初识联邦学习
最早知道联邦学习是在今年6月参加的O‘Reilly AI大会上,谷歌的session介绍了他们用联邦学习改善输入法预测的最新成果,令人耳目一新。它的过程是这样的:每个手机接受云端分发的初始模型,用本地的数据进行训练,之后把更新的模型传回云端,云端对来自各个手机端的数据进行聚合,形成新的模型再下发,重复这一过程。它期望达到的效果是在保护本地数据隐私的情况下实现传统方式中收集所有客户端数据进行统一训练的效果,同时节省上传本地数据的网络消耗。这一方法已经被用于谷歌输入法中,提高预测下个词语的准确率,那是我第一次知道联邦学习。
后来,GDPR的风越吹越大,对数据所有权和隐私性的关注越来越多,拿不到赖以生存的数据集,AI该怎么办?于是,联邦学习又一次出现在我的视野里。
这次,我决定好好看看它。于是,在经过了不到一周的短暂研究,我终于理解了政策与对策之间的巧妙关系以及一个新方向出来后研究员们的脑回路。虽然AI领域很多方法都停留在研究领域无法落地,但我相信,由于隐私保护的迫切性,联邦学习是一定会落地开花且成为未来的基础方法的。
TO C:谷歌GBoard应用
联邦学习,英文名叫Federated Learning,谷歌给他的定义是这样:
Build machine learning models based on data sets that are distributed across multiple devices while preventing data leakage.
也就是说,它是分布在不同设备的数据拥有者在不暴露自己数据的基础上联合训练出模型的方法。
从上面的定义可以看出,谷歌关注的是C端的应用,当然有C端的应用就一定能扩展到B端,这个我们下篇再看。
回到应用,谷歌TO C 最出名的应用就是刚刚介绍的输入法下个单词预测问题(GBoard next-word prediction)。他们发了这样一篇论文:

文中介绍了他们做联邦训练的算法FederatedAveraging,过程很好理解:每一轮训练,服务端首先下发一个全局模型给该轮参与者,参与者拿到这个模型后,根据自己的本地数据(比如,用户用输入法的敲字记录)进行模型训练,SGD计算梯度,更新模型参数,待模型收敛后传回服务端。服务端拿到参与者的模型更新后,对参数求平均生成一个新模型。
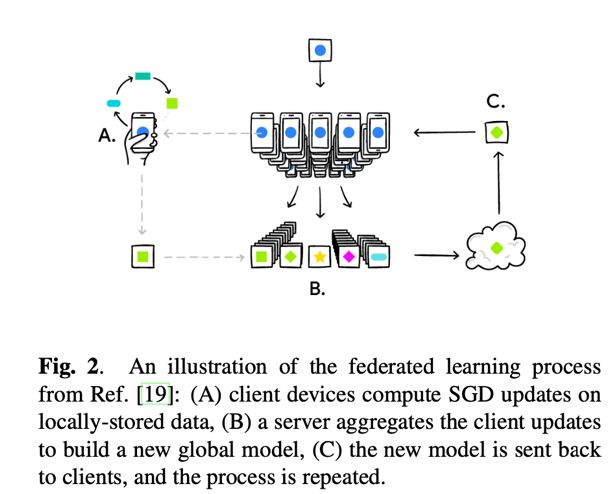
在这个过程中,不同于传统方式上传log,联邦训练使用Gboard设备中本地缓存的输入文本,也就意味着在本地训练时用到的训练数据,不仅仅局限于你在谷歌系产品中输入的内容,而是你输入的所有内容,因此更能反映真实的输入分布。同时,训练对于参与者也加入了要求,就硬件要求而言,设备必须至少具有2GB的可用内存。此外,仅当客户端正在充电,连接到wifi且处于空闲状态时,(可能也就是你睡觉的时候吧),才允许客户端参与,这样有效保证了训练对于手机端是无感知的。
比起传统方式来说,这种方式有几点好处:
首先,在整个过程中,参与者只会上传模型的更新,而不用把本地所有的输入记录都上传了,这样一来,你之前用谷歌输入法敲的“张三李四王麻子“统统不会被谷歌拿走,从物理上保护了你的隐私,同时也巧妙了绕过了GDPR关于数据隐私性的规定。你的数据就在你的手机里,我只是用它而已。
其次,由于联邦学习使用的本地数据源来自于缓存。缓存没有长度限制,且数据质量更高,因此召回和CTR更好。
基于此,谷歌得出来这样的结论:
Federated learning has proved to be a useful extension of server-based distributed training to client device-based training using locally stored data.
