Oracle的安装:
我们就用虚拟机来模拟服务器来安装oracle数据库吧。
虚拟机选择vmware 随便挑选一个版本下载,网上有很多密钥直接输入进去就注册成功了。接着下载一个操作系统,链接: https://pan.baidu.com/s/1r-dYtkU0DCZ8b7dG1MC1mw 提取码: d4yn
这个是vmware的复制版本 ,直接在vmware打开windows系统就安装成功了。这个是windowsxp系统,直接用vmware打开就可以了,不需要安装,非常省事!
vmware虚拟机的网络配置:
这个步骤非常重要!要让虚拟机的操作系统能上网,主机和虚拟机还能通信(也就是相互能ping通)!
点击“编辑” - 选择 “虚拟网络编辑器”
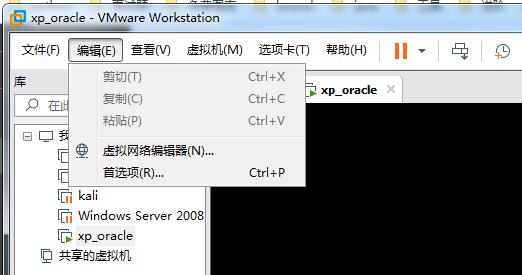
然后在弹出的界面选择VMnet1网络,然后还原默认设置。最后确认。

接着点击“虚拟机” - “设置”
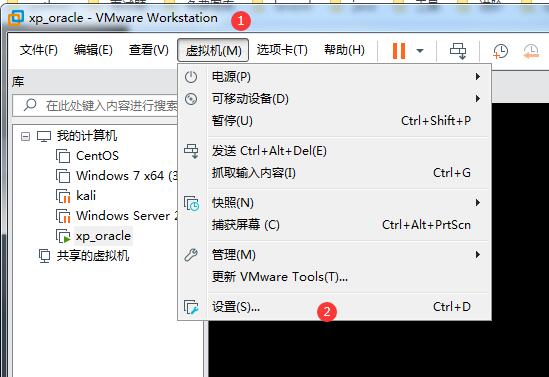
按下面步骤选择,最后确定。这样虚拟机和主机就可以互ping通了,虚拟机也可以上网了。

启动虚拟机操作系统。我们来安装oracle数据库。
准备下载oracle数据库
链接: https://pan.baidu.com/s/1WmPFs2fvwnkS1mLi8LuoAA 提取码: mnmn
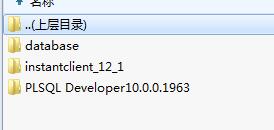
这个包里面三个文件夹,database就是orcale的数据库,其他两个都是连接数据库的客户端软件。
怎么把下载的database放到虚拟机中呢?
直接搞一个共享文件夹,然后在虚拟机的操作系统中的网络里面添加一个网络就可以看见这个共享文件夹了。
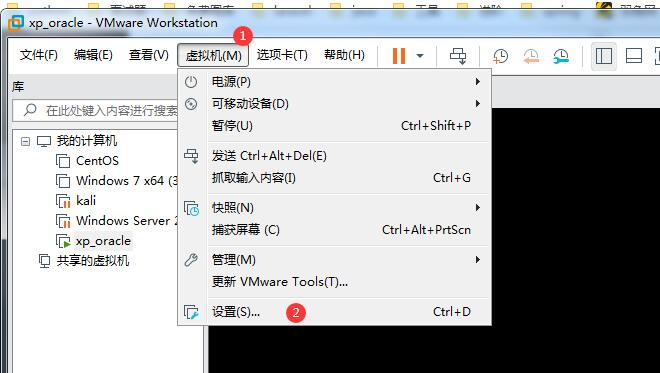
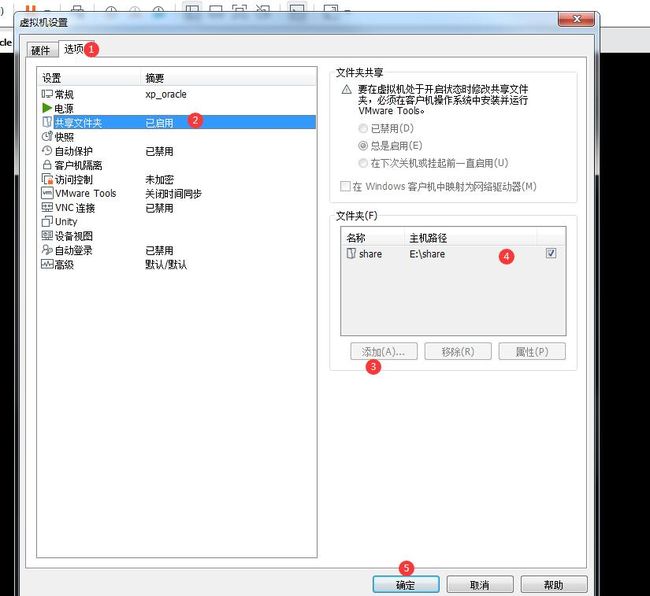
按下面的步骤来搞!





