http://blog.csdn.net/stark_summer/article/details/50144591

消息队列优势:异步、削峰、解耦。
Kafka是一个开源的分布式消息系统,Kafka中的核心概念有:
• Kafka用 topic 对消息(message)归类。例如,在网页活动跟踪中,每个活动种类(包括网页浏览、搜
索、点击等)的消息都可以发布到一个各自的topic中。
• 向Topic发布消息的进程称为producer。
• 向Topic订阅消息并处理已发布消息的进程称为consumer。一个group中只能一个consumer消费一个topic,所以当所有consumer都是一个组时就是点对点模式,当每个consumer各属于一个组时,就是消息订阅模式。
• Kafka运行在一台或多台机器组成的集群上,Kafka集群中的节点称为 broker,端口9092。
Kafka的工作流程大致如下:producer向topic发布消息,Kafka集群对发布的消息进行处理后传给consumer。
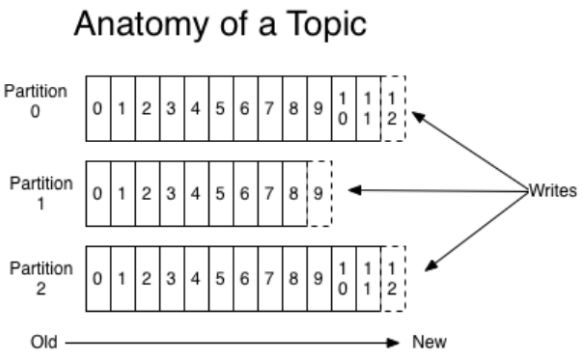
发布给一个topic的消息可以在Kafka集群中分割成多个 partition,每个parititon都是一个log,log中的消息
按发布的顺序排成一个消息列 (message sequence),Kafka不断地向log的末尾写入新的消息。每
个partition中的消息都有一个在partition中唯一的ID,称为offset,也就是相对log开头的偏移
量,Consumer在读取消息的时候会记住当前消息的offset。一个有三个partition的topic内部结构如下所
示:
1)一个topic中的每个partition都可以分给Kafka集群中的一个broker来处理(一个broker可以处理多
个partitions),这样的设计让Kafka可以方便地横向扩展,同时也提高了并行度。Kafka可以对每
个partition进行备份(replicate),备份数量(replication factor)可以设置,将备份分散到集群中不
同的broker上来实现HA。对每个partition来说都有一个作为 leader (领导者)的broker和零到多个
follower (跟随者)。Leader负责所有对partition的读写请求,follower则被动地复制leader的操作。如
果leader失效,follower之一会自动成为新的leader。
Producer可以依据一些规则来选择将消息分发给topic中的哪个partition,常见的规则有轮流分发、按哈希
值分发等等。
2)传统的消息分发模式一般有两种:queueing(队列)模式和publish-subscribe(发布订阅)模式。
在queueing模式中,消息列中的消息会依次被consumer读取。在publish-subscribe模式中,每条消息会广播(broadcast)给所有的consumer,各个consumer根据预先定义好的方式订阅所有被广播的消息的一部
分。Kafka使用 Consumer Group 实现了这两种模式的结合。
在Kafka中,一个或多个consumer组成consumer group。Consumer group表现为“逻辑的订阅者(logical subscriber)”——所有topic收到的消息都会广播给所有的consumer group,而每个consumer group选择订阅一个或多个topic中的消息,也就是说consumer group外部的消息分发模式是publish-subscribe模式。而同一个consumer group内部的consumer则遵循queueing模式。这个混合的消息分发模式有两个极限情况:
1. 所有consumer都在同一个consumer group中:这种情况是纯粹的queueing模式。
2. 每个consumer都在不同的consumer group中:这种情况是纯粹的publish-subscribe模式。
当同一个消息列中的消息被多个consumer读取时,会出现消息到达consumer的顺序和在消息列中的顺序不同的情况,所以在Kafka中,一个topic中的每个partition都只能被订阅它的各个consumer group中的 一个
consumer读取(但是一个consumer可以读多个partition),以保证在各consumer group内,各partition的消息按发布的顺序被读取。因此,一个consumer group中的consumer个数不能多于它订阅的topic中
的partition个数。在下图中,一个两节点的Kafka集群在分发四个partition的消息,每个节点负责两
个partition的分发。Kafka集群将消息分发给两个consumer group:Consumer Group A中有两
个consumer,Consumer Group B中有四个consumer。

注意,Kafka只保持partition中的消息顺序不变,并不保证topic中的消息顺序不变。要保证topic中消息顺
序不变,可以让topic只有一个partition,但是这样会牺牲并行度。
3)前面我们提到,Kafka对消息以partition为单位进行备份,一个备份称为一个replica。一个partition
