作者雏鹰(企业代号名),目前负责贝壳找房增长方向AB实验平台研发工作。
引言
随着贝壳找房业务的不断增长,精细化运营显得尤为重要。为了保证每一次迭代,每一个方案能够真正得到用户的认可,为贝壳带来有效的商机转化率,我们就不得不理性对待每次功能上线,反复对比找到产品方案中的不足加以改进。基于这种需要,我们推出了贝壳找房AB实验平台(Athena)(以下简称ab平台)来为大家做产品方案的优化测试,利用实验得到的转化数据为各个业务线优化产品方案提供科学的依据。
AB实验
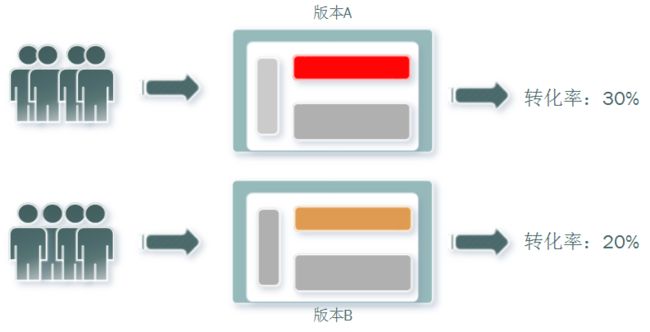
为同一个目标制定两个方案(比如两个页面),将产品的用户流量随机分割成 A/B 两组,一组实验组,一组对照组,两组实验同时运行一段时间后分别统计两组用户的表现,再将相关结果数据(比如pv/uv、商机转化率等)进行对比,就可以科学地帮助决策。比如在这个例子里,50%用户看到 A 版本页面,50%用户看到 B 版本页面,经过一段时间的观察后,统计发现A 版本用户转化率 30%,高于 B 版本的 20%,如此,我们就可以判定 A 版本胜出,然后将 A 版本页面推送给所有的用户。
通常网站会利用分域、分层、分桶的机制保证流量高可用以及分流的灵活性和科学性。这样做的原因有以下几点:
(1)AB实验大多数情况下是在一定场景下进行的,我们只需要选择对应场景的流量即可,做到流量合理划分。比如某个新功能在某个城市上线,那我们的实验流量肯定是选择这个城市的用户,比如北京用户。这里就需要按照城市维度划分单个流量域,在这个流量域内进行新功能的实验。
(2)流量是有限的,但是实验的数量是可以无限扩展的。试想如果我们在链家网选择北京这个城市后,针对北京房源列表页展示做了实验一列表展示优化实验,实验二推荐算法对比实验,还有其他实验等。如果不分层,北京用户这部分流量,实验一占了60%,实验二最多只能占到40%,再来其他实验,只能被分到更少的流量。因此会产生实验流量饥饿的问题。在做了分层之后,每层实验之间流量互不干扰,共享100%的流量,流量在每一层被重新打散分配。就可以支持更多的实验同时运行而不会导致流量饥饿的问题。
(3)实验的对照组和实验组之间是流量互斥的,因此需要分桶隔离,将流量随机分到不同的桶中。
分层实验
在整个平台介绍之前,先介绍以下AB实验平台设计的理论基础,这样可以方便大家理解后续的设计架构。业界的AB平台的设计都参考了谷歌重叠实验框架的论文:《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》,译文可以参考:http://www.flickering.cn/uncategorized/2015/01/。我们的ab平台也是参考了其分层实验模型设计而成。
分层实验模型
作为实验平台,支持同时运行大量AB实验是其基本要求。多实验并行的情况下,我们根据共享同一份流量情况下,两个实验效果是否会产生干扰,将实验之间的关系分为正交实验和互斥实验。
