| 作者:邓哲也 | 旷视 MegEngine 基础架构组工程师
在近年来的深度学习领域,许多研究机构和研究者通过增大模型的参数量来提升模型的表现,取得了非常显著的成果,一次次令业界称奇。这客观上使得“扩大模型的尺寸”几乎一度成为各家竞相追逐的唯一指标。几年间,最先进的模型的参数量已增加了成百上千倍,但每张 GPU 的显存大小却几乎没有增长。这导致大模型的训练往往依赖于巨量的 GPU 卡数。于是,很多想法出色、有研究热情的研究者单纯因为资金不足,难以继续从事深度学习的研究,而近年里的重要科研成果也几乎都是被几家头部研究机构所垄断。从长远看来,这种趋势未必有利于深度学习这门科学的发展进步。
作为深度学习训练框架的开发者,我们除了帮助用户在一个训练任务中利用更多的 GPU 卡(即分布式训练)之外,还采用了各种技术手段,以增加每张 GPU 上显存的利用效率,降低研究者的资金成本。增加显存利用效率的常见方法有:
- 生命周期不重叠的算子共享显存;
- 通过额外的数据传输减少显存占用;
- 通过额外的计算减少显存占用。
目前已有的方法中大多都要求计算图是静态的,随着越来越多的框架支持动态图模式,能否在动态图训练时最大程度地利用有限的显存资源,成为了评估深度学习框架性能的重要指标。MegEngine 在近期发布的v1.4 版本中,通过引入 DTR[[1]](https://arxiv.org/abs/2006.09... 技术并进行进一步的工程优化,提供了一种通过额外计算减少显存占用的途径,从而让小显存也能训练大模型,享受更大 batch size 所带来的训练收益。在 2080Ti 上,ResNet-50、ShuffleNet 等网络的最大 batch size 可以达到原来的 3 倍以上。本篇文章将从工程实现的角度重点介绍在 MegEngine 中如何使用 DTR 技术对动态图显存进行优化的。
一、背景介绍
1.1 计算图
在深度学习领域,神经网络模型本质上都可以用一个计算图来表示。它的训练过程可以分为三个部分:前向传播,反向传播,参数更新。
以 y=wx+b 为例,它的前向计算过程为输入 x 和参数 w 首先经过乘法运算得到中间结果 p,接着 p 和参数 b 经过加法运算,得到右侧最终的输出 y。
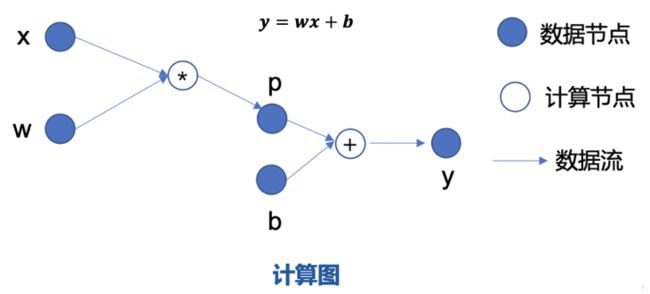
反向传播需要求出 y 关于 w 与 b 的导数,首先求出 y 关于 p 的导数是 1,p 关于 w的导数是 x,使用链式法则就可以得到 y关于 w 的导数是 x。
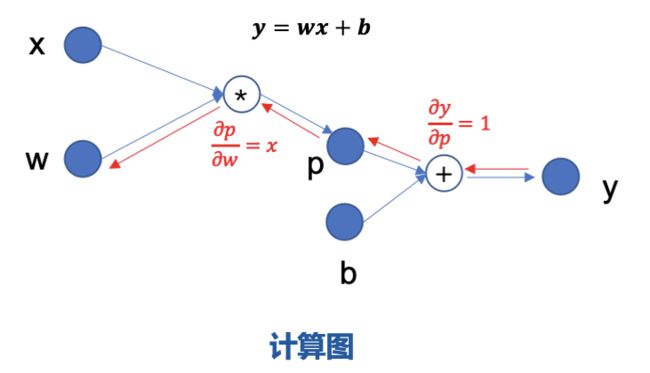
注意,在反向传播的过程中,会用到前向传播的中间结果。因此当网络结构过大时,显存容量会显著地制约 batch size 的大小。
1.2 静态图显存优化
因此,对于大网络结构的训练场景,在静态图上的显存优化主要可以分为三个方向:
- 静态内存分配。由于获得了整张计算图,所以可以去分析每一个 tensor 和每个算子的生命周期。对于生命周期没有重叠的算子,它们是可以共享显存的。
- 梯度检查点(用计算换显存)。设置一些梯度检查点,剩下的中间结果就先释放掉,如果将来在反向传播的过程中发现前向结果不在显存中,就找到最近的梯度检查点,恢复出被释放的 tensor。

