输入url到页面显示发生了什么
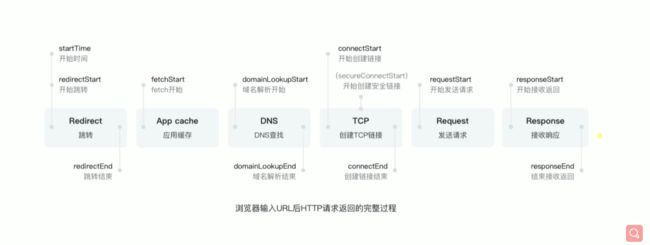
- 第一步 redirect(跳转)
会做一个redirect,问什么呢,因为浏览器可能记录了你所访问的地址,并且永久跳转到一个新的地址,所以一开始浏览器就要去判断需不需要redirect以及我要redirect到哪里。 - 第二步 App cache(应用缓存)
请求的资源可能已经缓存过了,如果没有缓存,才会真正的去发送请求。 - 第三步 DNS解析
域名会被解析成ip地址,找到响应的服务器。 - 第三步 创建TCP连接
如果是普通的http请求,会有三次握手;如果是https请求又不一样,中间会有保证安全的数据传输的过程。 - 第四步 Request发送请求
此时连接创建完毕后就会真正的发送http数据包。 - 第五步 Response接收响应
后端接收数据进行处理最后返回数据。
网络协议分层
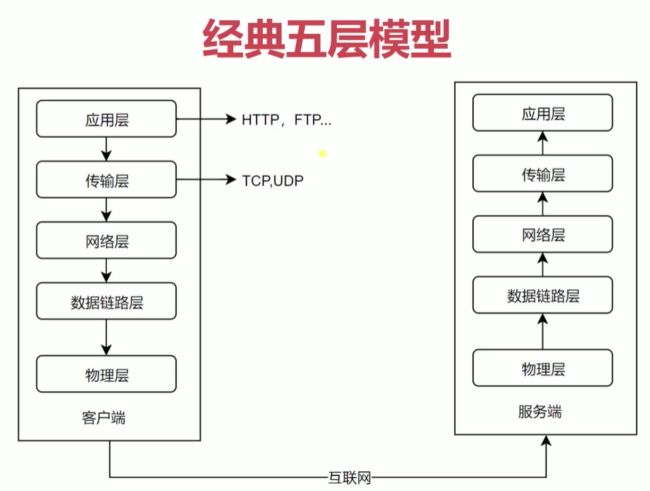
- TCP/IP协议是一个很重要的协议,要创建一个HTTP的服务或者FTP的服务,这些服务都是基于TCP协议的基础上实现的。
- 传输层
- 向用户提供可靠的端到端(end-to-end)服务。
- 比如自己的电脑和百度之间如何进行传输,传输的数据有大有小,如果数据很大就要进行分包、分片,分包和分片数据到另一端的时候如何去传输、组装都是由传输层来定义的。
- 传输层向高层屏蔽了下层数据的通信细节。
- 数据传输,分包、分片、组装是怎么实现的,在应用层(也就是http层)是不需要关心的,传输层已经帮我们封装好了。
- 向用户提供可靠的端到端(end-to-end)服务。
- 应用层
- 为应用软件提供了很多服务
- 构建于TCP协议之上
- 屏蔽了网络传输相关细节
http的历史
- http/0.9
- 只有一个get命令:我们用的get请求、post请求统称为http的命令或者方法。
- 没有header等描述数据的信息
- 服务器发送完数据后,就关闭了TCP连接。
- TCP连接里面可以发送多个http请求,http请求是在某一个tcp连接中去发送的。
- http/1.0(和http1.1很相近)
- 增加了一些命令;如post、put、header等
