一、 问题描述
最近在正常的版本迭代过程中,开发代码已正常交付测试,结果有一天,测试反应,测试环境响应很慢,系统卡,让开发找下原因.
二、 开发介入
首先现阶段只有生产和预生产环境,有专门的监控工具,可以很方便的定位到CPU占比较高的线程和对应的慢sql,或者慢响应。不过SIT环境并没有这些工具,所以需要我们自己手动介入了。要了测试机器的账户和密码,首先看到的现象如下
Linux指令:
1>ps –ef | grep java
2>top –d 1
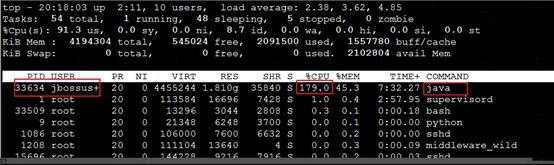
这里看到cpu直接彪到179%,为了避免是瞬时升高,我们监控了两分钟左右,持续在这个比值。可能会很奇怪,cpu怎么会超过100%,这里其实统计的是cpu的总利用率,原因在于,我们的机器是2C,所以是进行累计求和的。
三、 javacore 和 heapdump文件的区别
java程序在运行时,当遇到致命问题时,jvm会在java进程挂掉之前产生两个文件,一个是javacore,一个是heapdump文件
两者的区别:
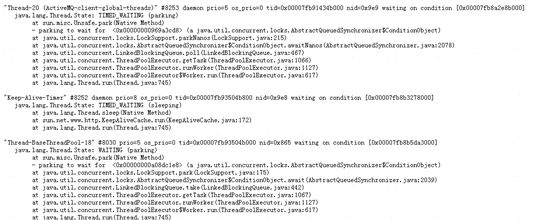
JavaCore文件主要保存的是Java应用各线程在某一时刻的运行的位置,即JVM执行到哪一个类、哪一个方法、哪一个行上。它是一个文本文件,打开后可以看到每一个线程的执行栈,以stack trace的显示。通过对JavaCore文件的分析可以得到应用是否“卡”在某一点上,即在某一点运行的时间太长,例如数据库查询,长期得不到响应,最终导致系统崩溃等情况
HeapDump文件是一个二进制文件,它保存了某一时刻JVM堆中对象使用情况,这种文件需要相应的工具进行分析,如Jdk自带工具Jvisual VM、IBM Heap Analyzer这类工具。这类文件最重要的作用就是分析系统中是否存在内存溢出的情况
如下图:javacore文件部分截图
dump 文件由于是二进制文件,我们只是看下文件后缀名
四、 手动拉取heapdump文件
结合我们的实际问题,上述两个文件我们其实都需要,虽然说是heapdump是用来分析堆内存的,但是如果频繁fgc,cpu的使用率必然也会居高不下
第二种方式:是JVM会帮我们自己生成,当我们的机器在频繁FGC的时候,会自动触发产生dump文件。
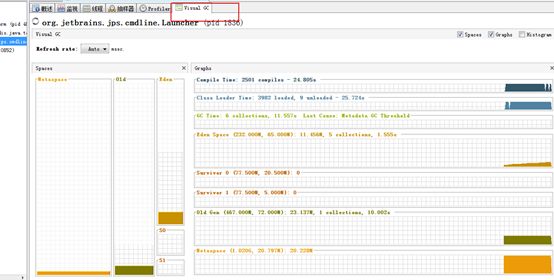
我们先来看下当时频繁FGC时的现状,下图我们重点关注老年代的使用率和FGC的次数,这里我们监控频率是3s
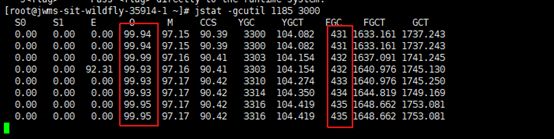
jstat -gc 1186 3000 该指令可以看到具体的分代大小,和每次回收大小

这里我们使用的G1收集器
注意点:通常dump文件是非常大的,如果用这种方式生成的文件大小都有几个G甚至十几个G,这种文件我们通过ftp下载本地,进行分析,是非常困难。所以在生成文件大小时,可以去指定大小
五、 JavaCore文件分析
JavaCore文件上述我们可以看到,其实单单看文件,是比较痛苦,因为这里会罗列出每个线程的执行状态,对于我们定位问题的效率是很慢的
所以我们需要重点关注当前哪个线程的CPU占比最高,这是发现问题的关键。通常我们用自研工具或者三方工具来去统计,举一个跟本专题不相关的例子
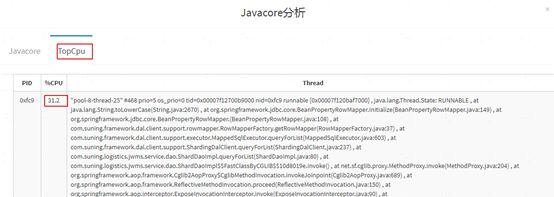
六、 Heapdump文件分析
这里我们使用工具MemoryAnalyzer工具来进行分析,为什么不用jdk自带的jvisualvm
个人感觉:这个工具结合visualGC插件来分析实时应用的堆内存使用情况还是比较直观
言归正传,进入我们今天的主角
导入dump文件之后
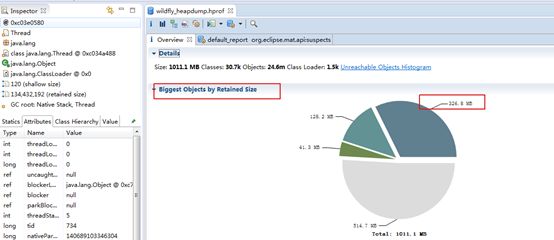
这里说名下,标色的是我们应用所占用堆内存最大的对象集
以下是我们最常用的分析统计工具,红框分别表示:直视图、树视图,直视图统计了大对象里占用最大的基本类型,还是不够直观。所以我们用树视图

树视图打开如下:
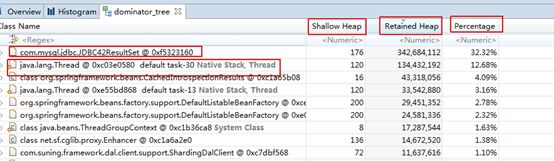
Shallow heap:对象自身占用的内存大小,不包括引用
Retained heap:表示当前对象被GC之后,从堆上总共释放的掉的内存
Percentage:占用百分比
这里的单位表示字节大小。由第一行我们看到,是于数据库相关的,关键字ResultSet,说明当前操作数据库的线程本身大小176字节,但是被GC掉后,可以回收342684112字节的内存,这下我们可以大胆的推断:应该是查了很多数据。
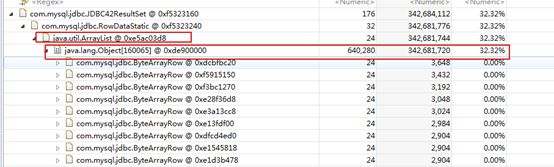
上图可以确定是一个数据量很大的list
进一步确认:打开第二个线程,结果已经出来了,里面已经标出我们对应的sql和调用点
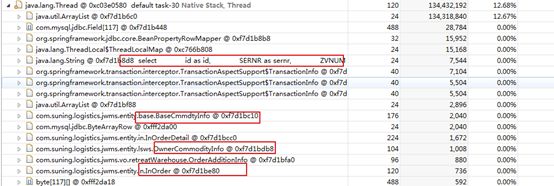
将sql抽取出来,发现是全表扫描,该表目前的数据量是14万,而我们生产实际有600多万,生产上线必炸,通过代码修改,cpu使用率恢复正常
七、 总结
以上分析是对于我们再没有使用比较高级的javacore 和 dump文件分析工具时,自己去手动拉取文件自己去分析。在大型互联网公司里,各自都有自己的分析工具。比如业界比较流行的就是阿里的在线分析诊断工具Arthas
.