- 内存交换(用带宽换显存)。把暂时不用的数据从 GPU 上交换到 CPU 上,到了需要的时候,再把它交换回来。

二、动态图显存优化与 DTR 策略
2.1 动态图显存优化
对于动态图的显存优化,相比静态图,最明显的变化是,动态图无法提前获得全局的计算图信息。因为无法得到每个 tensor 的生命周期,所以静态显存分配不再可用;梯度检查点还是可行的,且依然可以寻找最优的检查点;内存交换在动态图中仍然也是可用的。因此动态图显存优化有两个方向:
- 用计算换显存,也就是动态图版的 Sublinear 显存优化;
- 用带宽换显存,在 GPU 和 CPU 之间交换内容。

上图是从 ResNet-50 这个网络中取出的三个 tensor,分别是卷积、BatchNorm 和 ReLu 的输出 tensor,对比了用重计算和通过带宽来交换它们的时间开销。可以发现交换的耗时比重计算的耗时普遍大两个数量级左右。因为在 CPU 和 GPU 之间交换数据的耗时取决于 PCIe 的速度,而 8 张 2080Ti 显卡同时训练时,每张卡上分到的交换速度只有 3GB/s 左右。因此,可以确定在动态图中主要的优化方向仍然是用计算去换显存。
为了达到用计算换显存的目的,MegEngine 采取以下三步来实现。
- 实现基础设施:记录产生每个 tensor 的计算路径,使框架支持释放和恢复 tensor;
- 用户提供策略:提供释放 tensor 的接口,由用户显式地调用,框架不需要提供任何策略,只需按照用户的策略去执行每一步,在需要恢复 tensor 时现场重计算;
- 框架寻找策略:框架自动寻找策略并执行它,不需要用户的干预,做到用户对显存优化完全无感知。
在理解框架如何释放和恢复 tensor 前,我们需要先了解 tensor 的计算路径。在网络训练的过程中,每个 tensor 的来源只有两种情况:
- 由外部数据加载进来,例如:输入数据;
- 是某个算子的输出,例如:卷积层的输出。
对于算子的输出,我们可以记录这个 tensor 的计算路径(Compute Path),结构体如下所示:
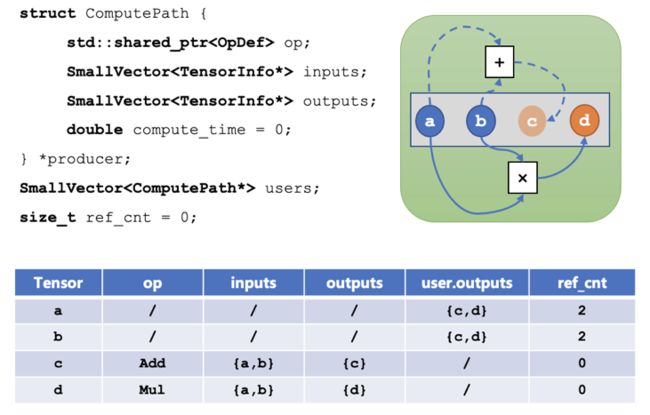
每个 tensor 都会有一个 producer,如果 producer 是空,就表示它是由外部数据加载进来的,否则它是一个计算路径,其中:
- op 表示产生这个 tensor 的算子;
- inputs 表示这个算子需要的输入 tensor;
- outputs 表示这个算子产生的输出 tensor;
- compute_time 表示这个算子实际的运行时间;
- users 中存储的是所有依赖该 tensor 作为输入的计算路径;
- ref_cnt 表示依赖该 tensor 作为输入的 tensor 数量。
关于如何利用计算历史来释放和恢复 tensor,来看一个具体的例子:
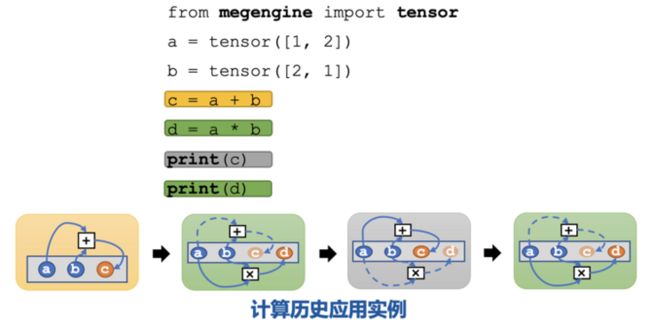