- 增加了status code和header(请求头响应头,里面可以有数据相关的描述)
- 多字符集支持、多部分发送、权限、缓存等。
- http1.1(在http1.0的基础上增加了一些功能来优化整个连接的过程)
- 支持持久连接(http1.0发送一个http请求会先建立一个tcp连接,但是接收完数据后连接会关闭,下次发请求要重新建立连接,建立连接要经过tcp的三次握手,比较消耗性能,如果能够复用,性能会得到很大的优化,持久连接就是http请求完成后tcp连接不会关闭,可以继续在这个连接上发送其他http请求)
- pipeline (一个tcp连接可以串行发送多个请求,服务端会根据请求过来的顺序一个一个返回,后一个请求要等待前一个请求返回完成才可以发送,不能并行,在http2会做优化)
- 增加host和其他一些命令(有了host,一个后台服务器【物理服务器】就可以同时部署多个web服务)
- http2
- 所有的数据以二进制进行传输(http1.0大部分数据都是通过字符串传输的,字符串传输和二进制数据传输分片方式是不一样的,在http2.0中数据都是以帧进行传输的,也正是因为这个原因,同一个连接里面发送多个请求不需要再按照顺序来)
- 同一个连接里面发送多个请求不需要再按照顺序来
- 头信息压缩以及推送等提高效率的功能。(在http1头信息中很多字段,比如content-type、cache-conteol等等都是以字符串形式保存的,占用带宽的量比较大,http2会对其进行压缩,减少带宽)
- 服务端主动推送(http1请求一个页面,服务器会先返回页面,浏览器解析了页面以后,再去请求需要的css、js等资源;到了http2服务器在返回页面的同时把css、js等资源推送到客户端)
- https(就是一个安全版本的http1.1)
TCP连接和http的关系
- http不存在连接的概念,只存在请求和响应;要发送http请求,必须先创建tcp连接。之后才可以发送请求。
- 长连接和短连接的区别是:短连接是在发送http请求的时候创建连接,请求完就关闭连接;长连接是先声明一个连接,然后发送http请求,请求完成后连接不会关闭。
TCP连接三次握手
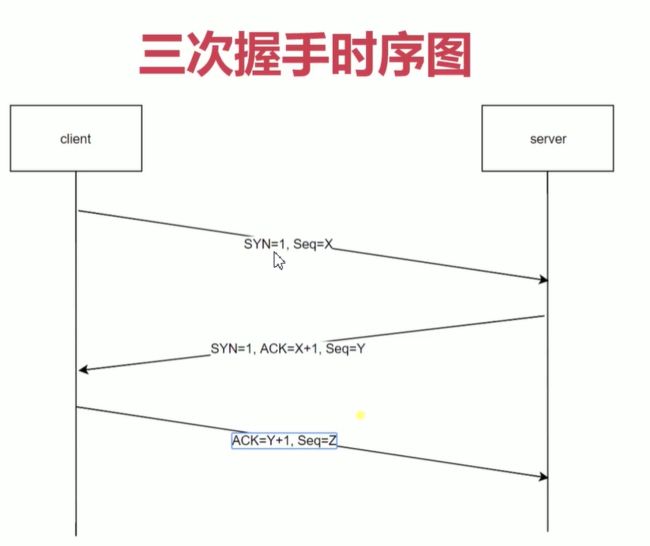
- 为什么要有三次握手?它的作用是什么?