互斥实验:如果分层共享同一份流量就有可能出现实验效果之间相互干扰的问题,这样的实验叫互斥实验,也就是如果实验一和实验二是互斥关系,那么经过实验一的流量就不能进入到实验二。
正交实验:如果实验之间共享同一份流量实验效果之间不干扰,这样的实验我们叫正交实验,这种情况下,流经两个实验的流量是可以共享的,流经实验一的流量也可以流经实验二。
举个栗子:例如实验一是web页面背景色,实验二是文字颜色,实验一的对照实验是蓝色,实验二的对照实验也是蓝色,那么如果实验一和实验二共享同一份流量,那么这部分流量就会出现一种背景色为蓝色,文字为蓝色的情况,这样的页面是不可读的,两个实验的效果就产生了干扰,这里的实验一和实验二就是互斥实验。另假设,这里实验一不变,实验二是列表页推荐算法的优化,那么页面的背景色展示和算法优化就可以共享同一份流量,经过实验一的流量到实验二的时候被重新随机打散。实验效果之间并不会产生干扰,将这样的实验我们称之为正交实验。后文还会详细讲模型如何处理这两种实验。
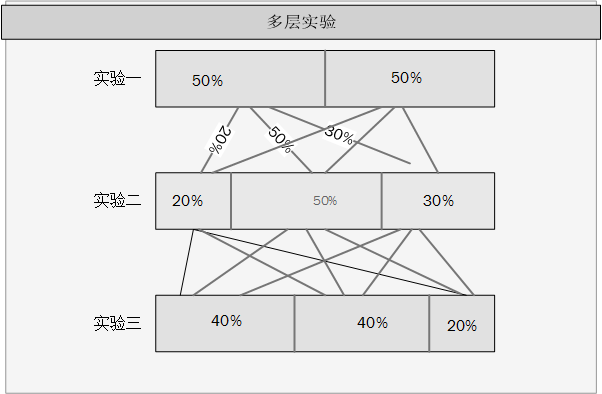
多实验并行过程中,既有正交实验,也有互斥实验并且要保证流量在实验过程中科学合理的分配。分层实验模型就提出了“层”的概念。层的原则是:同一层存在多个互斥实验,流量流经该层最多可以参与一个实验。层与层之间,流量是正交的,也就是说流量在穿越每一层实验时候,都会被再次随机打散,经过上层实验一的流量可能会经过下层的任何一个实 验,可能是实验一,也可能是实验二。如图:
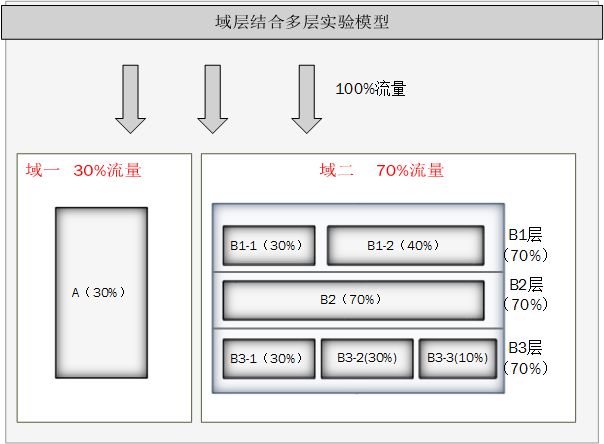
正如之前所述,在正常的实验过程中,我们一般会从总体流量中按照一定的维度去划分一个个流量区域,来做实验,比如一部分实验做在PC端,一部分做在M端。如此,就引出了另外一个概念,“域”。这里划分出的流量池就是一个域,在这个域里还可以进行分层实验,不同域之间流量隔离,所有的流量域加起来共享100%流量。如图:
通过域、层、实验之间的嵌套关系组合,就可以满足我们很多场景的实验,划分想要的流量域,运行想要的各种不同的实验类型。
流量分桶
模型有了,怎么分流也很重要,那么什么是分流呢?分流指的是是根据分流算法策略为每层的每个实验分配相应的流量,从请求角度来说,是让每个请求都能在各层都能准确稳定的命中到相应实验。分流也叫流量分桶,为什么叫流量分桶呢?那首先就得说明一下这里的桶指的是什么。
这里,每一层的每个实验的实验组和对照组就是一个桶,每层的流量一共是100,假设这一层有两个实验分别是实验一和实验二,流量配比各为50%,每个实验各有一实验组和对照组,实验组和对照组平分流量各得25%,那么这里每层实验就有4个桶。整体流量按桶划分,从0开始编号的话,可以认为,实验一组一的桶装的是024的编号,实验一组二的桶装的是2549编号,类推,实验二组二的桶装的是75~99的编号。一个流量请求在每一层中只能命中到一个实验组,也就是说只能被分到一个桶内。一般我们会选择用用户id和实验层id哈希取模(mod=f(uid, layer)%100),得到的值在哪个桶内,该请求就命中哪个实验的那个组,这样 保证了用户在每层命中的实验是随机且是稳定的。
