讨论问题:
一、很多媒体报道美国在过去一些年间贫富差距扩大。这里我们分析全球数据,运用数据分析全球各个州之间在过去20年间的贫富差距是扩大,减小还是维持不变。
二、以亚洲与南美数据为例分析,如果A组的平均值大于B组,是否说明最大值在A组中
1、首先,将国家和地区数据在Github上取下来:
url = "https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
s = StringIO.StringIO(requests.get(url).content)
countries = pd.read_csv(s)
print countries.head()
Country Region
0 Algeria AFRICA
1 Angola AFRICA
2 Benin AFRICA
3 Botswana AFRICA
4 Burkina AFRICA
然后将国家的人均收入数据从https://www.gapminder.org/data/documentation/gd001/这个网站上取下来
income = pd.read_excel('.../indicator gapminder gdp_per_capita_ppp.xlsx',sheetname = "Data")
print income.head()
GDP per capita 1800 1801 1802 1803 1804 1805
0 Abkhazia NaN NaN NaN NaN NaN NaN
1 Afghanistan 603.0 603.0 603.0 603.0 603.0 603.0
2 Akrotiri and Dhekelia NaN NaN NaN NaN NaN NaN
3 Albania 667.0 667.0 668.0 668.0 668.0 668.0
4 Algeria 716.0 716.0 717.0 718.0 719.0 720.0
有些国家没有数据,删除缺失项
income = income.dropna(how='all')
我们想要画出某年各个国家的人均收入分布图,分布图用直方图来表示是最合适的,这里将年份作为行名更容易画各年的直方图
income.index=income[income.columns[0]] # 国家作为序号
income = income.drop(income.columns[0], axis = 1)
income.columns = map(lambda x: int(x), income.columns) # 将列名中的年份数据转为int类型,为了直接取年份
income = income.transpose()#转置
print income.head()
GDP per capita Afghanistan Albania Algeria Andorra Angola \
1800 603.0 667.0 716.0 1197.0 618.0
1801 603.0 667.0 716.0 1199.0 620.0
1802 603.0 668.0 717.0 1201.0 623.0
1803 603.0 668.0 718.0 1204.0 626.0
1804 603.0 668.0 719.0 1206.0 628.0
接下来画直方图:
year = 2000
plt.hist(income.ix[year].values, bins = 20)
plt.title('Year: %i' % year)
plt.xlabel('人均收入')
plt.ylabel('频数')
