一、Mycat简介
1.1 什么是Mycat
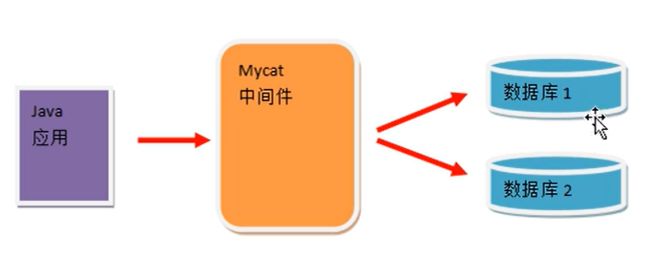
Mycat是目前最流行的基于Java语言编写的数据库中间件,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分库分表。配合数据库的主从模式还可以实现读写分离。
Mycat是基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得MyCat变得非常的强大。
Mycat发展到目前的版本,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是哪种存储方式,在MyCat里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提高开发速度。
Mycat官网
Mycat电子书籍
1.2 使用Mycat后的结构图
二、Mycat中的概念
2.1 切分
逻辑上的切分,在物理层面,是使用多库、多表来实现切分的。
2.1.1 Mycat垂直拆分
垂直分库是根据数据库里面的数据表的业务进行拆分,比如:一个数据库里面既存在用户数据,又存在订单数据,那么垂直拆分可以把用户数据放入到用户库,把订单数据放到订单库。
垂直分表是对数据表进行垂直拆分的一种方式,常见是把一个多字段的大表按常用字段和非常用字段进行拆分,每个表里面的数据记录数一般情况下是相同的,只是字段不一样,使用主键关联。
比如原始用户表是:

垂直拆分后的表是:

垂直拆分的优点是:
- 可以使得数据变小,一个数据块(block)就能存放更多的数据,在查询时就会减少I/O次数(每次查询时读取的Block就少)
- 可以达到最大化利用Cache的目的,具体在垂直拆分的时候可以将不常变的字段放一起,将经常改变的放一起
- 数据维护简单
缺点是:
- 主键出现冗余,需要管理冗余例
- 会引起表连接JOIN操作(增加CPU开销)可以通过在业务服务器上进行join来减少数据库压力
- 依然存在单表数据量过大的问题(需要水平拆分)
- 事务处理复杂
2.1.2 Mycat水平拆分
水平拆分是通过某种策略将数据分片来存储,有库内分表、分库两部分,每片数据会分散到不同的MySQL表或库,达到分布式的效果,能够支持非常大的数据量。
水平拆分表如下:
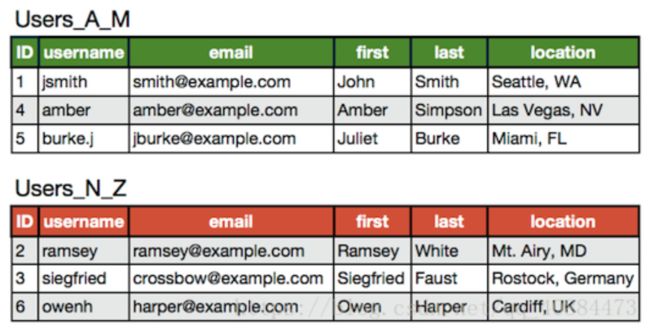
实际情况中往往会是垂直拆分和水平拆分的结合,即将Users_A_M和Users_N_Z再拆成Users和UserExtras,这样一共四张表。
水平拆分的优点是:
- 不存在单库大数据和高并发的性能瓶颈
- 应用端改造较少
- 提高了系统的稳定性和负载能力
缺点是:
- 分片事务一致性难以解决
- 跨节点Join性能差,逻辑复杂
- 数据多次扩展难度跟维护量极大
2.2 逻辑库 & 逻辑表
- 逻辑库-Schema:Mycat中定义的database是逻辑上存在的,但是物理上是不存在的。
- 逻辑表-table:Mycat中定义的table是逻辑上存在的,但是物理上是不存在的。
2.3 数据主机 & 数据节点
- 数据主机-dataHost:是物理MySQL存放的主机地址,可以使用主机名、IP、域名定义。