架构与实现
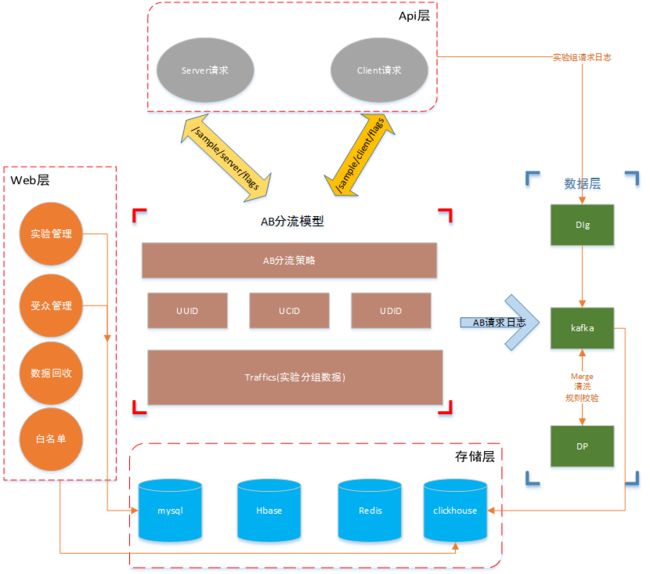
ab平台架构主要包括web层、api层、数据层、存储层,核心分流服务构成:
web层:主要提供用户界面化的操作来配置实验,创建实验受众,创建白名单,查看实验实验效果等功能,其中用户配置实验过程中最重要的一部分就是实验受众。
实验受众:指的是用于实验的流量人群。目前受众分为两种,分别是基于维度标签组合形成的AB受众和基于用户画像标签圈定的人群包受众:
AB受众:支持按照设备(ios、android)、城市、URL(比如区分贝壳pc和m站)等维度生成标签,再由标签之间组合形成各个维度的受众,比如北京安卓用户。这种受众通过解析请求的cookie信息,正则匹配标签内容判断是否应该进入对应受众。
人群包受众:因为人群包受众是通过DMP平台提供的用户画像标签(比如城市、最近的活跃度等)圈出来的人群id集合,所以也叫DMP受众,目前这部分受众的用户的id取值逻辑主要取自于设备id。通过判断用户请求信息的设备id是否包含在人群id集合中,来判断是否应该进入到该受众。
上面提到了白名单,那么白名单是什么呢?我们可以把白名单理解为一种特殊的受众,白名单中包含了人为添加的用户id。它一般应用于一个实验的某个实验组上,为这个实验组指定白名单,那么在对这个实验分流的时候,白名单的用户就忽略分流策略,直接命中配置了该白名单的实验组。白名单常用于测试情况下,指定测试人员命中实验组,方便测试。
配置实验受众、指定了实验起始和过期时间、配置实验组和对照组的流量之后,就可以开始实验了。配置好的实验如图:
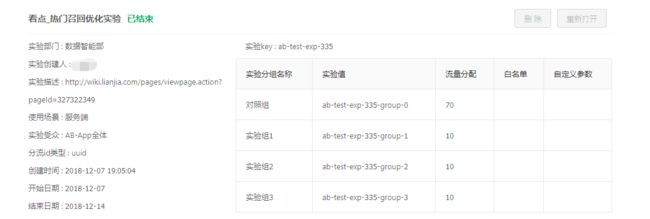
api层:提供业务方调用ab平台接口,用户请求ab平台的api时,解析请求header中的cookie信息判别受众以及获取用户id用于实验分流。根据实验场景不同,api分为客户端API和服务端API。
客户端api主要用于客户端实验比如UI等实验,API请求逻辑处理如图:

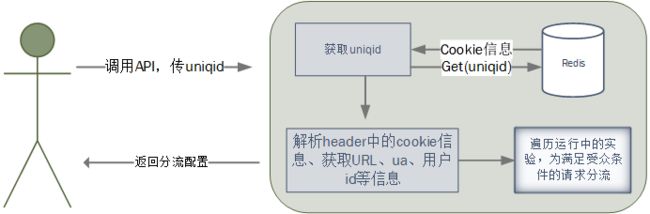
服务端API主要用于后端逻辑优化、算法策略实验对比等,由于从前端到后端实验调用处,链路可能很长,对于请求信息的传递的保存和传递显得困难。因此,我们设计了uniqId,当用户请求线上域名的时候,负载均衡层会生成一个唯一的uniqId,将用户的请求信息保存到redis,之后的请求链路中,会将uniqid传递给后端,该参数也是请求ab服务时必不可少的参数。API逻辑如图所示:
分流服务:主要提供流量划分的功能。
分流依据:ab平台利用用户id进行分流,这其中包括标记新用户或访客的lianjia_uuid、注册用户的lianjia_ucid、针对移动设备的lianjia_device_id。