首先在 MegEngine 中定义两个tensor a 和 b,计算 c=a+b。图中每个灰色的长方形都表示显存,假设显存里只能放下 3 个 tensor。这时正好有足够的空间来放下 c,并记录下 c 的计算路径(对应上图黄色框所示)。接着算 d=a*b,因为此时显存里已经没有空间放下 d 了,需要先把 c 从显存中释放,释放 c 的时候,c 的计算路径仍然是保留在 host 端的,但是c占用的显存可以被释放掉,此时就有空闲的位置放 d 了(对应图中第一个绿色框)。如果此时用户想 print(c),框架发现此时 c 不在显存中,需要立即把它恢复出来。恢复之前,发现显存已经满了,就得先把d释放掉,然后根据c的计算路径恢复出c,返回给用户(对应图中灰色框)。如果用户继续 print(d),就先释放 c,恢复出 d(对应图中最后的绿色框作)。
通过这个例子可以发现,用户对于它使用的 tensor 是否在显存中是没有感知的,当用户想访问一个暂时被释放的 tensor 时,框架会当场把它恢复出来给用户,用户会以为他要访问的 tensor 一直在显存里。
2.2 DTR 策略
为了使得框架能够自动计算策略,我们在 MegEngine v1.4 中引入了 DTR——《动态 tensor 重造》这篇论文中的技术,它是完全动态的启发式策略。它的核心就是当显存超过一个阈值的时候,动态地选择一些 tensor 将其释放掉,直到显存低于阈值。选择时会根据三方面对 tensor 进行估价:
- 重计算的开销越小越好;
- 占用的显存越大越好;
- 在显存中停留的时间越长越好。
另外,DTR 论文中还提出,除了重计算带来的开销之外,其他的额外开销主要用于寻找应该被释放掉的最优 tensor。因为在显存中,tensor 停留的时长是不断在变化的,所以只能在需要释放的时候现场计算最优的 tensor。
对此,论文中提出了两个运行时的优化技巧:
- 不考虑小的 tensor,当 tensor 大小小于候选集中的 tensor 的平均大小的 1% 时,不加入候选集;
- 每次在需要释放 tensor 的时候,随机采样 sqrt(N) 个 tensor 进行遍历(N 为目前可释放的 tensor 候选集的大小)
三、MegEngine 中的工程实现
3.1 动态图核心——Tensor Interpreter
在介绍 DTR 实现之前,首先介绍一下 MegEngine 动态图的核心——Tensor Interpreter(解释器),它会把 python 代码翻译成下面这四种基础操作,依次解释执行:
- Put:把外部数据从 host 端加载进显存中,得到一个 tensor
- ApplyOp:执行一个算子,它的参数是 op(算子)和输入 tensor,返回输出tensor
- Del:删除一个 tensor,释放它在显存中占用的空间
- GetValue:获取一个 tensor 的值,需要把数据从显存中加载到 host 端
3.2 释放和恢复 tensor 的底层实现
在前文,我们提到过用户并不知道他访问的 tensor 当前是否在显存中,但是框架能保证当用户想获得 tensor 的内容时,就算它不在显存中,也可以立即恢复出来。
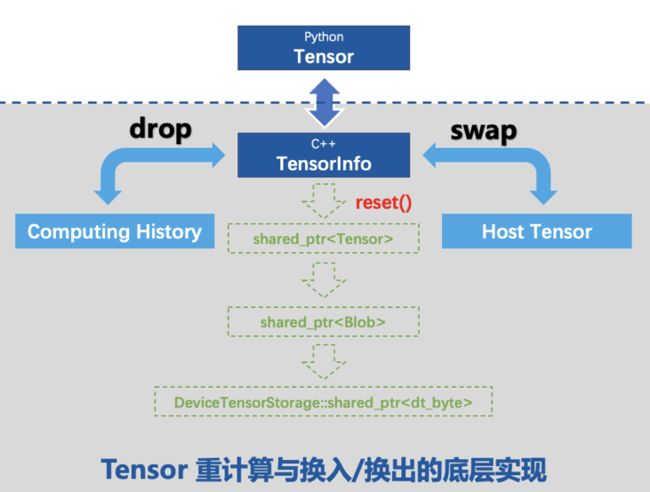
