用于真实的并且保留身份的侧面合成的双代理对抗生成网络
摘要:
合成真实的侧脸有希望通过用极端的姿态填充样本以及避免烦躁的注释工作,来更高效地训练对于大规模的无约束人脸识别的深度姿态不变的模型。但是因为合成人脸和真实人脸图片分布之间的差异,从合成的人脸中学习可能不会获得想要的性能。为了缩小这一差异,我们提出了双代理的对抗生成网络(DA-GAN)模型,该模型能够使用无标签的真实人脸数据来提高人脸模拟器输出的真实性,在真实性改善的同时又保留身份信息。双代理被特别设计为同时区分真假和身份信息。特别需要指出的是,我们使用了现有的3D人脸模型作为模拟器来生成不同姿态的侧面人脸图像。DA-GAN采用了一个全卷积网络作为生成器来生成高分辨率的图像和一个有双代理的自动编码器作为分辨器。除了新的架构,我们对于标准的GAN做了几个关键的修改来保持姿态和纹理,保留身份信息以及稳定训练过程:(i)一个姿态感知loss;(ii)一个身份感知loss;(iii)一个有边界平衡正则项的对抗loss。实验结果表明DA-GAN不仅带来了非常有趣的感知结果,而且在大规模并且具有挑战的NIST IJB-A无限制人脸识别基准测试中显著优于现有技术。除此之外,提出的DA-GAN有望成为更有效解决一般的迁徙学习问题的新方法。DA-GAN是我们提交给2017 NIST IJB-A人脸识别比赛的基础,在这个比赛中我们在验证和识别方面获得第一名。
全文:http://papers.nips.cc/paper/6612-dual-agent-gans-for-photorealistic-and-identity-preserving-profile-face-synthesis
这篇文章的目的旨在从单张人脸(正面)合成不同姿态下的不同人脸,来解决在实际的人脸识别数据集中,侧面人脸训练样本分布不平衡导致人脸识别模型对于具有少量样本的姿态下的人脸识别失败的问题。
合成多角度人脸的生成模型架构如下图所示,整个架构分为模拟器,生成器,辨别器三个部分。
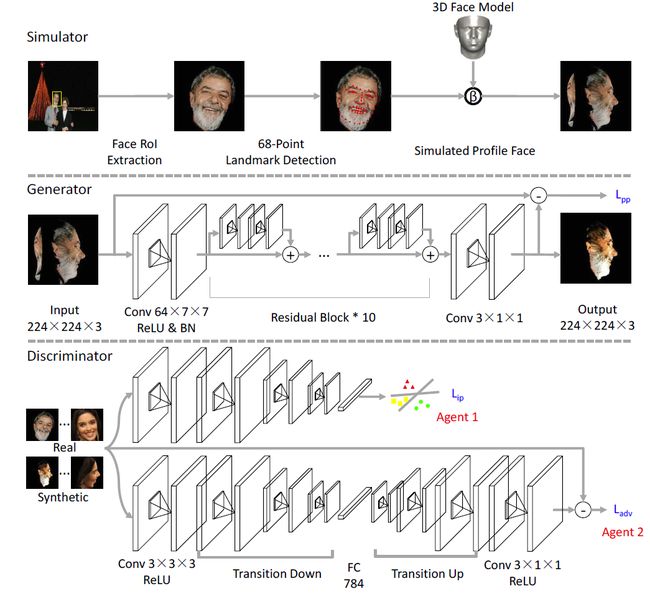
1.模拟器:
模拟器是用来从正面人脸合成不同角度的人脸的工具。首先,从图片中提取人脸感兴趣的区域(the face Region of Interest, RoI),然后对于提取的人脸,通过论文(S. Xiao, J. Feng, J. Xing, H. Lai, S. Yan, and A. Kassim. Robust facial landmark detection via recurrent attentive-refinement networks. In European Conference on Computer Vision, pages 57–72. Springer, 2016.)估算68个面部关键点,最终采用论文(X. Zhu, J. Yan, D. Yi, Z. Lei, and S. Z. Li. Discriminative 3d morphable model fitting. In Automatic Face and Gesture Recognition (FG), 2015 11th IEEE International Conference and Workshops on, volume 1, pages 1–8. IEEE, 2015.)的工作,将2D的关键点转换成3D形变模型(3D Morphable Model, 3D MM)。然后模拟不同旋转角度下的人脸。
2.生成器
本文中的生成器并不是标准的GAN中,从噪声数据中直接模拟逼近给定的数据分布。这篇论文中的生成器更形象的表述应该是一个精修器。因为作者发现采用模拟器生成的不同角度的人脸图片,当旋转的角度在[-90,-60]和[+60,+90]这两个区间范围内,其效果会很差,并且丢失大量纹理。因此这里生成器将模拟器中的输出作为输入,采用U型网络结构(先卷积,再反卷积decovolution),来生成最终的对应角度的旋转后的人脸图片。
3.辨别器
与其说是两个代理的辨别器,不如说就是两个分辨器,一个分辨图片是仿造的,还是真实的;一个分辨给定输入的图片的类标签(是否可以考虑这两个网络合成为一个,同时输出真假,以及类标签,类似Conditional Image Synthesis With Auxiliary Classifier GANs一文提出的AC-GAN)
loss设计
文章中训练网络一共设计了3个loss项,分别是对抗学习的loss,身份感知的loss以及姿态感知的loss
对抗的loss
采用的是有边界平衡正则项的Wasserstein距离,具体描述见论文(Began: Boundary equilibrium generative adversarial networks),其loss定义如下:
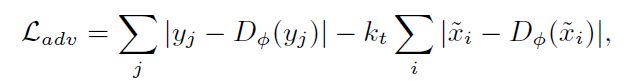
其中y是真实的人脸图片,kt是一个边界平衡正则项,其更新式如下:
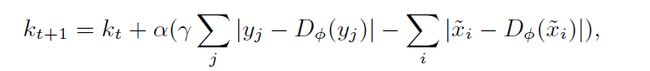
其中α是kt更新的学习率。
身份感知loss
评判的是分辨器的类别输出的问题,其定义如下:
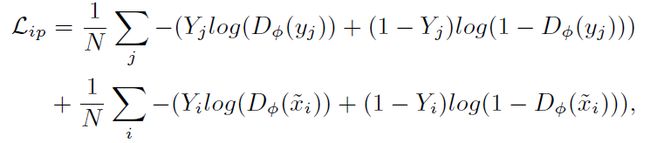
其中Y是对应的真实标签,这就是一个交叉熵的形式,与之前的需要一个预训练的分类器不同,这里的分类标签就是其中一个discriminator给出的分类结果
姿态感知loss
保证修改前后的图片像素变化最小(这限制了图片优化过程的变化不会很大)
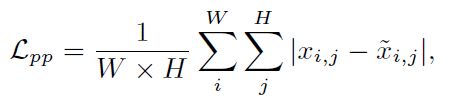
这篇文章提供了一个思路就是,在没有需要生成样本的指导下,要怎样采用GAN来生成样本,来进行训练,其给出的思路是,找生成的近似的模型,然后使用GAN模型进行近一步的优化,这样训练中就不需要有原图——需要生成的图,这样一个训练对的出现。因而在某种程度上,降低了训练GAN的成本,训练GAN只需要设计好优化的loss(但是关键是,要有近似解)
最后总结下这篇文章的贡献,整体的生成图片的框架,以及生成图片的原因,同时如何使用图片的原理(平衡不同pose在数据集中的分布);3个loss,2个分辨器各司其职。