分流实现:基于多层实验模型的流量分桶原理,ab平台对其做了适当的简化,以更加适合目前我们的业务需求。我们定义每层一个实验,各层之间流量正交。每个实验受众,可以理解为一个域。一个受众可以用于多个实验。
在程序设计中,我们取map集合,命名traffics,将运行中的实验加载到traffics中,traffics的key是每个实验的名字,比如exp1,traffics的值是traffic,每个traffic也是一个map结构,traffic的key是每个实验分组的名字,比如这里是group1,group2。traffic的值是每个实验组的桶内编号的集合,这里是一个set结构来存储。如图所示:

分流过程:
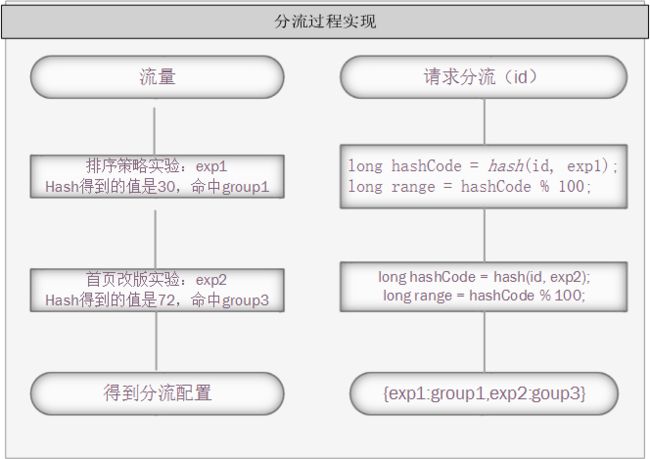
业务方通过解析得到的实验配置,控制该用户命中不同的逻辑。
数据层:将流量的实验分组信息与用户行为日志做关联,分析实验的指标数据。实验效果分析包括实时数据分析和离线数据分析,过程分别如下:
离线数据分析:流量分组日志实时写入到kafka,这部分分组数据作为离线数据一部分写入到hive表中,与存储在hive表中的用户行为数据,按照用户id做关联,关联得到的用户在各个实验方案下的行为数据写入到clickhouse中。
实时数据分析:流量分组日志实时写入到kafka,这部分分组数据作为实时数据写入到hbase中。同时,用户行为日志数据由dig埋点服务实时写入到行为日志的kafka中,spark-streaming实时任务仍然按照用户id整合kafka中的行为日志数据和存储在hbase中的流量分组数据。整合之后的数据实时写入到kafka,再由实时任务消费写入到clickhouse。如图所示:
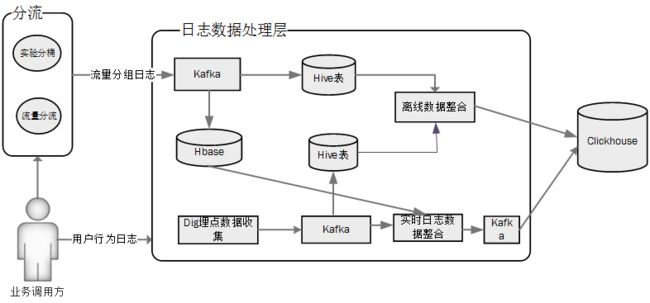
经过对存储在clickhouse中的数据通过复杂的SQL进行聚合分析,得到用户在相应实验方案下的pv、uv、转化等数据。效果如图所示:
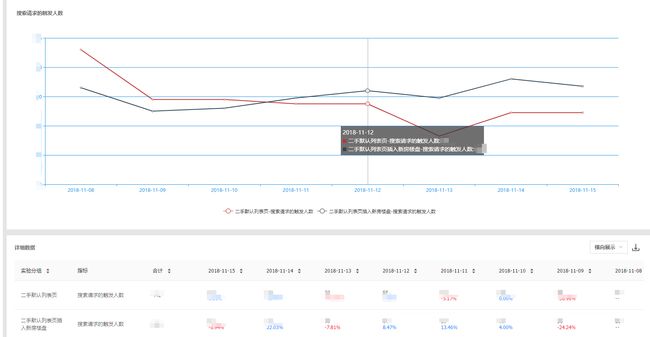

存储层:ab平台的存储层主要包括:
mysql:用于保存实验配置、白名单配置、实验受众信息。
Hbase:存储用户命中AB实验分组信息,用于实时处理的分组日志数据整合。
redis:借助其高性能的数据写入和读取特性,用于存储和用户请求分流直接相关的uniqId对应的cookie信息、白名单包含的用户id、人群包包含的用户id集合,保证请求分流能够1-2毫秒内快速高效完成。
clickHouse:这是一款能够支持十亿级日志数据秒级自定义分析的查询引擎,其高效的存储性能以及丰富的数据聚合函数成为实验效果分析的不二选择。离线和实时整合后的用户命中的实验分组对应的行为日志数据最终都导入了clickhouse,用于计算用户对应实验的一些埋点指标数据(主要包括pv、uv)。