plt.show()
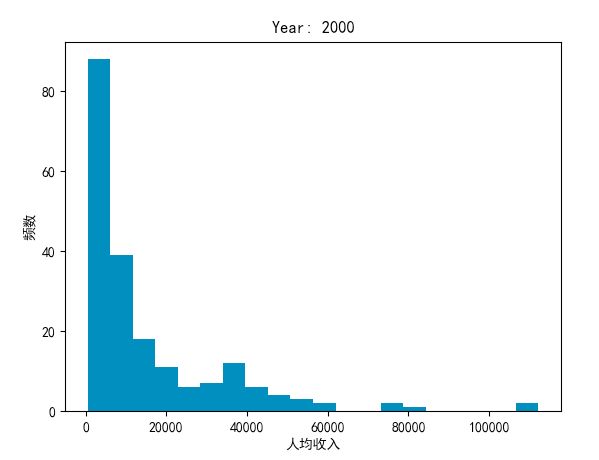
可以看出人均一万美金以下的国家最多,各个国家之间的贫富差距相当大,那1万美金以下究竟是怎么分布的看不出来,将收入取log则能区分出来:
plt.hist(np.log10(income.ix[year].dropna().values), bins = 20)
plt.title('Year: %i' % year)
plt.xlabel('人均收入 (log10)')
plt.ylabel('频数')
plt.show()

可以看出2000年时人均10000美金的国家是最多的,人均一万美金以下的分布也较广,还有人均几百美金的
接下来看各州之间的贫富差距:
2、将Country表格与income表格合并,观察两个表格可以看出共同的参数是国家名,所以以这个为主键进行合并
def mergeByYear(year):
#取出收入数据
data = pd.DataFrame(income.ix[year].values, columns=['Income'])
# 拿到income的列名,作为新dataframe的Country列
data['Country'] = income.columns
joined = pd.merge(data, countries, how="inner", on=['Country'])
return joined
print mergeByYear(2000).head()
Income Country Region
0 962.0 Afghanistan ASIA
1 5305.0 Albania EUROPE
2 9885.0 Algeria AFRICA
3 31662.0 Andorra EUROPE
4 3387.0 Angola AFRICA
3、画出各州的人均收入分布,这里采用箱形图来表现,箱形图可以表示数据的多种特征,如下图所示:
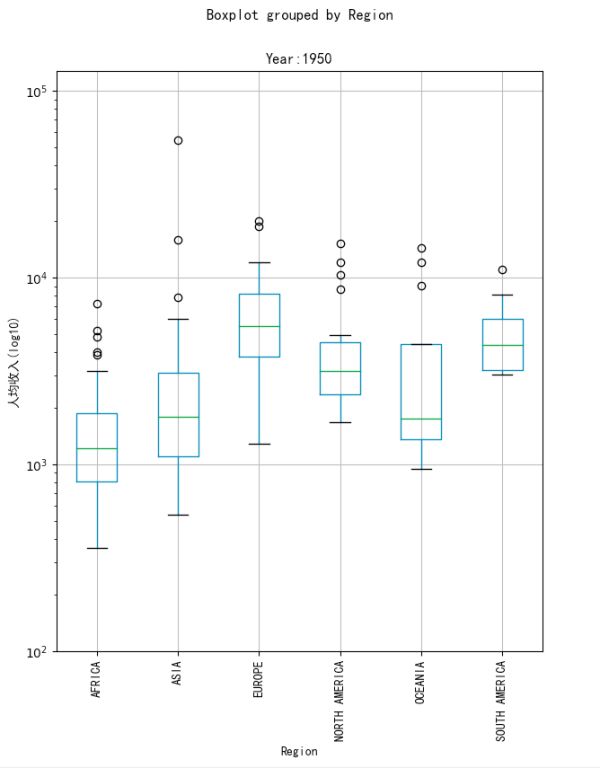
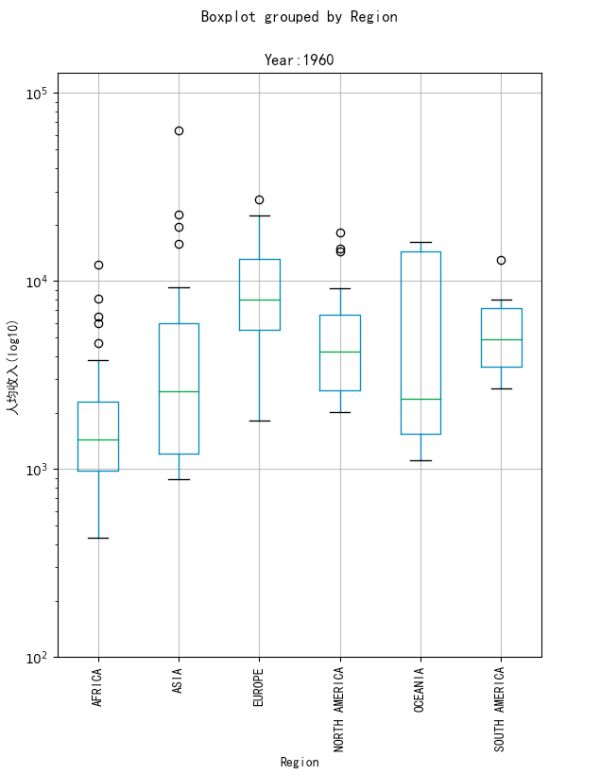
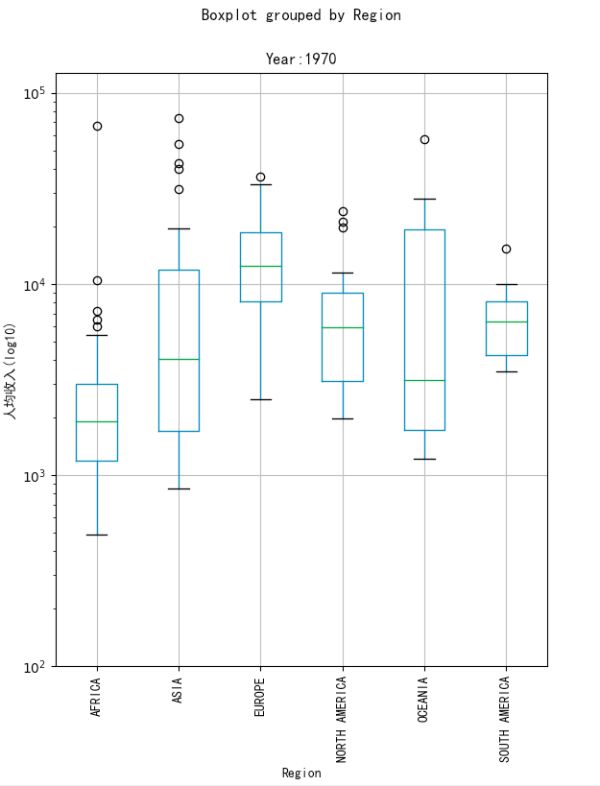
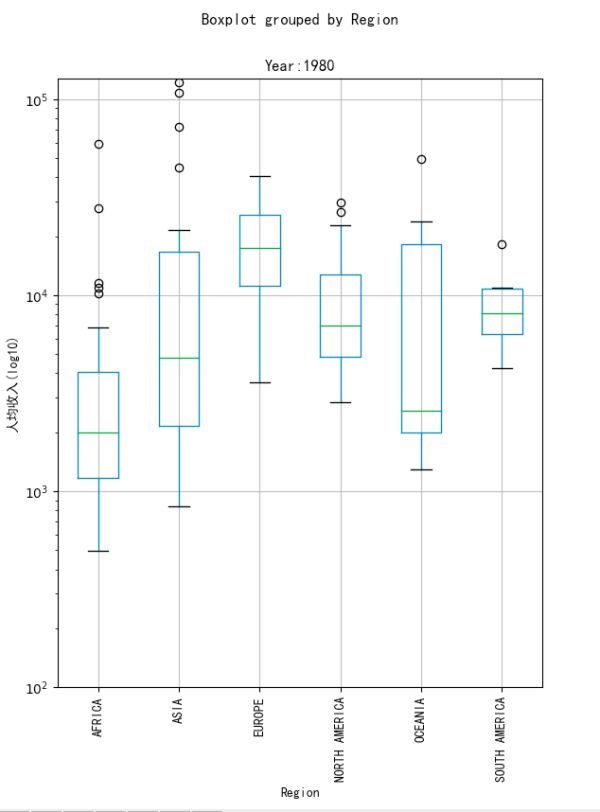
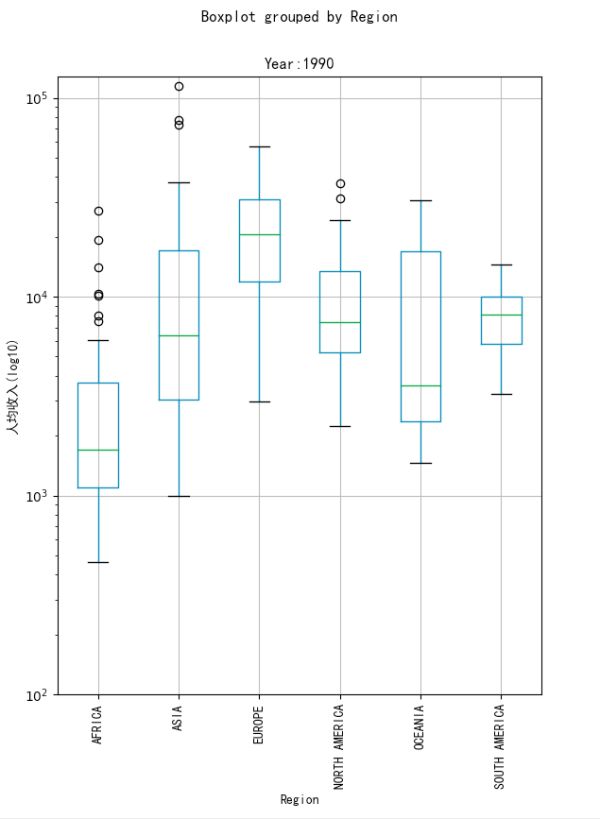

可以看出亚洲和非洲人均收入的趋势是向上的,亚洲相比上升更多,其他州则基本保持不变。同时可以看出非洲和亚洲的奇异值相比较多,并且箱型图越来越长,说明亚洲和非洲各个国家之间的贫富差距较大,这种差距从20世纪60年代持续至今。
接下来讨论问题二:
1、如果有两组数据X和Y,都大致服从正态分布,X和Y的标准差都为1,但是X的均值大于Y的均值,计算Pr(X > a)/Pr(Y > a) 。
列出该表达式的函数:
diff是X的均值,Y的均值为0
def ratioNormals(diff,a):
X = scipy.stats.norm(loc = diff,scale = 1)
Y = scipy.stats.norm(loc = 0,scale = 1)
return X.sf(a)/Y.sf(a) #sf是生存函数,即求X>a的概率
用不同的均值差来计算概率比值:
diffs = np.linspace(0,5,50)
aa = range(2,6)
for a in aa:
ratios = [ratioNormals(diff, a) for diff in diffs]
