redis中的数据结构
redis总结
1.字符串--SDS
struct sdshdr {
unsigned int len; //字符长度
unsigned int free; //当前可用空间
char buf[]; //具体存放字符的buf
};
通过预分配内存和维护字符串长度,实现动态字符串
减少修改字符串带来的内存分配次数(空间预分配和惰性空间释放)
(1)空间预分配:小于1MB,多分配与len同样大小的未使用空间,大于1MB,多分配1MB的未使用空间
(2)惰性空间释放:字符串收缩多余的的字节存放在free等待将来使用
Bitmaps
String类型上的一组面向bit操作的集合,最大长度是512m, 所以bitmaps能最大设置2^32个不同的bit
1.Bitmaps的最大优点就是存储信息时可以节省大量的空间
2.Bitmaps局限性:样本分布不均匀,造成空间上的浪费,以及key值如果是url等可能hash出相同的int值,降低Bitmap准确性
3.Bitmaps使用场景:各种实时分析和存储与对象ID关联的节省空间并且高性能的布尔信息(例如使用 bitmap 实现用户上线次数统计、统计活跃用户)
vs 布隆过滤器
Bloom Filter与单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应,从而降低了冲突的概率
2. list -- 双端链表
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
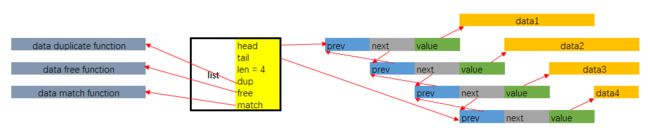
- 双端链表
- 无环
- 多态: void*保存节点值
利用redis构建轻量级消息队列
(1)维护两个队列:pending 队列和 doing 表(hash表)
(2)由 pending 队列出队后,workers 分配一个线程去处理任务,并将时间戳和当前线程名称以及任务 id 写入 doing 表,如果 worker 完成消息的处理则自行擦除 doing 表中该任务 id 信息,如果处理业务失败,则主动回滚
(3)启用一个定时任务,每隔一段时间去扫描doing队列,检查每隔元素的时间戳,如果超时,把任务 rollback,即把该任务从 doing 表中删除,再重新 push 进 pending 队列
3.hash 表
typedef struct dictEntry { //保存K-V值的结构体
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; //one of 结构
struct dictEntry *next;//链地址法解决冲突
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht { //哈希表结构体
dictEntry **table;//指向kv结构;
unsigned long size;//表大小
unsigned long sizemask;//计算索引值
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;//操作特定类型键值对的函数
void *privdata;//私有数据指针, 传递给类型特定函数的可选参数
dictht ht[2];//两个bucket,用于扩容
long rehashidx; /* rehashing not in progress if rehashidx == -1 */ //-1时候不在扩容中
unsigned long iterators; /* number of iterators currently running */ //运行的迭代器数
} dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint; //安全迭代器,能迭代所有已存在的kv;先rehash再迭代
} dictIterator;
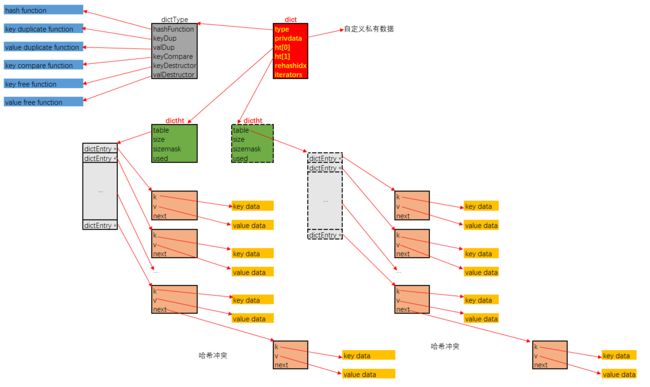
平滑扩容, 定义了ht[2]这个数组字段. 其用意是这样的:
- 一般情况下, 字典dict仅持有一个哈希表dictht的实例, 即整个字典由一个bucket实现.
- 随着插入操作, bucket中出现冲突的概率会越来越大, 当字典中存储的结点数目, 与bucket数组长度的比值达到一个阈值(1:1)时, 字典为了缓解性能下降, 就需要扩容
- 扩容的操作是平滑的, 即在扩容时, 字典会持有两个dictht的实例, ht[0]指向旧哈希表, ht[1]指向扩容后的新哈希表. 平滑扩容的重点在于两个策略:
- 后续每一次的插入, 替换, 查找操作, 都插入到ht[1]指向的哈希表中
- 每一次插入, 替换, 查找操作执行时, 会将旧表ht[0]中的一个bucket索引位持有的结点链表, 迁移到ht[1]中去. 迁移的进度保存在rehashidx这个字段中.在旧表中由于冲突而被链接在同一索引位上的结点, 迁移到新表后, 可能会散布在多个新表索引中去.
- 当迁移完成后, ht[0]指向的旧表会被释放, 之后会将新表的持有权转交给ht[0], 再重置ht[1]指向NULL
这种平滑扩容的优点有两个:
- 平滑扩容过程中, 所有结点的实际数据, 即dict->ht[0]->table[rehashindex]->k与dict->ht[0]->table[rehashindex]->v分别指向的实际数据, 内存地址都不会变化. 没有发生键数据与值数据的拷贝或移动, 扩容整个过程仅是各种指针的操作. 速度非常快
- 扩容操作是步进式的, 这保证任何一次插入操作都是顺畅的, dict的使用者是无感知的. 若扩容是一次性的, 当新旧bucket容量特别大时, 迁移所有结点必然会导致耗时陡增.
