的东西了不是很明白,这里我们简单介绍一下/proc/self/task的相关知识点:
我们都知道可以通过/proc/$pid/来获取指定进程的信息,例如内存映射、CPU绑定信息等等。如果某个进程想要获取本进程的系统信息,就可以通过进程的pid来访问/proc/$pid/目录。但是这个方法还需要获取进程pid,在fork、daemon等情况下pid还可能发生变化。为了更方便的获取本进程的信息,linux提供了/proc/self/目录,这个目录比较独特,不同的进程访问该目录时获得的信息是不同的,内容等价于/proc/本进程pid/。进程可以通过访问/proc/self/目录来获取自己的系统信息,而不用每次都获取pid
至于关于Linux下/proc相关的更多介绍,可以参见博客Linux下/proc目录简介写的费仲详细的。
3.7.3 ZygoteHooks.nativePreFork(…)/完成GC堆的初始化工作
一看这方法命名就知道是本地方法,还记得我在前面篇章介绍的怎么查找Android系统源码对应的jni文件方法吗,如果小伙们不记得了,我们重新回忆回忆:
这里有一个小窍门,怎么找到Android系统中Java的本地方法对应的Jni所在文件呢,一般的规则如下:
1. 将Java类所在的包名中的.转换成_,譬如我们这里的Zygote所在包名为com.android.internal.os,转换后即为com_android_internal_os
2. 将上述转换后的字符串+"_"+Java类名.cpp,就是我们要找的Jni文件了,譬如我们这里的com_android_internal_os_Zygote.cpp
可以知道对应的文件名为dalvik_system_ZygoteHooks.cc路径为art/runtime/native/dalvik_system_ZygoteHooks.cc。最终我们定位到了ZygoteHooks_nativePreFork函数,逻辑如下所示:
//[art/runtime/native/dalvik_system_ZygoteHooks.cc]
static jlong ZygoteHooks_nativePreFork(JNIEnv* env, jclass) {
Runtime* runtime = Runtime::Current();
CHECK(runtime->IsZygote()) << "runtime instance not started with -Xzygote";
runtime->PreZygoteFork();//堆的初始化工作,不是我的领域撤我的菜了
if (Trace::GetMethodTracingMode() != TracingMode::kTracingInactive) {
Trace::Pause();
}
//将线程转换为long型并保存到token,该过程是非安全的
return reinterpret_cast<jlong>(ThreadForEnv(env));
}
让我们继续跟进PreZygoteFork,该代码位于art/runtime/runtime.cc中,其逻辑如下所示:
//[art/runtime/runtime.cc]
void Runtime::PreZygoteFork() {
/*
好吗,这块牵涉到非常专业的知识了堆的初始化工作,这里应该牵涉到art虚拟机了,
有兴趣的可以看看邓凡平大师或者罗升阳的博客或者书籍有比较深的介绍
*/
heap_->PreZygoteFork();
}
3.7.4 ZygoteHooks.preFork(…)小结
至此ZygoteHooks.preFork的工作我们到这里就告一段落了,其主要功能便是停止Zygote的4个Daemon子线程的运行,等待并确保Zygote是单线程(用于提升fork效率),并等待这些线程的停止,初始化gc堆的工作, 并将线程转换为long型并保存到token中。(上述源码牵涉的专业知识比较多不理解也没有关系,其实我也不是很理解,这个并不影响我们对整个Activity启动流程的分析)。
3.8 ZygoteHooks.nativeForkAndSpecialize(…)进程创建"二步曲"正式开干
此时的我来自何处,将要去往何方。我们还是先来捋一捋,我们是从章节3.6过来的,犯迷糊的小伙们可以回头看看章节3.6就知道怎么来到这里的了,说真的此时的我也分析的要吐了,但是到了这一步了,吐了也要整完。
这又是一个本地方法,根据我们前面介绍的查找对应的JNI文件的方法,最终找到了com_android_internal_os_Zygote.cpp并通过JNI调用了com_android_internal_os_Zygote_nativeForkAndSpecialize函数,其代码逻辑如下:
//[frameworks/base/core/jni/com_android_internal_os_Zygote.cpp]
static jint com_android_internal_os_Zygote_nativeForkAndSpecialize(
JNIEnv* env, jclass, jint uid, jint gid, jintArray gids,
jint debug_flags, jobjectArray rlimits,
jint mount_external, jstring se_info, jstring se_name,
jintArray fdsToClose, jstring instructionSet, jstring appDataDir) {
...
//正式开始fork子进程流程
return ForkAndSpecializeCommon(env, uid, gid, gids, debug_flags,
rlimits, capabilities, capabilities, mount_external, se_info,
se_name, false, fdsToClose, instructionSet, appDataDir);//由于这部分知识内容比较多,所以还是独立一个大节来分析,详见章节3.9
}
真的干不动了,其中的细枝末节就能忽略的都忽略,直奔主题进入下一个环节!
3.9 ForkAndSpecializeCommon
对于这个方法我想大伙如果有阅读过system_server进程创建流程的话肯定不陌生了,在前面博客Android Zygote进程启动源码分析指南我们已经有见过其踪影了,但是这里还是得分析分析。源码如下:
//[frameworks/base/core/jni/com_android_internal_os_Zygote.cpp]
static pid_t ForkAndSpecializeCommon(JNIEnv* env, uid_t uid, gid_t gid, jintArray javaGids,
jint debug_flags, jobjectArray javaRlimits,
jlong permittedCapabilities, jlong effectiveCapabilities,
jint mount_external,
jstring java_se_info, jstring java_se_name,
bool is_system_server, //ForkAndSpecializeCommon方法涉及的参数,我们重点关注该参数,表示是否是创建system_server进程,很显然不是
jintArray fdsToClose,
jstring instructionSet, jstring dataDir) {
//设置子进程的signal信号处理函数
SetSigChldHandler();
...
sigset_t sigchld;
sigemptyset(&sigchld);
sigaddset(&sigchld, SIGCHLD);
...