如上图,若框架要释放掉当前这个 tensor 的显存,reset 它的指针就可以把最底层的显存释放掉。为了将来能够恢复出该 tensor,需要在 tensorInfo 中维护一些信息,如果使用 drop(用计算换显存)就需要记录计算历史;如果使用 swap(用带宽换显存),就需要把它先交换到 cpu 上记录一个 host tensor。将来如果用户访问了该 tensor,框架会检查它对应的 tensorInfo,如果发现已经不在显存上了,就根据计算历史或 host tensor 在显存中恢复出 tensor 的内容返回给用户。
3.3 引入 DTR 后的算子执行

上图是 DTR 核心的伪代码,对于 ApplyOp 方法,以往只需要执行黄色的代码,表示对 input 输入执行 op 算子。
现在由于我们引入了 DTR 技术,这些输入 tensor 有可能已经不在显存中了。因此,执行前首先需要给它们打上标记,在这个算子执行完之前不能释放掉这些输入 tensor。然后调用 AutoEvict(),控制当前的显存占用不超过阈值,方法是检查当前的显存占用,如果一直超过阈值就不断地调用 FindBestTensor()算法,再根据启发式估价函数找出最优的 tensor 释放掉。
做完 AutoEvict() 之后,当前的显存占用已经低于阈值了,此时检查输入的每个 tensor是否在显存中,如果不在显存中就调用 Regenerate()把它恢复出来,然后才能执行当前算子。Regenerate(x)的过程就是重计算 x 的过程,重计算的时候读取 x 的计算历史——op 和 inputs,然后递归调用 ApplyOp 就可以恢复出 x。
3.4 tensor 的删除操作
当一个 tensor 不会再被用户和框架使用时,这个 tensor 就可以被删除,从而释放其占用的显存。MegEngine 通过引用计数来控制 tensor 的删除,当引用计数变为 0 的时候,这个 tensor 就会自动发一个删除的语句给解释器。这样带来的问题是,如果真的把这个 tensor 删除的话,它确实可以立即节省显存,但会让整体的策略变得非常局限。
比如下面这张图是某张计算图的子图,可以看到一个 9MB 的 tensor 经过一个卷积算子,得到了一个 25MB 的 tensor,再经过一个 Elemwise 算子,得到一个 25MB 的 tensor,再经过 BatchNorm 算子和 Elemwise 算子,得到的都是 25MB 的 tensor。

注意到,由于这里的 Elemwise 算子都是加法,所以它的输入(两个红色的 tensor)在求导的时候都不会被用到。因此,求导器不需要保留住两个红色的 tensor,在前向计算完之后它们实际上是会被立即释放掉的。这样的好处是可以立即节省显存,但在引入 DTR 技术之后,如果真的删掉了这两个红色的 tensor,就会导致图中绿色的 tensor 永远不可能被释放,因为它们的计算源(红色 tensor)已经丢失了,一旦释放绿色的 tensor 就再也恢复不出来了。解决方案是在前向的过程中用释放来代替删除,也就是“假删除”——保留 tensorInfo,只是释放掉 tensorInfo 下面对应的显存。这样只需要保留 9MB 的 tensor 就可以释放掉后面 4 个 25MB 的 tensor,并且可以在将来的任意时刻恢复出它们。

