- n 个骰子的点数
dp[i][j] 表示前 i 个骰子产生点数 j 的次数
public List> dicesSum(int n) {
final int face = 6;
final int pointNum = face * n;
long[][] dp = new long[n + 1][pointNum + 1];
for (int i = 1; i <= face; i++)
dp[1][i] = 1;
for (int i = 2; i <= n; i++)
for (int j = i; j <= pointNum; j++) // 使用 i 个骰子最小点数为 i
for (int k = 1; k <= face && k <= j; k++)
dp[i][j] += dp[i - 1][j - k];
final double totalNum = Math.pow(6, n);
List> ret = new ArrayList<>();
for (int i = n; i <= pointNum; i++)
ret.add(new AbstractMap.SimpleEntry<>(i, dp[n][i] / totalNum));
return ret;
}
- 扑克牌顺子
public boolean isContinuous(int[] nums) {
if (nums.length < 5)
return false;
Arrays.sort(nums);
int cnt = 0;
for (int num : nums)
if (num == 0)
cnt++;
for (int i = cnt; i < nums.length - 1; i++) {
//不是连续的,返回false
if (nums[i + 1] == nums[i])
return false;
cnt -= nums[i + 1] - nums[i] - 1;
}
return cnt >= 0;
}
- 股票的最大利润
public class maxProfit {
public static int max(int[] arr) {
if(arr.length==0) return 0;
int maxprofit=0;
int min = arr[0];
//循环从1开始,因为要使用最低的买入策略arr[0]
for(int i=1;i- 求 1+2+3+...+n
正常的带if的实现是这样
public static int sumSolu(int n){
if(n<=0) return 0;
int sum=n;
sum+=sumSolu(n-1);
return sum;
}
一旦不需要if,就要利用&&的特点,第一个条件语句为 false 的情况下不会去执行第二个条件语句
public int Sum_Solution(int n) {
int sum = n;
boolean b = (n > 0) && ((sum += Sum_Solution(n - 1)) > 0);
return sum;
}
- 不用加减乘除做加法
a ^ b 表示没有考虑进位的情况下两数的和,(a & b) << 1 就是进位。
递归会终止的原因是 (a & b) << 1 最右边会多一个 0,那么继续递归,进位最右边的 0 会慢慢增多,最后进位会变为 0,递归终止
public int Add(int num1, int num2) {
return num2 == 0 ? num1 : Add(num1 ^ num2, (num1 & num2) << 1);
}
ArrayList
- 概览
实现了 RandomAccess 接口,因此支持随机访问,这是理所当然的,因为 ArrayList 是基于数组实现的。
public class ArrayList
implements List
数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;
- 扩容
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。
扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
3 线程安全
为了获得线程安全的 ArrayList,可以使用 Collections.synchronizedList(); 得到一个线程安全的 ArrayList。
List
List
也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
List
LinkedList
- 概览
基于双向链表实现,内部使用 Node 来存储链表节点信息。
private static class Node
E item;
Node
Node
}
每个链表存储了 Head 和 Tail 指针:
transient Node
transient Node
- ArrayList 与 LinkedList
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现;
ArrayList 支持随机访问,LinkedList 不支持;
LinkedList 在任意位置添加删除元素更快。
HashMap
- 存储结构
内部包含了一个 Entry 类型的数组 table。
transient Entry[] table;
其中,Entry 就是存储数据的键值对,它包含了四个字段。从 next 字段我们可以看出 Entry 是一个链表,即数组中的每个位置被当成一个桶,一个桶存放一个链表,链表中存放哈希值相同的 Entry。也就是说,HashMap 使用拉链法来解决冲突。
static class Entry implements Map.Entry {
final K key;
V value;
Entry next;
int hash;
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap m) {
}
}
- 拉链法的工作原理
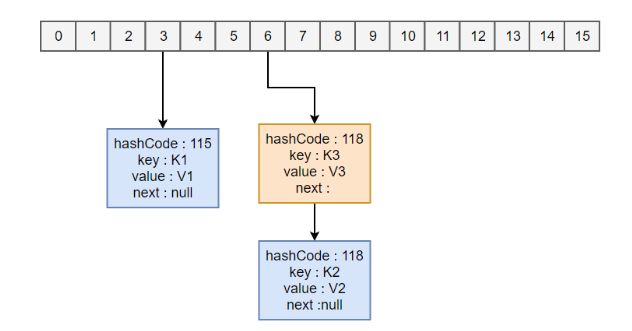
HashMap
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");
新建一个 HashMap,默认大小为 16;
插入
插入
插入
应该注意到链表的插入是以头插法方式进行的,例如上面的
查找需要分成两步进行:
计算键值对所在的桶;
在链表上顺序查找,时间复杂度显然和链表的长度成正比。
- put 操作
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 键为 null 单独处理
if (key == null)
return putForNullKey(value);
int hash = hash(key);
// 确定桶下标
int i = indexFor(hash, table.length);
// 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 value
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 插入新键值对
addEntry(hash, key, value, i);
return null;
}
HashMap 允许插入键为 null 的键值对。因为无法调用 null 的 hashCode(),也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
使用链表的头插法,也就是新的键值对插在链表的头部,而不是链表的尾部。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
// 头插法,链表头部指向新的键值对
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}