//fork目标进程
pid_t pid = fork();//详见章节3.9.2
/*
fork()创建新进程,采用copy on write方式,这是linux创建进程的标准方法,
会有两次return,对于pid==0为子进程的返回,对于pid>0为父进程的返回
*/
if (pid == 0) {
gMallocLeakZygoteChild = 1;
//关闭继承自zygote的socket文件描述符
DetachDescriptors(env, fdsToClose);
...
//非system_server进程
if (!is_system_server) {
//创建进程组
int rc = createProcessGroup(uid, getpid());
...
}
//关于下面相关的system相关策略的设置可以参见博客https://www.cnblogs.com/0xJDchen/p/6806573.html
// 设置进程所属额外的groups
SetGids(env, javaGids);
// 设置资源限制
SetRLimits(env, javaRlimits);
// 通常不使用native bridge
// native bridge用于运行带有与系统不同的处理器架构native库的应用
if (use_native_bridge) {
ScopedUtfChars isa_string(env, instructionSet);
ScopedUtfChars data_dir(env, dataDir);
android::PreInitializeNativeBridge(data_dir.c_str(), isa_string.c_str());
}
//设置实际用户/组id
int rc = setresgid(gid, gid, gid);
//设置有效用户/组id
rc = setresuid(uid, uid, uid);
if (rc == -1) {
ALOGE("setresuid(%d) failed: %s", uid, strerror(errno));
RuntimeAbort(env, __LINE__, "setresuid failed");
}
// 针对低版本kernel,弥补ASLR(地址空间布局随机化)的缺失
if (NeedsNoRandomizeWorkaround()) {
int old_personality = personality(0xffffffff);
int new_personality = personality(old_personality | ADDR_NO_RANDOMIZE);
}
//设置进程权能
SetCapabilities(env, permittedCapabilities, effectiveCapabilities);
//设置调度策略
SetSchedulerPolicy(env);
//设置selinux安全上下文
rc = selinux_android_setcontext(uid, is_system_server, se_info_c_str, se_name_c_str);
//设置进程名
if (se_info_c_str != NULL) {
SetThreadName(se_name_c_str);
}
delete se_info;
delete se_name;
在Zygote子进程中,设置信号SIGCHLD的处理器恢复为默认行为
UnsetSigChldHandler();
//等价于调用zygote.callPostForkChildHooks,这个后面章节会讲到
env->CallStaticVoidMethod(gZygoteClass, gCallPostForkChildHooks, debug_flags,
is_system_server, instructionSet);//详见章节3.9.3
} else if (pid > 0) {
//zygote进程处理逻辑
...
}
return pid;
}
ForkAndSpecializeCommon函数的处理逻辑并不是很复杂(但是其中涉及的Linux的相关知识点就比较深入了),其处理的逻辑如下:
- 进行fork创建目标进程之前的准备工作,主要是一些信号处理和描述符的问题
- 通过fork创建目标进程
- fork成功之后,在非system_server子进程中继续进行进程相关的一些设置,譬如uid,selinux,调度策略等相关的处理
- 在子进程中分支最后通过JNI调用zygote.callPostForkChildHooks方法
对于上述的处理逻辑,还是老办法各个突破,一一分析!
3.9.1 fork原理简介
在正式开始打怪升级爆装备之前,还是得先进行一些战术准备啥的。而我们本篇博客的核心的核心就是围绕fork目标进程开展的,所以我们有必要对其介绍一番!
对于fork我想小伙们应该有一定编程基础的应该都不会是很陌生,可是fork背后的技术估计知道的人就不是很多了,在这里fork采用了一种叫做copy-on-write即写时拷贝技术简称COW技术,而我们的Zygote进程在fork目标进程的时候在这里使用了copy-on-write技术可以提高应用运行速度,因为该种方式对运行在内存中的进程实现了最大程度的复用,并通过库共享有效降低了内存的使用量。也就是说当新的App通过fork()创建的的时候不进行内存的复制,这是因为复制内存的开销是很大的,此时子进程只需要共享父进程的内存空间即可,因为这个时候他们没有差异。而当子进程需要需要修改共享内存信息时,此时才开始将内存信息复制到自己的内存空间中,并进行修改。
并且同时fork技术是linux创建进程的标准方法,调用一次,返回两次,其返回值有三种类型,其分别的定义如下:
- 父进程中,fork返回新创建的子进程的pid,此时的pid大于0
- 子进程中,fork返回0
- 当fork出现异常甚至错误时,fork返回负数(造成这种的原因可能是当前创建 的进程数超过系统允许的上限或者系统内存不存时导致的)
并且我们的fork()的主要工作原理是寻找空闲的进程号pid,然后从父进程拷贝进程信息,例如数据段和代码段,fork()后子进程要执行的代码等。 Zygote进程是所有Android进程的母体,包括system_server和各个App进程。zygote利用fork()方法生成新进程,对于新进程A复用Zygote进程本身的资源,再加上新进程A相关的资源,构成新的应用进程A。其中下图中Zygote进程的libc、vm、preloaded classes、preloaded resources是如何生成的,可查看另一个文章 Android Zygote进程启动源码分析指南中有比较详细的介绍,见下图:

前面我们巴拉巴拉了一大堆的copy-on-write的作用,估计还是有点蒙圈,下面我们对其过程和原理总结一番:
- copy-on-write过程:当父子进程任一方修改内存数据时(这是on-write时机),才发生缺页中断,从而分配新的物理内存(这是copy操作)
- copy-on-write原理:写时拷贝是指子进程与父进程的页表都所指向同一个块物理内存,fork过程只拷贝父进程的页表,并标记这些页表是只读的。父子进程共用同一份物理内存,如果父子进程任一方想要修改这块物理内存,那么会触发缺页异常(page fault),Linux收到该中断便会创建新的物理内存,并将两个物理内存标记设置为可写状态,从而父子进程都有各自独立的物理内
好了,fork的基本原理叽歪叽歪到此就结束了,是时候开始分析正题了!
