深入理解JVM - 分区是如何溢出的?
前言
JVM运行时分区溢出学习JVM必须掌握的一块内容,同时由于JVM的升级换代,JVM的内部分区也在逐渐的变化,比如方法区的实现由永久代改为了元空间这些内容都是需要掌握的,这一节将会是一篇关于JVM分区的总结,同样根据两个案例来说下如何排查JVM令人头痛的OOM问题。
前文回顾:
上一期主要是对JVM调优以及工具的使用做了一个专栏的阶段总结,这里不再赘述,可以看个人主页的历史文章。
概述:
- 用图解的方式了解哪些分区会存在分区溢出的问题。
- 如何用代码来模拟出各个分区的溢出。
- 用两个案例来讲解分区的溢出是如何排查和解决的。
分区结构图简介:
在了解分区是如何溢出之前,这里先简单画一个JVM的分区运行图:
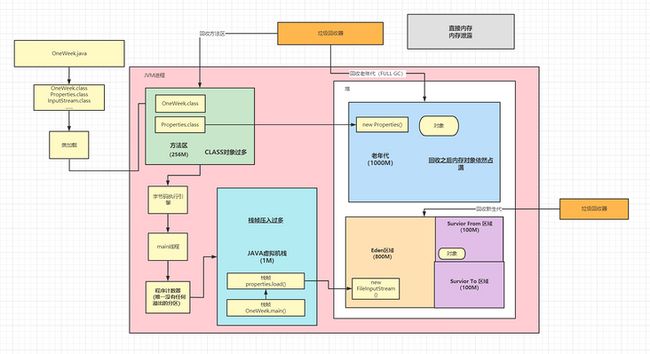
其实这一段代码在专栏开篇已经讲过,这里直接挪用过来,同时标记了会出现溢出的分区,上面的图对应下面这一段代码:
public class OneWeek {
private static final Properties properties = new Properties();
public static void main(String[] args) throws IOException {
InputStream resourceAsStream = OneWeek.class.getClassLoader().getResourceAsStream("app.properties");
properties.load(resourceAsStream);
System.out.println("load properties user.name = " + properties.getProperty("user.name"));
}
} 代码非常简单,当然和本文没有什么关系,这里直接跳过。
我们可以看到,容易出现方法区溢出的地方通常是这三个:方法区,JAVA虚拟机栈和JAVA堆(准确来说是老年代溢出)。这三个分区的溢出也是日常写代码当中很容易出现溢出的情况,结构图的最上方还有一个直接内存,因为这块空间平时可能用不上但是很容易出问题所以也放进来讲解,下面逐个分析他们发生溢出会出现什么情况:
方法区:由于现代框架普遍使用动态代理+反射,所以方法区通常会产生很多的代理对象,虽然多数情况下spring的bean都是单例的通常不会产生影响,但是遇到一些需要创建大量非单例对象情况(比如并发问题)下就很容易出现方法区的溢出。
虚拟机栈:这里看到上面的结构图可能会想1M是不是也太小了?其实每一个分配1M对于绝大多数情况下完全够用了,让虚拟机栈溢出也比较简单, 那就是死循环或者无限递归,下文会用代码进行演示。
堆:用的最多的分区也是最容易出问题的一个分区,堆内存需要配合垃圾收集器一起进行工作,通常情况下堆溢出是由于老年代回收之后还是有很多对象(占满),导致对象无法再继续分配而产生OOM的异常。
直接内存:由于篇幅有限直接内存是什么东东请同学们自行百度,这一块空间多数和Netty以及NIO等工具打交道的时候会有机会使用到,在这里重点解释下这块区域怎么溢出,只要记住当JVM申请不到足够的Direct Memory的时候就会造成直接内存的溢出。
会发生溢出的分区都已经被我们找出来了,下面就来介绍一下各自的分区是如何用代码来模拟溢出的。
分区溢出模拟:
方法区:
首先是方法区的空间溢出,这里不介绍过多的概念,上一节也提到了方法区多数情况下是由于动态生成类过多导致方法区产生了溢出,下面用一段代码来模拟:
建立项目的步骤这里省略,直接使用IDE简单生成一个Maven的项目即可,首先我们再Pom.xml文件中导入CGLIB的依赖,不清楚这个CGLIB是什么也没关系,只要简单理解为可以帮助我们生产动态JAVA类的工具即可,即可以不使用手动new的形式实现一个对象的构建:
cglib
cglib
3.3.0
下面是具体的测试代码:
public class CglibTest {
static class Man {
public void run() {
System.out.println("走路中。。。。。");
}
}
public static void main(String[] args) {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Man.class);
enhancer.setUseCache(true);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
if(method.getName().equalsIgnoreCase("run")){