这样虚拟机就可以访问刚才下载到主机的database文件夹了。
其实你也可以不用虚拟机安装,直接安装在本机上。就省掉了以上步骤!!!
正式安装oracle


输入口令和确认口令,这个是 注:此口令即是管理员密码。
检查先决条件,选中红框所示的选择框,如下图:

点击“下一步”,出现“概要”界面,点击“安装”。
出现安装进度条,等待安装完成,如下图:

安装完成后,自动运行配置向导,如下图,等待其完成:
完成后,出现“口令管理”界面,点击“口令管理”,如下图:
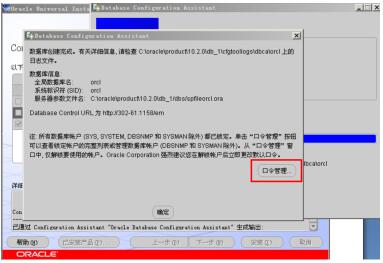
将 SCOTT 和 HR用户的沟去掉(解锁这两个账户,是为了我们之后方便测试,这两个账号下面有一些测试表),如下图所示,点击“确定”:
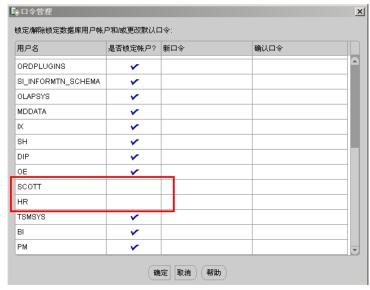
回到“口令管理”界面,点击“确定”,如下图:

自此oracle的安装就结束了。
配置一下oracle
C:\oracle\product\10.2.0\db_1\NETWORK\ADMIN 这个文件夹下面有两个配置文件需要修改一下,我安装到虚拟机C盘的所以是这个路径,你自己安装在哪里的,按这个思路去找
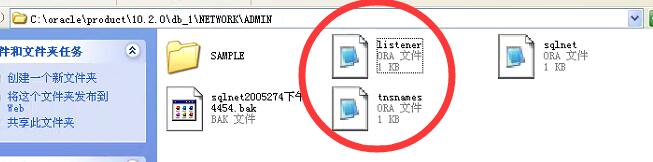
一个listener 是配置监听的。另一个tnsnames.ora文件就是客户端链接服务端要用到的配置文件( 主要等一会儿PL/sql软件要用到这个配置文件,需要把它复制到你的本地)
把这两个文件下的IP换成虚拟机的IP地址。
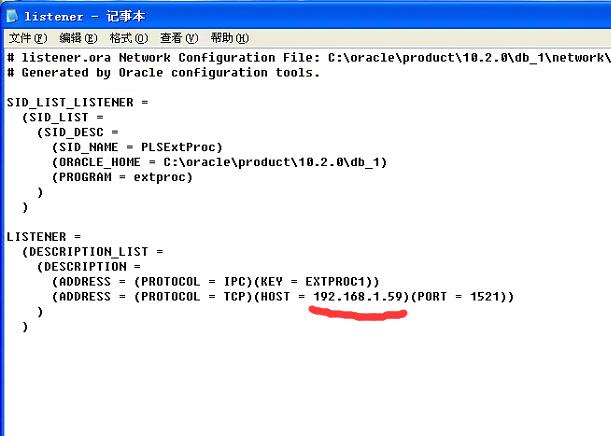
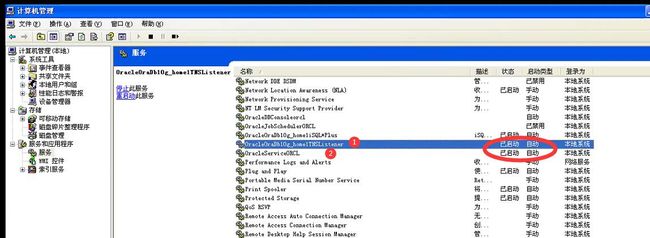
在服务 管理里面把这两个服务设置成自动启动并开启这两个服务。
oracle安装完成之后,其实他也一起安装一个sqlplus在你的系统里面,这个是一个命令行的客户端。我们打开cmd来测试一下oracle是否安装成功!
输入sqlplus 回车
然后输入用户名 system
密码:root (这个就是安装过程让你输入口令的)出现下面界面就说明你安装成功了!

在本机上安装PLSQL Developer 客户端软件
PLSQL Developer这个软件是一个带UI界面的oracle数据库管理工具。依赖于instantclient这个软件。这个软件就安装在你本地上就可以了。
傻瓜式安装即可,不建议汉化, 最后会提示输入序列号(破解) ,打开plsql-sn.txt复制序列号,输入即可。重要提示:不要把plsql developer 安装在有括号的目录下,否则会出现连不上数据库的情况,安装目录也不要出现中文。

安装完之后,直接打开,然后选择取消,为什么取消呢是为了设置一下instantclient这个软件的路径。刚才不是说了这个plsql软件是依赖于instantclient软件的,所以需要配置一下才能使用。

点击Tools -> preferences

配置连接数据库的快捷方式(当然你也可以不用弄,直接在database那个输入框那里直接输入IP地址:端口号/tablespace)
在虚拟机中把tnsnames.ora这个文件copy到本地来(随便放到哪里,算了直接放到instantclient这个文件夹下面)然后配置环境变量
值就是tnsnames.ora这个文件所在的文件夹

配置完了之后呢,就重新打开PL/SQL这个软件
数据库的操作
创建表空间,c盘下面就会多一个test.dbf文件,大小是100M,如果数据装满了,他会每10M的自动扩容。这个表空间是装各种表的。这个文件的后缀名,你可以用dbf和ora,这两个后缀名没有区别。创建表空间会在物理磁盘上建立一个数据文件,作为数据库对象(用户、表、存储过程等等)的物理存储空间。
create tablespace test
datafile 'c:\test.dbf'
size 100m
autoextend on
next 10m;
你不创建表空间。oracle安装的时候就已经默认创建了一些表空间,可以通过以下sql来查看默认创建了5个人表空间,以及他们存放的路径。
select * from dba_data_files;

删除表空间。如果你直接在C盘中去直接删test.dbf这个文件是删不掉的。需要先用命令执行了才能把这个文件删除掉。
drop tablespace test;
创建用户,是为了跟这个表空间进行关联,oracle都是通过用户管理表的。以下命令就是创建一个root账户,密码也是root,默认的表空间是test。创建用户必须为其指定表空间,如果没有显性指定默认表空间,则指定为users表空间;创建用户后,可以在用户上,创建表、存储过程等等其他数据库对象。
create user root
identified by root
default tablespace test;
- 当然我们还可以把改用户的默认表空间给改了
alter user root default tablespace test2;
- 那改成我们创建的root用户是存在哪里的呢?
select * from dba_users;

