原文链接:http://tecdat.cn/?p=23184
原文出处:拓端数据部落公众号
在本文中,我们将学习如何使用keras,用手写数字图像数据集(即MNIST)进行深度学习。本文的目的是为了让大家亲身体验并熟悉培训课程中的神经网络部分。
1 软件包的下载和安装
在这个例子的笔记本中,需要keras R包。由于它有许多需要下载和安装的依赖包,因此需要几分钟的时间才能完成。请耐心等待!
1.1 下载 keras
我们可以通过CRAN调用install.packages("keras")来获得。

1.2 加载keras包和所需的tensorflow后端
由于keras只是流行的深度学习框架的一个接口,我们必须安装一个特殊的深度学习后端。默认和推荐的后端是TensorFlow。通过调用install_keras(),它将为TensorFlow安装所有需要的依赖项。下面的单元格需要一分钟左右的时间来运行。
![]()

现在,我们准备好探索深度学习了。
2 MNIST数据集的概述
在深度学习中,比传统的机器学习领域更成功的应用之一是图像识别。我们将在本教程中使用广泛使用的MNIST手写数字图像数据集。关于该数据集的更多信息可以在以下网站找到:https://en.wikipedia.org/wiki...。
2.1 加载MNIST数据集
这个数据集已经包含在keras/tensorflow的安装中,我们可以简单地加载数据集。加载数据集只需要不到一分钟的时间。
dataset_mnist()![]()
2.2 训练和测试数据集
MNIST数据集的数据结构简单明了,有两块。(1) 训练集:x(即特征):60000x28x28张量,对应于60000张28x28像素的图像,采用灰度表示(即每个28x28矩阵中所有的值都是0到255之间的整数),y(即因变量):一个长度为60000的向量,包含相应的数字,整数值在0到9之间。(2) 测试集:与训练集相同,但只有10000个图像和因变量。数据集的详细结构可以通过下面的str(mnist)看到。
str(mnist)
现在我们准备好训练和测试数据集的特征(x)和因变量(y),可以用str()函数检查x\_train和y\_train的结构。
str(x_train)
str(y_train)![]()
2.3 绘制图像
现在让我们使用R将一个选定的28x28矩阵绘制成图像。显示图像的方式是从矩阵表示法中旋转了90度。因此,还需要额外的步骤来重新排列矩阵,以便能够使用image()函数来显示它的实际方向。
index_image = 28 ## 改变这个索引以看不同的图像。
output\_matrix <- t(output\_matrix)
这里是上述图像的原始28x28矩阵。
input_matrix
3 卷积神经网络模型
在本节中,我们将展示如何使用卷积神经网络(CNN)对MNIST手写数据集进行分类,将图像分为数字。这与之前学习的问题完全相同,但CNN是一种比一般的深度神经网络更好的图像识别深度学习方法。CNN利用了二维图像中相邻像素之间的关系来获得更好的表现。它还避免了为全彩的高分辨率图像生成数千或数百万的特征。
3.1 数据集导入和参数设置
现在让我们再次从头开始导入MNIST数据集,因为已经专门为深度神经网络模型做了一些预处理。对于CNN,有不同的预处理步骤。我们还定义了一些以后要使用的参数。
#加载mnist数据的训练和测试数据集
x_train <- train$x
y_train <- train$y
x_test <- test$x
y_test <- test$y# 定义一些用于CNN模型的参数
epochs <- 10
# 输入图像维度
img_rows <- 283.2 数据预处理
对于一般的CNN方法,MxN图像的输入是一个具有K个特定通道的MxNxK三维数组。例如,一个灰度MxN图像只有一个通道,其输入是MxNx1张量。一个MXN每通道8位的RGB图像有三个通道,有3个MxN数组,数值在0和255之间,所以输入是MxNx3张量。对于现在的问题,图像是灰度的,但我们需要通过使用array\_reshape()将二维数组重塑为三维张量来特别定义有一个通道。input\_shape变量将在后面的CNN模型中使用。对于RGB颜色的图像,通道的数量是3,如果输入的图像是RGB格式,我们需要在下面的代码单元中用 "3 "代替 "1"。
3.2.1 在维度中添加通道