3.9.2 fork()函数分析
fork闹,煎饼果子来一套!
//[bionic/libc/bionic/fork.cpp]
int fork() {
__bionic_atfork_run_prepare();//fork完成前,父进程回调方法
//fork期间,获取父进程pid,并使其缓存值无效
pthread_internal_t* self = __get_thread();
pid_t parent_pid = self->invalidate_cached_pid();
//通过syscall调用内核的clone
#if defined(__x86_64__)
int result = syscall(__NR_clone, FORK_FLAGS, NULL, NULL, &(self->tid), NULL);
#else
int result = syscall(__NR_clone, FORK_FLAGS, NULL, NULL, NULL, &(self->tid));
#endif
if (result == 0) {
self->set_cached_pid(gettid());
__bionic_atfork_run_child();//fork完成后,子进程回调方法
} else {
self->set_cached_pid(parent_pid);
__bionic_atfork_run_parent();fork完成执行父进程回调方法
}
return result;
}
上述的分析已经完全超纲了,臣妾做不到。这里我们还是简单分析一下,fork函数的核心是通过syscall调用了内核的clone机制(至于clone原理这个感性去的小伙们自行研究吗,不在重点讨论范围之内),并且在执行clone前后都有对应的回调方法,如下:
- __bionic_atfork_run_prepare: fork完成前,父进程回调方法
- __bionic_atfork_run_child: fork完成后,子进程回调方法
- __bionic_atfork_run_paren: fork完成后,父进程回调方法
以上3个方法的实现都位于bionic/libc/bionic/pthread_atfork.cpp中。如果有需要,可以扩展该回调方法,添加相关的业务需求。
写着写着感觉整不下去了,Activity启动流程咋感觉画风变成了进程创建的专区了啊,估计这章要扑街了!!!!
3.9.3 Zygote.callPostForkChildHooks(…)跑错片场
是不是跑错片场了,我是谁,我怎么来到了这里!还是的回到章节3.9继续撸一下,在com_android_internal_os_Zygote.cpp中存在如下的JNI动态注册逻辑,如下:
//[com_android_internal_os_Zygote.cpp]
static const char kZygoteClassName[] = "com/android/internal/os/Zygote";
static const JNINativeMethod gMethods[] = {
{
"nativeForkAndSpecialize",
"(II[II[[IILjava/lang/String;Ljava/lang/String;[ILjava/lang/String;Ljava/lang/String;)I",
(void *) com_android_internal_os_Zygote_nativeForkAndSpecialize },
{
"nativeForkSystemServer", "(II[II[[IJJ)I",
(void *) com_android_internal_os_Zygote_nativeForkSystemServer },
{
"nativeUnmountStorageOnInit", "()V",
(void *) com_android_internal_os_Zygote_nativeUnmountStorageOnInit }
};
int register_com_android_internal_os_Zygote(JNIEnv* env) {
gZygoteClass = MakeGlobalRefOrDie(env, FindClassOrDie(env, kZygoteClassName));
gCallPostForkChildHooks = GetStaticMethodIDOrDie(env, gZygoteClass, "callPostForkChildHooks",
"(IZLjava/lang/String;)V");
return RegisterMethodsOrDie(env, "com/android/internal/os/Zygote", gMethods, NELEM(gMethods));
}
所以我们是没有跑错片场的,此时通过jni我们调用到了Zygote的callPostForkChildHooks方法中,这兜兜转转也真是不容易啊!
//[Zygote.java]
private static void callPostForkChildHooks(int debugFlags, boolean isSystemServer,
String instructionSet) {
VM_HOOKS.postForkChild(debugFlags, isSystemServer, instructionSet);
}
VM_HOOKS我们已经介绍过了,不做过多的分析,接着分析postForkChild,其逻辑如下:
//[ZygoteHooks.java]
//注意此方法是在子进程中执行的
public void postForkChild(int debugFlags, boolean isSystemServer, String instructionSet) {
//又是一个native方法
nativePostForkChild(token, debugFlags, isSystemServer, instructionSet);
/*
设置了新进程Random随机数种子为当前系统时间,也就是在进程创建的那一刻就决定了未来随机数的情况,也就是伪随机。
*/
Math.setRandomSeedInternal(System.currentTimeMillis());
}
显而易见毋庸置疑的这又是一个JNI的调用,最终调用到了ZygoteHooks_nativePostForkChild函数,其逻辑如下:
//[art/runtime/native/dalvik_system_ZygoteHooks.cc]
static void ZygoteHooks_nativePostForkChild(JNIEnv* env,
jclass,
jlong token,
jint debug_flags,
jboolean is_system_server,
jstring instruction_set) {
//此处的token是在章节3.7中创建的
Thread* thread = reinterpret_cast<Thread*>(token);
//设置新进程的主线程id
thread->InitAfterFork();
EnableDebugFeatures(debug_flags);
...