我们的用户就放在users表中的。那这个users表是存放在哪个表空间的呢?
我们可以通过先查询所有的表,然后在看users表存在在那个表空间。
select * from all_tables;
-- 或者直接使用下面这一句可查看users表所属的表空间。
-- select * from all_tables where table_name='USER$';
授权用户。创建完用户,还需要给用户授权才能登陆使用才行。也就是需要给用户分配角色才能使用。Oracle 中已存在三个重要的角色:connect 角色,resource角色,dba角色。
- CONNECT 角色: --是授予最终用户的典型权利,最基本的
- ALTER SESSION --修改会话
- CREATE CLUSTER --建立聚簇
- CREATE DATABASE LINK --建立数据库链接
- CREATE SEQUENCE --建立序列
- CREATE SESSION --建立会话
- CREATE SYNONYM --建立同义词
- CREATE VIEW --建立视图
- RESOURCE 角色: --是授予开发人员的
- CREATE CLUSTER --建立聚簇
- CREATE PROCEDURE --建立过程
- CREATE SEQUENCE --建立序列
- CREATE TABLE --建表
- CREATE TRIGGER --建立触发器
- CREATE TYPE --建立类型
- DBA角色:拥有全部特权,是系统最高权限,只有 DBA才可以创建数据库结构,并且系统权限也需要DBA授出,且 DBA用户可以操作全体用户的任意基表,包括删除
grant dba to root;
-- 或者更加细致的授权
-- grant create session to 用户名 --这个是给用户赋予登录的权限。
-- grant create table to 用户名 --给用户赋予表操作的权限
-- grant unlimited tablespace to 用户名 --给用户赋予表空间操作的权限
-- grant select any table to 用户名 --给该用户赋予访问任务表的权限 同理可以赋予update 和delete 的
查看当前用户的权限
select * form user_sys_privs;
oracle的数据类型
- CHAR 固定长度字符串 最大长度2000 bytes
- VARCHAR2 可变长度的字符串 最大长度4000 bytes 可做索引的最大长度749
- NCHAR 根据字符集而定的固定长度字符串 最大长度2000 bytes
- NVARCHAR2 根据字符集而定的可变长度字符串 最大长度4000 bytes
- DATE 日期(日-月-年) DD-MM-YY(HH-MI-SS) 经过严格测试,无千虫问题
- LONG 超长字符串 最大长度2G(231-1) 足够存储大部头著作
- RAW 固定长度的二进制数据 最大长度2000 bytes 可存放多媒体图象声音等
- LONG RAW 可变长度的二进制数据 最大长度2G 同上
- BLOB 二进制数据 最大长度4G
- CLOB 字符数据 最大长度4G
- NCLOB 根据字符集而定的字符数据 最大长度4G
- BFILE 存放在数据库外的二进制数据 最大长度4G
- ROWID 数据表中记录的唯一行号 10 bytes ********.****.****格式,*为0或1
- NROWID 二进制数据表中记录的唯一行号 最大长度4000 bytes
- NUMBER(P,S) 数字类型 P为总位数,S为小数位数
- DECIMAL(P,S) 数字类型 P为总位数,S为小数位数
- INTEGER 整数类型 小的整数
- FLOAT 浮点数类型 NUMBER(38),双精度
- REAL 实数类型 NUMBER(63),精度更高
表
创建表
create table person(
pid number(11) primary key,
name char(24) not null,
phone number(11) unique,
class_name varchar(10),
bitrhday date
);
删除表
drop table person;
新增一列,修改一列,重名一列
alter table person add(addresss varchar(10) default '');
alter table person modify(addresss varchar(20) not null);
alter table person rename column addresss to address;
查询表的字段
select * from user_tab_columns where table_name=upper('person');
新增、修改、删除
insert into person (pid,name,phone,class_name,birthday,address) values
(1,'热巴',13666666666,'演员',to_date('1992-05-01','yyyy-MM-dd'),'北京市');
update person set class_name='演戏' where pid=1;
delete from person where pid=1;
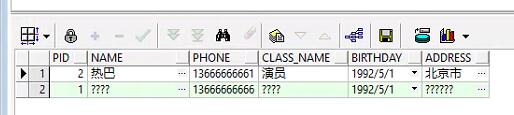
select * from person;
这里出现了一个坑:查询出来居然中文是一对问号。这里是由于服务器的数据库字符集与客户端的字符集不一致导致的乱码。
先查询服务器的字符集,是这个SIMPLIFIED CHINESE_CHINA.ZHS16GBK
select userenv('language') from dual;
再查询本地的字符集是SIMPLIFIED CHINESE
select * from V$NLS_PARAMETERS;
所以需要修改成一致的,我们就修改本地的字符集吧,设置环境变量NLS_LANGUAGE为SIMPLIFIED CHINESE_CHINA.ZHS16GBK
然后重新插入一条记录,重新查询出来中文就对啦!!!
序列
在实际项目中每一张表会配一个序列,但是表和序列是没有必然的联系的,一个序列被哪
一张表使用都可以,但是我们一般都是一张表用一个序列。
在很多数据库中都存在一个自动增长的列,如果现在要想在 oracle 中完成自动增长的功能,则只能依靠序列完成,所有的自动增长操作,需要用户手工完成处理。
范例:创建一个 seqpersonid的序列,验证自动增长的操作CREATE SEQUENCE testid;
序列创建完成之后,所有的自动增长应该由用户自己处理,所以在序列中提供了以下的两种操作:
nextval :取得序列的下一个内容
currval :取得序列的当前内容
select testid.nextval from dual;
select testid.currval from dual;
在插入数据时需要自增的主键中可以这样使用
insert into person (pid,name,phone,class_name,birthday,address) values
(testid.nextval,'热巴',13666666662,'演员',to_date('1992-05-01','yyyy-MM-dd'),'北京市');
使用scott用户做一些复制的操作(这个账号下有一些测试表和数据,scott账户的默认密码是tiger)

单行函数和数值函数
- upper:搞成大写
- lower:搞成小写
- initcap:首字母大写
- concat:字符串连接
- substr:字符串截取 substr(string string, int a, int b); a为要截取的开始位置,b为要截取的长度
- TRANSLATE(char, from, to) : 返回将出现在from中的每个字符替换为to中的相应字符以后的字符串。若from比to字符串长,那么在from中比to中多出的字符将会被删除。三个参数中有一个是空,返回值也将是空值。
- select translate('abcdefga','abc','wo') 返回值 from dual;
分析:该语句要将'abcdefga'中的'abc'转换为'wo',由于'abc'中'a'对应'wo'中的'w', 故将'abcdefga'中的'a'全部转换成'w'; 而'abc'中'b'对应'wo'中的'o', 故将'abcdefga'中的'b'全部转换成'o'; 'abc'中的'c'在'wo'中没有与之对应的字符, 故将'abcdefga'中的'c'全部删除; 简单说来,就是将from中的字符转换为to中与之位置对应的字符,若to中找不到与之对应的字符,返回值中的该字符将会被删除。在实际的业务中,可以用来删除一些异常数据,比如表a中的一个字段t_no表示电话号码,而电话号码本身应该是一个由数字组成的字符串,为了删除那些含有非数字的异常数据,就用到了translate函数
- select translate('abcdefga','abc','wo') 返回值 from dual;
- replace(char, search_string,replacement_string):将char中的字符串search_string全部转换为字符串replacement_string。
- lengthb(string)计算string所占的字节长度:返回字符串的长度,单位是字节
- length(string)计算string所占的字符长度:返回字符串的长度,单位是字符
对于单字节字符,LENGTHB和LENGTH是一样的。如可以用length(‘string’)=lengthb(‘string’)判断字符串是否含有中文。
注:一个汉字在Oracle数据库里占多少字节跟数据库的字符集有关,UTF8时,长度为三。 - round():默认情况下 ROUND 四舍五入取整,可以自己指定保留的位数。
- trunc(number,decimals) number:指需要截取的数字。TRUNC函数还可以截取数字和日期类型
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual; --显示当前时间
select trunc(sysdate,'year') from dual; --截取到年(本年的第一天)
select trunc(sysdate,'q') from dual; --截取到季度(本季度的第一天)
select trunc(sysdate,'month') from dual; --截取到月(本月的第一天)
select trunc(sysdate,'') from dual; --为空
select trunc(sysdate) from dual; --截取到日(今天)
select to_char(trunc(sysdate),'yyyy-mm-dd hh24:mi:ss') from dual; --默认截取到日(当日的零点零分零秒)
select trunc(sysdate,'day') from dual; --截取到周(本周第一天,即上周日)
select trunc(sysdate,'iw') from dual; --本周第2天,即本周一
select to_char(trunc(sysdate,'dd'),'yyyy-mm-dd hh24:mi:ss') from dual; --截取到日(当日的零点零分零秒)
select trunc(sysdate,'hh24') from dual; --截取到小时(当前小时,零分零秒)
select trunc(sysdate,'mi') from dual; --截取到分(当前分,零秒)
select trunc(sysdate,'ss') from dual ;--报错,没有精确到秒的格式
select trunc(122.555) from dual t; --默认取整
select trunc(122.555,2) from dual t;
select trunc(122.555,-2) from dual t;--负数表示从小数点左边开始截取2位
- mod(11, 2) :取余函数 11除以2的余数
- nvl(字段,默认值) : 如果字段为null,则为默认值
日期函数
- 日期 – 数字 = 日期
- 日期 + 数字 = 日期
- 日期 – 日期 = 数字
范例:查询雇员的进入公司的周数。分析:查询雇员进入公司的天数(sysdate – 入职日期)/7就是周数
select ename,(round(sysdate-hiredate)/7) from emp;
查询所有雇员进入公司的月数。分析:获得两个时间段中的月数:MONTHS_BETWEEN()
select ename,round(months_between(sysdate,hiredate)) from emp;
查询所有的雇员将将年月日分开,此时可以使用TO_CHAR 函数来拆分
拆分时需要使用通配符
- 年:y, 年是四位使用 yyyy
- 月:m, 月是两位使用 mm 一位数字的时候会前面用零填充,我们可以使用fm关键词去掉前面的零
- 日:d, 日是两位使用 dd 一位数字的时候会前面用零填充,我们可以使用fm关键词去掉前面的零
select ename,to_char(hiredate,'yyyy')年,to_char(hiredate,'MM')月,to_char(hiredate,'dd')日 from emp;
select ename,to_char(hiredate,'yyyy')年,to_char(hiredate,'fmMM')月,to_char(hiredate,'fmdd')日 from emp;
查询所有的雇员的年薪。使用nvl函数
select ename,sal,comm,sal*12+nvl(comm,0) 年薪 from emp;
