支持向量机分类预测
线性支持向量机
在上一节关于线性模型的课程中,我们学习了通过感知机构建一个线性分类器,完成二分类问题。
感知机的学习过程由误分类驱动,即当感知机寻找到没有实例被错误分类时,就确定了分割超平面。这样虽然可以解决一些二分类问题,但是训练出来的模型往往容易出现过拟合。
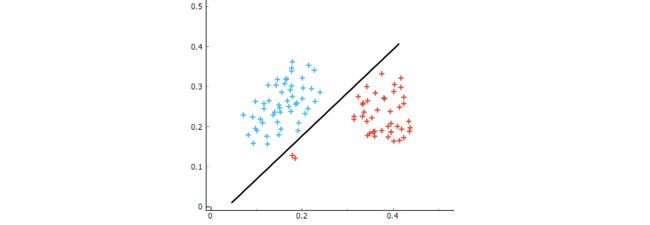
如上图所示,当感知机在进行分类时,为了照顾左下角的两个红色标记样本,分割线会呈现出如图所示的走向。这条线对于训练样本分割完全正确,但是很容易出现过拟合。不难想象,在蓝色标记样本和红色标记样本中间的新的测试数据很有可能会被误分类。
Vapnik 于 1963 年提出了支持向量机(SVM)理论,它是一种功能强大的监督学习算法,用于分类或回归,SVM 可以看作是感知机的延伸,其和感知机一样也是一种判别式分类器:也就是说,其作用就是在数据集之间划清界限。这里我们先举一个分类的例子来引入支持向量机。
首先,我们需要创建一个数据集,这里数据集的创建用到了 scikit-learn 的数据生成器 make_blobs,不同于上个实验中我们用到的 make_classification 分类数据生成器,make_blobs 用于生成可聚类的数据集,产生一个数据集和相应的标签。其参数 n_samples:表示数据样本点个数,n_features:表示数据的维度,这里使用默认值 2,centers:产生数据的类别数,random_state:随机数种子,设置为 0,cluster_std:数据集的标准差,浮点数或者浮点数序列,默认值为 1.0。当然这里也可以使用 make_classification 分类数据生成器来生成数据。
from sklearn.datasets.samples_generator import make_blobs
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
%matplotlib inline
# 导入数据生成器
X, y = make_blobs(n_samples=50, centers=2,
random_state=0, cluster_std=0.60)
# 绘制散点图
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
判别式分类器尝试在两组数据之间画一条线。这里我们画三条不同的线来分开这些类:
# 分类器 x 的取值范围为 (-1, 3.5)
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
# 分别绘制三条线(分类器),m 为斜率,b 为截距
for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]:
plt.plot(xfit, m * xfit + b, '-k')
# 设置坐标范围
plt.xlim(-1, 3.5)
从上图结果来看,这是三个非常不同的分类器,可以完美地区分这些样本。但是对于新的数据点,这三种分类器的分类结果可能完全不同。
支持向量机:间隔最大化
那么,对此如何改进呢?支持向量机是解决此问题的一种方法。支持向量机的作用不仅是画一条线,而且还要考虑围绕某个给定宽度的线的区域,通过找出一个最大间隔超平面来完成分类,即间隔最大化。

如图所示,中间的实线是我们找到的分割超平面。这个超平面并不是随手一画,它必须满足两个类别中距离直线最近的样本点,与实线的距离一样且最大。这里的最大,也就是上面提到的最大间隔超平面。
许多朋友在一开始接触支持向量机时,对它这个奇怪的名字比较疑惑。其实,支持向量机中的「支持向量」指的是上图中,距离分割超平面最近的样本点,即两条虚线上的一个实心点和两个空心点。
接下来我们就通过 scikit-learn 来拟合一个支持向量机分类器。
# 导入支持向量机估计器
from sklearn.svm import SVC
# 构建支持向量机分类模型
clf = SVC(kernel='linear')
clf.fit(X, y)
从上述代码运行结果可以看到 SVC 函数的参数,这里我们介绍了几个重要的参数,完整的可以参考 官方文档 。
C:SVC 的惩罚参数又叫松弛变量,默认值是 1.0。C 值越大对训练集测试时准确率很高,但泛化能力弱。C 值越小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。这里提到的松弛变量如果你不了解,你可以通过 简单理论基础 了解一下,详细数学理论知识这里就不展开了。
kernel:核函数,默认是 'rbf',可以是 'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'。这里用的 'linear' ,用于线形可分的数据集,而默认是 'rbf',指的是高斯径向基核函数,常用于非线性分类的问题,在实验后面我们还会详细阐述。
gamma: 'rbf','poly' 和 'sigmoid' 的核函数参数。默认是 'auto',则会选择 1/n_features。
为了更好地可视化,接下啦,我们将创建一个决策函数 plot_svc_decision_function,该函数将为我们绘制决策边界。其中 meshgrid 将原始数据变成网格数据形式,enumerate() 函数参数为可遍历或可迭代的对象(如列表、字符串),返回索引和值。decision_function 计算样本点到分割超平面的函数距离。contour 使用 X 和 Y 绘制 P 的等高线图。参数 X 和 Y 的大小等于 P 的大小。