//指令集不为空且非system_server
if (instruction_set != nullptr && !is_system_server) {
ScopedUtfChars isa_string(env, instruction_set);
InstructionSet isa = GetInstructionSetFromString(isa_string.c_str());
Runtime::NativeBridgeAction action = Runtime::NativeBridgeAction::kUnload;
if (isa != kNone && isa != kRuntimeISA) {
action = Runtime::NativeBridgeAction::kInitialize;
}
// 设置heap、创建Jit等
Runtime::Current()->InitNonZygoteOrPostFork(
env, is_system_server, action, isa_string.c_str());
} else {
Runtime::Current()->InitNonZygoteOrPostFork(
env, is_system_server, Runtime::NativeBridgeAction::kUnload, nullptr);
}
}
干不动了,真的干不动了!还是继续分析一下
//[art/runtime/runtime.cc]
void Runtime::InitNonZygoteOrPostFork(
JNIEnv* env, bool is_system_server, NativeBridgeAction action, const char* isa) {
is_zygote_ = false;
//通常is_native_bridge_loaded_为false, See ro.dalvik.vm.native.bridge属性
if (is_native_bridge_loaded_) {
switch (action) {
case NativeBridgeAction::kUnload:
UnloadNativeBridge();//卸载用于跨平台的桥连库
is_native_bridge_loaded_ = false;
break;
case NativeBridgeAction::kInitialize:
InitializeNativeBridge(env, isa);//初始化用于跨平台的桥连库
break;
}
}
//创建Java堆处理的线程池
heap_->CreateThreadPool();
//重置gc性能数据,以保证进程在创建之前的GCs不会计算到当前app上
heap_->ResetGcPerformanceInfo();
//当flag被设置,并且还没有创建JIT时,则创建JIT
if (!is_system_server &&
!safe_mode_ &&
(jit_options_->UseJitCompilation() || jit_options_->GetSaveProfilingInfo()) &&
jit_.get() == nullptr) {
CreateJit();
}
//创建信号处理函数
StartSignalCatcher();
//启动JDWP线程,当命令debuger的flags指定"suspend=y"时,则暂停runtime
Dbg::StartJdwp();
}
其中关于信号处理过程,其代码位于art/runtime/signal_catcher.cc文件中,这个对于native crash的捕获非常有用。终于干完了,干完了,上述的小伙们想了解的就了解下,不想了解的就直接过就好了。
3.10 ZygoteHooks.postForkCommon
分析到此处,真的是心力憔悴了啊!又要回答我是谁,我是怎么来的了,只能穿越到章节3.6继续未完成使命了!
//[ZygoteHooks.java]
public void postForkCommon() {
Daemons.start();//启动守护线程
}
//[Daemons.java]
public static void start() {
ReferenceQueueDaemon.INSTANCE.start();
FinalizerDaemon.INSTANCE.start();
FinalizerWatchdogDaemon.INSTANCE.start();
HeapTaskDaemon.INSTANCE.start();
}
还记得在章节3.7中将4个守护线程stop了吗,此处是在fork新进程后,启动Zygote和目标进程的4个Daemon线程。
3.11 Zygote.forkAndSpecialize小结
从章节3.6至此处,我也被搞得云里雾里了,套路太多了!对于上述的整个处理逻辑从整理高度来概括的话分为如下三个部分:
- preFork: 停止Zygote的4个Daemon子线程的运行,初始化gc堆;
- nativeForkAndSpecialize:调用fork()创建新进程,设置新进程的主线程id,重置gc性能数据,设置信号处理函数等功能。
- postForkCommon:启动4个Deamon子线程。
该方法调用关系链如下:
Zygote.forkAndSpecialize
ZygoteHooks.preFork()
Daemons.stop
ZygoteHooks.nativePreFork
dalvik_system_ZygoteHooks.ZygoteHooks_nativePreFork
Runtime.PreZygoteFork
heap_->PreZygoteFork()
Zygote.nativeForkAndSpecialize
com_android_internal_os_Zygote.com_android_internal_os_Zygote_nativeForkAndSpecialize
com_android_internal_os_Zygote.ForkAndSpecializeCommon
fork()
Zygote.callPostForkChildHooks
ZygoteHooks.postForkChild
dalvik_system_ZygoteHooks.nativePostForkChild
Runtime::InitNonZygoteOrPostFork
ZygoteHooks.postForkCommon
Daemons.start
来个三连杀,上时序图,如下:
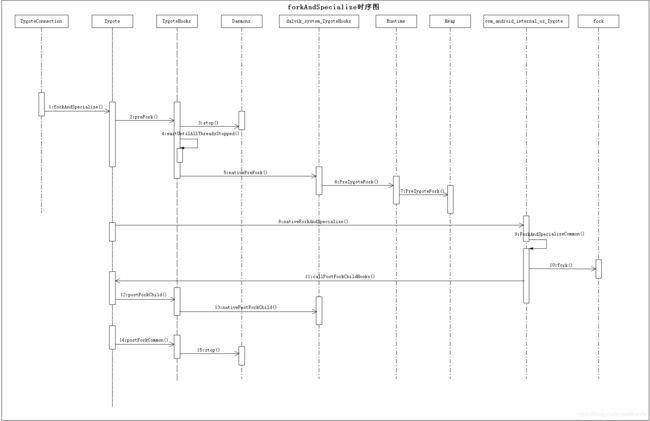
好吗行文至此,我们的App进程已经完成了创建的所有工作了,难道就要结束了吗,不这只是一个开始,真的只是一个开始。在接下来我们要开始新创建的App进程的工作。在前面ZygoteConnection.runOnce方法中,Zygote进程执行完forkAndSpecialize()后,新创建的App进程便进入handleChildProc()方法,下面的操作运行在App进程。
3.12 Zygote进程接受请求并创建进程小结
至此Zygote进程接受请求并创建进程到这里就告一段落了,由于此大章节牵涉的内容比较多所以我们先停止前进的脚步,对前面的知识简单总结一下。通过前面的分析我们来理一理zygote进程是如何接受请求并创建目标进程其基本流程如下:
-
Zygote进程被用户空间第一号进程init进程启动之后会通过registerZygoteSocket创建localSocket服务端,等待客户端(这里指AMS所在的system_server)进程的孵化请求
-
接着在Zygote进程在主动孵化完system_server进程中之后,进入runSelectLoop无限循环中,等待客户端的请求
-
AMS客户端和zygote端通过localsocket建立数据连接,然后发送创建目标进程请求
-
Zygote进程通过acceptCommandPeer处理AMS的连接返回ZygoteConnection连接处理类
-
接着调用已经封装好的ZygoteConnection类的方法runOnce继续处理进程创建流程
-
接着在上述runOnce方法中通过Zygote.forkAndSpecialize开始真正的进程创建流程
如上就是Zygote进程接受请求并创建进程的基本流程,伪代码可以表达如下:
ZygoteInit.main(...) --->
ZygoteInit.registerZygoteSocket(...) --->
ZygoteInit.runSelectLoop(...) --->
ZygoteInit.acceptCommandPeer(...) --->
ZygoteConnection.runOnce(...) --->
Zygote.forkAndSpecialize(...) --->
ZygoteHooks.preFork(...) --->
Daemons.stop(...) --->
ZygoteHooks.nativePreFork(...) --->
dalvik_system_ZygoteHooks.ZygoteHooks_nativePreFork(...) --->
Runtime.PreZygoteFork(...) --->
heap_->PreZygoteFork(...) --->
Zygote.nativeForkAndSpecialize(...) --->
com_android_internal_os_Zygote.com_android_internal_os_Zygote_nativeForkAndSpecialize(...) --->
com_android_internal_os_Zygote.ForkAndSpecializeCommon(...) --->
fork(...) --->
Zygote.callPostForkChildHooks(...) --->
ZygoteHooks.postForkChild(...) --->
dalvik_system_ZygoteHooks.nativePostForkChild(...) --->
Runtime::InitNonZygoteOrPostFork(...) --->
ZygoteHooks.postForkCommon(...) --->
Daemons.start(...) --->
如果感觉上述还不过瘾,只能来终极杀手锏了,上整个的时序图了!