链地址法解决hash冲突
rehash负载因子: used/size
平滑扩容
(1)后续每一次的插入,替换,查找操作,都插入到ht[1]指向的哈希表中
(2)每一次插入,替换,查找操作执行时,会将旧表ht[0]中的一个bucket索引位持有的结点链表,迁移到ht[1]中去,迁移的进度保存在rehashidx这个字段中。在旧表中由于冲突而被链接在同一索引位上的结点,迁移到新表后,可能会散布在多个新表索引中去
(3)当迁移完成后, ht[0]指向的旧表会被释放,之后会将新表的持有权转交给ht[0], 再重置ht[1]指向NULL
字典遍历迭代器
(1)安全迭代器: 禁止rehash(bgaofrewrite和bgsave指令需要遍历所有对象进行持久化, 不允许出现重复)
(2)不安全迭代器: rehash中会发生元素重复遍历
4.set --intset 对象保存的所有元素都是整数值
否则,用hashtable
typedef struct intset {
uint32_t encoding; // 编码方式
uint32_t length; // 集合包含的元素数量
int8_t contents[]; // 保存元素的数组
} intset;
//3种编码方式
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
1.凡有一个数值元素的值超过了int32_t的取值范围, 整个intset都要进行升级, 即所有的数值都需要以int64_t的形式存储. 显然升级的开销是很大的
2.intset中的数值是以升序排列存储的, 插入与删除的复杂度均为O(n). 查找使用二分法, 复杂度为O(lgn)
3。intset的代码实现中, 不预留空间, 即每一次插入操作都会调用zrealloc接口重新分配内存. 每一次删除也会调用zrealloc接口缩减占用的内存. 省是省了, 但内存操作的时间开销上升了.
4.intset的编码方式一经升级, 不会再降级.
总之, intset适合于如下数据的存储:
所有数据都位于一个稳定的取值范围中. 比如均位于int16_t或int32_t的取值范围中
数据稳定, 插入删除操作不频繁. 能接受O(lgn)级别的查找开销
5. zset 有序集--ziplist / dict + skiplist
5.1 ziplist

当数据量少时, sorted set是由ziplist来实现的。任意类型数据
(1)zlbytes存储整个ziplist所占用的内存的字节数
(2)zltail指的是ziplist中最后一个entry的偏移量
(3)zllen指的是整个ziplit中entry的数量
(4)zlend是一个终止字节, 其值为全F, 即0xff
(5)每个entry中prevlen存储了它前一个entry所占用的字节数,encoding存储着当前结点的数据类型:(二进制,还是数值。。。。),如何编码(如果是数值,数值如何存储,如果是二进制数据,二进制数据的长度),data存储真实的数据
5.2 dict+skiplist
当sorted set中的元素个数, 即(数据, score)对的数目超过128的时候或者当sorted set中插入的任意一个数据的长度超过了64, sorted set是由dict + skiplist来实现
数据结构中跳表原理

/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
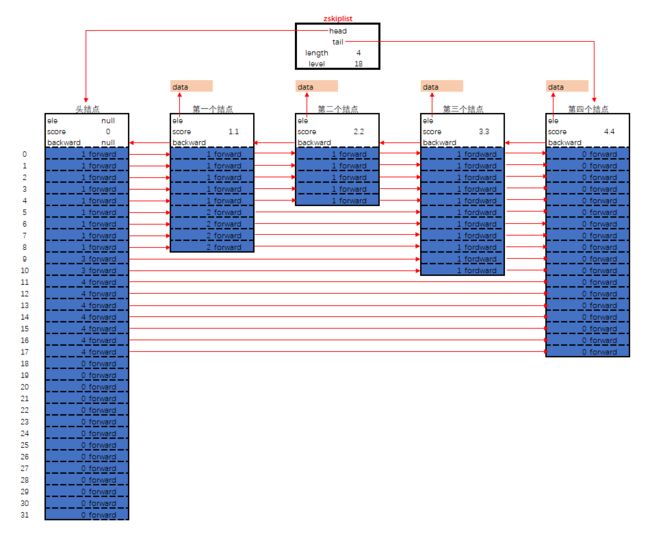
1.skiplist 在有序链表和多层链表的基础上发展起来的,每个节点随机出一个层数(level),除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多),这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置,同时插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整,降低了插入操作的复杂度
- level[]是一个柔性数组,存放指向各层链表后一个节点的指针(后向指针),另外,每个后向指针还对应了一个span值,它表示当前的指针跨越了多少个节点,span用于很方便地计算出元素排名(rank)
- 分数(score)允许重复,即skiplist的key允许重复,经典skiplist中是不允许的
- 在比较时,不仅比较分数(相当于skiplist的key),还比较数据本身,在Redis的skiplist实现中,数据本身的内容唯一标识这份数据,而不是由key来唯一标识,当多个元素分数相同的时候,还需要根据数据内容来进字典排序
对比其树
- skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的, 而哈希表不是有序的,在哈希表上只能做单个key的查找, 不适宜做范围查找
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂, 而skiplist的插入和删除只需要修改相邻节点的指针, 操作简单又快速
3.查找单个key,skiplist和平衡树的时间复杂度都为O(log n),