之后,谷歌奠定了在联邦学习TO C方向大佬的地位,开始研究一些细节问题,比如各个设备配置不一样,训练速度不同步怎么办,如何保证更新上传的安全性等等。
值得一提的是,在这篇文章中也写到了一个我非常关心的问题——对隐私数据的界定。直白一点说,本地数据算隐私,本地模型就不算了么?你不存储我的原始数据了,那我传给你的模型更新安全么?对此,文章是这么说的:
第一点,传给服务器的模型更新是临时的,集中的和汇总的(Model updates communicated to the server are ephemeral, focused and aggregated)。也就是说,我并不在意你这个单个客户端训练出的更新,我想要的是所有模型汇总起来的结果,感受到了一丝丝自作多情的感觉。
第二点,客户端更新永远不会存储在服务器上,他们在内存中进行处理,并在汇总成权重向量后立即丢弃(Client updates are never stored on the server and are processed in memory and immediately discarded after accumulation in a weight vector),这个很明确了吧,你的更新是一次性的,我也不稀罕存下来。
这就是谷歌对于我安全性担忧的回应,听上去有理有据,听完还有点被降维打击的感觉。
总之,通过这种方式,原始的数据受到了保护,虽然每个手机累点儿,再也没有闲下来的时候了,能省了数据传输也是好的。如果你想让各个客户端的模型更个性化一点,你可以在下发的共享模型中增加一些改进,形成千人千面的本地模型。
TO C:FL应用在推荐系统
看完了预测问题,之后来看看华为如何将联邦学习应用在推荐系统领域,看完论文发现,他们不仅用了联邦学习,还把元学习的理念揉进来,提出了联邦元学习模型。

元学习(meta-learning),也叫Learning to learn,是在增强学习之后的又一分支,其目的在于通过以往的经验来学习,也就是让机器自己学习如何训练。
这篇文章就用到了元学习的概念,一层一层优化的脑回路是这样的:在推荐领域,用的很多的是协同过滤(CF),但要实现CF,服务器需要收集大量的用户数据和物品数据来集中训练。应用联邦学习FL后解决了数据隐私问题,于是华为把关注点放在了优化客户端与服务器传输内容方面,在联邦学习的框架中,服务器与用户设备传输的是模型,模型太大且是通用的。于是他们引入元学习,升级成联邦元学习(Federated Meta-learning),让服务器与设备间只传输能够训练模型的算法,这样一来,既精简了传输内容,又可以使每个客户端的模型与众不同,也就是说,在这个新的框架中,任务从联合训练模型升级到了联合优化训练模型的算法。
具体的实现分为两个阶段:
第一阶段,模型训练,在各个用户设备上进行,首先在当前算法的支持集上训练模型,然后在单独的查询集上评估模型,反馈测试结果,用以提高算法训练模型的能力。
第二阶段,算法更新,在服务器上进行,根据反馈的测试结果更新算法,进行元训练。
为了不引入复杂的公式,我画了两张图表明这个过程。
首先来看看,单纯的元学习应用在推荐系统是如何做的:
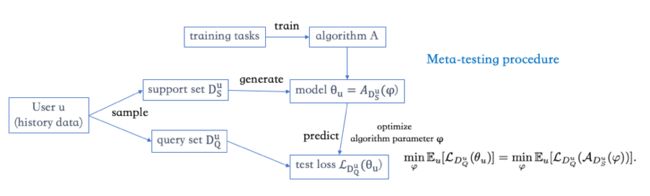
大量用户的历史数据会被采样分为支持集和查询集,他们相互独立且都已打好标签。用支持集训练模型,用查询集预测,计算损失,进行优化。当训练好的算法应用到新用户时,首先要用支持集根据这个算法生成模型,之后才能用这个模型进行预测。为了评估算法的性能,我们会将算法应用到各个测试任务中来进行元测试(meta testing)。
之后再看看加了元学习的联邦学习是怎么做的,相比上个图来说,是增加了各个客户端并行处理的过程:
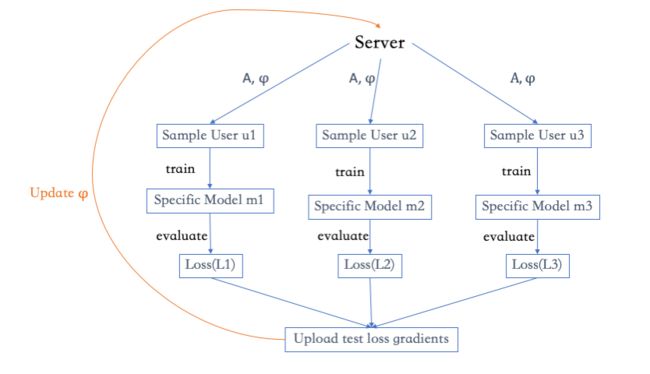
服务器先分发带有参数的算法给各个客户端,每个用户收到算法后用本地数据生成、训练并评估模型,最后,服务器从用户那里收集损失的梯度来更新算法的参数。在整个过程中,用户上传的只是算法和损失梯度,而不是模型或原始数据。
至于模型和算法有什么区别,为什么传算法就比传算法更优秀?
从理论上讲,授之以鱼不如授之以渔,传输整个模型当然不如传输生成模型的技能更优秀,这也是元学习的理念。
从论文的实验中也可以略窥一二,文章介绍了他们进行服务预测的一个实验,总共有2400种服务,由于联邦学习需要训练一个统一的模型,因此需要处理全部2400种类别,而联邦元学习是在本地训练本地使用的,因此只需要训练40个类别。同理,联邦学习的特征向量需要揉合用户特征和服务特征,因此需要11892维,而联邦元学习只需要服务特征,共103维,这样看来,是不是优秀了很多。
联邦学习应用在B端
当然C端的应用还有很多,因为现在这个领域真的很火,不过要再讲我也讲不出来了,因为我看到的文章中这两个应用方向已经足够有代表性了(其实是也并没有看那么多了)。下面,我们再看看B端的应用,在这方面,以杨强教授带领的微众银行AI团队走在最前沿,看完了他们的研究,突然细思恐极,等B端的联邦学习真正都落地,各个公司都打破信息孤岛后,我们可能真的就没有什么隐私了,莫名觉得有点有趣。
什么意思呢,微众银行对于B端FL是这样说的:
所谓“联邦学习”,顾名思义,就是搭建一个虚拟的“联邦国家”,把大大小小的“数据孤岛”联合统一进来。他们就像这个“联邦国家”里的一个州,既保持一定的独立自主(比如商业机密,用户隐私),又能在数据不共享出去的情况下,共同建模,提升AI模型效果。
本质上,它是一种加密的分布式机器学习技术,参与各方可以在不披露底层数据和底层数据的加密(混淆)形态的前提下共建模型。这也是一种共赢的机器学习方式,它打破了山头林立的数据次元壁,盘活了大大小小的“数据孤岛”,连成一片共赢的AI大陆。
什么意思呢?现在各个公司都有数据隔离性,银行有你资产状况的数据,京东淘宝有你购买记录的数据,携程途牛有你出去玩的数据,他们谁都不共享自己的数据跟其他的公司,都是各训练各的模型,是一个个“数据孤岛”。B端的联邦学习就是要把这些公司联合起来,在不暴露数据的情况共同建模,最后打通你生活的方方面面,比如根据你的购买力推荐商品,根据你的出行情况推荐分期等等。至于是不是共赢呢,对于各个公司来说看起来是的,但对于用户来说也是这样的么?就仁者见仁智者见智了。
回到技术上,微众对于B端的FL也分了几种类别来研究:
第一种,横向联邦学习,A与B的数据集有些特征重叠,但样本不同,重点解决样本缺的问题。比如工行和建行的数据,特征都差不多,但样本不同。
第二种,纵向联邦学习,A与B的数据集有些样本重叠,但特征不同,重点解决特征缺的问题。比如你携程的数据和你滴滴的数据,样本都是你,但特征肯定不同。
第三种,联邦迁移学习,A与B的数据集样本也不同,特征也不同,这个就是对模型更高的追求了。比如国内滴滴的数据和国外google的数据,他们特征也不同,样本也不同。
那么,类分好了,参照谷歌的联邦学习步骤,对于这三类也总结了不同的训练方式,由于联邦迁移学习我还没学懂,就不介绍啦。在介绍的时候,我会一并介绍横向和纵向FL的激励机制,也是我之前很关心的问题,当各个公司贡献量不均时,如何合理评估他们的贡献。方法来源于微众的下面这篇文章:

B端:横向联邦学习
刚刚说了,横向联邦学习是解决样本缺的问题,当各个公司一起参加训练,贡献样本后,训练就这样展开:
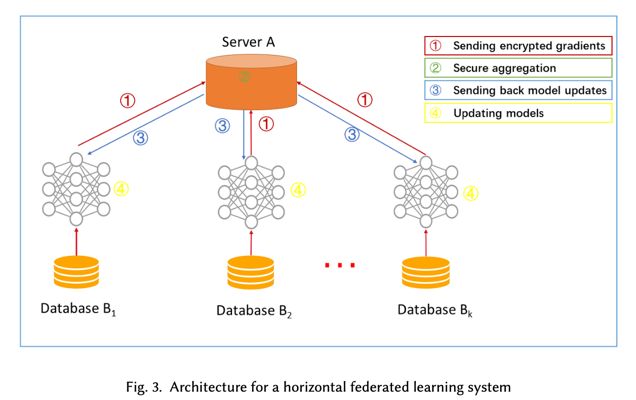
第一步:参与方用本地数据计算,训练梯度,使用加密,差分隐私(differntial privacy, DP)或秘密共享技术掩盖梯度,并将掩蔽的结果发送到服务器;
第二步:中心服务器执行安全聚合,而无需学习有关任何参与者的信息;
第三步:中心服务器向参与者下发聚合结果;
第四步:参与者解密梯度,更新各自的模型。
不断迭代上述过程直至损失收敛,所有参与者共享最终模型参数。
由于各个参与方贡献的是数据的样本,因此对参与方贡献评估的思路就是看看它提供的样本对于训练有没有用,采用的方法是——删除法。
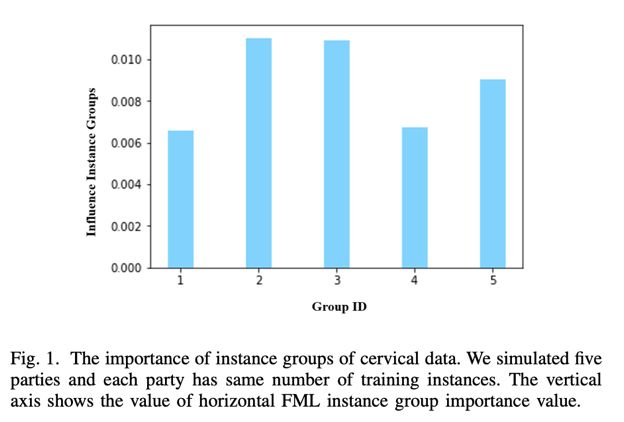
每次删掉一个参与方提供的样本,重新训练模型,计算删前删后两个模型预测能力的变化,记为影响度(Infuence Measure),用该指标衡量各个参与方的贡献。像这样:
道理很浅显易懂,但是评估过程的开销应该不小吧。
B端:纵向联邦学习
比起横向来说,纵向复杂一些,是特征层面的共享,以A和B的合作为例,为了保证A和B的数据的隐私性,我们需要引入一个具有公信力的第三方C,训练过程是这样的:
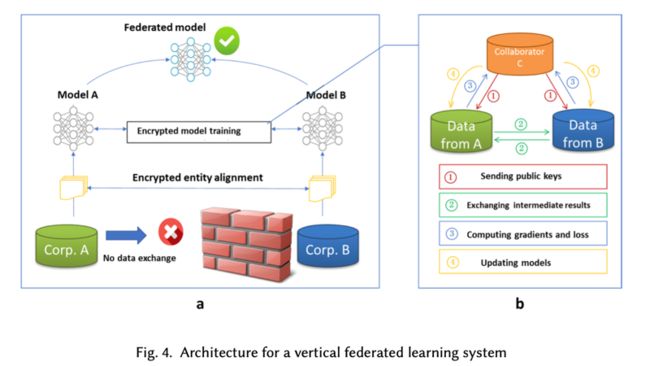
首先需要进行的是加密样本对齐,利用基于加密的用户样本对齐技术,找到A和B的共有样本。之后开始迭代:
第一步:C创建加密对,将公钥发送给A和B,用来对训练过程中需要交换的数据进行加密;
第二步:A和B以加密的形式交换用于计算梯度的中间结果;
第三步:A和B分别基于加密的中间结果计算梯度和损失,向C发送加密的值,C汇总计算总梯度,并将其解密。
第四步:C将解密的梯度和损失发送回A和B,A和B更新相应的模型参数。
在这里,微众用的是同态加密的方式来加密传输的数据。说到同态加密,知乎里的高赞回答说的很形象生动,有兴趣的宝宝可以看一下。
同态加密方案最有趣的地方在于,其关注的是数据处理安全。同态加密提供了一种对加密数据进行处理的功能。也就是说,其他人可以对加密数据进行处理,但是处理过程不会泄露任何原始内容。同时,拥有密钥的用户对处理过的数据进行解密后,得到的正好是处理后的结果。
同态加密的实现原理是什么?在实际中有何应用?
简单来说,就是我加密传给你我的数据给你处理,你虽然处理的是密文,但结果传给我,我解码后拿到的结果,跟你直接处理明文后给我的结果是相同的。这样特性的函数就能满足我们的要求。
对于纵向联邦学习的贡献评估是同样的思路,评估你贡献的特征到底值不值钱,这里用到了一个新的指标——Shapley值,它可以计算特征的重要性。
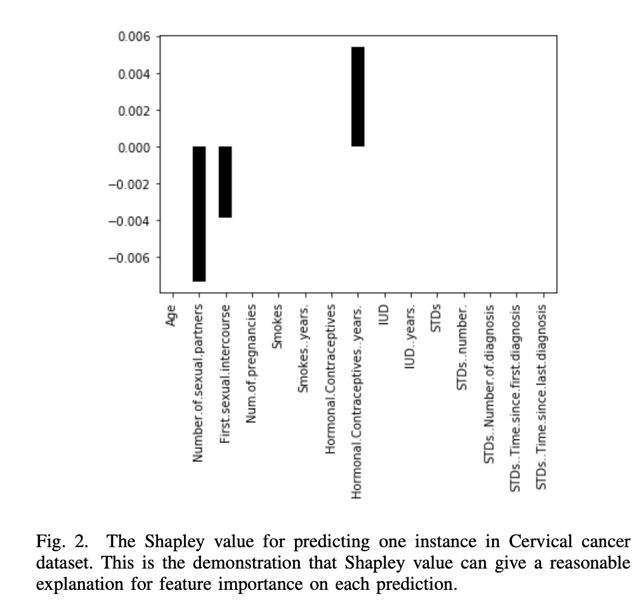
在测试中,每次打包一个组织的所有特征作为一个联合特征,其他特征作为单独特征,一起参与评分,分越高表明贡献越大。像这样:
当然,之后学者就开始研究如何不带C一起玩,只有A和B如何完成这个过程,这篇论文引入区块链的方式来做,就不具体介绍了。
怎么样,看了B端联邦学习的思路,是不是觉得我们的生活即将不再是一个孤岛,当各个公司一起联合训练时,我们的本地数据共享不共享,真的还是保护我们隐私的核心问题么?但与此同时,我们即将面对一个更便利更精准的生活环境,目前微众已经推出了一些应用,有兴趣的可以了解一下。
一些细节
最后,介绍几个我读论文时的一些细节问题,有助于更好的理解整个体系:
1) 什么是非IID数据?
在读论文时,经常可以看到说联邦学习面对的数据是non-IID,对此专门学习了一下,其实很简单,缩写很唬人,展开就是non idependently and identically distributed data,也就是数据不遵循独立同分布。
现有的机器学习任务默认训练数据遵循独立同分布,神经网络、深度学习等常见算法一般都将数据遵循IID的假设作为其推导的一部分。但在联邦学习中,各个设备上的数据是由设备/用户独立产生的,不同设备/用户的非同源数据具有不同的分布特征,任何特定用户的本地数据集都不能代表总体分布。因此研究提升Non-IID数据的学习效率,对于联邦学习具有重要意义。
2) 联邦学习与分布式学习有什么不同?
分布式学习,参数服务器将数据存储在分布式工作节点上,通过中央调度节点分配数据和计算资源。一切都由中央节点控制,工作节点没有决策权。但是对于联合学习,工作节点代表数据所有者。它具有本地数据的完全自治权,并且可以决定何时以及如何加入联合学习。
3) 联邦学习的激励机制?
刚刚说了两种联邦学习如何评估参与方贡献,微众在这个基础上提到可以用区块链技术建立一个让参与各方都满意的一个共识机制来记录大家的贡献,以此奖励对联盟有作用的机构。具体的实现还不是很清楚,期待之后的论文。
如果看到这里你还在,那么我真的很感动了,说明你对于新技术有极大的热情,当然也说明我写的形象生动。希望我的介绍能让你对联邦学习有一个大概的了解,如果你有什么新的想法,欢迎一起探讨。