上图就是 MegEngine 中对 tensor 的删除的伪代码实现,在解释器收到 Del 指令时,会对 tensorInfo 调用 Free()函数,根据当前的状态是否是前向计算来决定做真删除还是假删除。假删除的实现很简单,打上删除标记,释放掉 tensorInfo 管理的显存即可;真删除的实现比较复杂,首先更新产生该 tensor 的输入 tensor 的 ref_cnt,然后调用 RemoveDep()检查所有依赖该 tensor 作为输入的 tensor,如果它们不在显存中,必须现在调用 Regenerate 恢复出它们,因为一旦当前 tensor 被真删除,这些 tensor 就恢复不出来了。
做完了上述操作之后,就可以真正释放掉该 tensor 对应的 tensorInfo 了。释放完还需要递归地检查 x 的计算历史输入 tensor,如果这些 tensor 中有 ref_cnt=0 且被打上删除标记的,就可以执行真删除。
3.5 训练耗时对比
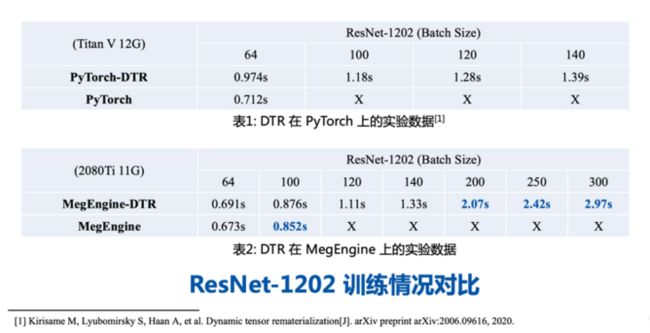
下图是 MegEngine 的 DTR 实现与原论文在 PyTorch 中的实现在 ResNet-1202 上的训练情况对比。请注意实验用的显卡不同,所以从数据上看 MegEngine 稍快一些。在显存管理上 MegEngine 要更好一些,因为在 11G 的显卡上仍然能跑 batchsize=100 的训练。除了论文中尝试的最大 batchsize=140 之外,我们尝试了更大的 batch size,也都是可以运行的。
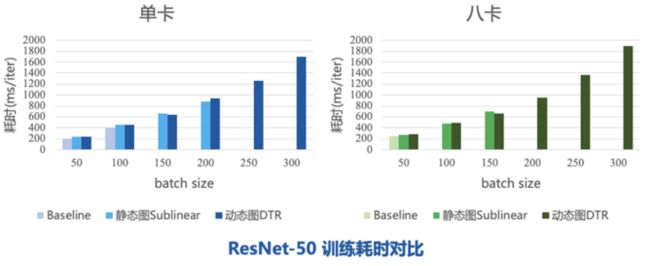
下面是 MegEngine 框架上开启不同显存优化的训练耗时对比,baseline 是在动态图模式下不加任何显存优化运行的结果。首先是两个常见的模型——ResNet-50 和 ShuffleNet,可以发现开启 DTR 优化后极限 batch size 超过了静态图 Sublinear 和 baseline,且在 batch size 相同时耗时和 Sublinear 持平。
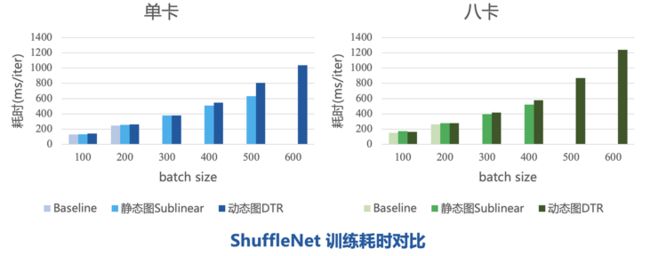
上面的两个模型都是偏静态的,所以我们可以用静态图的 Sublinear 显存优化来做对比,而下面这个 SPOS 网络就比较特殊,它是一个从输入到输出有多条路径可以更新的大网络。在训练过程中,每一轮会随机采样去更新某一条路径,这就导致每轮执行的语句可能不相同。对于这种网络,在动态图里实现会比较自然。因此,这里只取了动态图DTR优化的结果与 Baseline 比较。不论是单卡还是八卡,动态图的极限 batch size 都在 100,如果打开 DTR 可以跑到 250 甚至更大。

3.6 碎片问题和优化方法
在实现 DTR 的过程中,我们发现随着 batch size 增大,每次产生的 tensor 的显存占用也会增大,tensor 大了之后,显存中能存下的 tensor 数量就会变少,重计算次数就会增多,tensor 的生成和释放会越来越频繁,导致碎片问题非常严重。例如:虽然当前空闲显存有 1G,但是它们分散在很多个小的空闲块中,如果此时有一个 1G 的显存申请无法满足,就会触发碎片整理操作,对性能造成巨大影响。
对于这个问题,我们提出了三种可能的优化:
- 参数原地更新