plt.plot(diffs,ratios)
plt.legend(["a={}".format(a) for a in aa], loc=0);
plt.xlabel('Diff');
plt.ylabel('Pr(X>a) / Pr(Y>a)');
plt.title('不同差值下Pr(X>a)与Pr(Y>a)的概率比');
plt.yscale('log')
plt.show()

可以看出,在正太分布下,当X的均值大于Y时,Pr(X>a)>Pr(Y>a),并且差值越大,两者之间的差距也越大。
2、考虑亚洲和南美的人均收入分布,计算这两个州的人均收入,哪个州的人均收入更多
利用mergeByYear函数拿到地区、国家、收入的dataframe,按照地区分组聚合,计算平均收入,可以看出亚洲的平均收入远大于南美。
merged = mergeByYear(2012).groupby('Region', as_index=False).mean()
merged = merged.loc[(merged.Region == "ASIA") | (merged.Region == "SOUTH AMERICA")]
merged.Income = np.round(merged.Income, 2)#保留小数点两位
print merged
Region Income
1 ASIA 23500.43
5 SOUTH AMERICA 13015.75
3、那接下来算一下人居收入大于10000美金的国家占所在州的比例,,再次看一下上面的结论是否正确。构造一个计算国家比例的函数:
def ratioCountries(groupedData, a):
#下面key指的是Region,group指代的是key所对应的分组,必须要有key指定才能找到分组信息,这里求得是各州中人均收入大于10000美金的国家占所在州国家的比例
prop = [len(group.Income[group.Income >= a]) / float(len(group.Income.dropna())) for key, group in groupedData]
z = pd.DataFrame(groupedData.mean().index, columns = ['Region'])
z['Mean'] = np.round(groupedData.mean().values,2)
z['P(X > %g)' % a] = np.round(prop, 4)
return z
df = mergeByYear(2012).groupby('Region')
df_ratio = ratioCountries(df, 1e4)
print df_ratio
Region Mean P(X > 10000)
0 AFRICA 5601.22 0.2000
1 ASIA 23500.43 0.5676
2 EUROPE 30738.19 0.8571
3 NORTH AMERICA 16036.65 0.6500
4 OCEANIA 10481.15 0.3077
5 SOUTH AMERICA 13015.75 0.7500
把南美和亚洲提取出来:
df_ratio = df_ratio[(df_ratio.Region == 'ASIA') | (df_ratio.Region == 'SOUTH AMERICA')]
print df_ratio
Region Mean P(X > 10000)
1 ASIA 23500.43 0.5676
5 SOUTH AMERICA 13015.75 0.7500