- 客户端和服务端之间要创建连接,如果客户端只发送了一次请求,服务端就创建连接了,可能会存在一个问题:当服务器把数据返回给客户端的时候,可能因为网络原因,客户端没收到,响应时长过了以后,客户端关闭了这个连接;但是服务端不知道,依然保持着当前端口连接等待客户端发送请求过来,这样就会造成不必要的性能开销。所以需要客户端接收到响应后再次发送一个请求,服务端收到了说明现在网络良好,可以传输数据了。所以三次握手的目的就是规避由于网络延迟造成服务端产生不必要开销的问题。
cors预请求(跨域的时候回出现预请求的验证 )
允许的方法有
- GET
- HEAD
- POST
允许的Content-Type有
- text/plain
- multipart/form-data
- application/x-www-form-urlencoded
其他限制
- 请求头限制
- 自定义的请求头
- XMLHttpRequestUpload对象没有注册任何事件监听器
- 请求中没有使用ReadableStream对象
但我们可以在服务端设置允许的请求头,比如
response.writeHead(200,{
'Access-Control-Allow-Origin' : '*', //允许跨域的域名
'Access-Control-Allow-Headers' : 'custom-Test',//允许跨域的请求头,可以是自定义的
'Access-Control-Allow-Methods' : 'POST, PUT, Delete',//允许跨域的请求方法
'Access-Control-Max-Age' : '1000'//不需要再次发送预请求的最大时间,单位是秒
});
在跨域的时候,会发现程序写的只发送了一条请求,但network出现了两条,其中一条请求头的除了Mehods的类型是OPTIONS,其他信息和我们发出的请求一模一样,该请求就是发送的预请求。
缓存Cache-Control
可缓存性(哪些地方可以去缓存)
- public 指的是发送的http请求返回内容所经过的任何路径当中,包括一些中间的http的代理服务器,以及发出这个请求的客户端浏览器,都可以进行对于返回内容的缓存的操作,缓存操作指的就是把这份内容缓存在本地,下一次请求可以直接读缓存去使用
- private 指的是只有发起求情的浏览器才能够进行缓存
- no-cache 指的是任何节点都不能进行缓存。
到期
- max-age =
缓存多少秒后过期 - s-maxage =
只在代理服务器才生效,同时设置max-age和s-max-age,s-max-age会代替maxage;是专门为代理服务器设置的,客户端浏览器还是读取max-age作为缓存的时间。 - max-stale =
max-age是发起请求的一方主动带的请求头,在max-age过期之后,如果返回的资源中有max-stale的设置,代表即便缓存过期了,但是只要是在max-stale的时间内,还可以使用过期的缓存,而不需要去源服务器去请求新的内容,只有在发起端设置是有用的,服务端设置是没有用的。
重新验证
- must-revalidate 在设置了max-age的缓存当中,如果过期了,必须从服务端,源服务端去方请求重新获取数据验证内容是否真的过期了,而不能直接使用本地的缓存。
- proxy-revalidate 和must-revalidate基本一个意思,不过是作用于缓存服务器当中的,在过期后,缓存服务器必须从源服务器请求一遍,而不能使用本地的缓存。
其他
- no-store 要和no-cache做一个区分,no-cache是可以在本地进行缓存的,也可以在代理服务器进行缓存,但每次发起请求都要去服务器那边做验证,如果服务器返回告诉可以用本地的缓存,然后请求方才能去使用缓存。no-store指本地和代理服务器都不可以缓存,打个不恰当的比方,即使告诉浏览器可以使用缓存,浏览器本地也没有缓存。
-
no-transform 作用于代理服务器,有些代理服务器觉得返回的资源太大了,代理服务器会进行一些压缩,进行一些格式转换,通过no-transform禁止代理服务器的这种行为。
 image.png
image.png
验证
- Last-Modifiled 上次修改时间,配合If-Modified-Since或者If-Unmodified-Since使用
我们请求一个资源,请求的资源返回了Last-Modifield头信息,指定了一个时间,这个时间在下一次浏览器发起请求的时候就会带上Last-Modifield传过来的值,比如值为val,那么浏览器会设置头信息If-Modified-Since或者If-Unmodified-Since,一般浏览器都是使用If-Modified-Since,If-Unmodified-Since很少会被用到,头信息的值就是val,服务器可以通过读取request的头信息,找到资源存在的地方,找到其修改的时间,如果发现这两个时间是一致的,代表该资源未被修改过,然后就告诉浏览器可以使用缓存的资源,如果不一致,就返回新的资源。 - Etg 是一种更加严格的验证,通过数据签名 ,配合If-Match或者If-Non-Match使用,我们的资源,也就是内容会产生一个唯一的签名,如果资源的数据进行过修改,那么签名就会产生一个新的,最典型的做法就是会对资源的内容进行一个hash计算得到一个唯一值。也就是浏览器在请求一个资源的时候响应头会返回该资源的签名值,下次浏览器去请求的时候会带上头信息If-Match或者If-Non-Match,服务器收到后会和现在该资源的签名去做对比,如果一致,就不需要返回新的内容。
const http = require('http');
const fs = require('fs');
http.createServer(function (request, response) {