之前在 MegEngine 中很少有 inplace 的操作,如果模型本身参数特别巨大,每次更新参数就相当于移动了一个巨大的 tensor 的位置,可能产生出更多的碎片。解决方案是打开 INPLACE_UPDATE 的环境变量,原地更新这些参数,可以减少部分碎片。
- 改进估价函数
我们对 DTR 的启发式估价函数做了一个小小的改进,引入了一些碎片相关的信息,希望换出的 tensor 除了自己占用的显存越大越好之外,还希望它在显存中两端的空闲显存块大小之和越大越好。
$$ f(t)=\frac{\text{计算耗时}^\alpha}{\text{停留时长}^\beta(\text{显存+空闲段大小})^\gamma}\delta^{\text{重计算次数}} $$
此外我们还引入了重计算次数这一惩罚系数,希望每个算子被重算的次数尽量均匀。以及对于函数中的四个属性,增设了一些超参数,这样我们可以通过改变这些超参数来使启发式策略侧重于不同的属性。
- 静态规划策略
一个更有效的方法就是对于每轮的执行序列都相同的网络,我们把它看作是静态图,把网络静态化,就可以运用静态的显存分配,不仅完全避免碎片整理,还可以显著降低显存峰值,去尝试更大的 batch size。
比如下图在 ResNet-50 上,batchsize=400 时,动态分配显存的峰值为 9595MB,静态分配显存的峰值为 8549MB,降低了 10% 左右。一旦静态分配显存之后,碎片问题再也不会产生。

四、未来工作方向
如果想要彻底发挥出重计算的能力——训练出更大的模型和尽可能大的 batch size,一种可能的方法是侧重于模型的静态化。因为动态图虽然非常好写,但是在 batch size 较大时,受碎片问题的影响比较大;在静态图上,可以享受到所有静态图优化的好处,比如静态显存分配、图优化技术等等。
更宏观地,我们希望抽象出一套同时适用于静态图和动态图的显存优化策略,如下图所示:

不论是静态图的 Sublinear 优化还是动态图的 DTR 优化,都可以看作是对执行序列做了一个 Seq2Seq 的变换——在序列中加入了一些 drop 和 recompute 语句。区别在于,静态图是获得了整个运行序列后,计算最优的释放和重计算序列;动态图则是在解释执行序列的过程中,当场插入 drop 和 recompute 语句。执行序列有两种方式:动态图 Imperative Runtime 解释执行和静态图 Computing Graph 编译执行。Profile 会在实际运行中,记录每个算子的运行时间、每个 tensor 在显存中停留的时长等运行时信息,之后用户可以根据 profile 的结果去调整计算序列。这样用户不需要了解底层的执行逻辑,也不用修改框架的源代码就可以针对不同的模型定制策略。
参考文献:
[1] Kirisame M, Lyubomirsky S, Haan A, et al. Dynamic tensor rematerialization[J]. arXiv preprint arXiv:2006.09616, 2020.
附:
GitHub:MegEngine 天元
官网:MegEngine-深度学习,简单开发
欢迎小伙伴加入我们 MegEngine 技术交流 QQ 群:1029741705