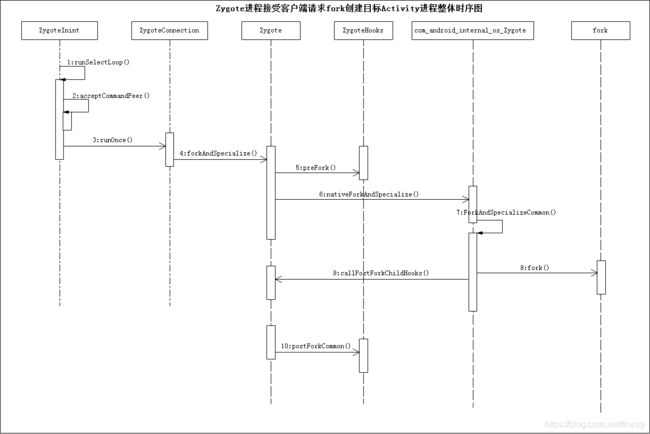
四. 开创目标新进程时代并初始化运行时环境
我已经等待了五百年了,终于轮到我上场了。在前面的第三章节中,我们在runOnce方法中调用forkAndSpecialize创建完新进程之后,在返回值为pid==0的子进程中继续开始执行handleChildProc()方法。从此属于我的时代来临了。并且如果对于进程创建流程熟悉的小伙们或者不是刚兴趣的这个也可以跳过了!
4.1 ZygoteConnection.handleChildProc(…)
注意此处是从章节3.5的调用流程过来的!并且此时是运行在新进程中了不是zygote进程中了
//[ZygoteConnection.java]
private void handleChildProc(Arguments parsedArgs,
FileDescriptor[] descriptors, FileDescriptor pipeFd, PrintStream newStderr)
throws ZygoteInit.MethodAndArgsCaller {
//关闭与关联连接的socket
closeSocket();
// 关闭清理Zygote socket
ZygoteInit.closeServerSocket();
if (descriptors != null) {
try {
//重定向
/*
* dup2(int old_fd, int new_fd) dup2函数的作用是用来复制一个文件的描述符,
* 通常用来重定向进程的stdin、stdout和stderr。
* 下面的函数将0、1、2绑定到null设备上,通过标准的输入输出无法输出信息
*/
Os.dup2(descriptors[0], STDIN_FILENO);
Os.dup2(descriptors[1], STDOUT_FILENO);
Os.dup2(descriptors[2], STDERR_FILENO);
for (FileDescriptor fd: descriptors) {
IoUtils.closeQuietly(fd);
}
newStderr = System.err;
} catch (ErrnoException ex) {
...
}
}
if (parsedArgs.niceName != null) {
//设置进程名,通常是包名
Process.setArgV0(parsedArgs.niceName);
}
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
if (parsedArgs.invokeWith != null) {
//注意我们不会走入此分支,而是下面的分支
//据说这是用于检测进程内存泄露或溢出时场景而设计,这个不是我说的gityuan说的
WrapperInit.execApplication(parsedArgs.invokeWith,
parsedArgs.niceName, parsedArgs.targetSdkVersion,
VMRuntime.getCurrentInstructionSet(),
pipeFd, parsedArgs.remainingArgs);
} else {
RuntimeInit.zygoteInit(parsedArgs.targetSdkVersion,
parsedArgs.remainingArgs, null /* classLoader */);//详见章节4.2
}
}
handleChildProc主要干了啥,从上面的源码来看主要是干了一些zygote进程创建目标进程之后的扫尾工作以及新进程创建之后的相关运行时初始化工作!
- zygote进程创建目标进程之后的扫尾工作 譬如关闭了相关的继承自zygote的socket链接,重定向输入输出
- 新进程创建之后调用RuntimeInit.zygoteInit进行相关运行时的初始化工作
4.2 RuntimeInit.zygoteInit(…)
说实话,这个方法名自我感觉命名方式太不友好了,zygoteInit让人感觉以为是Zygote进程的初始化呢,但是实际上它执行的是目标进程相关的初始化(估计此时谷歌的小伙们是被门夹了才用了这么个命名吗)!