console.log('request come',request.url);
if(request.url == '/'){
const html = fs.readFileSync('test.html','utf-8');
response.writeHead(200,{
'Content-Type':'text/html'
});
response.end(html);
}
if(request.url == '/script.js'){
const etag = request.headers['if-none-match'];
if(etag === '777'){
/**
* 1.当写入头为304的时候,即使我们把Etag的值改变了,浏览器也不会重新拿到新资源,
* 也不会更新响应头返回的Etag的新值,所以下次请求的时候用的还是老的Etag的值。
* 2.当设置Cache-Control的值no-cache时候,如果响应头返回了Last-Modified和Etag的值,
* 浏览器再次发送请求的时候会添加Last-Modified和Etag的请求头;
* 当设置Cache-Control的值no-cache时候,即使应头返回了Last-Modified和Etag的值,
* 浏览器再次发送请求也不会添加Last-Modified和Etag的请求头;
**/
response.writeHead(304,{
'Content-Type':'application/javascript',
'Cache-Control':'max-age=2000000,no-store',
'Last-Modified':'123',
'Etag':'7778'
});
response.end('some word')
}else{
response.writeHead(200,{
'Content-Type':'application/javascript',
'Cache-Control':'max-age=2000000,no-store',
'Last-Modified':'123',
'Etag':'777'
});
response.end('console.log("script loaded twice")');
}
}
}).listen(8888);
console.log('service listening on 8888');
Cookie
- 通过Set-Cookie设置 :Cookie是在服务端返回数据的时候通过添加Set-Cookie请求头设置在浏览器里面保存内容的;保存的内容就叫做Cookie。
- 下次求情会自动带上
- 键值对,可以设置多个
Cookie属性
- max-age和expires设置过期时间
- Secure 只在https的时候发送
- HttpOnly 设置了HttpOnly属性以后,浏览器端就无法通过 document.cookie访问
const http = require('http');
const fs = require('fs');
http.createServer(function (request, response) {
console.log('request come',request.url);
const host = request.headers.host;
if(request.url == '/'){
const html = fs.readFileSync('./test.html','utf-8');
/**注意,下面代码我们在a.test.com的域名设置domain的值为test.com,其实是不能成功的,也就是说不能
* 在二级域名下设置一级域名的cookie;此时cookie不能被设置成功。
* **/
if(host==='a.test.com'){
response.writeHead(200,{
'Content-Type':'text/html',
'Set-Cookie':['id=123;max-age=2','abc=456;HttpOnly','def=789;domain=test.com']
});
}
response.end(html);
};
}).listen(8888);
console.log('service listening on 8888');
修改代码
if(host==='test.com'){
response.writeHead(200,{
'Content-Type':'text/html',
'Set-Cookie':['id=123;max-age=2','abc=456;HttpOnly','def=789;domain=test.com']
});
}
此时是可以设置成功的,由于设置的domain的值是一级域名test.com。那么a.test.com以及b.test.com都会带上所设置的cookie。
Http长连接
发送http请求需要创建TCP连接,在http0.9和http1.0的时候每发送一次请求都需要建立创建一个TCP的连接,请求响应后这个连接就会关闭,下次发请求会重新创建TCP连接;http1.1之后包括http1.1是支持长连接的,意思是只创建一次TCP连接,
之后的请求都通过这个连接。我们打开百度,随意输入一个关键字去搜索,打开network截图如下:

图中有一列显示的是connectionID,connectionID相同表明是同一个TCP连接。http1.1的连接在TCP上发送请求是有先后顺序的,不能在同一个TCP连接上去并发的发送。我们在加载首页的时候是希望去并发的,因为这样效率会高一点;所以浏览器可以允许并发的创建TCP连接,数目会有限制,比如chrome浏览器限制的数量为6;