System.out.println("遇到红绿灯,等待.....");
return methodProxy.invokeSuper(o, objects);
}
return methodProxy.invokeSuper(o, objects);
}
});
Man man = (Man) enhancer.create();
man.run();
}
}
} 这里简单解读一下代码:
在代码的第一句,使用while(true)语句构建一个死循环,让内部的代码不断的循环工作。接着我们首先使用下面这段代码初始化一个生成类的API对象,同时设置生成的类的super类是Man.class,也就是说我们只能生产Man这个类的超类,同时我们开启对象缓存,至于有什么作用无需关注。
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Man.class);
enhancer.setUseCache(true); 接着我们用回调的匿名钩子函数,在方法调用之间增加一个拦截方法,在这里我们做的事情是匹配到run方法的调用的对象之前做一些我们自定义的操作,比如像下面这样增加一条打印语句:
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
if(method.getName().equalsIgnoreCase("run")){
System.out.println("遇到红绿灯,等待.....");
return methodProxy.invokeSuper(o, objects);
}
return methodProxy.invokeSuper(o, objects);
}
}); 接着GCLIB就会通过JDK的动态代理构建代理对象并且完成方法的调用。
既然这里可以对于Man对象的方法进行拦截,那对他的子类当然也是同样适用的,我们可以增加一个新的类继承Man类,比如像下面这样:
static class OldMan extends Man{
@Override
public void run() {
System.out.println("走的很慢很慢。。。。。。。");
}
} 然后我们在死循环的结尾增加下面的代码:
OldMan oldMan = (OldMan) enhancer.create();
oldMan.run(); 紧接着,我们就可以开始运行代码了,然后,然后你会发现程序报错了。。。。。。错误内容如下:
遇到红绿灯,等待.....
走路中。。。。。
Exception in thread "main" java.lang.ClassCastException: com.xd.test.jvm.CglibTest$Man$$EnhancerByCGLIB$$ba733242 cannot be cast to com.xd.test.jvm.CglibTest$OldMan
at com.xd.test.jvm.CglibTest.main(CglibTest.java:50) 这里其实是类强制转换的异常,我们不能把一个动态生成的代理父类转为一个代理的子类,这里要改成下面的格式,利用多态的特性把superclass设置为Man子类即可:
enhancer.setSuperclass(OldMan.class);限制方法区大小:
重点来了,现在我们限制一下方法区的大小,这里使用了JDK8的版本,参数和JDK8以下的参数不一样,由于JDK8使用了元空间,我们需要使用下面的参数来进行元空间的大小设置:
-XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m 注意MetaspaceSize这个值不是初始化元空间大小哦,而是初次触发元空间扩展的大小,而MaxMetaspaceSize才是元空间真正允许扩展的最大大小,虽然默认设置下这两个参数的值都很小,但是JVM会在每次FULL GC之后自动扩大元空间,理论上来说可以无限接近于系统内存的大小,但是毫无疑问JVM会有限制,在扩展到一定程度之后会直接让方法区溢出,所以在这里这两个参数我们设置为一样的大小即可。
接着运行代码,不需要多长时间,控制台就会爆出如下的提示,告诉我们方法去区溢出了:
Caused by: java.lang.OutOfMemoryError: Metaspace 以上便是方法区的溢出测试。
虚拟机栈:
虚拟机栈的溢出是最简单的,这里直接上代码演示一下:
首先我们需要设置一下栈内存大小,这里我们为每个线程分配1M的栈内存大小:
-XX:ThreadStackSize=1M 接着使用下面的代码跑一下,代码内容十分简单就是一个单纯的无限递归调用的代码:
public static void main(String[] args) {
int count = 0;
work(count);
}
public static void work(int count){
System.out.println("一共运行了:"+ (count++) +"次");
work(count);
} 运行结果如下,从个人电脑来看运行了6000多次:
一共运行了:6466次
一共运行了:6467次
一共运行了:6468次
一共运行了:6469次
一共运行了:6470次
一共运行了:6471次
java.lang.StackOverflowError
at sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:691)
at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:579)
at sun.nio.cs.StreamEncoder.implWrite(StreamEncoder.java:271)
at sun.nio.cs.StreamEncoder.write(StreamEncoder.java:125)
at java.io.OutputStreamWriter.write(OutputStreamWriter.java:207)
at java.io.BufferedWriter.flushBuffer(BufferedWriter.java:129)
at java.io.PrintStream.write(PrintStream.java:526)
at java.io.PrintStream.print(PrintStream.java:669)
at java.io.PrintStream.println(PrintStream.java:806) 栈内存的溢出比较好理解,多数情况下是由于编程引发的错误,比如循环调用,无限递归调用等等,栈内存溢出的情况比较罕见的,一般是开发人员编程错误(这里也不用担心正常方法调用链过长的可能性)。
栈的溢出也可以形象理解为往一个纸箱里面放书,当书放不进纸箱的时候,系统只能报错了,另外特别注意栈帧弹出虚拟机栈之后变量是直接销毁的,所以不存在垃圾回收这一个概念,再次强调,虚拟机栈和垃圾回收器没有半毛钱关系。
堆内存:
堆内存的溢出模拟测试也比较简单,就是不断创建 无法被垃圾回收器回收的对象,比如说大字符串,或者占用很多内存的数组,最简单的办法就是分配一个一次性无法容纳下的超大数组,是不是非常简单?下面同样演示一段代码进行讲解:
同样,我们需要先给堆空间限制一下大小,使用-Xms20M -Xmx20M 来限制一下堆内存的大小,然后编写下面的代码并且执行:
public class Test {
public static void main(String[] args) {
byte[] arr = new byte[1024*1024*20];
}
} 运行代码,会获得下面的结果:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at Test.main(Test.java:11) 上面是模拟溢出的一种最简单的办法,更多的溢出这里不再过多讨论,下面我们来看下一个重点:真实场景下如何排查TOMCAT溢出问题?
如何排查分区溢出问题?
Tomcat出现OOM如何排查?
在这个案例中,一个每秒仅仅只有100+请求的系统却频繁的因为OOM而崩溃,下面会一步步排查一个这样的问题是如何牵扯到Tomcat和分区溢出扯上关系的。
还原案发现场:
首先,我们需要还原案发现场,在某一天系统突然收到报警,通知说线上系统出了问题。于是排查异常信息,这时候第一件事情是跑到线上看一下日志的结果,结果非常惊讶的发现报错信息如下:
Exception in thread "http-nio-8080-exec-1089" java.lang.OutOfMemoryError: Java heap space 这一段和上面模拟的代码结果非常类似,不同的是这个线程是一个Tomcat的线程,当然这个消息非常不好,因为线上居然发生了OOM!这是一个非常严重的BUG。下面来看下是如何一步步进行排查的。
简单了解Tomcat的底层原理
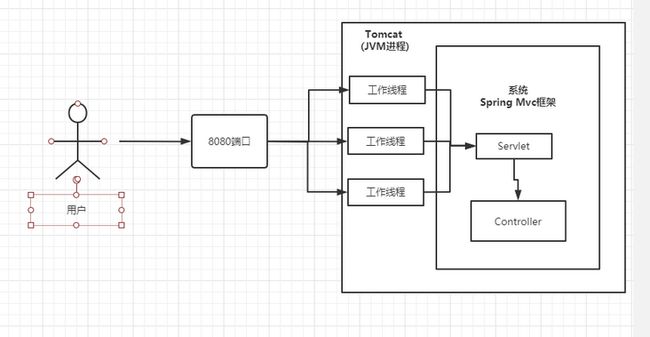