关于clickhouse,如果有兴趣,可以了解一下我们之前发表过的clickhouse实践文章:ClickHouse Practice。
灰度发布
灰度发布:是指在黑与白之间,能够平滑过渡的一种发布方式。AB test就是一种灰度发布方式,让一部分用户继续用A,一部分用户开始用B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。(百度百科)
灰度实现思路:当某个实验效果非常好时,可以动态调整该实验的流量占比,从而迅速得到收益,并且在大流量上验证该实验的有效性。一旦确认该实验效果非常良好,便可以在全流量上线。由于目前AB仅支持Http接口调用,在某些高并发场景下,业务方希望使用SDK来避免网络IO的性能消耗,因此该功能基于SDK实现(目前只支持java程序调用)。
灰度发布SDK:
(1)拉取配置:调用方集成SDK之后,SDK会每隔一分钟拉取AB平台的所有实验分流配置到本地,保证调用方要用的配置是最新的。
(2)根据灰度发布实验的名字,获取该实验的分桶配置,也就上在分流模型中说的traffic。
(3)根据实验名字和用户id进行hash,r = HashUtil.hash(uuid, expName),获取在灰度实验中命中的实验组。
自定义参数功能:自定义参数可以为用户在不同的实验方案下指定不同的参数取值。比如灰度发布实验中,可以指定版本号为自定义参数,为不同的实验组设置不同的版本号。如此,流量命中实验组之后可以直接得到得到具体的版本号信息,方便控制版本发布。
业务支持情况
ab实验平台目前已经有多个部门接入使用,累计运行实验近百个,已支持并行运行实验40+。
实践效果
AB实验平台利用统计数据在很多场景下指导算法策略以及产品方案的优化方向。下图是算法策略部门在AB实验平台上进行进行的贝壳首页推荐策略A/B 实验。横轴是实验时间,纵轴是CTR,利用ab平台划分6个实验组,根据实验方案下的指标数据得出CTR的表现情况,为方案优化提供数字依据。
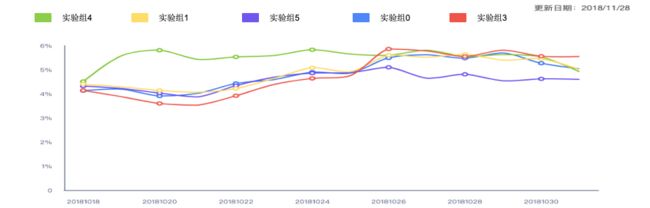
不足
虽然目前的实验平台已经具备了一部分功能,可以满足大部分实验需求。但是,我们的实验平台相比业界的很多平台还有不足。包括以下方面:
(1)实验效果解读不够直观易懂,暂时缺乏置信区间等统计数据辅助决策。
(2)基于层的实验划分支持不完善,目前只支持多层正交实验,对互斥实验支持度不够。
(3)灰度发布功能有很大的局限性,目前的方式业务代码耦合度高。
展望
首先以上的不足将是我们努力的方向,后续会不断探索优化平台。很期待大家在产品迭代方案选择上优先利用ab平台走AB测试,在项目上线前利用ab平台优先走灰度发布。希望借助于AB测试,利用灰度发布形成一套结合AB测试的开发上线流程:需求评审-建立试验方案-新功能开发-灰度发布-小流量AB测试-发布成功的功能,关闭失败的。也期待大家多提宝贵的意见与建议,以便于我们提供更好的平台服务。