的replica总数称为replication factor,replication factor按topic设置。一个partition的所有replica
中会有一个leader和零到若干个follower,所有的读写请求都由leader处理,follower像consumer一样接
收leader上的消息,写进自己的log中,保持自己的log和leader的log一致(offset一致、消息一致、消息顺
序一致)。
在Kafka中,一个replica和leader同步的标准有两个:
1. 和Zookeeper的session没有终止(通过Zookeeper的心跳机制)。
2. 如果这个replica是一个follower,它相对leader的延迟不能“太多”(可容忍的延迟可以设置)。
一个replica如果满足这两个标准,它则被称为一个 in sync replica (ISR)。Leader会记录ISR的列表,并将这
个列表存在Zookeeper上,如果有replica失效或者延迟过多,则会被leader移出ISR列表。
只有当所有的ISR都接收到了一条消息并将这条消息写进自己的log中,这条消息才算被提交(committed),而broker只会将被提交的消息发给consumer,这就保证了只要有一个ISR还在工作,提交过的消息就不会丢失。当leader失效,ISR中的一个replica将被选举为新的leader。对Kafka中一些概念的简单介绍到此结束。您可以通过开源社区的资料了解更多关于Kafka的细节。
消息队列,不像flume,它还可以存储数据,并提供对数据的管理,不用用户关心很多细节,分布式,高并发,replica容错,kafka集群由zookeeper协调
broker: kafka集群中的每一个服务器进程(节点)一般一个,kafka server,监听一些端口,下面有topic,每个topic存在可能在不同的物理机上,其他follower只是单纯的复制消息,实现冗余,每个topic有多个partition,partition可能在不同节点,每个节点相同partition只有一个,partition可有多副本,即replication,建议大于1,每条消息在partiton中有offset来唯一标识,partiton一appendlog形式存在,只能append,不支持随机读写。
producer:向kafka发送数据的程序
consumer:从kafka接收数据的程序,分两种,一种一条一条的读数据,另一种需指定partition和offset
消息在kafka中无论是否被消费,将保存7天(默认),然后将被清除,释放磁盘。按照offset顺序消费信息,重置offset可随机读,offset保存在zookeeper中。zookeeper负责维护producer和consumer。consumer group
jms有两种模型,一种是queue(队列模型),消息按队列方式顺序消费,消息只能被消费一次,一个consumer获得该消息,其他consumer不能获得该消息,另一种是topic(订阅模型),所有订阅该消息的consumer都获得该消息。kafka将这两种模型结合,只有topic模型,但是增加了consumer group概念,并且规定,一个消息在一个组里面只有一个consumer消费,那么极端情况就是所有consumer在一个组里,那就是queue模式,所有consumer分别是一个组,那就是topic模型。
对于日志来说,一条记录以"\n"结尾,或者通过其它特定的分隔符分隔,这样就可以从文件中拆分出一条一条的记录,不过这种格式更适用于文本,对于Kafka来说,需要的是二进制的格式。kafka以offset来记录数据的位置,大小,offset有zookeeper维护。
发布给一个topic的消息可以在Kafka集群中分割成多个 partition,每个parititon都是一个log,log中的消息按发布的顺序排成一个消息列 (message sequence),Kafka不断地向log的末尾写入新的消息。每个partition中的消息都有一个在partition中唯一的ID,称为 offset,也就是相对log开头的偏移量,Consumer在读取消息的时候会记住当前消息offset。
一个topic中的每个partition都可以分给Kafka集群中的一个broker来处理(一个broker可以处理多个partitions),这样的设计让Kafka可以方便地横向扩展,同时也提高了并行度。Kafka可以对每个partition进行备份(replicate),备份数量(replication factor)可以设置,将备份分散到集群中不同的broker上来实现HA。对每个partition来说都有一个作为 leader (领导者)的broker和零到多个 follower (跟随者)。Leader负责所有对partition的读写请求,follower则被动地复制leader的操作。如果leader失效,follower之一会自动成为新的leader。Producer可以依据一些规则来选择将消息分发给topic中的哪个partition,常见的规则有轮流分发、按哈希值分发等等。
kafka 的consumer 有组的概念,每个组中的消费者只能有一个消费一个topic ,所以极限情况分别为所有消费者都在同一个组,那就是队列模式,另一个是所有消费者分别在一个组,那就是订阅模式。kafka 通过topic和组将java 的队列和订阅两种模式jms 统一。