x\_train <- array\_reshape(x\_train, c(nrow(x\_train), img\_rows, img\_cols, 1))
x\_test <- array\_reshape(x\_test, c(nrow(x\_test), img\_rows, img\_cols, 1))
input\_shape <- c(img\_rows, img_cols, 1)这里是重塑图像的结构,第一维是图像索引,第2-4维是一个三维张量,尽管只有一个通道。
str(x_train)![]()
3.2.2 标准化
与DNN模型一样,为了在优化过程中同样考虑数值的稳定性,我们将输入值标准化为0和1之间。
x\_train <- x\_train / 255
x\_test <- x\_test / 2553.2.3 将因变量转换为分类变量
与DNN模型一样,因变量被转换为分类变量。
#将类向量转换为二进制类矩阵
to_categorical(train, numclass)3.3 构建一个CNN模型
正如我们所讨论的,CNN模型包含一系列二维卷积层,其中有几个参数。(1)kernal\_size,通常是3x3或5x5;(2)过滤器的数量,对应于输出张量中的通道数量(即第三维);(3)激活函数。对于第一层,还有一个input\_shape参数,即输入图像的尺寸和通道。为了防止过度拟合和加快计算速度,通常在一个或几个二维卷积层之后应用一个池化层。一个典型的池化层将2x2池大小的最大值作为输出的新值,这基本上是将大小减少到一半。除了池化邻居值之外,也可以使用Dropout。在几个二维卷积层之后,我们还需要将三维张量输出 "扁平化 "为一维张量,然后添加一个或几个密集层,将二维卷积层的输出连接到目标因变量类别。
3.3.1 定义一个CNN模型结构
现在我们定义一个CNN模型,其中有两个带有最大池的二维卷积层,第2层带有附加滤波以防止过拟合。然后将输出扁平化,并使用两个密集层连接到图像的类别。
#定义模型结构
conv_2d(filters = 32,size = c(3,3)) %>%
max\_pooling\_2d(size = c(2, 2)) %>%
conv_2d(filters = 64, size = c(3,3), 'relu') %>%
max_pooling(size = c(2, 2)) %>%
dropout(rate = 0.25) %>%
layer_flatten() %>%summary(model)
3.3.2 编译模型
与DNN模型类似,我们需要编译所定义的CNN模型。
# 编译模型
loss\_categorical\_crossentropy,
optimizer_adadelta(),
c('accuracy')训练模型并保存每个训练迭代(epochs)的历史。请注意,由于我们没有使用GPU,它需要几分钟的时间来完成。如果在GPU上运行,训练时间可以大大减少。
3.3.3 训练模型
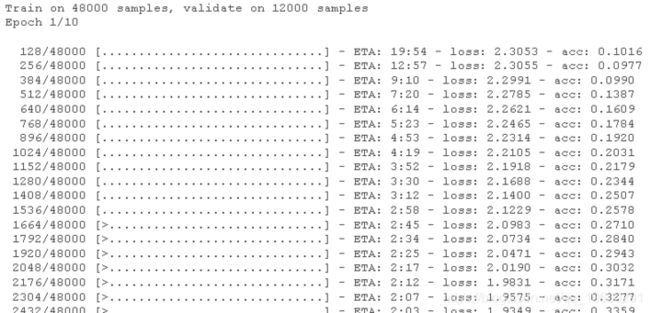
现在,我们可以用我们处理过的数据来训练模型。每个epochs的历史记录都可以被保存下来以追踪进度。请注意,由于我们没有使用GPU,它需要几分钟的时间来完成。在等待结果时,请耐心等待。如果在GPU上运行,训练时间可以大大减少。
# 训练模型
fit(
x\_train, y\_train,
validation_split = 0.2
)
plot(cnn)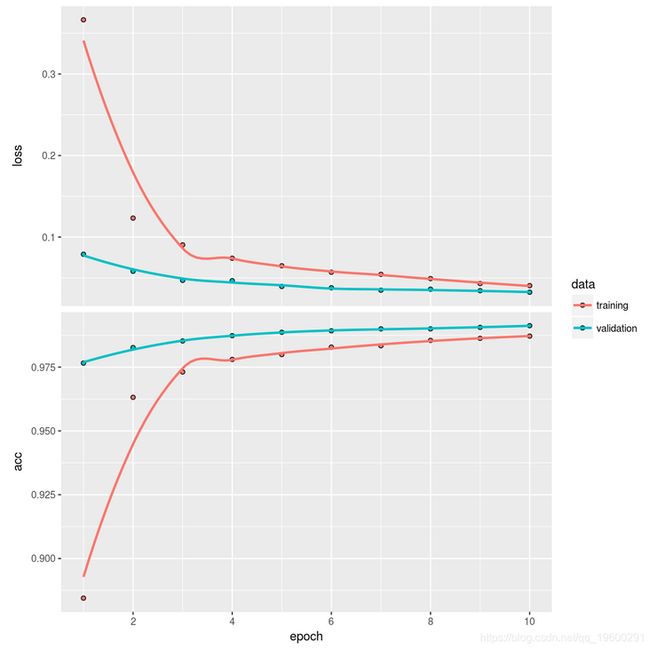
可以在测试数据集上评估训练后的模型准确性,这是很好的。
evaluate(x\_test, y\_test)

3.4 模型预测
对于任何新的图像,在经过同样的预处理后,我们可以用训练好的模型来预测该图像属于哪一个数字。
#
# 模型预测
predict\_classes(x\_test)![]()
3.5 检查误判的图像
现在让我们检查几张被误判的图像,看看是否人眼识别能比这个简单的CNN模型做得更好。
## 错分类图像的数量
sum(cnn_pred != testy)![]()
x\[cnn_pred != test$y,\]
y\[cnn_pred !=test$y\]
cnn\_pred\[cnn\_pred !=test$y\]index_image = 6 ## 改变这个索引以看到不同的图像。
image(1:28, output_matrix数字9被误预测为数字8