def plot_svc_decision_function(clf, ax=None):
if ax is None:
ax = plt.gca() # 获得对象子图
x = np.linspace(plt.xlim()[0], plt.xlim()[1], 30)
y = np.linspace(plt.ylim()[0], plt.ylim()[1], 30)
Y, X = np.meshgrid(y, x) # 生成网格点坐标矩阵,将向量 x 和 y 定义的区域转换成矩阵(数组) X 和 Y
P = np.zeros_like(X) # 生成和 X 相同 shape 的全 0 数组
for i, xi in enumerate(x):
for j, yj in enumerate(y):
P[i, j] = clf.decision_function([[xi, yj]])
# 得到分割超平面
# 绘制分割超平面旁的两条虚线
ax.contour(X, Y, P, colors='k',
levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
接下来,让我们调用这个函数,画出分类结果:
# 绘制与前面相同的散点图
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
plot_svc_decision_function(clf)
从上图结果我们可以看到分割超平面以及经过两条虚线的「支持向量」。
让我们使用 Jupyter notebook 的交互功能 ipywidgets 来探索点的分布是如何影响支持向量和拟合判别的。代码如下,其中 interact() 函数传入函数名及其参数即可实现交互式控件,参数为数值型时,可出现一个可选滚动条,选择不同参数传入函数。
from ipywidgets import interact
# 定义只有 10 个点的支持向量机模型
def plot_svm(N=10):
# 生成 2 类的数据
X, y = make_blobs(n_samples=200, centers=2,
random_state=0, cluster_std=0.60)
X = X[:N]
y = y[:N]
clf = SVC(kernel='linear')
clf.fit(X, y) # 模型拟合
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring') # 绘制生成的数据散点图
plt.xlim(-1, 4) # 设置坐标范围
plt.ylim(-1, 6)
plot_svc_decision_function(clf, plt.gca()) # 得到决策边界
interact(plot_svm, N=(10, 200), kernel='linear')
你在上图出现的滚动条中选择不同的 N 的数值,你会看到从 10 个点到 200 个点的情况下的分割超平面的变化以及其支持向量的变化,当数值变化较小时,你会发现只有支持向量才是重要的。也就是说,如果移动任何其他点而不让它们越过决策边界,它们将不会对分类结果产生影响,这也是 SVM 的独特之处。
非线性支持向量机
通过上面的内容,你应该对线性分类有所了解,并可以使用支持向量机构建一个简单的线性分类器了。而在实际生活中,我们大部分情况面对的却是非线性分类问题,因为实际数据往往都不会让你通过一个水平超平面就完美将其分类。
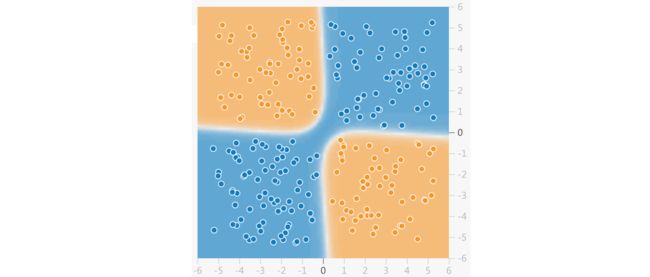
上图展现的就是一个非线性分类问题,而支持向量机就是解决非线性分类的有力武器。让我们先看看用前面的方法是否能分离非线性的数据,这里用 make_circles 生成环形形状的数据集,其参数 factor 表示里圈和外圈的距离之比,noise = 0.1 表示有 0.1 的点是异常点。
# 导入数据生成器
from sklearn.datasets.samples_generator import make_circles
X, y = make_circles(n_samples=100, factor=0.2, noise=0.1) # 生成 100 个含噪声环状数据
# 拟合支持向量机分类器
clf = SVC(kernel='linear').fit(X, y)
# 绘制散点图和分割超平面
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
plot_svc_decision_function(clf)
显然,没有线性判别可以将这些数据分开。支持向量机引入了核函数来解决非线性分类的问题。简单来讲,通过核函数,我们可以将特征向量映射到高维空间中,然后在高维空间中找到最大间隔分割超平面完成分类。而映射到高维空间这一步骤也相当于将非线性分类问题转化为线性分类问题。

如上图所示:
第一张图中,红蓝球无法进行线性分类。
使用核函数将特征映射到高维空间,类似于在桌子上拍一巴掌使小球都飞起来了。
在高维空间完成线性分类后,再将超平面重新投影到原空间。
在将特征映射到高维空间的过程中,我们常常会用到多种核函数,包括:线性核函数、多项式核函数、高斯径向基核函数等。其中,最常用的就算是高斯径向基核函数了,也简称为 RBF 核。