//[RuntimeInit.java]
public static final void zygoteInit(int targetSdkVersion, String[] argv, ClassLoader classLoader)
throws ZygoteInit.MethodAndArgsCaller {
//调试跟踪有关
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "RuntimeInit");
//重定向log输出,System.out重定向到Android log
redirectLogStreams();
//通用的初始化,譬如设置未捕获异常处理等
commonInit();//见章节4.2.1
//还记得有些博客为啥说Android进程天生支持Binder通信吗,此处就是原因呢
nativeZygoteInit();//详见章节4.2.2
//此时我们的目标进程已经创建了,要怎么才能进入目标进程java世界的入口AtvityThread呢,这不就来了吗!
applicationInit(targetSdkVersion, argv, classLoader);//详见章节4.2.3
}
在zygoteInit中执行的主要代码逻辑如下:
- 重定义Log输出
- 通用的初始化
- 启动Binder线程池
- 应用初始化,为进入目标进程Java世界ActivityThread打下了坚定的基础
4.2.1 RuntimeInit.commonInit(…)
//[RuntimeInit.java]
private static final void commonInit() {
//设置默认的未捕获异常的处理方式,当然用户也可以自行定义
Thread.setDefaultUncaughtExceptionHandler(new UncaughtHandler());
//设置时区,中国时区为"Asia/Shanghai"
TimezoneGetter.setInstance(new TimezoneGetter() {
@Override
public String getId() {
return SystemProperties.get("persist.sys.timezone");
}
});
TimeZone.setDefault(null);
//重置Log配置
LogManager.getLogManager().reset();
new AndroidConfig();
// 设置默认的HTTP User-agent格式,用于 HttpURLConnection
String userAgent = getDefaultUserAgent();
System.setProperty("http.agent", userAgent);
NetworkManagementSocketTagger.install();
// 设置socket的tag,用于网络流量统计
String trace = SystemProperties.get("ro.kernel.android.tracing");
if (trace.equals("1")) {
Slog.i(TAG, "NOTE: emulator trace profiling enabled");
Debug.enableEmulatorTraceOutput();
}
initialized = true;
}
该方法要是做了一些常规的初始化,从逻辑上分析主要分为如下几个方面:
- 设置未捕获异常的处理方法
- 设置时区
- 重置log配置
- 设置默认的HTTP User-agent格式,用于 HttpURLConnection
- 设置流量统计Socket tag
这其中User-Agent是Http协议中的一部分,属于头域的组成部分,是一种向访问网站者提供你所使用的浏览器类型,操作系统,浏览器内核等信息的标识。通过这个标识,用户所访问的网站可以显示不同的排版,从而为用户提供更好的体验或者进行信息统计。
4.2.2 RuntimeInit.nativeZygoteInit(…)
聪明人一看就知道这又是一个JNI的调用,最终会调用到AndroidRuntime.cpp文件这个各位一定要注意,注意,其代码如下
//[frameworks/base/core/jni/AndroidRuntime.cpp]
static void com_android_internal_os_RuntimeInit_nativeZygoteInit(JNIEnv* env, jobject clazz)
{
gCurRuntime->onZygoteInit();
}
这里至于为什么最终调用的是AppRuntime,大伙可以参见前面讲解system_server的博客 Android 系统启动之SystemServer大揭秘中有非常详细的介绍!
接着分析AppRuntime.onZygoteInit函数,其主要功能开启Binder线程,这也是为什么App应用是天生支持Binder的。
//[frameworks/base/cmds/app_process/App_main.cpp]
virtual void onZygoteInit()
{
sp<ProcessState> proc = ProcessState::self();
ALOGV("App process: starting thread pool.\n");
proc->startThreadPool();
}
为啥说Android进程天生支持Binder通信呢!如果下次还有人面试的时候问你,直接把下面的甩给他!
- ProcessState::self():主要工作是调用open()打开/dev/binder驱动设备,再利用mmap()映射内核的地址空间,将Binder驱动的fd赋值ProcessState对象中的变量mDriverFD,用于交互操作。startThreadPool()是创建一个新的binder线程,不断进行talkWithDriver().
- startThreadPool(): 启动Binder线程池, 详见Android Binder原理深入分析开篇之Android Binder原理深入分析之进程的Binder线程池工作过程。
4.2.3 RuntimeInit.applicationInit(…)
终于快要见到胜利的曙光了,而我也是快不行了啊!