图中可以看出,connectionID为93370的TCP连接发送了三次请求,后一次请求要等待前一次的返回。
数据协商
分类
- 请求
1.Accept通过Accept 声明浏览器想要的数据
2.Accept-Encoding 代表数据的编码方式,主要限制服务端如何进行数据压缩,比如gzip,deflate,br
3.Accept-Language
4.User-Agent -
返回
1.Content-Type
2.Content-Encoding
3.Content-Language
 image.png
image.png
Redirect
const http = require('http');
http.createServer(function (request, response) {
console.log('request come',request.url);
if(request.url=='/'){
response.writeHead(301,{
'Location':'/new'
});
response.end('');
}
if(request.url=='/new'){
response.writeHead(200,{
'Content-Type':'text/html'
});
response.end('this is content
');
}
}).listen(8888);
console.log('service listening on 8888');
301(临时重定向)和302(永久重定向)区别是 302会先发送请求到服务端,服务端返回之后浏览器再次发送请求,一共发送了两次请求;302是服务端高告知浏览器如果再次出现某个资源的请求路径,直接在浏览器端改变求情资源的地址,所以只会发送一次请求。要特别注意的是,一旦做了301的跳转,浏览器会尽可能长时间的去做缓存,即使之后服务端修改了响应头,改为200,浏览器也是无感知的,除非是客户端用户自己手动清理浏览器的缓存才能得到新的响应资源,所以使用301一定要慎重。
CSP Content-Security-Policy 内容安全策略
作用
- 限制资源获取
- 报告资源获取越权
限制方式
- default-src限制全局 限制跟请求链接的作用范围
- 制定资源类型
类型种类很多,比如:default-src(全局的限制,包括img资源、css资源、js资源等等) , content-src ,img-src , mainfest-src , font-src , media-src ,
style-src , frame-src , script-src ...
test.html
Title
scp
服务端 service.js
const http = require('http');
const fs = require('fs');
http.createServer(function (request, response) {
console.log('request come',request.url);
const html = fs.readFileSync('./test.html','utf-8');
if(request.url==='/'){
response.writeHead(200,{
'Content-Type':'text/html',
//只允许通过外链加载的js执行
// 'Content-Security-Policy':'default-src http: https:'
// 只允许通过外链的从本域加载的js执行
'Content-Security-Policy':'default-src \'self\''
//只允许通过外链的从本域或者 http://code.jquery.com/加载的js执行
// 'Content-Security-Policy':'default-src \'self\' http://code.jquery.com/'
});
response.end(html);
}else{
response.writeHead(200,{
'Content-Type':'application/javascript'
});
response.end('console.log("loaded script")');
}
}).listen(8888);
console.log('service listening on 8888');
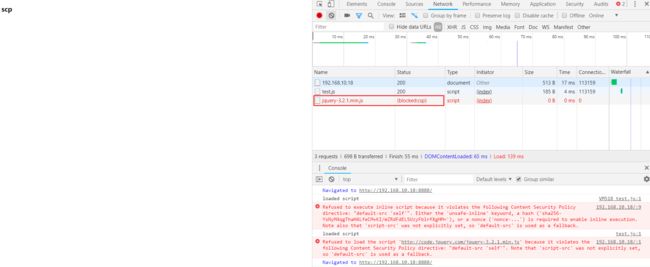
Content-Security-Policy的设置可以在服务端,亦可以在客户端返回的html文档。
nginx代理
- 下载安装http://nginx.org/en/download.html
 image.png
image.png
下载后解压
目录结构如下:
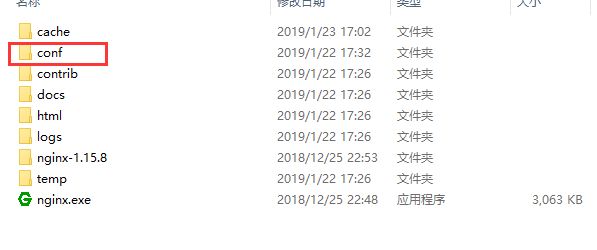 image.png
image.png
配置文件在conf下面的nginx.conf文件中,我们建一个servers文件夹
在下面配置需要代理的域名。
文件nginx.conf中加入
include servers/*.conf;
表明include servers文件夹下面所有以.conf结尾的文件。
我们配置一个test.conf内容如下
proxy_cache_path cache levels=1:2 keys_zone=my_cache:10m;
server {
listen 80;
server_name test.com;
location / {
proxy_cache my_cache;
proxy_pass http://127.0.0.1:8888;