我们来看看用高斯径向基核函数的 SVM 模型是否能正确分类前面所生成的环状数据:
clf = SVC(kernel='rbf') # 核函数选择高斯径向基
clf.fit(X, y) # 拟合模型
# 绘制散点图及决策边界
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
plot_svc_decision_function(clf)
从以上图形看出,选择了高斯径向基核函数的支持向量机分类器能将环状数据正确分类,你还可以将上述代码第一步中的 kernel='rbf' 的 'rbf' 改成 'poly' 或者 'sigmoid',看看其他核函数对支持向量机的分类效果的影响。
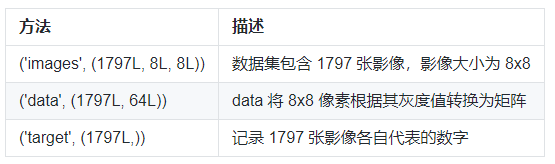
接下来,我们就通过 scikit-learn 来完成另一个非线性分类实例。这次,我们选择了 digits 手写数字数据集。digits 数据集无需通过外部下载,可以直接由 scikit-learn 提供的 datasets.load_digits() 方法导入。该数据集的详细信息如下:
第一步,导入数据并进行初步观察。
from sklearn import datasets # 导入数据集模块
# 载入数据集
digits = datasets.load_digits()
# 绘制数据集前 5 个手写数字的灰度图
for index, image in enumerate(digits.images[:5]):
plt.subplot(2, 5, index+1) # 子图绘制
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
# 图片灰度处理
可以用 digits.target[:5] 查看前五张手写数字对应的实际标签。
digits.target[:5]
通常,我们在处理图像问题时,都是将图像的每一个像素转换为灰度值或按比例缩放的灰度值。有了数值,就可以构建和图像像素大小相同的矩阵了。在这里,digits 已经预置了每一张图像对应的矩阵,并包含在 digits.images 方法中。
我们可以通过 digits.images[1] 输出第 1 张手写数字对应的 8x8 矩阵。很方便地,scikit-learn 已经将 8x8 矩阵转换成了方便作为特征变量输入 64x1 的矩阵,并放在了 digits.data 中。你可以使用 digits.data[1]查看。
digits.data[1]
下面,我们需要划分训练集和测试集,然后针对测试集进行预测并评估预测精准度。
from sklearn.model_selection import train_test_split # 导入数据集划分模块
from sklearn.metrics import accuracy_score # 导入评估模块
feature = digits.data
target = digits.target
# 划分数据集,将其中 70% 划为训练集,另 30% 作为测试集
train_feature, test_feature, train_target, test_target = train_test_split(
feature, target, test_size=0.30)
model = SVC() # 建立模型,这里默认 kernel='rbf'
model.fit(train_feature, train_target) # 模型训练
results = model.predict(test_feature) # 模型预测
scores = accuracy_score(test_target, results) # 评估预测精准度
scores
最后,模型预测准确度为 42.6%。由于每一次运行时,数据集都会被重新划分,所以你训练的准确度甚至会低于 42.6%。你应该会疑惑,准确度为什么这么低,不是说支持向量机的分类效果很好吗?
不要忘记了,我们在建立模型的时候使用的是默认参数。
model
上面输出了默认模型的参数。我们可以看到,该模型的确使用了最常用的 RBF 高斯径向基核函数,这没有问题。问题出在了 gamma 参数,gamma 是核函数中的一个常数,这里选择了 auto 自动。自动即表示 gamma 的取值为 1 / 特征数量,这里为 1/64。
你可以尝试将 gamma 参数的值改的更小一些,比如 0.001。重新建立模型:
model = SVC(gamma=0.001) # 重新建立模型
model.fit(train_feature, train_target) # 模型训练
results = model.predict(test_feature) # 模型预测
scores = accuracy_score(test_target, results) # 评估预测精准度
scores
可以看到,这一次的预测准确度已经达到 98%了,结果非常理想。所以说,会用 scikit-learn 建立模型只是机器学习过程中最基础的一步,更加重要的是理解模型的参数,并学会调参使得模型的预测性能更优。
你可以通过 官方文档 了解 scikit-learn 中支持向量机分类器 sklearn.svm.SVC 中包含的参数,并尝试修改它们查看结果变化。