查询出所有雇员的职位的中文名。使用decode函数类似于if...elseif...else。也可以使用case...when..then...when ...then...else...end
select ename,decode(job,'CLERK','业务员','SALESMAN','销售','PRESIDENT','总裁','MANAGER','经理','员工') from emp;
select t.empno,
t.ename,
case
when t.job = 'CLERK' then
'业务员'
when t.job = 'MANAGER' then
'经理'
when t.job = 'ANALYST' then
'分析员'
when t.job = 'PRESIDENT' then
'总裁'
when t.job = 'SALESMAN' then
'销售'
else
'员工'
end
from emp t
多行函数(聚合函数)
- count()
- min()
- max()
- avg()
- sum()
查询每个部门的人数
select deptno,count(ename) from emp group by deptno;
按部门分组,查询出部门名称和部门的员工数量
select d.deptno,d.dname,count(ename)
from emp e,dept d
where e.deptno = d.deptno
group by d.deptno,d.dname;
查询出部门人数大于 5 人的部门
select d.deptno,d.dname,count(ename)
from emp e,dept d
where e.deptno = d.deptno
group by d.deptno,d.dname having count(ename)>5;
查询出部门平均工资大于 2000的部门
select deptno,avg(sal) from emp group by deptno having avg(sal)>2000;
查询员工表和部门表
select * from emp,dept where emp.deptno=dept.deptno;
查询出雇员的编号,姓名,部门的编号和名称,地址
select e.ename,e.empno,e.deptno,d.dname,d.loc
from emp e ,dept d
where e.deptno=d.deptno;
查询出每个员工编号,姓名,部门名称,工资等级和他的上级领导的姓名,工资等级
select e.empno,
e.ename,
decode(s.grade,
1,'一级',
2,'二级',
3,'三级',
4,'四级',
5,'五级') grade,
d.dname,
e1.empno,
e1.ename,
decode(s1.grade,
1,'一级',
2,'二级',
3,'三级',
4,'四级',
5,'五级') grade
from emp e, emp e1, dept d, salgrade s, salgrade s1
where e.mgr = e1.empno
and e.deptno = d.deptno
and e.sal between s.losal and s.hisal
and e1.sal between s1.losal and s1.hisal
查询比 7654工资高的雇员
select * from emp t1 where t1.sal>(select sal from emp where empno=7654);
查询出比雇员 7654 的工资高,同时从事和 7788的工作一样的员工
select * from emp t1 where t1.sal>(select sal from emp where empno=7654)
and t1.job = (select job from emp where empno=7788);
查询 emp 表带有 rownum 列
select rownum, t.* from emp t
我们可以根据 rownum 来取结果集的前几行,大于5小于11
select * from (select rownum rm, a.* from (select * from emp) a where rownum < 11) b where b.rm >5;
select * from (select rownum r ,emp.* from emp) b where b.r >5 and b.r <11;
视图
视图就是提供一个查询的窗口,所有数据来自于原表。
创建视图【必须有dba权限】
create view v_emp as select ename, job from emp;
修改视图[不推荐],因为原表也会跟着一起修改
update v_emp set job='CLERK' where ename='ALLEN';
commit;
创建只读视图
create view v_emp1 as select ename, job from emp with read only;
视图的作用
-
第一点: 使用视图,可以定制用户数据,聚焦特定的数据。
解释: 在实际过程中,公司有不同角色的工作人员,我们以销售公司为例的话,采购人员,可以需要一些与其有关的数据,而与他无关的数据,对他没有任何意义,我们可以根据这一实际情况,专门为采购人员创建一个视图,以后他在查询数据时,只需select * from view_caigou 就可以啦。
-
第二点:使用视图,可以简化数据操作。
解释:我们在使用查询时,在很多时候我们要使用聚合函数,同时还要显示其它字段的信息,可能还会需要关联到其它表,这时写的语句可能
会很长,如果这个动作频繁发生的话,我们可以创建视图,这以后,我们只需要select * from view1就可以啦~,是不是很方便呀~ -
第三点:使用视图,基表中的数据就有了一定的安全性
因为视图是虚拟的,物理上是不存在的,只是存储了数据的集合,我们可以将基表中重要的字段信息,可以不通过视图给用户,视图是动态的数据的集合,数据是随着基表的更新而更新。同时,用户对视图,不可以随意的更改和删除,可以保证数据的安全性。
-
第四点:可以合并分离的数据,创建分区视图
随着社会的发展,公司的业务量的不断的扩大,一个大公司,下属都设有很多的分公司,为了管理方便,我们需要统一表的结构,定期查看各公司业务情况,而分别看各个公司的数据很不方便,没有很好的可比性,如果将这些数据合并为一个表格里,就方便多啦,这时我们就可以使用union关键字,将各分公司的数据合并为一个视图。