一、消费方式
kafka采用发布订阅模式:一对多。发布订阅模式又分两种:
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
kafka consumer 采用 pull(拉)模式从 broker 中读取数据。pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费,consumer 会等待一段时间之后再返回,这段时长即为 timeout。
二、Kafka的消费者和消费者组
Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中,那么这就变成了队列模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。 一个消费者组中消费者订阅同一个Topic,每个消费者接受Topic的一部分分区的消息,从而实现对消费者的横向扩展,对消息进行分流。
注意:当单个消费者无法跟上数据生成的速度,就可以增加更多的消费者分担负载,每个消费者只处理部分partition的消息,从而实现单个应用程序的横向伸缩。但是不要让消费者的数量多于partition的数量,此时多余的消费者会空闲。此外,Kafka还允许多个应用程序从同一个Topic读取所有的消息,此时只要保证每个应用程序有自己的消费者组即可。
消费者组的概念就是:当有多个应用程序都需要从Kafka获取消息时,让每个app对应一个消费者组,从而使每个应用程序都能获取一个或多个Topic的全部消息;在每个消费者组中,往消费者组中添加消费者来伸缩读取能力和处理能力,消费者组中的每个消费者只处理每个Topic的一部分的消息,每个消费者对应一个线程。

线程安全
在同一个群组中,无法让一个线程运行多个消费者,也无法让多线线程安全地共享一个消费者。按照规则,一个消费者使用一个线程,如果要在同一个消费者组中运行多个消费者,需要让每个消费者运行在自己的线程中。最好把消费者的逻辑封装在自己的对象中,然后使用java的ExecutorService启动多个线程,使每个消费者运行在自己的线程上,可参考https://www.confluent.io/blog
三、分区分配策略
一个 consumer group 中有多个 consumer,一个 topic 有多个 partition,所以必然会涉及到 partition 的分配问题,即确定哪个 partition 由哪个 consumer 来消费。
关于如何设置partition值需要考虑的因素
- 1、一个partition只能被同一个消费者组里的一个消费者消费(一个消费者可以同时消费多个partition),因此,如果设置的partition的数量小于consumer的数量,就会有消费者消费不到数据。所以,推荐partition的数量一定要大于等于同时运行的consumer的数量。
- 2、另外一方面,建议partition的数量大于等于集群broker的数量,这样leader partition就可以均匀的分布在各个broker中,最终使得集群负载均衡。需要注意的是,kafka需要为每个partition分配一些内存来缓存消息数据,如果partition数量越大,就要为kafka分配更大的heap space。
Kafka 有两种分配策略,一个是 RoundRobin,一个是 Range,默认为Range,当消费者组内消费者发生变化时,会触发分区分配策略(方法重新分配)。
Partition Rebalance分区再均衡
- 1、消费者组中新添加消费者读取到原本是其他消费者读取的消息。
- 2、消费者关闭或崩溃之后离开群组,原本由他读取的partition将由群组里其他消费者读取。
- 3、当向一个Topic添加新的partition,会发生partition在消费者中的重新分配。
以上三种现象会使partition的所有权在消费者之间转移,这样的行为叫作再均衡。
再均衡的优点:
- 给消费者组带来了高可用性和伸缩性
再均衡的缺点:
- 再均衡期间消费者无法读取消息,整个群组有一小段时间不可用
- partition被重新分配给一个消费者时,消费者当前的读取状态会丢失,有可能还需要去刷新缓存,在它重新恢复状态之前会拖慢应用程序。因此需要进行安全的再均衡和避免不必要的再均衡。
RoundRobin
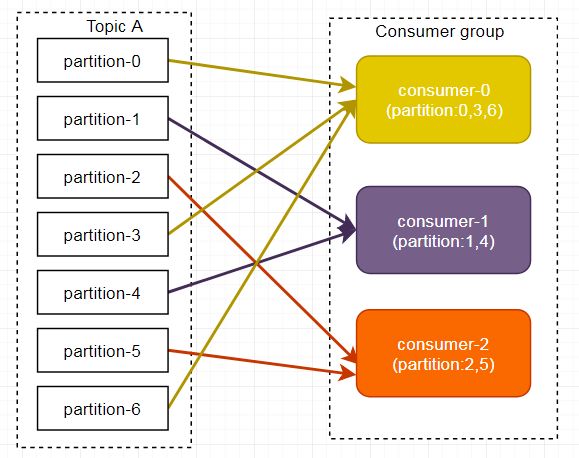
RoundRobin 轮询方式将分区所有作为一个整体进行 Hash 排序,消费者组内分配分区个数最大差别为 1,是按照组来分的,可以解决多个消费者消费数据不均衡的问题。
但是,当消费者组内订阅不同主题时,可能造成消费混乱,如下图所示,Consumer0 订阅主题 A,Consumer1 订阅主题 B。
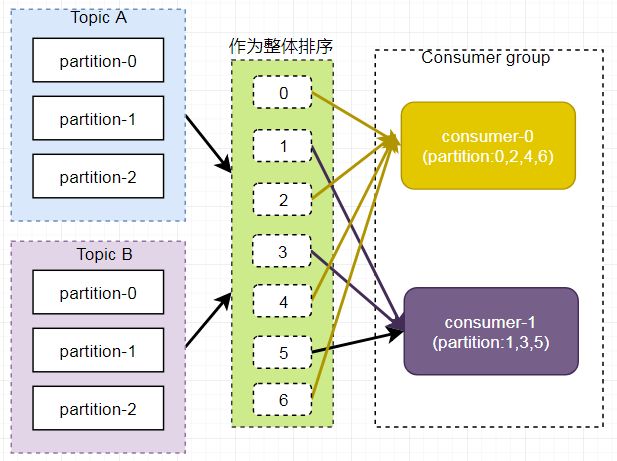
将 A、B 主题的分区排序后分配给消费者组,TopicB 分区中的数据可能 分配到 Consumer0 中。
Range
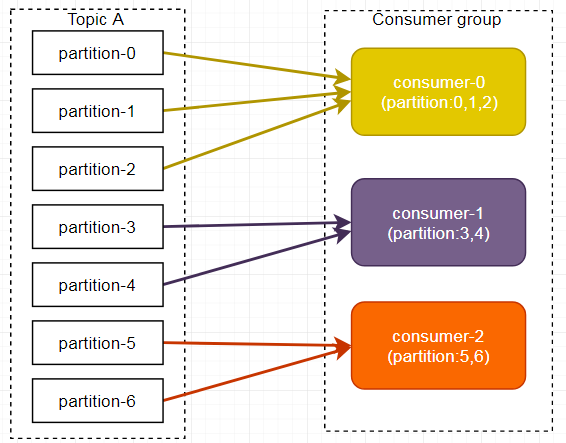
Range 方式是按照主题来分的,不会产生轮询方式的消费混乱问题。
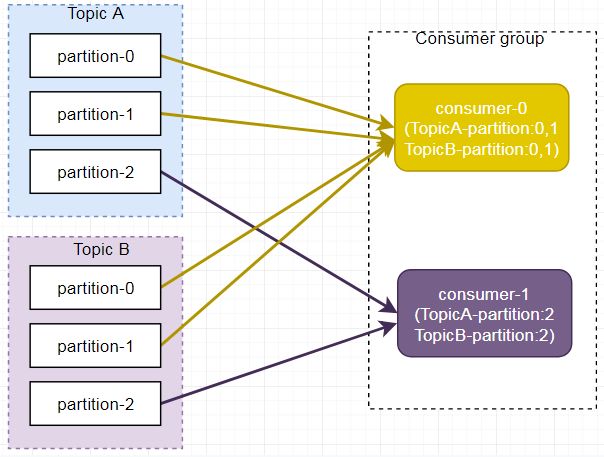
但是,如下图所示,Consumer0、Consumer1 同时订阅了主题 A 和 B,可能造成消息分配不对等问题,当消费者组内订阅的主题越多,分区分配可能越不均衡。
四、Offset 的维护
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故
障前的位置继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
consumer group +topic + partition 唯一确定一个offest
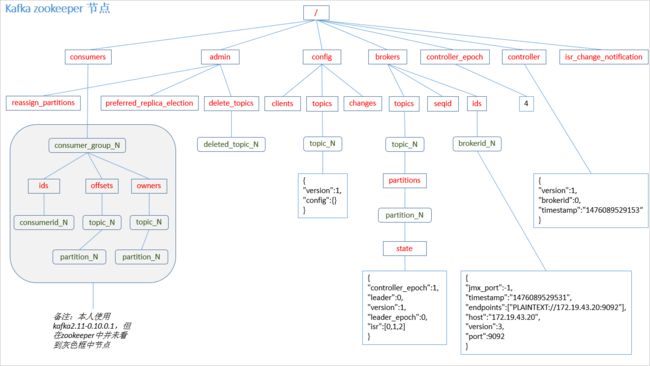
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中,从 0.9 版本开始,
consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为__consumer_offsets。
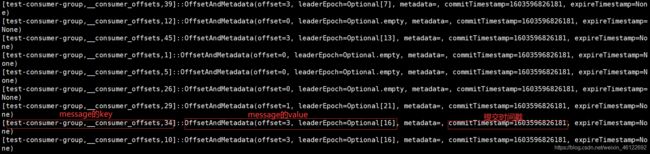
你如果特别好奇,实在想看看offset什么的,也可以执行下面操作:
修改配置文件 consumer.properties
[root@centos7-4 kafka]# vim config/consumer.properties
添加如下配置
exclude.internal.topics=false
再启动一个消费者
[root@centos7-4 kafka]# bin/kafka-console-consumer.sh --topic __consumer_offsets
--bootstrap-server localhost:9092 --formatter
"kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"
--consumer.config config/consumer.properties --from-beginning
五、消费者的配置
1、fetch.min.bytes:指定消费者从broker获取消息的最小字节数,即等到有足够的数据时才把它返回给消费者。
2、fetch.max.wait.ms:等待broker返回数据的最大时间,默认是500ms。fetch.min.bytes和fetch.max.wait.ms哪个条件先得到满足,就按照哪种方式返回数据。
3、max.partition.fetch.bytes:指定broker从每个partition中返回给消费者的最大字节数,默认1MB。
4、session.timeout.ms:指定消费者被认定死亡之前可以与服务器断开连接的时间,默认是3s。
5、auto.offset.reset:消费者在读取一个没有偏移量或者偏移量无效的情况下(因为消费者长时间失效,包含偏移量的记录已经过时并被删除)该作何处理。默认是latest(消费者从最新的记录开始读取数据)。另一个值是earliest(消费者从起始位置读取partition的记录)
6、enable.auto.commit:指定消费者是否自动提交偏移量,默认为true。
7、partition.assignment.strategy:指定partition如何分配给消费者,默认是Range。Range:把Topic的若干个连续的partition分配给消费者。RoundRobin:把Topic的所有partition逐个分配给消费者。
8、max.poll.records:单次调用poll方法能够返回的消息数量。
六、提交和偏移量
6.1、消费者为什么要提交偏移量
当消费者崩溃或者有新的消费者加入,那么就会触发再均衡(rebalance),完成再均衡后,每个消费者可能会分配到新的分区,而不是之前处理那个,为了能够继续之前的工作,消费者需要读取每个partition最后一次提交的偏移量,然后从偏移量指定的地方继续处理。
6.2、提交偏移量可能带来的问题
case1:如果提交的偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。

case2:如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
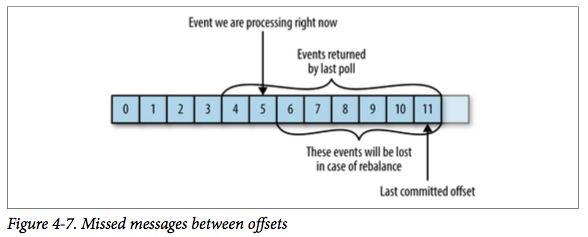
6.3、提交偏移量的方式
- 1)自动提交 Automatic Commit
enable.auto.commit设置成true(默认为true),那么每过5s,消费者自动把从poll()方法接收到的最大的偏移量提交。提交的时间间隔由auto.commit.interval.ms控制,默认是5s。
自动提交的优点是方便,但是可能会重复处理消息
- 2)提交当前偏移量 Commit Current Offset
将enable.auto.commit设置成false,让应用程序决定何时提交偏移量。commitSync()提交由poll()方法返回的最新偏移量,所以在处理完所有消息后要确保调用commitSync,否则会有消息丢失的风险。commitSync在提交成功或碰到无法恢复的错误之前,会一直重试。如果发生了再均衡,从最近一批消息到发生再均衡之间的所有消息都会被重复处理。
不足:broker在对提交请求作出回应之前,应用程序会一直阻塞,会限制应用程序的吞吐量。
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records) {
System.out.println("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n", record.topic(),
record.partition(), record.offset(), record.key(),
record.value());
}
try {
consumer.commitSync();//处理完当前批次的消息,在轮询更多的消息之前,调用commitSync方法提交当前批次最新的消息
} catch (CommitFailedException e) {
log.error("commit failed", e);//只要没有发生不可恢复的错误,commitSync方法会一直尝试直至提交成功。如果提交失败,我们也只能把异常记录到错误日志里
}
}
- 3)异步提交
异步提交的commitAsync,只管发送提交请求,无需等待broker响应。commitAsync提交之后不进行重试,假设要提交偏移量2000,这时候发生短暂的通信问题,服务器接收不到提交请求,因此也就不会作出响应。与此同时,我们处理了另外一批消息,并成功提交了偏移量3000,。如果commitAsync重新尝试提交2000,那么它有可能在3000之后提交成功,这个时候如果发生再均衡,就会出现重复消息。
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records) {
System.out.println("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n", record.topic(),
record.partition(), record.offset(), record.key(),
record.value());
}
consumer.commitAsync(new OffsetCommitCallback() {//在broker作出响应后执行回调函数,回调经常被用于记录提交错误或生成度量指标
public void onComplete(Map offsets, Exception e) {
if (e != null) {
log.error("Commit Failed for offsets {}", offsets, e);
}
}});
}
- 4)同步和异步组合提交
一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大的问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。但是如果在关闭消费者或再均衡前的最后一次提交,就要确保提交成功。
因此,在消费者关闭之前一般会组合使用commitAsync和commitSync提交偏移量。
try {
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records) {
System.out.println("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n", record.topic(),
record.partition(), record.offset(), record.key(),
record.value());
}
consumer.commitAsync();//如果一切正常,我们使用commitAsync来提交,这样速度更快,而且即使这次提交失败,下次提交很可能会成功
} catch (CommitFailedException e) {
log.error("commit failed", e);
} finally {
try {
consumer.commitSync();//关闭消费者前,使用commitSync,直到提交成成功或者发生无法恢复的错误
} finally {
consumer.close();
}
}
- 5)提交特定的偏移量
消费者API允许调用commitSync()和commitAsync()方法时传入希望提交的partition和offset的map,即提交特定的偏移量。
private Map currentOffsets = new HashMap<>();//用于跟踪偏移量的map
int count = 0;
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records) {
System.out.println("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n", record.topic(),
record.partition(), record.offset(), record.key(),
record.value());//模拟对消息的处理
//在读取每条消息后,使用期望处理的下一个消息的偏移量更新map里的偏移量。下一次就从这里开始读取消息
currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, “no matadata”));
if (count++ % 1000 == 0) {//每处理1000条消息就提交一次偏移量,在实际应用中,可以根据时间或者消息的内容进行提交
consumer.commitAsync(currentOffsets, null);
}
}
}
- 6)再均衡监听器
在为消费者分配新的partition或者移除旧的partition时,可以通过消费者API执行一些应用程序代码,在使用subscribe()方法时传入一个ConsumerRebalanceListener实例。
ConsumerRebalanceListener需要实现的两个方法
a):public void onPartitionRevoked(Collection
partitions)方法会在再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,下一个接管partition的消费者就知道该从哪里开始读取了。 b):public void onPartitionAssigned(Collection
partitions)方法会在重新分配partition之后和消费者开始读取消息之前被调用。
下面的例子演示如何在失去partition的所有权之前通过onPartitionRevoked()方法来提交偏移量。
//指定主题subscribe
consumer.subscribe(Collections.singletonList(TOPIC), new ConsumerRebalanceListener() {
/**
* 消费者组停止消费前的后续工作,例如位移的提交
*/
@Override
public void onPartitionsRevoked(Collection partitions) {
//例如将偏移量存入到DB
}
/**
* 消费者停止消费,均衡分区和消费者
*/
@Override
public void onPartitionsAssigned(Collection partitions) {
//从DB读取消费位移,用seek()指定位移
}
});
public class HandlerRebalance implements ConsumerRebalanceListener {
private final Map currOffsets;
private final KafkaConsumer consumer;
//private final Transaction tr事务类的实例
public HandlerRebalance(Map currOffsets,
KafkaConsumer consumer) {
this.currOffsets = currOffsets;
this.consumer = consumer;
}
/*模拟一个保存分区偏移量的数据库表*/
public final static ConcurrentHashMap
partitionOffsetMap = new ConcurrentHashMap();
//分区再均衡之前
public void onPartitionsRevoked(
Collection partitions) {
final String id = Thread.currentThread().getId()+"";
System.out.println(id+"-onPartitionsRevoked参数值为:"+partitions);
System.out.println(id+"-服务器准备分区再均衡,提交偏移量。当前偏移量为:"
+currOffsets);
//开始事务
//偏移量写入数据库
System.out.println("分区偏移量表中:"+partitionOffsetMap);
for(TopicPartition topicPartition:partitions){
partitionOffsetMap.put(topicPartition,
currOffsets.get(topicPartition).offset());
}
consumer.commitSync(currOffsets);
//提交业务数和偏移量入库 tr.commit
}
//分区再均衡完成以后
public void onPartitionsAssigned(
Collection partitions) {
final String id = "" + Thread.currentThread().getId();
System.out.println(id+"-再均衡完成,onPartitionsAssigned参数值为:"+partitions);
System.out.println("分区偏移量表中:"+partitionOffsetMap);
for(TopicPartition topicPartition:partitions){
System.out.println(id+"-topicPartition"+topicPartition);
//模拟从数据库中取得上次的偏移量
Long offset = partitionOffsetMap.get(topicPartition);
if(offset==null) continue;
//从特定偏移量处开始记录 (从指定分区中的指定偏移量开始消费)
//这样就可以确保分区再均衡中的数据不错乱
consumer.seek(topicPartition,partitionOffsetMap.get(topicPartition));
}
}
}
七、Consumer Rebalance解析
Consumer有个Rebalance的特性,即重新负载均衡,该特性依赖于一个协调器来实现。每当Consumer Group中有Consumer退出或有新的Consumer加入都会触发Rebalance。
之所以要重新负载均衡,是为了将退出的Consumer所负责处理的数据再重新分配到组内的其他Consumer上进行处理。或当有新加入的Consumer时,将组内其他Consumer的负载压力,重新进均匀分配,而不会说新加入一个Consumer就闲在那。
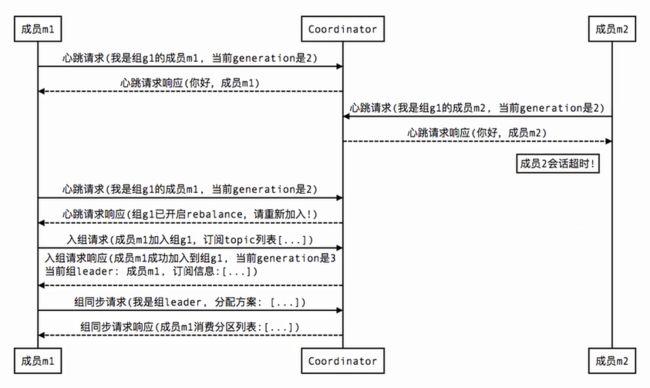
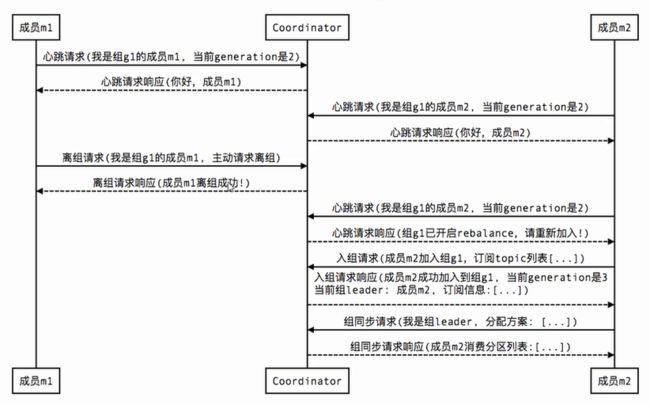
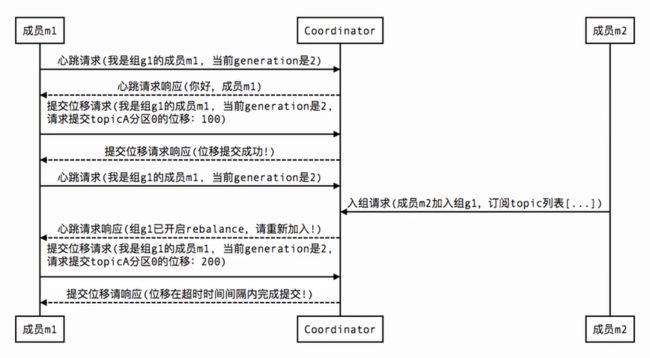
下面就用几张图简单描述一下,各种情况触发Rebalance时,组内成员是如何与协调器进行交互的。
-
1、新成员加入组(member join):
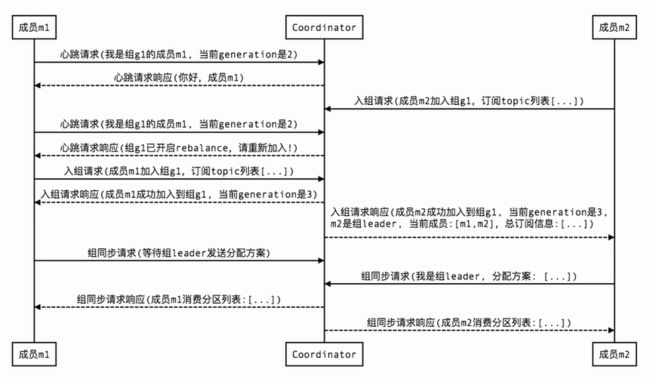
Tips:图中的Coordinator是协调器,而generation则类似于乐观锁中的版本号,每当成员入组成功就会更新,也是起到一个并发控制的作用。
-
2、组成员崩溃/非正常退出(member failure):
-
3、组成员主动离组/正常退出(member leave group):
-
4、当Consumer提交位移(member commit offset)时,也会有类似的交互过程:
参考:
https://blog.csdn.net/weixin_46122692/article/details/109270433
http://www.dockone.io/article/9956
https://www.cnblogs.com/sodawoods-blogs/p/8969774.html
https://blog.csdn.net/weixin_44367006/article/details/103075173
https://blog.51cto.com/zero01/2498017