可以看出人均大于10000美金的国家在所在州所占比例,亚洲小于南美,这与上面的结论不一致。
4、上面可以看出亚洲国家之间的贫富差距有多大,接下来考虑一个问题,如果考虑各国人口数量,那人均收入是否会发生改变呢
比如我国和日本,我国的人均GDP8000美金,日本人均GDP35000美金,按照上面的算法,两国人均收入(8000+32000)/2,我国人均收入瞬间提升到20000美金。如果考虑两国人口呢,假设中日是一个国家,中国人口14亿,日本1亿3000万,那平均收入的计算方法为:
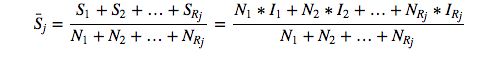
N为人口,I为本国的人均收入,则上述中日两国修正后的人均收入为(8000 14+320001.3)/(14+1.3)≈10000
如此看来,计算了各国人口,这个平均值才能代表亚洲的真实水平,那接下来修正一下这个数据。这里可以将上述表达式进行拆分,只需要求出各国总收入除以整个州的人口,然后求和便能求出平均收入。
首先导入人口数据,并对其进行预处理:
#首先导入人口数据
population = pd.read_excel('.../indicator_total population with projections.xlsx',sheetname = "Data")
print population.head()
Total population 1086 1100 1290 1300 1348 1349 1351 1377 \
0 Abkhazia NaN NaN NaN NaN NaN NaN NaN NaN
1 Afghanistan NaN NaN NaN NaN NaN NaN NaN NaN
2 Akrotiri and Dhekelia NaN NaN NaN NaN NaN NaN NaN NaN
3 Albania NaN NaN NaN NaN NaN NaN NaN NaN
4 Algeria NaN NaN NaN NaN NaN NaN NaN NaN
1413 ... 2006 2007 2008 2009 \
0 NaN ... NaN NaN NaN NaN
1 NaN ... 28420974.0 29145841.0 29839994.0 30577756.0
2 NaN ... NaN NaN 15700.0 NaN
3 NaN ... 3156607.0 3169665.0 3181397.0 3192723.0
4 NaN ... 33391954.0 33906605.0 34428028.0 34950168.0
删除全部是NAN的国家,按照上面的方法将数据进行处理,方便下面进行分组聚合。
population = population.dropna(how='all')
population = population.rename(columns = {'Total population':'Country'})#重命名
#把国家列设为index
population.index=population[population.columns[0]]
population = population.drop(population.columns[0], axis = 1)
population.columns = map(lambda x: int(x), population.columns)#将年份改为int类型
population = population.transpose()
接下来我们想把人口数据这个表格与mergeByYear这个包含人均收入,国家,地区的表格进行合并.
