我们使用Redis的时候往往都是主从模式或者集群架构,不会使用单台Redis服务。
一、Redis主从配置实战
我们使用master节点写输入,然后将数据同步到slave节点,从节点可以提供读取或者备份的功能,分担master节点压力。

redis主从架构搭建,配置从节点步骤
1、 复制一份redis.conf文件为redis-6380.conf
cp ./redis.conf ./conf/redis-6380.conf
2、打开redis-6380.conf配置文件,将相关配置修改为如下值:
port 6380 pidfile /var/run/redis_6380.pid # 把pid进程号写入pidfile配置的文件 logfile "6380.log" dir /usr/local/redis‐5.0.3/data/6380 # 指定数据存放目录 # 需要注释掉bind # bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
3、在redis-6380.conf中配置主从复制
replicaof 192.168.0.60 6379 # 从本机6379的redis实例复制数据,Redis 5.0之前使用slaveof. 这里的IP是redis服务IP replica‐read‐only yes # 配置从节点只读
注意: 如果的时候发现从节点中始终是空,即没有同步到主节点的数据,可能是192.168.0.60的设置问题,如果是主从都在一台服务器上,可以试试改成127.0.0.1.
4、启动从节点
注意一下命令,我这里是相对路径。
./src/redis-server ./conf/redis-6380.conf
然后我们查看redis服务实例,发现6379和6380都已经启动了。

5、连接从节点
[root@localhost redis-6.2.3]# ./src/redis-cli -p 6380 127.0.0.1:6380>
查看是否同步了数据:
127.0.0.1:6380> keys * 1) "test3" 2) "tul2" 3) "tul" 4) "tul3" 5) "test1" 6) "yaolao" 7) "test2" 127.0.0.1:6380>
注意: 如果的时候发现从节点中始终是空,即没有同步到主节点的数据,可能是192.168.0.60的设置问题,如果是主从都在一台服务器上,可以试试改成127.0.0.1试试。、
6、测试在6379实例上写数据,6380实例是否能及时同步新修改数据
7、可以自己再配置一个6381的从节点
至此。,我们的主从配置就完成了。我们可以自己去配置多个从节点。
二、主从实现原理
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC命令给master请求复制数据。
master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中。当持久化进行完毕以后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后再加载到内存中。然后,master再将之前缓存在内存中的命令发送给slave。
当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多
个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送
给多个并发连接的slave。
主从复制(全量复制)流程图

psync命令是redis底层的C语言实现的。
数据部分复制
当master和slave断开重连后,一般都会对整份数据进行复制。但从redis2.8版本开始,redis改用可以支持部分数据复制的命令PSYNC去master同步数据,slave与master能够在网络连接断开重连后只进行部分数据复制(断点续传)。
master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的slave都维护了复制的数据下标offset和master的进程id,因此,当网络连接断开后,slave会请求master继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
主从复制(部分复制,断点续传)流程图:
如果slave节点挂了之后,只想同步新增的数据(不需要同步全部)。
最新的命令redis会写到repl backlog buffer(默认大小是1MB)这个缓冲区中。

offset是偏移量,即上次复制产生的偏移量,再一次复制新的数据的时候只需要从这个偏移量后面开始复制即可。注意,这种只适合几分钟之内的。
如果从缓冲区没有找到传过来的这个偏移量,说明从节点可能挂了非常久的时间,这时候需要做全量复制,而不是断点续传了。
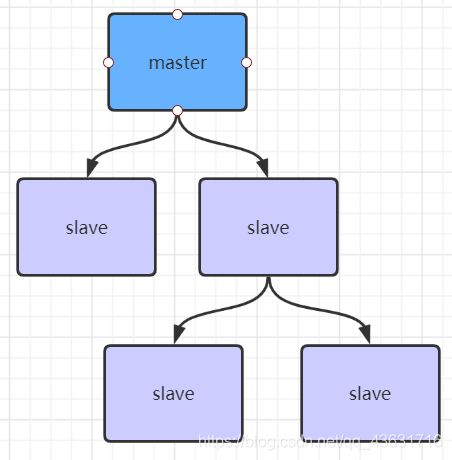
缓解主从复制风暴
如果有很多从节点,为了缓解主从复制风暴(多个从节点同时复制主节点导致主节点压力过大),可以做如下架构,让部分从节点与从节点(与主节点同步)同步数据,即配置主从的ip地址可以写某个从节点的,而不是都写mast节点的IP.
到此这篇关于Redis主从配置和底层实现原理解析(实战记录)的文章就介绍到这了,更多相关Redis主从配置内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!