首先我们来简单了解一下Tomcat这种web服务器的工作原理是什么呢?其实学了JVM之后,对这个概念应该有了更深入的了解,毫无疑问就是底层依然还是一个JVM的进程,通常情况下,我们使用Tomcat都会绑定一个8080的端口启动,Tomcat在最开始的时候请求是通过一个叫做Servlet的东西进行处理的,而这个Servlet在后来经过框架的包装就变成了spring mvc的一个mapping,到后续随着框架的演进,现在通常都会使用框架比如说spring boot内置的Tomcat进行web服务器的管理,我们不再需要单独的Tomcat进行项目部署操作,直接集成式一键启动即可。
那么我们的请求是如何被Tomcat解析的呢?Tomcat通过监听端口并把我们发送过来的网络请求经过解析的和处理,然后再传给MVC的进行包装分发,最后到具体的某一个映射(Mapping),整个业务过程其实就是Tomcat把我们写好的类(controller)通过他的类加载器加载到Tomcat的内部进行执行,执行完成之后再结果返回给请求发送方。
那么tomcat是如何监听端口的呢?其实tomcat本身就是一个工作线程,对于我们的每一个请求,tomcat的工作线程都会从自己管理的线程池中分配一个工作线程来负责进行处理,也就是说多个请求之前是相互独立并且互不干扰的。为了更好的理解,下面画了图来简单解释一下上文描述的工作机制:
小贴士:
建议在JVM调优的时候务必加上此参数:
-XX:+HeapDumpOnOutOfMemoryError。一旦出现OOM等内存溢出的情况时候,JVM会从内存中备份一份当前的溢出日志,根据日志也可以很快的定位到问题发生的点以及产生了什么问题。
内存快照分析:
言归正传,这里再次回到案例来,这里省略具体的分析步骤,最后通过内存快照的结果发现,导致内存泄露的居然是数组,从日志的分析结果中发现了如下的内容:
byte[10008192] @ 0x7aa800000 GET /order/v2 HTTP/1.0-forward...
byte[10008192] @ 0x7aa800000 GET /order/v2 HTTP/1.0-forward...
byte[10008192] @ 0x7aa800000 GET /order/v2 HTTP/1.0-forward...
byte[10008192] @ 0x7aa800000 GET /order/v2 HTTP/1.0-forward... 就是类似这样的byte数组,在每一次调用的时候,都产生了大概10M左右大小的数组,最终由于几百次的调用的同时这些数组对象 并不能回收掉,最终导致了内存的溢出。
这时候你可能会认为有人要来背锅了,然而工程师断定代码泄露不是个人编写的代码导致的。接着我们继续思考,不是开发人员造成的,排查代码确实没有看到明显会导致溢出的点,那么这是怎么回事呢?
进一步排查,发现是有一个对象存在长期的占用那就是:org.apache.tomcat.util.threads.TaskThread,从包名字就可以知道是Tomcat自己的线程,这意味着Tomcat在这个线程当中创建了数组并且没有被回收。
既然数组没有被回收也就意味着工作线程还在执行任务,按理来说工作线程执行任务通常都是很快就会完成的,为什么TaskThread会长期等待呢?这里再通过测试和分析发现每一个工作线程居然停留了4秒以上,我们都知道通常情况下一个请求都是在一秒以内完成的,而这里的线程居然停留了长达4秒,这里是一个问题点,另外这里还发现每一个工作线程就创建了2个10M的数组,导致数组也因为还在使用而无法释放,所以这里2个10M的数组又是怎么来的?这是第二个问题点,
通过配置文件的查找发现了下面的内容:
max-http-header-size: 10000000 就是这个东西导致了每次Http请求都会创建20M的数组内容。
这里小结一下上面的内容,其实就是说每一个工作线程都创建一个20M数组,意味着100个工作线程就是2000M的大小,并且2000M还无法回收。按照这个速度累积,一旦请求过多JVM就会立马崩溃。
解决问题:
既然知道了是工作线程的问题,那么接下来就要着手解决为什么线程会停留4秒以上以及这个20M数组的来源,在接下来的排查中还发现日志中还有如下的内容:
Timeout Exception.... 日志大致内容就是RPC的请求出现了大量的连接超时,而连接超时的时间刚好是4秒!通过询问发现原来工程师设置了RPC的超时时间刚好也是4秒,真相大白了!在每一次的工作线程执行代码的时候,都会执行一次RPC的远程调用,而当RPC服务挂掉的时候,此时由于连接远程服务器迟迟得不到响应导致系统需要等待4秒才会释放线程,在等待的时候工作线程会占用这个请求的资源并且卡死在线程上等待结果,如果在同一时间有很多的请求就会出现百来个工作线程挂在自己的线程卡死并且等待响应的结果,最终由于堆内存占用过多的数组对象,无法再分配新的对象导致OOM!