proxy_set_header Host $host;
}
}
server {
listen 80;
server_name a.test.com;
location / {
proxy_pass http://127.0.0.1:8888;
proxy_set_header Host $host;
}
}
server {
listen 80;
server_name b.test.com;
location / {
http://127.0.0.1:8888 http://127.0.0.1:8888;
proxy_set_header Host $host;
}
}
其中server是指要在电脑上起一个服务,其端口是80,它的server_name即域名为test.com,这个server_name指的就是我们在浏览器上面要访问的hostname,nginx会根据要访问的hostname来判断要把服务启动在什么地方,代理到什么地方。比如上面配置了test.com,说明要访问的地址是test.com,然后test.com被代理到的服务是http://127.0.0.1:8888。(要记得在hosts文件中配置test.com的映射地址,如127.0.0.1);之后我们写后端服务。
service.js代码如下
const http = require('http');
const fs = require('fs');
const wait = (seconds)=>{
return new Promise((resolve,reject)=>{
setTimeout(()=>{
resolve();
},seconds*1000);
});
};
http.createServer(function (request, response) {
console.log('request come',request.url);
const host = request.headers.host;
/**
* const html = fs.readFileSync('./test.html','utf-8');
* 此处不能用utf-8编码,因为utf-8读取时按照字符串读取,使用zlib的话,
* 希望读取的是buffer
* */
const html = fs.readFileSync('./test.html');
if(request.url==='/'){
response.writeHead(200,{
'Content-Type':'text/html',
});
response.end(html);
}
if(request.url==='/data'){
/**s-maxage是专门给代理缓存用的,同时使用了max-age=20, s-maxage=20,
* 那么代理缓存会使用s-maxage,浏览器会使用max-age。
* **/
response.writeHead(200,{
'Cache-Control':'max-age=2;s-maxage=20'
});
wait(2).then(()=>{
response.end('success')
});
}
}).listen(8888);
console.log('service listening on 8888');
test.html代码如下
nginx-cache
this is content, and data is:
test.conf的配置是
proxy_cache_path cache levels=1:2 keys_zone=my_cache:10m;
server {
listen 80;
server_name test.com;
location / {
proxy_cache my_cache;
proxy_pass http://127.0.0.1:8888;
}
}
server {
listen 80;
server_name b.test.com;
location / {
proxy_pass http://127.0.0.1:8888;
proxy_set_header Host $host;
}
}
从代码中可以看出,在访问'/'路径会返回test.html,在test.html中发起了一个请求,并将结果文本显示到页面上。服务端我们延时了2s去返回请求,并设置了响应头'Cache-Control':'max-age=2, s-maxage=20',告诉浏览器可以缓存结果2秒(max-age=2),告诉代理服务器可以缓存20秒(s-maxage=20)。启用代理服务缓存还需要在具体的server配置 proxy_cache。参照上面的test.conf。
修改service.js ,设置Cache-Control的值为
response.writeHead(200,{
'Cache-Control':'max-age=5,s-maxage=20,private'
});
在浏览器端重新刷新,会发现s-maxage=20将不再生效。private是指只有浏览器才可以缓存数据。
HTTPS 即http+secret
加密
- 私钥
- 公钥
公钥放在互联网上所有人都可以拿到的遗传加密的字符串,这个加密字符串是用来加密我们传输的信息的,使用公钥加密的数据传输到服务器之后,只有服务器通过私钥进行解密才能把公钥加密过的数据解析出来。而私钥只放在服务器上,其他任何人都拿不到私钥。所以中间人即便截取了http的消息,但没有私钥还是解密不了数据的。公钥和私钥主要是用在握手的时候进行一个传输,传输内容是一个正真的在后期传输的过程中使用的加密字符串,因为加密字符串是使用公钥私钥的方式进行加密传输的,所以中间人拿不到加密字符串,后续的数据传输过程中客户端和服务端都是用这个加密字符串进行数据加密传输。