frameworks/base/core/java/com/android/internal/os/RuntimeInit.java
private static void applicationInit(int targetSdkVersion, String[] argv, ClassLoader classLoader)
throws ZygoteInit.MethodAndArgsCaller {
//true代表应用程序退出时不调用AppRuntime.onExit(),否则会在退出前调用
nativeSetExitWithoutCleanup(true);
//设置虚拟机的内存利用率参数值为0.75
VMRuntime.getRuntime().setTargetHeapUtilization(0.75f);
VMRuntime.getRuntime().setTargetSdkVersion(targetSdkVersion);
final Arguments args;
try {
args = new Arguments(argv);
} catch (IllegalArgumentException ex) {
Slog.e(TAG, ex.getMessage());
return;
}
//调用ActivityThread的main方法
invokeStaticMain(args.startClass, args.startArgs, classLoader);//详见章节4.2.4
}
继续回到RuntimeInit.java类中的applicationInit看看它做了些什么,applicationInit定义在RuntimeInit.java中,其主要逻辑如下:
- 调用nativeSetExitWithoutCleanup(true),从而使应用退出时不调用System.exit()
- 设置虚拟机的内存利用率参数值
- 接着调用invokeStaticMain继续下一步操作
注意此处的args.startClass为”android.app.ActivityThread”,是AMS和zygote进程进行socket通信的时候传递过来的,这个类对应应用开发的同事来说是最熟悉的陌生人了。
4.2.4 RuntimeInit.invokeStaticMain(…)
接着分析invokeStaticMain方法,其中传递进来的参数className是android.app.ActivityThread ,所以其主要逻辑如下:
- 因此通过Class.forName反射返回的cl为ActivityThread 类
- 获取ActivityThread 类的main方法
- 判断ActivityThread 类的main方法修饰符是不是public和static
- 接着抛出异常MethodAndArgsCaller
private static void invokeStaticMain(String className, String[] argv, ClassLoader classLoader)
throws ZygoteInit.MethodAndArgsCaller {
Class<?> cl;
//通过反射加载ActivityThread
try {
cl = Class.forName(className, true, classLoader);
} catch (ClassNotFoundException ex) {
throw new RuntimeException(
"Missing class when invoking static main " + className,
ex);
}
Method m;
try {
// ActivityThread的main方法
m = cl.getMethod("main", new Class[] {
String[].class });
} catch (NoSuchMethodException ex) {
throw new RuntimeException(
"Missing static main on " + className, ex);
} catch (SecurityException ex) {
throw new RuntimeException(
"Problem getting static main on " + className, ex);
}
int modifiers = m.getModifiers();
// main方法必须是public static
if (! (Modifier.isStatic(modifiers) && Modifier.isPublic(modifiers))) {
throw new RuntimeException(
"Main method is not public and static on " + className);
}
// 为了进程启动时清理栈帧,抛出MethodAndArgsCaller,在ZygoteInit.main方法中捕获处理,此处是关键啊
throw new ZygoteInit.MethodAndArgsCaller(m, argv);
}
这里有一点需要重点注意的,在Android 8之前的版本都是通过直接在MethodAndArgsCaller抛出该异常,然后在ZygoteInit.java中的main方法中捕获,但是Android 8及以后都改变了这种策略是通过返回MethodAndArgsCaller,然后在main中直接调用,其逻辑如下所示,接着判断Runnable 是否为空,如果不为空则调用run方法。
invokeStaticMain方法中直接抛出MethodAndArgsCaller caller对象异常,该方法的参数m是指main()方法, argv是指ActivityThread. 这里直接通过异常抛回去(重点,此时是运行在App进程中),即回到了ZygoteConnection.runOnce然后返回到ZygotInit的runSelectLoop中然后返回到ZygoteInit.main中,下一步进入caller.run()方法,也就是MethodAndArgsCaller.run()。好吗是不是有点糊涂,还是直接看下调用链吗,逻辑如下:
//注意,这个时候是在App进程,否则你会一直在思考不是说runSelectLoop是个死循环吗,为啥出来了啊
throw MethodAndArgsCaller
throw RuntimeInit.findStaticMain
throw ZygoteConnection.handleChildProc
throw ZygoteConnection.runOnce
throw ZygoteInit.runSelectLoop
ZygoteInit.main
catch caller.run
//[ZygoteInit.java]
public static class MethodAndArgsCaller extends Exception
implements Runnable {
/** method to call */
private final Method mMethod;
/** argument array */
private final String[] mArgs;
public MethodAndArgsCaller(Method method, String[] args) {
mMethod = method;
mArgs = args;
}
public void run() {
try {
//调用ActivityThread的main方法
mMethod.invoke(null, new Object[] {
mArgs });
} catch (IllegalAccessException ex) {
throw new RuntimeException(ex);
} catch (InvocationTargetException ex) {
Throwable cause = ex.getCause();
if (cause instanceof RuntimeException) {
throw (RuntimeException) cause;
} else if (cause instanceof Error) {
throw (Error) cause;
}
throw new RuntimeException(ex);
}
}
}
进过上述的兜兜转转终于开启了我们的目标进程ActivityThread的之旅了,不容易啊
ZygoteHooks.startZygoteNoThreadCreation();
try {
Trace.traceBegin(Trace.TRACE_TAG_DALVIK, "ZygoteInit");
......
runSelectLoop(abiList);
closeServerSocket();
} catch (MethodAndArgsCaller caller) {
// 调用MethodAndArgsCaller的run方法
caller.run();
} catch (RuntimeException ex) {
Log.e(TAG, "Zygote died with exception", ex);
closeServerSocket();
throw ex;
}
}
4.2 ActivityThead.main(…)
到这里不再继续进行下去了,干不动了!从此我们的目标进程要翻身当家做主人了,并且正式开启Java世界的旅程了。而我们的目标Activity也要从AMS和zygote进程的世界进入目标进程的世界了。
//[ActivityThread.java]
public static void main(String[] args) {
...
Environment.initForCurrentUser();
...
Process.setArgV0("" );
//创建主线程looper
Looper.prepareMainLooper();
ActivityThread thread = new ActivityThread();
//attach到系统进程
thread.attach(false);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
//主线程进入循环状态
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
该方法的职能是:
- 调用attach,告诉AMS进程应启动完毕,可以进行其他事情了
- 初始化应用进程的主线程,主线程会有一个消息队列,当消息队列开始循环时,便不断从获取消息处理。
我们通常说,ActivityThread就是应用进程的主线程,这其实是一种笼统的说法,其实ActivityThread并非真正意义上的线程,它不是Thread的子类,只不过ActivityThread充当了主线程的职能,它初始化了一个消息队列。在ActivityThread对象构建时,会创建一个Handler对象,这个Handler对象所绑定的消息队列就是主线程的消息队列,后面主线程所作的任何事情都是通过往Handler中发送消息来完成的,所以说Android系统是基于消息驱动的。ActivityThread对象构建后,会调用自身的attach()函数,发起一个绑定操作。
4.3 开创目标新进程时代并初始化运行时环境小结
子进程被fork出来以后,子进程通过handleChildProc来进行运行时初始化的逻辑也告一段落了。其中调用的伪代码如下(细节各位就参见上述详细源码分析了)
ZygoteConnection.handleChildProc(...)
