Android音频开发(1):基础知识
导读
人的说话频率基本上为300Hz3400Hz,但是人耳朵听觉频率基本上为20Hz20000Hz。
对于人类的语音信号而言,实际处理一般经过以下步骤:
人嘴说话——>声电转换——>抽样(模数转换)——>量化(将数字信号用适当的数值表示)——>编码(数据压缩)——>
传输(网络或者其他方式)
——> 解码(数据还原)——>反抽样(数模转换)——>电声转换——>人耳听声。
- 抽样率
实际中,人发出的声音信号为模拟信号,想要在实际中处理必须为数字信号,即采用抽样、量化、编码的处理方案。
处理的第一步为抽样,即模数转换。
简单地说就是通过波形采样的方法记录1秒钟长度的声音,需要多少个数据。
根据奈魁斯特(NYQUIST)采样定理,用两倍于一个正弦波的频繁率进行采样就能完全真实地还原该波形。
所以,对于声音信号而言,要想对离散信号进行还原,必须将抽样频率定为40KHz以上。实际中,一般定为44.1KHz。
44.1KHz采样率的声音就是要花费44000个数据来描述1秒钟的声音波形。
原则上采样率越高,声音的质量越好,采样频率一般共分为22.05KHz、44.1KHz、48KHz三个等级。
22.05 KHz只能达到FM广播的声音品质,44.1KHz则是理论上的CD音质界限,48KHz则已达到DVD音质了。
- 码率
对于音频信号而言,实际上必须进行编码。在这里,编码指信源编码,即数据压缩。如果,未经过数据压缩,直接量化进行传输则被称为PCM(脉冲编码调制)。
要算一个PCM音频流的码率是一件很轻松的事情,采样率值×采样大小值×声道数 bps。
一个采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的WAV文件,它的数据速率则为 44.1K×16×2 =1411.2 Kbps。
我们常说128K的MP3,对应的WAV的参数,就是这个1411.2 Kbps,这个参数也被称为数据带宽,它和ADSL中的带宽是一个概念。将码率除以8,就可以得到这个WAV的数据速率,即176.4KB/s。这表示存储一秒钟采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的音频信号,需要176.4KB的空间,1分钟则约为10.34M,这对大部分用户是不可接受的,尤其是喜欢在电脑上听音乐的朋友,要降低磁盘占用
只有2种方法,
降低采样指标或者压缩。降低指标是不可取的,因此专家们研发了各种压缩方案。最原始的有DPCM、ADPCM,其中最出名的为MP3。所以,采用了数据压缩以后的码率远小于原始码率。
一、发的主要应用有哪些?
音频播放器,录音机,语音电话,音视频监控应用,音视频直播应用,音频编辑/处理软件,蓝牙耳机/音箱,等等。
二、频开发的具体内容有哪些?
(1)音频采集/播放
(2)音频算法处理(去噪、静音检测、回声消除、音效处理、功放/增强、混音/分离,等等)
(3)音频的编解码和格式转换
(4)音频传输协议的开发(SIP,A2DP、AVRCP,等等)
三、 音频应用的难点在哪?
延时敏感、卡顿敏感、噪声抑制(Denoise)、回声消除(AEC)、静音检测(VAD)、混音算法,等等。
四、 音频开发基础概念有哪些?
