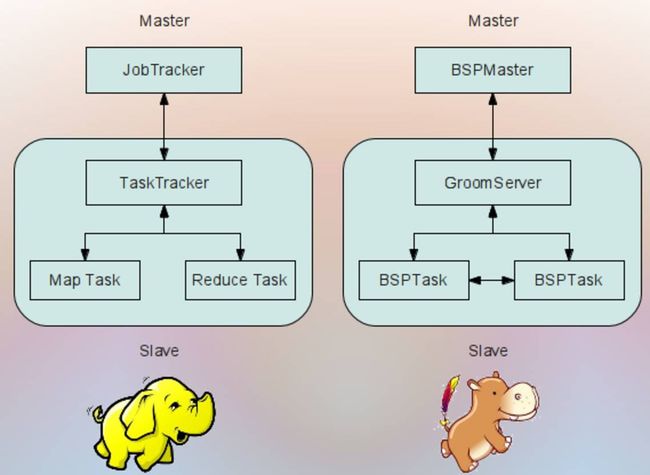
在 "TF Boy 之初筵 - 分布十三式", 里面,我们提到参数服务器PS+Worker。 我们基本上是在Client里面定义好了TF模型(网络图),然后提交给Master,然后Master找到Worker, 选择其中一部分作为PS,另外一部分作为Worker。 所以深入点点,就知道其实机器簇,不仅仅包括PS 和Job Worker 这些Worker, 还有Client-Master的架构。

其实这个Client-Master过程和Hadoop的YARN分布式非常相似!Client-Master进行资源管理。

如果我们回顾一下, Hadoop的YARN的管理, 往物理机器管理方面有一层结构(NameNode 和 DataNode), 往应用管理方面也有一层结构(Application Master 和 Container)。

我们之前的MNIST例子运行里面("TF Boy 之初筵 - 分布十三式"), 就没有了物理机器管理的这一层。这一层资源分配是手动做的。 其实这层物理管理就是云计算的能力。所以,目前好多分布式系统都是这样Client-Master结构,直接忽视了Hadoop云的平台能力, 关注到Map-Reduce,或者BSP的应用。
但是我们关注的不是Client-Master结构, 今天说的PS结构是如何工作的。 如果把TensorFlow和Hadoop/Spark结合起来, 就会有四层结构: NameNode-DataNode, ResourceManager-NodeManager这两层分别是物理链接和资源配置层。 Client-Master 是应用架构, PS-Worker (Map-Reduce)是Task架构。
前言:从PS交互到TF架构
一旦Session开始Run之后, Client就会把网络模型提交到Master。

然后Master会把模型解析, 会把参数的部分配置到PS上面, 然后数据和网络运算放到Worker的部分。

然后,PS 和 Worker之间就会协同工作, 通过RECV 和 SEND 的简单操作进行协同:

而这种协同, 可以利用:1)建立在TCP的gRPC 2)RDMA Remote direct memory access 进行的。
所以总得来说, 机器簇通过利用Master进行参数的剥离,构建了适合机器学习的参数服务器。常用的有两种接口gRPC和RDMA。

如果我们把上述的:
Client-Master分布式(Distributed Master),
图的执行(Dataflow Executor) ,
每个图节点的类型(Kernel implementations),
以及交互模式(RPC/RDMA Networking Layer),
再有单机设备使用(CPU/GPU Device Layer)
合在一起就是TensorFlow底层的基础架构:
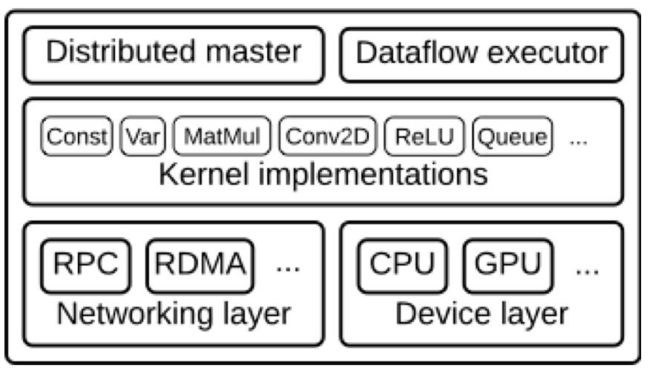
TF机器族
那么我们先假定, 通过Hadoop平台的资源配置给我们Client-Master的应用构建。 我们通过VPN的Client端链接到云端的Main Node开始部署。 然后利用N+1个Worker Node, 分配1个PS Task Node 和 N个Worker Task Node。

有了这些信息,我们就可以构建TF族了。 我们把PS信息和Task Worker的信息, 写到tf.train.ClusterSpec中, 这是一个族的Specification定义描述。 同时还要指定好, 信息交互的协议(RPC/RDMA)。 然后我们定义好要运行的TF图Graph, 在启动一个TF Session。 就可以开始跑分布式的TF学习了。

对应到前面的Client-Master结构, 大家要注意的是,这里的Session 并不会跑在PS上面的。
如果更进一步,还要关注参数服务器上的参数的更新方式,Task Worker之间是同步还是异步学习的?如果是同步学习的, 那么对优化器就要加同步学习的锁。

分布式编程
运算Tensor图
首先得有一个运算的图, 这个图肯定有些部分可以同时运行的那种。 如下图的”add 1“ 和 ”subtract 8“:

然后, 我们很容易实现一个单机的程序来完成这个图的:

接下来, 我们希望把y1 和 y2的计算放到2个worker上去计算。
定义机器族, 配置不同Device运行图的不同部分
1. 首先我们定义一个机器族
cluster = tf.train.ClusterSpec({"local": ["localhost:2222","localhost:2223"]})
2. 把运算分配到两个机器device上去。
withtf.device("/job:local/task:0"):
y1 = x -8
withtf.device("/job:local/task:1"):
y2 = x +1
z = y1 * y2
要注意的是,device的定义形式如下:
/job:JOB_NAME/task:TASK_NUMBER
3.启动Session,提交y计算。
要注意的是, session里面z值是要从worker上面获取的, 需要开启grpc的链接。
import
tensorflowastf
cluster = tf.train.ClusterSpec({"local": ["localhost:2222","localhost:2223"]})
x = tf.constant(5)
withtf.device("/job:local/task:0"):
y1 = x -8
withtf.device("/job:local/task:1"):
y2 = x +1
z = y1 * y2
with
tf.Session("grpc://localhost:2223")assess:
result = sess.run(z)
print(result)
4. 定义并运行Worker的Server,每个Server要指定job_name和task_index, 这里指定的值, 回头是要在上面的设备/job:JOB_NAME/task:TASK_NUMBER里面匹配上的。
importtensorflowastf
cluster = tf.train.ClusterSpec({"local": ["localhost:2222","localhost:2223"]})
task_number =0# and 1
server = tf.train.Server(cluster,job_name="local",task_index=task_number)
print("Starting server #{}".format(task_number))
server.start()
server.join()
需要启动task_index = 0 和 task_index = 1 两个Server。
5.Session运行结束, 打印值。
python zcalc.py
-18
模拟Map-Reduce编程
从上面, 我们知道了分布式是如何实现的, 我们接下来解释, TF的机器簇,是如何模拟Map-Reduce编程的。
函数式接口
MR编程是将接口柯西化, 然后实现函数式编程的。 这样我们要定义好Map 和 Reduce。 又因为是函数式编程, 我们运行前时候不知道数据内容。
TF里面有一个很好的Tensor叫Placeholder来实现这个功能。
x=tf.placeholder(tf.float32,100)
我们定义了一个100个数据长度的float32类型的输入数据。
Reduce 接口
然后我们分布在不同的两个设备上执行Reduce操作。 这里是把100个数据, 均匀分成两组, 一组50个, 求均值, 然后再集中求均值。
withtf.device("/job:local/task:1"):first_batch=tf.slice(x,[0],[50])mean1=tf.reduce_mean(first_batch)
withtf.device("/job:local/task:0"):second_batch=tf.slice(x,[50],[-1])mean2=tf.reduce_mean(second_batch)mean=(mean1+mean2)/2
Map 接口
我们在Session启动的时候, 把随机产生的100个数据feed给x 这个placeholder。
withtf.Session("grpc://localhost:2222")assess:result=sess.run(mean,feed_dict={x:np.random.random(100)})print(result)
同时通过gRPC接口到task 0机器上读取到mean值, 然后打印出来。

再对比下下, 我们通过placeholder模拟了函数式编程, 通过feed 模拟了map操作, 通过worker Server 实现了并行。 然后又通过gRPC实现了Reduce的合并功能。
参数服务器
有了并行之后,我们可以方便的定义Worker Server了,然后通过分布式的device指定运行的内容。

然后把部分Worker指定为参数服务器, 甚至评价服务器Scorer

小结:
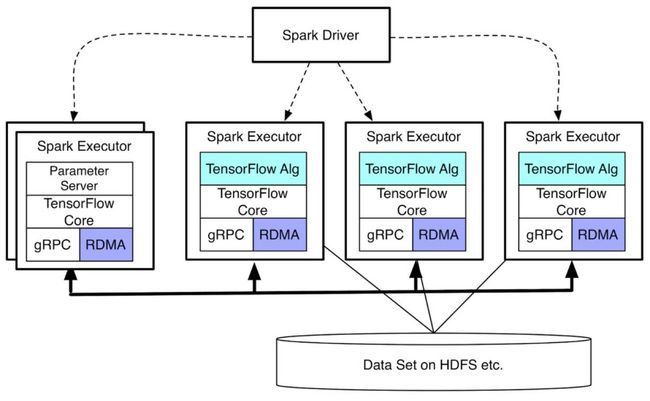
我们解释了基于机器簇的TF分布式的实现。 并且说明了Client-Master结构的便利性, 因此Hadoop和TF可以组合使用。 当然了, 这个也是可以在除了Hadoop平台外的Spark平台实现的:
相关话题:
TF Boy 之初筵 - 分布十三式
机器学习平台的优化器 (优化篇)
机器学习平台的优化器 (平台篇)
收敛率概述 (Overview of Rates of Convergence)
迭代优化算法之直观概述 (SVRG)
信息熵的由来
“66天写的逻辑回归” 引
一步一步走向锥规划 - LS
一挑三 FJ vs KKT
变分の美
矩阵分解 (乘法篇)
矩阵分解 (加法篇)
最大似然估计的2种论证


参考:
http://planspace.org/20170411-distributed_mapreduce_with_tensorflow/
https://www.tensorflow.org/extend/architecture