生产者不需要在zookeeper中注册,它属于客户端。
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.增加吞吐量,实现性能现行扩展。一条message只能在一个partition,追加的方式写到日志文件,偏移量offset记录每条消息相对于日志头的位置。同一个分区内,消息追加写,有序,但不同分区间无法保证有序。若是既需要kafka的吞吐量,又需要某些场景分区间有序。可通过重写partitioner.class的partition方法,自定义分区方式(默认采取轮训方式,类似于取余,根据partition数实现负载均衡),比如按照消息的某些列做特殊处理,让具有某些特征的消息进入同一分区,从而保证有序性。
List
return Math.abs(key.hashCode()) % partitions.size();
如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略。轮训即按照partition数量均匀分布,类似取余,是默认策略,有利于负债均衡和吞吐量。
Producer
负责发布消息到Kafka broker
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个【文件夹】,段segment由index和data文件组成,两个文件成对出现,分别存储索引和数据。
即xxx.index和xxx.log,该文件夹下存储这个Partition的所有消息和索引文件。
segment文件命名规则:对于所有的partition来说,segment名称从0开始,之后的每一个segment名称为上一个segment文件最后一条消息的offset值。
先找到该message所在的segment文件,通过二分查找的方式寻找小于等于345552的offset,假如叫S的segment符合要求,如果S等于345552则S上一个segment的最后一个message即为所求;如果S小于345552则依次遍历当前segment即可找到。
实际上offset的存储采用了稀疏索引,这样对于稠密索引来说节省了存储空间,但代价是查找费点时间。
Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可在Partition文件超过1GB时删除旧数据,配置如下所示。
# The minimum age of a log file to be eligible for deletion #默认一周,删除过期文件与提高Kafka性能无关。
1. 基于时间:log.retention.hours=168
2. 基于大小:log.retention.bytes=1073741824
offset由Consumer控制。正常情况下Consumer会在消费完一条消息后递增该offset。当然,Consumer也可将offset设成一个较小的值,重新消费一些消息。因为offet由Consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些消费过,
也不需要通过broker去保证同一个Consumer Group只有一个Consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
Producer发送消息到broker时,会根据Paritition机制选择将其存储到哪一个Partition。如果Partition机制设置合理,所有消息可以均匀分布到不同的Partition里,这样就实现了负载均衡。
通过配置项【num.partitions】来指定新建Topic的默认Partition数量,也可在创建Topic时通过参数指定,同时也可以在Topic创建之后通过Kafka提供的工具修改。
1. 指定了 patition,则直接使用;
2. 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition
3. patition 和 key 都未指定,使用轮询选出一个 patition。
发送消息流程:
1. producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader
2. producer 将消息发送给该 leader
3. leader 将消息写入本地 log
4. followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
5. leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
producer可以通过指定key的方式决定数据发往哪个partition:
在发送一条消息时,可以指定这条消息的key,Producer根据这个key和Partition机制来判断应该将这条消息发送到哪个Parition。Paritition机制可以通过指定Producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。
本例中如果key可以被解析为整数则将对应的整数与Partition总数取余,该消息会被发送到该数对应的Partition。(每个Parition都会有个序号,序号从0开始)
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。