- 数据节点-dataNode:配置物理的database,数据保存的物理节点就是database。
2.4 分片规则
当控制数据的时候,如何访问物理database和table,就是访问dataHost和dataNode的算法。在MyCat处理具体的数据CRUD的时候,如何访问dataHost和dataNode的算法,如哈希算法、crc32算法等。
三、Mycat的使用
3.1 读写分离
原理:需要搭建主从模式,让主数据库(master)处理事务性增、改、删操作,而从数据库(slave)处理查询操作。
Mycat配合数据库本身的复制功能,可以解决读写分离的问题。
3.2 主从备份
3.2.1 主从备份概念
主从备份就是一种主备模式的数据库应用。主库数据与备库数据完全一致;实现数据的多重备份,保证数据的安全;可以在master[InnoDB]和slave[MyISAM]中使用不同的数据库引擎,实现读写的分离。
备注:InnoDB支持事物,MyISAM不支持事物,MyISAM查询效率更高。
3.2.2 MySQL5.5、5.6版本后本身支持主从备份
MySQL5.5、5.6版本后本身支持主从备份,在老旧版本的MySQL数据库系统中,不支持主从备份,需要安装额外的RPM包,如果需要安装RPM包,只能在一个位置节点安装。
3.2.3 主从备份目的
- 实现主备模式:保证数据的安全,尽量避免数据丢失的可能。
- 实现读写分离:使用不同的数据库引擎,实现读写分离,提高所有操作的效率。
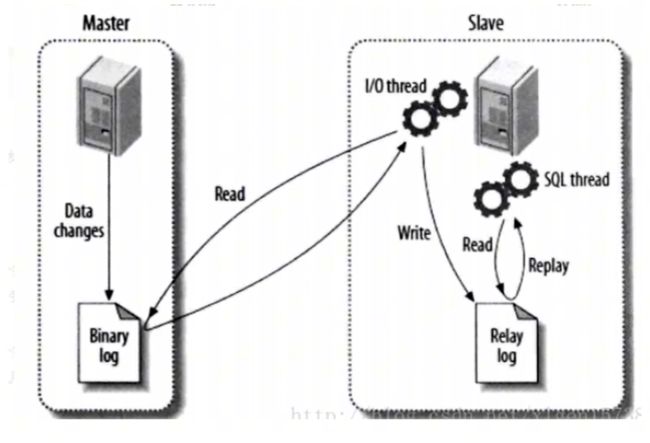
3.2.4 主从模式下的逻辑图
基于日志来实现主从数据同步
3.3 MySQL的主从模式搭建
3.3.1 安装MySQL
已安装
主库:47.115.26.11
从库:47.105.146.74
3.3.2 主从备份配置-master[主库]配置
1、修改master的配置文件
vi /etc/mysql/mysql.conf.d/mysqld.cnf
注意:该配置文件由于系统环境不同,安装方式不同,版本不同,因此目录、配置文件名也可能不相同。
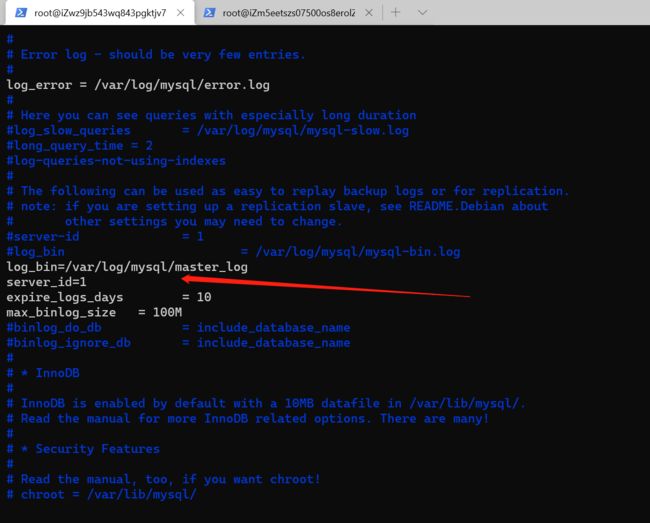
2、添加server_id
server_id是MySQL服务唯一标识,可任意配置,只要是数字即可,但master唯一标识数字必须小于slave唯一标识数字。
3、log_bin
开启日志功能以及日志文件命名,log_bin=master_log,变量的值就是日志文件名称,是日志文件名称的主体,MySQL数据库自动增加文件名后缀和文件类型。
log_bin=/var/log/mysql/master_log
server_id=1
4、重启MySQL
sudo service mysql restart
5、访问MySQL
mysql -u root -p
6、创建用户
在MySQL数据库中,为不存在的用户授权,会自动创建对应用户并授权(不需要先创建用户再授权),当前我们要创建的用户是从库访问主库使用的用户。
IP地址不能写%,因为主从备份中,当前创建的用户是给从库slave访问主库master使用的,用户必须有指定的访问地址,不能是通用地址。
grant all privileges on *.* to 'myslave'@'47.105.146.74' identified by 'myslave@123AC' with grant option;
flush privileges;
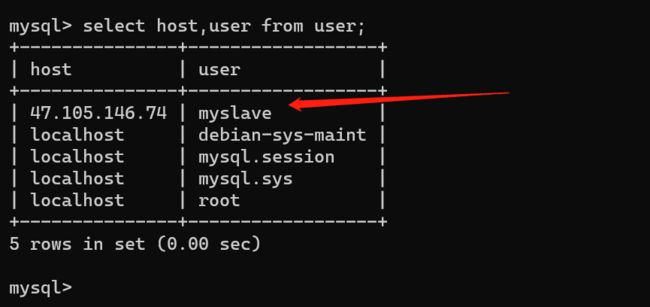
7、查看用户
use mysql;
select host,user from user;
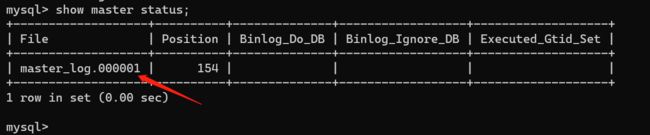
8、查看master信息
show master status;
9、关闭防火墙或在防火墙中开放3306端口
3.3.3 主从备份配置-slave[从库]配置
1、修改master的配置文件
vi /etc/mysql/mysql.conf.d/mysqld.cnf
2、添加server_id
server_id是MySQL服务唯一标识,可任意配置,只要是数字即可,但master唯一标识数字必须小于slave唯一标识数字。
server_id=2
3、重启MySQL
sudo service mysql restart
4、访问MySQL
mysql -u root -p
5、停止slave功能
stop slave;
6、配置主库信息
需要修改的数据是依据master信息修改的,IP是master所在物理机IP,用户名和密码是master提供的slave访问用户名和密码,日志文件是在master中查看的主库信息提供的,在master中使用show master status查看日志文件名称。
// 在从库中配置主库信息
change master to master_host='47.115.26.11',master_user='myslave',master_password='myslave@123AC',master_log_file='master_log.000001';
7、启动slave功能
start slave;
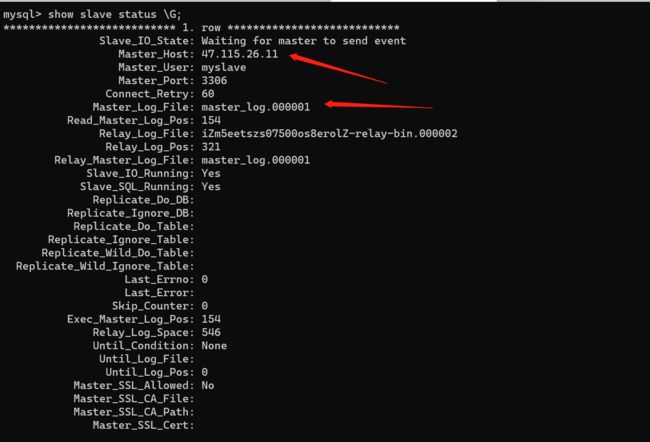
8、查看slave配置
show slave status \G;
3.4 测试主从数据同步
1、在主库中创建数据
create database master_slave_test_db character set utf8mb4;
2、查看主库中的数据库
show databases;

可以查看到到刚才创建的master_slave_test_db 数据库
3、查看从库中的数据库
show databases;
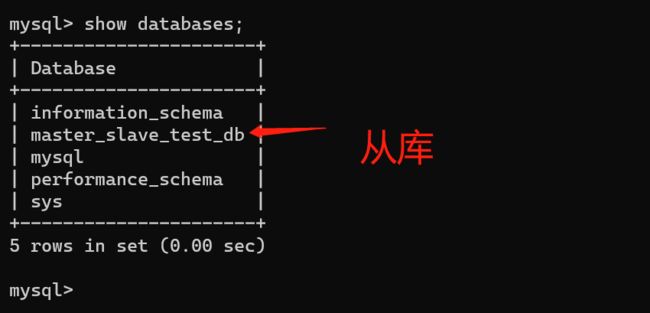
可以查看到到刚才在主库中创建的master_slave_test_db 数据库,说明从库已经同步到主库信息了。
注意:如果发现从库没有同步到主库的信息,检查一下master_log_file的文件名配置的是否正确并检查slave配置信息是否有异常。
//检查master_log_file的文件名配置的是否正确
// 1、在主库中执行
show master status;
// 2、在从库中执行
show slave status \G;
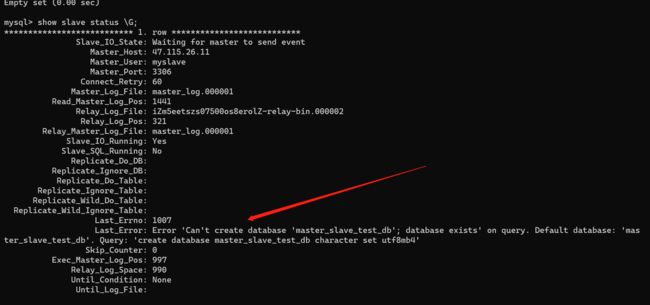
重点:根据异常信息对数据库进行了处理后(如补充从库中的数据表、字段等),需要停止slave,重新配置主库信息,再启动slave,否则会一直同步失败。
4、在主库中创建数据表并查看
use master_slave_test_db;
create table t_user(id int,name varchar(45));
show tables;
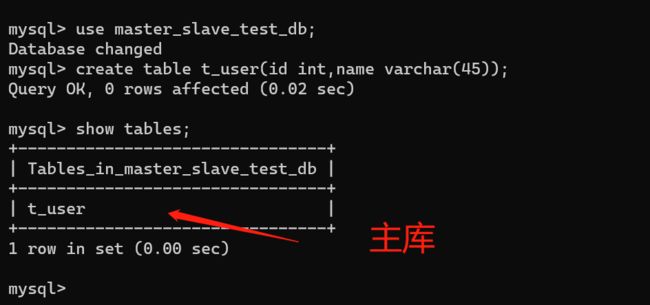
5、查看从库中的数据表
use master_slave_test_db;
show tables;

四、安装Mycat
4.1 安装并配置JDK
省略
4.2 在主库和从库上都需要处理
1、开放3306端口
2、保证root用户可以被Mycat访问
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
4.3 解压上传的Mycat压缩包
MyCat我将安装到39.108.250.186这台机器上
scp D:/temp/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz [email protected]:/data/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
4.4 解压
tar -zxf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
4.5 注意事项
1、将Mycat下载到本地后,在windows 10上,如果设置了隐藏后缀名,文件名不会显示后缀.gz,因此上传到远程服务器时,要把文件名.gz加上。
2、将Mycat下载到本地后,不能先用解压工具解压,再压缩成.zip文件再上传到服务器,这样传到服务器,再解压是无法运行Mycat的
4.5 Mycat目录介绍
- bin目录里是启动脚本
- conf目录里是配置文件
- catlet为MyCat的一个扩展功能
- lib目录里是MyCat和它的依赖jar
- logs目录里是console.log用来保存控制日志,mycatlog用来保存mycat的log4j日志
五、Mycat配置文件
MyCat的架构其实很好理解,Mycat是代理,Mycat后面就是物理数据库,和Web服务器的Nginx类似。对于使用者来说,访问的都是Mycat,不会接触到后端的数据库,我们现在做一个主从、读写分离,结构如下图
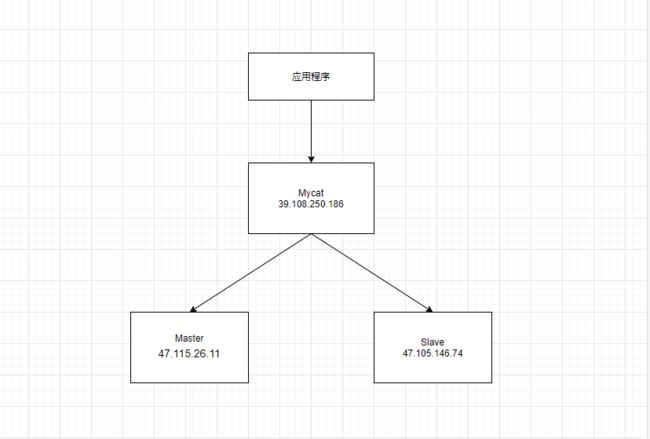
Mycat的配置文件都在conf目录里面,这里介绍几个常用的文件
- server.xml :Mycat的配置文件,设置账号、参数等;
- schema.xml:Mycat对应的物理数据库和数据库表的配置;
- rule.xml:Mycat分片(分库分表)规则;
5.1 server.xml
5.1.1 server.xml 内容
省略……
123456
TESTDB
user
TESTDB
true
省略……
如Mycat中的用户,用户可以访问的逻辑库,可以访问的逻辑表,服务端口号等
- user:用户配置节点;
- name:登录的用户名,也就是连接Mycat的用户名;
- password:登录的密码,也就是连接Mycat的密码;
- schemas:逻辑库名,这里会和schema.xml中的配置关联,多个用逗号分开,例如需要这个用户管理两个数据库db1,db2,则配置db1,db2
- privileges:配置用户针对表的增删改查的权限;
Mycat的server.xml配置文件默认配置了一个账号root,密码是123456,数据库是TESTDB,读写权限都有,没有针对表做任何特殊的权限。
5.1.2 配置权限
dml权限顺序为:insert(新增)、update(修改)、select(查询)、delete(删除),0000~1111,0为禁止权限,1为开启权限。
5.2 schema.xml
5.2.1 schema.xml内容
schema.xml是最主要的配置文件,首先看默认的配置文件
select user()
在配置文件中可以定义读写分离,逻辑库,逻辑表,dataHost,dataNode等信息。
- schema:配置逻辑库,name与server.xml中schema对应;
- dataNode:定义数据节点的标签,也就是分库相关配置;
- dataHost:物理数据库,真正存储数据的数据库;
5.2.2 节点与属性介绍
5.2.2.1 标签schema
配置逻辑库的标签
1、属性name
逻辑库名称
2、属性checkSQLshema
是否检测SQL语法中的schema信息,如:Mycat逻辑库名称A,dataNode名称B;
SQL:select * from A.table;
checkSQLshema值是true,Mycat发送到数据库的SQL是:select * from table;
checkSQLshema值是false,Mycat发送到数据库的SQL是:select * from A.table;
3、属性sqlMaxLimit
Mycat在执行SQL的时候,如果SQL语句中没有limit子句,自动增加limit子句,避免一次性得到过多的数据,影响效率,limit子句的限制数量默认配置为100,如果SQL中有具体的limit子句,当前属性失效。
5.2.2.2 标签table
定义逻辑表的标签
1、属性name
逻辑表名
2、属性dataNode
数据节点名称,即物理数据库中的database名称,多个名称使用逗号分隔。
3、属性rule
分片规则名称,具体的规则名称参考rule.xml配置文件。
5.2.2.3 标签dataNode
定义数据节点的标签
1、属性name
数据节点名称,是定义的逻辑名称,对应具体的物理数据库database
2、属性dataHost
引用dataHost标签的name值,代表使用的物理数据库所在位置和配置信息
3、属性database
在dataHost物理机中,具体的物理数据库database名称
5.2.2.4 标签dataHost
定义数据主机的标签
1、属性name
定义逻辑上的数据主机名称
2、属性maxCon/minCon
最大连接数,max connections
最小连接数,min connections
3、属性dbType
数据库类型:mysql数据库
4、属性dbDriver
数据库驱动类型,native,使用mycat提供的本地驱动。
5.3 rule.xml
5.3.1 rule.xml内容
id
func1
user_id
func1
sharding_id
hash-int
id
rang-long
id
mod-long
id
murmur
id
crc32slot
create_time
partbymonth
calldate
latestMonth
id
rang-mod
id
jump-consistent-hash
0
2
160
2
partition-hash-int.txt
autopartition-long.txt
3
8
128
24
yyyy-MM-dd
2015-01-01
partition-range-mod.txt
3
rule.xml是用于定义分片规则的配置文件,Mycat默认的分片规则是auto-sharding-long:以500万为单位实现分片规则。逻辑库A对应dataNode-db1和db2,1500万保存在db1中,500万零11000万保存在db2中,1000万零1~1500万保存在db1中,以此类推。
六、实现读写分离
6.1 配置读写分离
6.1.1 schema.xml配置
select user()
6.1.2 balance
- 0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上;
- 1:全部的readHost与stand by writeHost参与select 语句的负载均衡;
- 2:所有读操作都随机的在writeHost、readHost上分发;
- 3:所有读请求随机的分发到writeHost对应的readHost上执行,writeHost不负担读压力;
6.1.3 server.xml配置(部分)
123456
mysql_master_slave_db
user
mysql_master_slave_db
true
6.2 Mycat命令
// 启动
bin/mycat start
//停止
bin/mycat stop
//重启
bin/mycat restart
//查看状态
bin/mycat status
6.3 访问Mycat方式
可以使用命令行访问或客户端软件访问,和连接MySQL一样,Mycat的端口是8066,管理端口默认为9066。
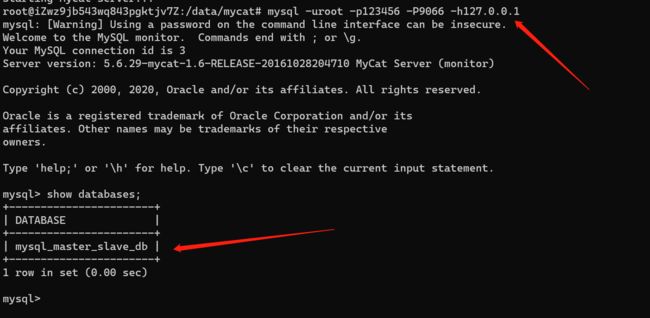
1、用命令行访问
mysql -uroot -p123456 -P9066 -h127.0.0.1
2、用客户端软件访问
我用MySQL Workbench连接Mycat,一直提示密码错误,后来换成用Navicat去连Mycat就连成功了,估计是MySQL Workbench连接Mycat有问题。
用Navicat连接Mycat成功
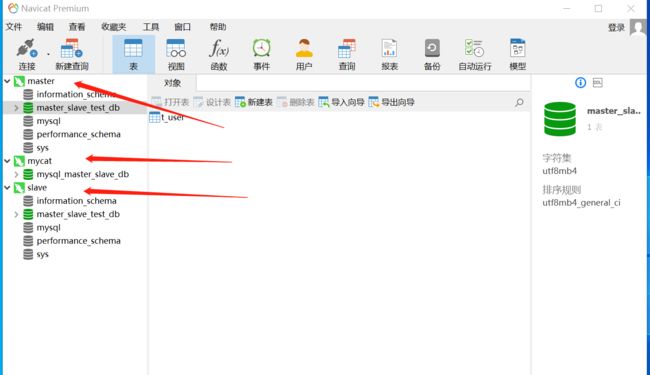
同时也用Navicat连接主库(master)和从库(slave)
6.4 查看Mycat日志
logs/wrapper.log日志中记录的是所有Mycat操作,查看的时候主要看异常信息caused by信息
6.5 测试读写分离
6.5.1 操作mycat插入数据
我们连接mycat,并在mysql_master_slave_db数据库的t_user表中插入两条数据
insert into t_user(id,name) values(1,'张三');
insert into t_user(id,name) values(2,'李四');
select * from t_user;
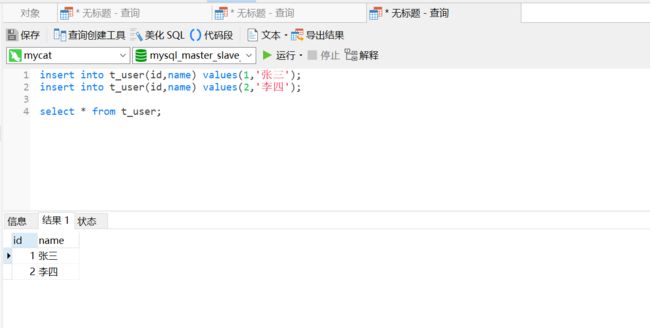
6.5.2 操作master、slave查看数据
master

slave
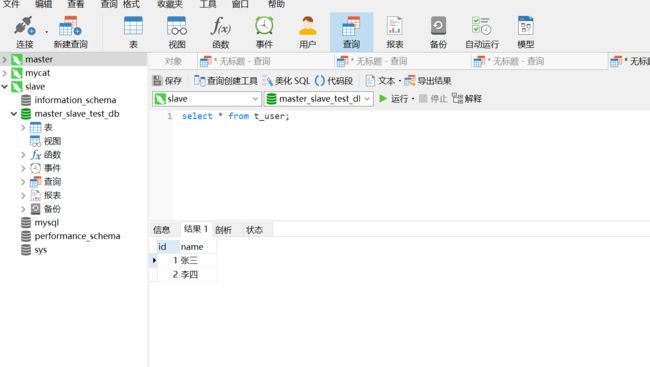
我们可以看到,master、slave库中都已经能查到刚才插入的两条数据了。数据插入的时的逻辑大致是这样的:操作mycat--->插入语句走的是master数据库--->数据插入到master后,slave库再同步该数据(同步是通过Binary log、Relay log实现的)。
6.5.3 验证读操作查询的是slave库
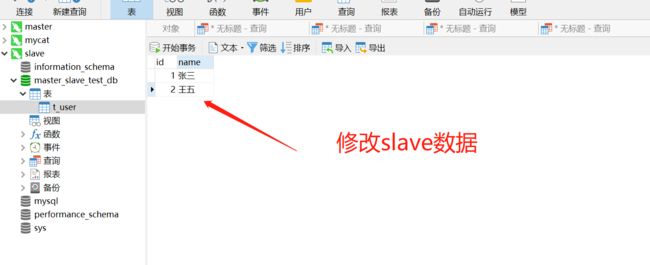
我们通过mycat执行查询操作,查到的数据是两条,那这两条到底是从master中查询到的,还是从slave库中查询到的呢?我们可以这样操作,直接操作slave库,将李四改成王五,我们通过mycat再来查数据
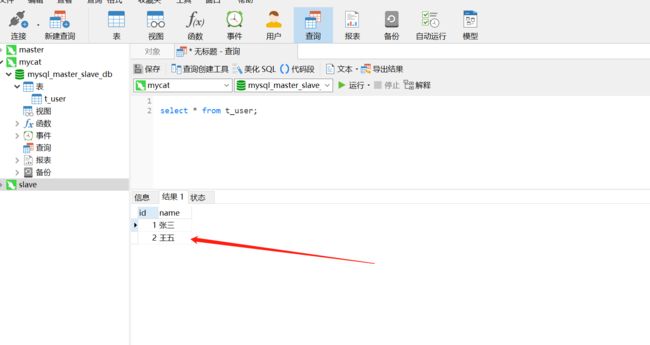
到此,我们的读写分离就实现好了。
七、Mycat分库
7.1 分片规则
7.1.1 auto-sharding-long 范围约定
以500万为单位实现分片规则。逻辑库A对应dataNode-db1和db2,1500万保存在db1中,500万零11000万保存在db2中,1000万零1~1500万保存在db1中,以此类推。
7.1.2 crc32slot规则
在CRUD操作时,根据具体数据的crc32算法计算,数据应该保存在哪一个dataNode中
7.2 配置分片规则需要注意的地方
1、
2、所有的tableRule只能使用一次,如果需要为多个表配置相同的分片规则,那么需要在此重新定义该规则。
3、在crc32slot算法中的分片数量(数据库数量)一旦给定,Mycat会将该分片数量和slor的取值范围保存到文件中,在修改分片数量时是不会生效的,需要将该文件删除,文件位置位于conf目录中的ruledata目录中。
7.3 配置分库
需求:
1、在master中创建3个数据库;
2、在Mycat中配置分库
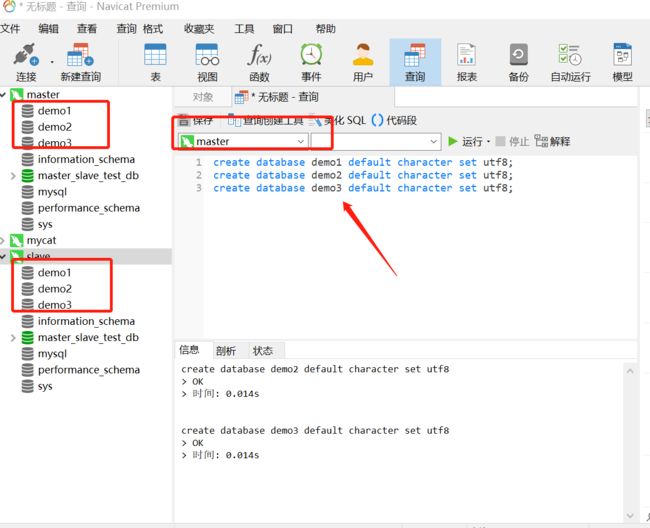
7.3.1 创建数据库
create database demo1 default character set utf8;
create database demo2 default character set utf8;
create database demo3 default character set utf8;
slave也会自动同步创建好这三个库
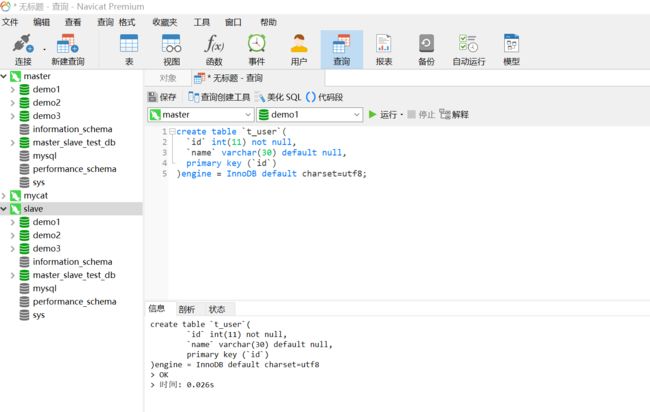
7.3.2 创建t_user表
在master的三个库中创建t_user表
create table `t_user`(
`id` int(11) not null,
`name` varchar(30) default null,
primary key (`id`)
)engine = InnoDB default charset=utf8;
7.3.3 修改配置文件
1、schema.xml
select user()
2、rule.xml
将crc32slot 分片数量改成3
3
3、重启Mycat
cd /data/mycat
bin/mycat restart
bin/mycat status
7.4 出现_slot列问题
我们现在操作mycat往t_user表里插入数据
insert into t_user(id,name) values(1,'admin');

执行结果是插入失败,提示Unknown column '_slot' in 'field list',这个错误的原因是,当我们用分库的方式去做数据存储时,Mycat会在我们的数据表中自动添加_slot这一个列,这一列记录的就是通过crc32slot算法计算出来的值。我们刚才是直接操作master来创建的t_user表,这样t_user表中就不会有_slot这一列。
当我们使用Mycat后,我们对所有表的创建应该在Mycat中完成。正确的操作流程是:先在mycat中配置逻辑库、逻辑表,然后在mycat中创建物理表,master库中会自动创建物理表,slave会自动同步。
7.5 解决_slot列问题
1、现在我们操作master将三个数据库里的t_user删除(slave库中的t_user表也会自动删除)
2、我们操作mycat,执行t_user建表语句
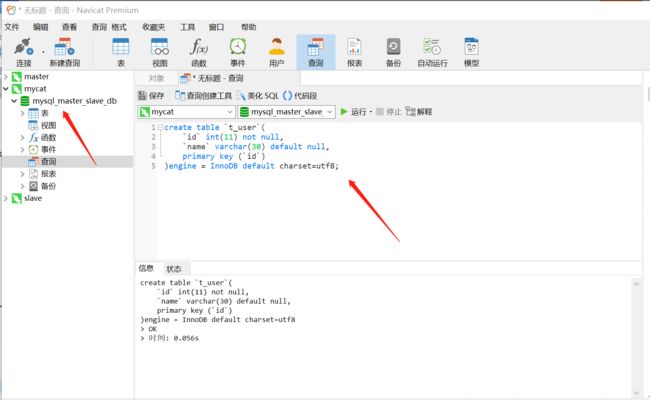
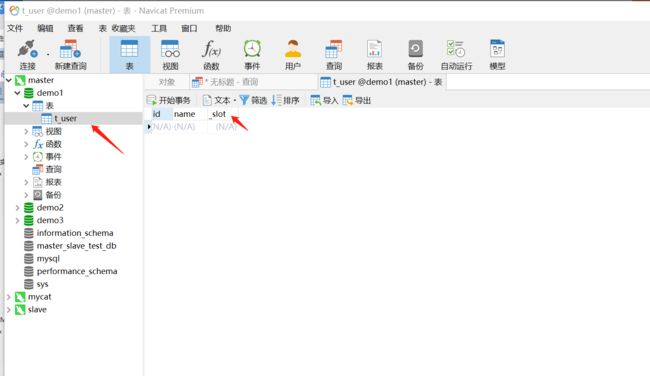
3、我们再去查看master和slave,可以看到三个库中都已经有t_user表了,并且多了_slot列
7.6 插入数据,实现数据分片
1、操作mycat 执行插入SQL
insert into t_user(id,name) values(1,'admin');
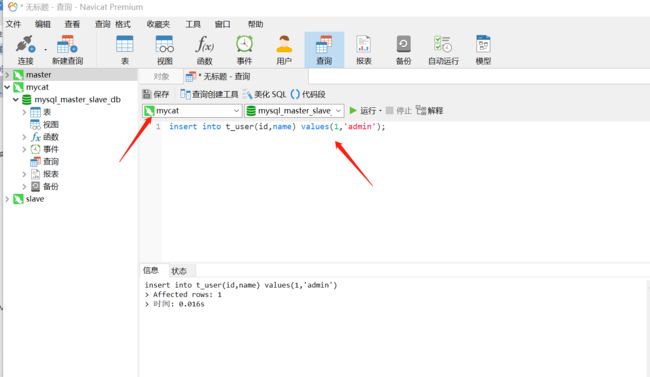
操作master,我们发现刚才这条数据插入到demo2这个库中了
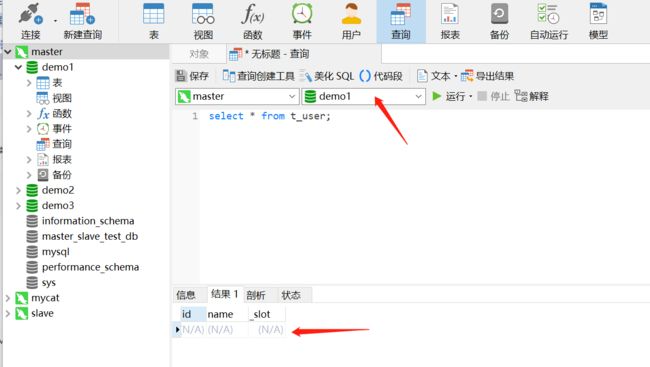
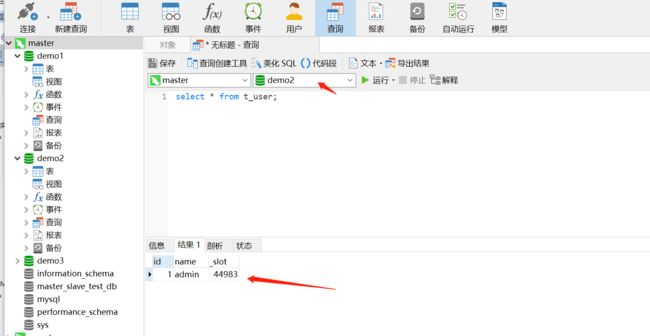
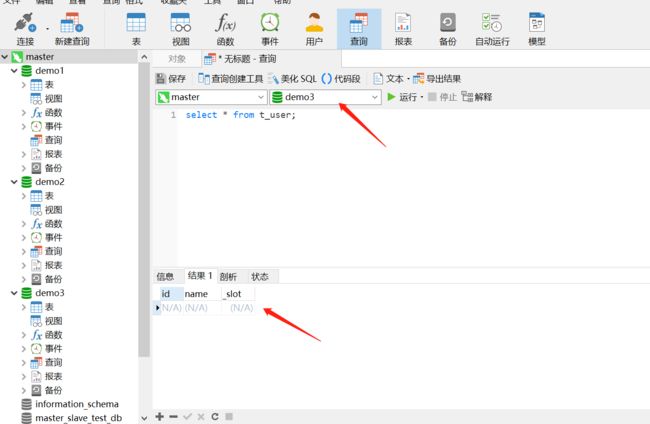
2、操作mycat 我们再插入一条数据
insert into t_user(id,name) values(2,'张三');
我们发现插入的还是demo2库中,但随着ID值的变化,后面的数据会被分摊到另外两个库中,到此,分库的功能我们就实现了。
7.7 注意事项
1、使用Mycat实现分库时,先在Mycat中定义逻辑库与逻辑表,然后在Mycat的链接中执行创建表的命令必须要在Mycat中运行。因为Mycat在创建表时,会在表中添加一个新的列,列名为_slot。
2、使用Mycat插入数据时,语句中必须要指定所有的列,即便是一个完全项插入也不能省略列名。
资料来源:MyCat基础入门到精通
最后给大家送波福利
阿里云折扣快速入口