知道了问题,下一步就是解决问题了,这里解决办法也比较简单,首先我们需要把超时的时间设置为1S,一旦RPC连接时间超过1S就立马释放资源,防止工作线程出现远程调用的长时间等待占用资源的问题,另外就是max-http-header-size这个参数可以适当的调整小一点,这样在每次调用的时候就不需要占用过大的数组导致资源利用紧张的问题了。
RPC通信框架导致的内存溢出:
问题情况:
- A服务器进行了升级之后,B的远程服务器宕机了,查看日志发现了OOM的异常
- 出现了超过4G的数组分配动作,由于JVM的堆不可能放下这种对象,直接导致了OOM
- 发现这个对象是RPC内部使用的通信对象构建出来的数组。
案发现场:
系统上有两个服务,服务A和服务B,服务A和服务B之间使用RPC的通信方式,同时使用的序列化协议是ProtoBuf,在通信协议上统一封装的对象格式这里假设使用的是Request,同时在远程调用的时候序列化和反序列化的封装和解析都是自定义的,接着我们在拓展一下细节:
- 首先在请求服务A的时候,需要对传输过来的对象进行序列化,这个序列化就是类似于把你的对象转为一个byte[]数组(字节流)
- 服务A接受请求并且通过RPC发送到远程服务器B之后,使用RPC通信规则对内容进行序列化转为byte[],服务B接受之后使用反序列化把byte[]数组进行反序列化,拿到对象的内容进行逻辑处理。
- 这两个服务之间遵循了自定义的Request的对象格式进行通信,保证序列化和反序列化之后的对象格式和内容一致。
那么问题是什么呢,问题很奇怪,当服务A进行升级之后,部署上去没有几分钟,发现服务B挂了!很奇怪,明明改的是服务A却是服务B挂了,经过日志分析,发现也是Byte[]数组太大导致溢出,这里阅读日志之后发现,居然分配了一个4G的数组......
RPC类的框架规则
这里先不急着说明产生问题的原因,我们先补充一下RPC框架的通信规则理论:
一个RPC 的通信框架大致过程:试想一下为了让服务A的所有请求在远程服务B接受之后都能够处理,服务器两边的RPC框架肯定是要对所有的请求对象做统一规范的,比如RPC使用了ProtoBuf作为序列化的协议标准,同时使用固定的对象格式对于对象数据进行序列化和反序列化操作,这里假设服务A序列化使用Request对象进行定制序列化之后发送到服务B,而服务B自然需要使用对应的Request将服务A传来的序列化对象来反序列化。
这里就有一个问题了,如果服务A改动了Request对象的定制格式,比如通信使用Request A+C被序列化之后发送的到服务B了,服务B按照之前的Request解开之后发现自己解不开对象,于是会创建一个byte[] 数组来存放序列化的数据,让客户端自己去完成反序列化的操作。
排查结果:
排查的结果就是服务A改了Request而m没有通知服务B修改对应的对象,导致反序列化失败并且新建了一个Byte[]数组来存放序列化的数据,而这个数组默认值刚刚好就设置了4G的大小!为什么要设置这么大的数组?开发人员说怕数组过小放不下,所以构建了一个4G的数组,保证无论A服务发送的对象如何大也不会影响到B。
解决问题:
很简单只要把这个反序列化失败之后创建数组的大小改小一点就行了,改成4M的大小基本足够应付大部分的情况。
总结
这一节主要讲述了分区的问题以及实际的案例中分区溢出的问题是如何排查的,可以看到虽然我们都十分清楚分区溢出是什么情况,但是到实际的案例中进行排查却又是五花八门的问题出现,希望通过案例讲解让更多的同学可以了解到JVM是如何进行问题排查,同时这里也可以发现,平时还是需要对于底层基础知识进行多积累,很多时候并不是学到的东西用不上,而是到了用上的时候你没学。所以平时多磨练一下自己的脑袋,遇到问题才不会手足无措。
写在最后:
不知道为什么时候在方法区的溢出实际运行测试的时候个人的笔记本电脑死活不能溢出,即使设置了参数也是方法区不断的溢出,难道是我是AMD的CPU的问题???
往期回顾:
注意这里使用的是“有道云笔记”的链接,方便大家收藏和自我总结: