MapReduce基本原理

image.png
基本概念
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
MapReduce由两个阶段组成:Map和Reduce,用于只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参是key、value对,表示函数的输入信息。
#jps
#start-all.sh
#jps
#hdfs dfs -lsr /
#hdfs dfs -cat /input/data.txt
#cd /root/training/hadoop-2.4.1/share/hadoop/mapreduce
#hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /input/data.txt /output
#hdfs dfs -lsr /
#hdfs dfs -cat /output/part-r-00000
hdfs dfs -cat /input/data.txt

image.png
第一个MapReduce程序
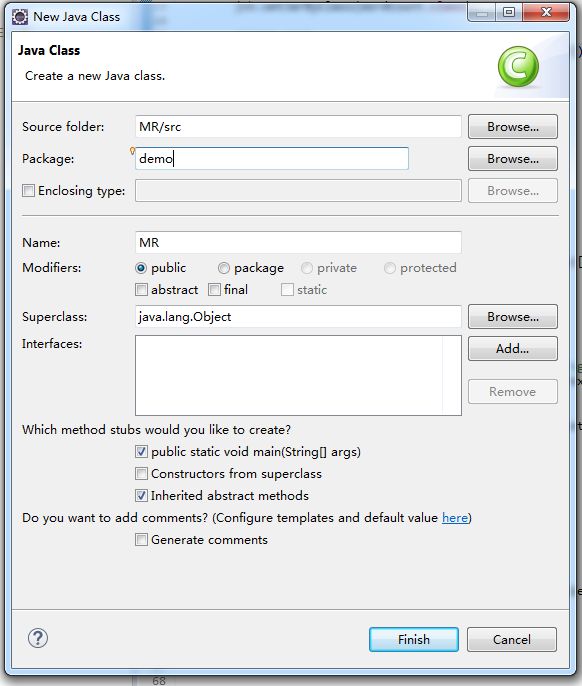
image.png
package demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception{
//申明一个job
Configuration conf = new Configuration();
Job job = new Job(conf);
//指明程序的入口
job.setJarByClass(WordCount.class);
//指明输入的数据
//FileInputFormat.addInputPath(job,new Path("/input/data.txt"));
//第二种
FileInputFormat.addInputPath(job,new Path(args[0]));
//组装Mapper和Reducer
//设置Mapper
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Reducer
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指明数据输出的路径
//FileOutputFormat.setOutputPath(job, new Path("/output1"));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交任务运行
//job.waitForCompletion(true);
job.waitForCompletion(false);
}
}
// k1 v1 k2 v2
//class WordCountMapper extends Mapper{
class WordCountMapper extends Mapper{
@Override
protected void map(LongWritable key1, Text value1,Context context)
throws IOException, InterruptedException {
//分词
//key1 value1
// 1 I love Beijing
String var = value1.toString();
String[] words = var.split(" ");
//统计每个单词的频率,得到k2和v2
for(String word:words) {
// k2 v2
context.write(new Text(word), new LongWritable(1));
}
}
}
//k3 v3 k4 v4
class WordCountReducer extends Reducer{
@Override
protected void reduce(Text key, Iterable values,Context context)
throws IOException, InterruptedException {
//key values
// I (1,1)
//得到每个单词总的频率
long sum = 0;
for(LongWritable value:values) {
sum += value.get();
}
//将k4和v4输出
context.write(key, new LongWritable(sum));
}
}
右击程序,选择Export,Java,JAR file
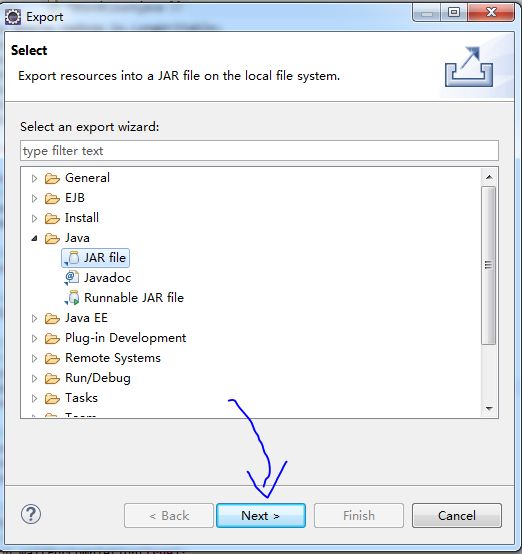
image.png
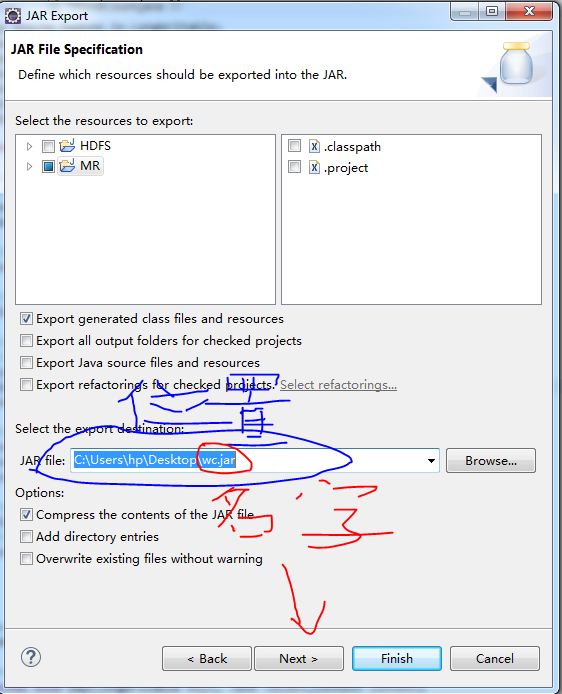
image.png
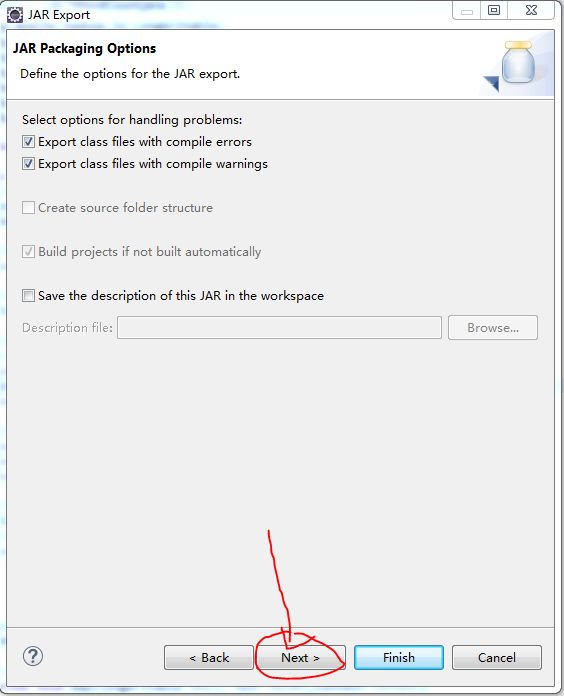
image.png
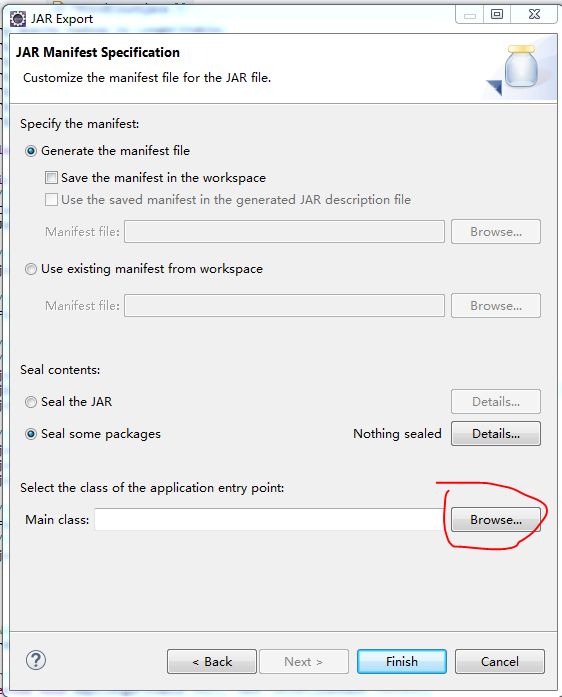
image.png
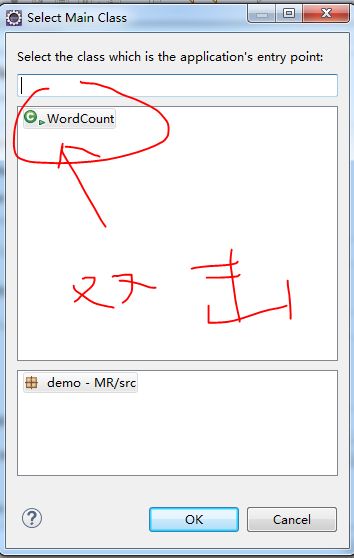
image.png

image.png
上传到training目录下
#cd ~/training
#hadoop jar wc.jar
#hdfs dfs -lsr /output1
# hdfs dfs -cat /output1/part-r-00000
#hadoop jar wc.jar /input/data.txt /output2
#hdfs dfs -lsr /output2
MapReduce的序列化
序列化(Serialization)是指把结构化对象转化为字节流。
反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象
Java序列化(java.io.Serializable)
Hadoop序列化的特点
序列化格式特点:
-紧凑:高效使用存储空间。
-快速:读写数据的额外开销小
-可扩展:可透明地读取老格式的数据
-互操作:支持多语言的交互
Hadoop的序列化格式:Writable
Hadoop序列化的作用
序列化在分布式环境的两大作用:进程间通信,永久存储。
Hadoop节点间通信。
#more emp.csv
# hdfs dfs -put emp.csv /input/emp.csv
image.png
demo.se-Emp.java
package demo.se;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
//代表员工
public class Emp implements Writable{
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
private int empno;
private String ename;
private String job;
private int mgr;
private String hiredate;
private int sal;
private int comm;
private int deptno;
public Emp(){
}
@Override
public String toString() {
return "The salary of" + this.ename + "is" + this.sal;
}
@Override
public void readFields(DataInput input) throws IOException {
// 反序列化
this.empno = input.readInt();
this.ename = input.readUTF();
this.job = input.readUTF();
this.mgr = input.readInt();
this.hiredate = input.readUTF();
this.sal = input.readInt();
this.comm = input.readInt();
this.deptno = input.readInt();
}
@Override
public void write(DataOutput output) throws IOException {
// 序列化
output.writeInt(empno);
output.writeUTF(ename);
output.writeUTF(job);
output.writeInt(mgr);
output.writeUTF(hiredate);
output.writeInt(sal);
output.writeInt(comm);
output.writeInt(deptno);
}
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
}
demo.se-EmpMain.java
package demo.se;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EmpMain {
public static void main(String[] args) throws Exception{
//申明一个job
Configuration conf = new Configuration();
Job job = new Job(conf);
//指明程序的入口
job.setJarByClass(EmpMain.class);
//指明输入的数据
FileInputFormat.setInputPaths(job,new Path(args[0]));
//组装Mapper和Reducer
//设置Mapper
job.setMapperClass(EmpMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Emp.class);
//指明数据输出的路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交任务运行
job.waitForCompletion(true);
}
}
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
class EmpMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
String str = value.toString();
String[] words = str.split(",");
//创建一个Emp的对象
Emp emp = new Emp();
//设置员工的属性
emp.setEmpno(Integer.parseInt(words[0]));
emp.setEname(words[1]);
emp.setJob(words[2]);
//设置员工的经理
try {
emp.setMgr(Integer.parseInt(words[3]));
}catch(Exception ex) {
emp.setMgr(0);
}
emp.setHiredate(words[4]);
emp.setSal(Integer.parseInt(words[5]));
//设置员工的奖金
try {
emp.setComm(Integer.parseInt(words[6]));
}catch(Exception ex) {
emp.setComm(0);
}
emp.setDeptno(Integer.parseInt(words[7]));
//输出 key:员工号 value:员工hdfs
context.write(new LongWritable(emp.getEmpno()), emp);
}
}
打包。
# hadoop jar se.jar /input/emp.csv /outputemp
#hdfs dfs -lsr /outputemp
#hdfs dfs -cat /outputemp/part-r-00000
MapReduce的排序
在Map和Reduce阶段进行排序时,比较的是key2
value2是不参与排序比较的。
如果要想让value2也进行排序,需要把key2和value2组装成新的类,作为key2,才能参与比较。
demo.sort.Emp.java
package demo.sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
//代表员工
public class Emp implements WritableComparable{
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
private int empno;
private String ename;
private String job;
private int mgr;
private String hiredate;
private int sal;
private int comm;
private int deptno;
public Emp(){
}
@Override
public int compareTo(Emp e) {
//按照薪水进行排序
if(this.sal >= e.sal) {
return 1;
}else {
return -1;
}
}
@Override
public String toString() {
return "The salary of" + this.ename + " is" + this.sal;
}
@Override
public void readFields(DataInput input) throws IOException {
// 反序列化
this.empno = input.readInt();
this.ename = input.readUTF();
this.job = input.readUTF();
this.mgr = input.readInt();
this.hiredate = input.readUTF();
this.sal = input.readInt();
this.comm = input.readInt();
this.deptno = input.readInt();
}
@Override
public void write(DataOutput output) throws IOException {
// 序列化
output.writeInt(empno);
output.writeUTF(ename);
output.writeUTF(job);
output.writeInt(mgr);
output.writeUTF(hiredate);
output.writeInt(sal);
output.writeInt(comm);
output.writeInt(deptno);
}
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
}
demo.sort.EmpSortMain.java
package demo.sort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EmpSortMain {
public static void main(String[] args) throws Exception{
//申明一个job
Configuration conf = new Configuration();
Job job = new Job(conf);
//指明程序的入口
job.setJarByClass(EmpSortMain.class);
//指明输入的数据
FileInputFormat.setInputPaths(job,new Path(args[0]));
//组装Mapper和Reducer
//设置Mapper
job.setMapperClass(EmpMapper.class);
job.setMapOutputKeyClass(Emp.class);
job.setMapOutputValueClass(NullWritable.class);
//指明数据输出的路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交任务运行
job.waitForCompletion(true);
}
}
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
class EmpMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
String str = value.toString();
String[] words = str.split(",");
//创建一个Emp的对象
Emp emp = new Emp();
//设置员工的属性
emp.setEmpno(Integer.parseInt(words[0]));
emp.setEname(words[1]);
emp.setJob(words[2]);
//设置员工的经理
try {
emp.setMgr(Integer.parseInt(words[3]));
}catch(Exception ex) {
emp.setMgr(0);
}
emp.setHiredate(words[4]);
emp.setSal(Integer.parseInt(words[5]));
//设置员工的奖金
try {
emp.setComm(Integer.parseInt(words[6]));
}catch(Exception ex) {
emp.setComm(0);
}
emp.setDeptno(Integer.parseInt(words[7]));
//输出 key:Emp value:NullWritable
context.write(emp,NullWritable.get());
}
}
#hadoop jar sort.jar /input/emp.csv /outputsortemp
#hdfs dfs -lsr /outputsortemp
#hdfs dfs -cat /outputsortemp/part-r-00000
MapReduce的分区
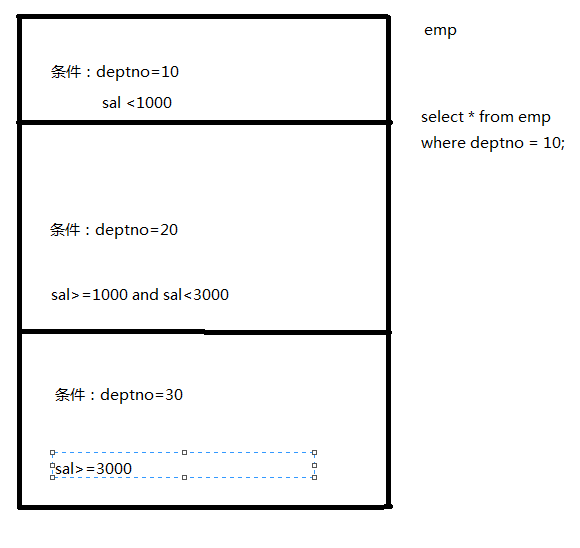
image.png
Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类
MapReduce有一个默认的分区规则:只会产生一个分区
什么是Combiner?
每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量
combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。
如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
WordCount.java
package demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception{
//申明一个job
Configuration conf = new Configuration();
Job job = new Job(conf);
//指明程序的入口
job.setJarByClass(WordCount.class);
//指明输入的数据
FileInputFormat.addInputPath(job,new Path(args[0]));
//组装Mapper和Reducer
//设置Mapper
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Combiner
job.setCombinerClass(WordCountReducer.class);
//设置Reducer
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指明数据输出的路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交任务运行
job.waitForCompletion(true);
}
}
// k1 v1 k2 v2
//class WordCountMapper extends Mapper{
class WordCountMapper extends Mapper{
@Override
protected void map(LongWritable key1, Text value1,Context context)
throws IOException, InterruptedException {
//分词
//key1 value1
// 1 I love Beijing
String var = value1.toString();
String[] words = var.split(" ");
//统计每个单词的频率,得到k2和v2
for(String word:words) {
// k2 v2
context.write(new Text(word), new LongWritable(1));
}
}
}
//k3 v3 k4 v4
class WordCountReducer extends Reducer{
@Override
protected void reduce(Text key, Iterable values,Context context)
throws IOException, InterruptedException {
//key values
// I (1,1)
//得到每个单词总的频率
long sum = 0;
for(LongWritable value:values) {
sum += value.get();
}
//将k4和v4输出
context.write(key, new LongWritable(sum));
}
}
#hadoop jar wcd.jar /input/data.txt /dd
#hdfs dfs -ls /dd
# hdfs dfs -cat /dd/part-r-00000
注意
-Combiner的输出是Reduce的输入,如果Combiner是可插拔的,添加Combiner绝不能改变最终的计算结果。所以Combiner值应该用于那种Reduce的输入key/value与输出key/value类型安全一致,且不影响最终结果的场景。不如累加,最大值等。
什么是Shuffle?
Shuffle的过程

image.png
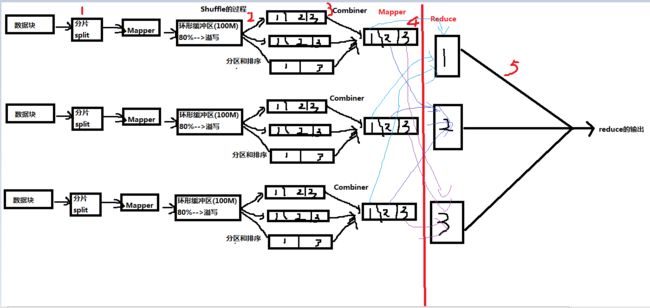
image.png