Process.setArgV0(parsedArgs.niceName);
RuntimeInit.zygoteInit(...)
RuntimeInit.commonInit();
Thread.setDefaultUncaughtExceptionHandler(new KillApplicationHandler(...))
RuntimeInit.nativeZygoteInit();
RuntimeInit.applicationInit(targetSdkVersion, argv, classLoader)
VMRuntime.getRuntime().setTargetHeapUtilization(0.75f);
VMRuntime.getRuntime().setTargetSdkVersion(targetSdkVersion);
throw MethodAndArgsCaller
throw RuntimeInit.findStaticMain
throw ZygoteConnection.handleChildProc
throw ZygoteConnection.runOnce
throw ZygoteInit.runSelectLoop
ZygoteInit.main
catch caller.run
其中整个关系调用图,可以使用如下时序图来总结一把!

总结
一路走过来都不容易啊,坚持看到此处的更加不容易啊。为大伙点赞打call,老铁666!
通过上述章节一顿猛如虎般的操作 ,我们终于完成了Activity启动中的如下流程:
- AMS通过sokcet请求Zygote创建目标Activity所属进程
- Zygote孵化目标Activity所属进程
- 接着继续初始化目标Activity所属进程
当我们的App第一次启动时(冷启动)或者启动的Activity被配置为远程进程时,即在AndroidManifest.xml文件中定义了process:remote属性时,都需要创建新的进程。比如当用户点击桌面的某个App图标,桌面本身是一个app(即Launcher App),那么Launcher所在进程便是这次创建新进程的发起进程,该通过binder发送消息给system_server进程,该进程承载着整个Java framework的核心服务。system_server进程从ASS.startSpecificActivityLocked开始,执行创建进程的相关流程,其流程图(以进程的视角)如下:
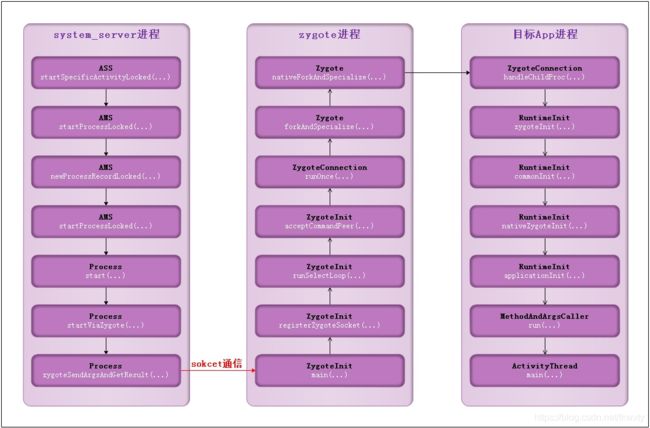
上图中,system_server进程通过socket IPC通道向zygote进程通信,zygote在fork出新进程后由于fork调用一次,返回两次,即在zygote进程中调用一次,在zygote进程和子进程中各返回一次,从而能进入子进程来执行代码。该调用流程图的过程:
-
system_server进程(章节2.1-2.4):开始最后目标Activity进程启动的之前的准备工作,检查AMS中是否存在目标Activity进程相关的ProcessRecord,如果有则更新,如果没有则创建;
-
system_server进程(章节2.5-2.9):通过Process.start()方法发起创建新进程请求,会先收集各种新进程uid、gid、nice-name等相关的参数,然后通过socket通道发送给zygote进程,并且Process.start()方法是阻塞操作,等待直到进程创建完成并返回相应的新进程pid,才完成该方法。;
-
zygote进程(章节3.1-3.11):接收到system_server进程发送过来的参数后封装成Arguments对象,图中绿色框forkAndSpecialize()方法是进程创建过程中最为核心的一个环节(详见章节3.6),其具体工作是依次执行下面的3个方法:
(1).preFork():先停止Zygote的4个Daemon子线程(java堆内存整理线程、对线下引用队列线程、析构线程以及监控线程)的运行以及初始化gc堆;
(2).nativeForkAndSpecialize():调用linux的fork()出新进程,创建Java堆处理的线程池,重置gc性能数据,设置进程的信号处理函数,启动JDWP线程;
(3).postForkCommon():在启动之前被暂停的4个Daemon子线程。 -
目标App进程(4.1~4.3):进入handleChildProc()方法,设置进程名,打开binder驱动,启动新的binder线程;然后设置art虚拟机参数,再反射调用目标类的main()方法,即Activity.main()方法。
再之后的流程,如果是startActivity则将要进入Activity的onCreate/onStart/onResume等生命周期;如果是startService则将要进入Service的onCreate等生命周期。
最后system_server进程等待zygote返回进程创建完成(ZygoteConnection.handleParentProc), 一旦Zygote.forkAndSpecialize()方法执行完成, 那么分道扬镳, zygote告知system_server进程进程已创建, 而子进程继续执行后续的handleChildProc操作.
并且在在章节4.2 AppRuntime.onZygoteInit的调用过程中会涉及到BInder线程的创建,这个过程中有startThreadPool()创建Binder线程池。也就是说每个进程无论是否包含任何Activity等组件,一定至少会包含一个Binder线程。这个也是很多面试的时候,面试官容易询问的问题!
写在最后
Activity启动流程源码实现(五)请求并创建目标Activity进程这里就要告一段落了,从前面的分析可以看出来,此时我们已将将要启动的目标Activity所属的进程在AMS中创建好了ProcessRecord信息记录,并且通过socket请求zygote进程fork出来了目标Activity进程了,并且也打入了目标Activity进程的Java世界的入口ActivityThread了。既然上述一切都准备就绪了,后面的博客就将进入ActivityThread继续分析目标Activiyt进程是怎么注册到system_server中以及则么呈现在我们界面上的。好了今天就到这里了,是时候说再见了!希望小伙们能点赞和关注,谢谢!