在音频开发中,下面的这几个概念经常会遇到。
1. 采样率(samplerate)
采样就是把模拟信号数字化的过程,不仅仅是音频需要采样,所有的模拟信号都需要通过采样转换为可以用0101来表示的数字信号,示意图如下所示:
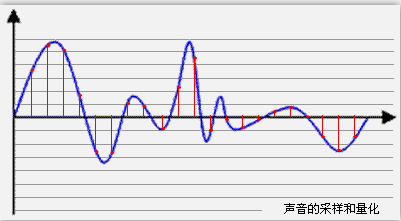
蓝色代表模拟音频信号,红色的点代表采样得到的量化数值。
采样频率越高,红色的间隔就越密集,记录这一段音频信号所用的数据量就越大,同时音频质量也就越高。
根据奈奎斯特理论,采样频率只要不低于音频信号最高频率的两倍,就可以无损失地还原原始的声音。
通常人耳能听到频率范围大约在20Hz~20kHz之间的声音,为了保证声音不失真,采样频率应在40kHz以上。常用的音频采样频率有:8kHz、11.025kHz、22.05kHz、16kHz、37.8kHz、44.1kHz、48kHz、96kHz、192kHz等。
对采样率为44.1kHz的AAC音频进行解码时,一帧的解码时间须控制在23.22毫秒内。
通常是按1024个采样点一帧
分析:
1. AAC
一个AAC原始帧包含某段时间内1024个采样点相关数据。
用1024主要是因为AAC是用的1024点的mdct。
音频帧的播放时间=一个AAC帧对应的采样样本的个数/采样频率(单位为s)
采样率(samplerate)为 44100Hz,表示每秒 44100个采样点,
所以,根据公式,
音频帧的播放时长 = 一个AAC帧对应的采样点个数 / 采样频率
则,当前一帧的播放时间 = 1024 * 1000/44100= 23.22 ms(单位为ms)
48kHz采样率,
则,当前一帧的播放时间 = 1024 * 1000/48000= 21.333ms(单位为ms)
22.05kHz采样率,
则,当前一帧的播放时间 = 1024 * 1000/22050= 46.439ms(单位为ms)
2. MP3
mp3 每帧均为1152个字节,
则:
每帧播放时长 = 1152 * 1000 / sample_rate
例如:sample_rate = 44100HZ时,
计算出的时长为26.122ms,
这就是经常听到的mp3每帧播放时间固定为26ms的由来。
2. 量化精度(位宽)
上图中,每一个红色的采样点,都需要用一个数值来表示大小,这个数值的数据类型大小可以是:4bit、8bit、16bit、32bit等等,位数越多,表示得就越精细,声音质量自然就越好,当然,数据量也会成倍增大。
常见的位宽是:8bit 或者 16bit
3. 声道数(channels)
由于音频的采集和播放是可以叠加的,因此,可以同时从多个音频源采集声音,并分别输出到不同的扬声器,故声道数一般表示声音录制时的音源数量或回放时相应的扬声器数量。
单声道(Mono)和双声道(Stereo)比较常见,顾名思义,前者的声道数为1,后者为2
4. 音频帧(frame)
是用于测量显示帧数的量度。所谓的测量单位为每秒显示帧数(Frames per Second,简称:FPS)或“赫兹”(Hz)。
音频跟视频很不一样,视频每一帧就是一张图像,而从上面的正玄波可以看出,音频数据是流式的,本身没有明确的一帧帧的概念,在实际的应用中,为了音频算法处理/传输的方便,一般约定俗成取2.5ms~60ms为单位的数据量为一帧音频。
这个时间被称之为“采样时间”,其长度没有特别的标准,它是根据编×××和具体应用的需求来决定的,我们可以计算一下一帧音频帧的大小:
假设某通道的音频信号是采样率为8kHz,位宽为16bit,20ms一帧,双通道,则一帧音频数据的大小为:
int size = 8000 x 16bit x 0.02s x 2 = 5120 bit = 640 byte
五、常见的音频编码方式有哪些?
上面提到过,模拟的音频信号转换为数字信号需要经过采样和量化,量化的过程被称之为编码,根据不同的量化策略,产生了许多不同的编码方式,常见的编码方式有:PCM 和 ADPCM,这些数据代表着无损的原始数字音频信号,添加一些文件头信息,就可以存储为WAV文件了,它是一种由微软和IBM联合开发的用于音频数字存储的标准,可以很容易地被解析和播放。
我们在音频开发过程中,会经常涉及到WAV文件的读写,以验证采集、传输、接收的音频数据的正确性。
六、常见的音频压缩格式有哪些?
首先简单介绍一下音频数据压缩的最基本的原理:因为有冗余信息,所以可以压缩。
(1) 频谱掩蔽效应: 人耳所能察觉的声音信号的频率范围为20Hz~20KHz,在这个频率范围以外的音频信号属于冗余信号。
(2) 时域掩蔽效应: 当强音信号和弱音信号同时出现时,弱信号会听不到,因此,弱音信号也属于冗余信号。
下面简单列出常见的音频压缩格式:
MP3,AAC,OGG,WMA,Opus,FLAC,APE,m4a,AMR,等等
七、Adndroid VoIP相关的开源应用有哪些 ?
imsdroid,sipdroid,csipsimple,linphone,WebRTC 等等
八、音频算法处理的开源库有哪些 ?
speex、ffmpeg,webrtc audio module(NS、VAD、AECM、AGC),等等
九、Android提供了哪些音频开发相关的API?
音频采集: MediaRecoder,AudioRecord
音频播放: SoundPool,MediaPlayer,AudioTrack
音频编解码: MediaCodec
NDK API: OpenSL ES
十、音频开发的延时标准是什么?
ITU-TG.114规定,对于高质量语音可接受的时延是300ms。一般来说,如果时延在300~400ms,通话的交互性比较差,但还可以接受。时延大于400ms时,则交互通信非常困难。
有问题请在下方留言或者加入星球