#将其与income,国家,地区按照国家这个主键进行合并
def mergeByYearWithPop(year):
merged_df = mergeByYear(year)
pop_df = pd.DataFrame(population.ix[year].values, columns=['Population'])
pop_df['Country'] = population.columns
joined = pd.merge(merged_df,pop_df,how="inner", on=['Country'])
#按照刚才的分析求调整后的收入,再定义一个函数,这里传入的是按地区分割的groupby对象
def func(df):
totlePop = df.sum()['Population']
df['AdjustedIncome'] = df.Income * df.Population / float(totlePop)
df.AdjustedIncome = np.round(df.AdjustedIncome, 2)
return df
return joined.groupby('Region').apply(func)
print mergeByYearWithPop(2012).head()
Income Country Region Population AdjustedIncome
0 1893.0 Afghanistan ASIA 33397058.0 15.66
1 9811.0 Albania EUROPE 3227373.0 53.43
2 12779.0 Algeria AFRICA 36485828.0 489.77
3 41926.0 Andorra EUROPE 87518.0 6.19
4 7230.0 Angola AFRICA 20162517.0 153.13
得到这个dataframe后,将最后一列按照Region求和便能得出调整后的平均收入,接下来求按国家计算的平均收入和考虑人口数量的平均收入
mergeWithPop_df = mergeByYearWithPop(2012).groupby('Region').sum()
df1 = mergeByYear(2012).groupby('Region').mean()
mergeWithPop_df.Income = mergeByYear(2012).groupby('Region').mean().Income
mergeWithPop_df = mergeWithPop_df.ix[['ASIA', 'SOUTH AMERICA']]
print mergeWithPop_df
Income Population AdjustedIncome
Region
ASIA 23500.432432 4.036626e+09 9717.54
SOUTH AMERICA 13015.750000 4.005576e+08 14551.71
这里可以看出,亚洲在调整前的平均收入大于南美,而当考虑了人口后,平均收入小于南美。
综上所述,如果A与B都服从正太分布,那当A的平均值大于B时,Pr(X>a)>Pr(Y>a),而当讨论两个州人均收入大于10000美金的国家所占比例时得出了相反的结论,这是因为国家的人均收入不遵循正太分布。
最后考虑了各国的总人口,将州人均收入进行了调整,得出在调整前亚洲的人均收入大于南美,然后调整后反而小了,这说明亚洲国家之间的贫富差距相当大,太多奇异值使得按照国家计算时与按照人口计算时偏差太大,而南美各国间的贫富差距较小,两个数据之间差距不太大。