顺序预读(prefetch,在Linux中也称为预读,read ahead)是一种用于提升顺序读性能的技术,用于缩小存储设备和应用程序之间巨大的效率差距。Linux内核在通用预读框架中执行顺序文件预读,它主动拦截VFS层中的文件读取请求,并将顺序的请求转换为异步预读请求,为即将到来的请求引入数据块,并在大块中进行。
I/O预读背景
带宽和延迟是I/O性能的两个主要衡量标准。对于这两个标准,在磁盘、内存和处理器之间存在着巨大的性能差距。例如,当今的DDR5内存的理论带宽通常为40GB/s以上,响应时间为纳秒级,而一个希捷(R) 7200转SATA磁盘的最大持续传输速率为200MB/s,平均寻道时间为5ms。两者之间存在的性能差距,带宽相差数百倍,延迟相差10^7倍。
I/O延迟是影响磁盘I/O性能的一个主要因素,可以用一个简单的I/O模型来近似。典型的磁盘I/O有两个步骤:首先,磁头移动到数据轨道,等待数据扇区在其下旋转;其次,开始数据读取和传输。相应的有两个操作时间:平均访问时间,典型值为8ms;数据传输时间,大致等于I/O大小和磁盘持续传输速率的乘积,对于目前的普通磁盘(HDD),平均传输速率为200MB/s。
在一个完整的I/O周期中,只有数据传输时间才能真正利用磁盘数据通道。I/O大小越大,在数据传输上花费的时间就越多,相对来说,在搜索上浪费的时间就越少,因此我们可以获得更多的磁盘利用率和I/O带宽。下图反映了上述磁盘I/O模型和代表性参数值的相关性。I/O预读的主要目的是将图中磁盘的工作点从左向右移动,从而获得更好的I/O带宽。

使用较大的I/O大小可以更好地利用磁盘
随着数字信息的激增,提前读算法仍然在继续发挥重要作用。固态磁盘极大地减少了耗时的寻道时间,但是仍然存在不小的访问延迟。特别是SSD存储器基本上是由许多并行操作的芯片组成,较大的预读I/O将能够利用并行芯片的优势。从SSD存储获得完全性能所需的最佳I/O大小与旋转介质不同,并且因设备而异。因此,即使是在SSD上,I/O预读也很关键。
总之,有顺序访问模式的地方,就有I/O预读的市场。无论是基于机械磁盘还是固态磁盘。
I/O优化和预读
从应用角度,目前业界有四种基本的I/O优化策略:
避免从存储设备上IO。最好的选择是完全避免或尽可能减少存储介质访问频率。这可以通过文件内存缓存来实现。预读擅长于将小的读请求转换为大的读请求,这有效地减少了存储介质访问的数量,从而降低了高昂的查找成本。具体的例子是众所周知的Linux VFS(虚拟文件系统)挂载选项noatime和relatime,用于消除由mtime更新触发的不必要的向存储设备的写操作。
顺序化。顺序访问能支持顺序预读并最大化磁盘性能利用率。对于并发顺序访问,预读在将交错的小I/O聚合为大I/O方面起着至关重要的作用。对于非顺序访问,通过使用智能磁盘布局管理、通知式预读、I/O排队和调度等技术,将磁盘寻址延迟最小化。举几个通过顺序化进行性能优化的例子:SCSI磁盘的TCQ(标记命令队列)和SATA磁盘的NCQ(本机命令队列);ext4/xfs的延迟分配和预分配;xfs中的回写集群等。
异步化。异步访问通过流水线化处理器和磁盘操作,隐藏应用程序的I/O延迟的方式来提高I/O效率。AIO、非阻塞I/O、回写和预读是异步I/O的常用工具。
并行化。聚合多个磁盘的容量和带宽可提升整体IO性能已经是分布式存储的共识。在传统的RAID层之外,以zfs和btrfs为例的新兴文件系统可以自己管理大型磁盘池。另一方面,在SSD内部使用了设备级并发处理。例如,英特尔在其SATA固态硬盘中开辟了10个并行的NAND闪存通道,可提供高达500MB/s的读取带宽和50000以上的 IOPS。并发I/O请求和并行数据传输是上述并行系统的I/O吞吐量的关键。主动预读在这个领域中扮演着重要的角色:它们通常需要大型的异步预读I/O来填充并行数据通道。
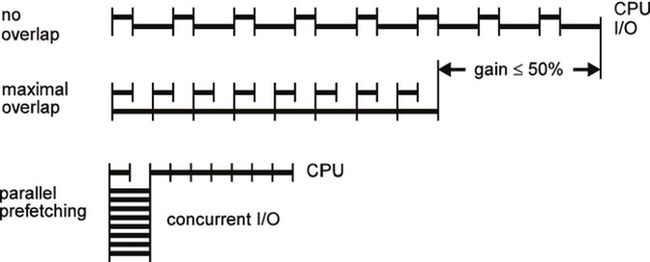
预读有助于实现I/O异步和并行
显然,预读在四种I/O优化策略中都扮演着重要的角色。预读可以为应用程序、存储设备和存储池,甚至处理器资源带来性能改善。通过屏蔽较高的I/O延迟,应用程序可以运行得更快更流畅。大块I/O可以更好地利用磁盘,可以更好地并行化,也有助于摊薄整个I/O路径的处理开销。
预读的基本方法
预读算法可以是预测式的,也可以是应用主动通知式的。预测式算法试图基于过去的I/O预测未来将被访问的I/O块,自动自发地执行预读决策,对上层应用是透明的,这种方式对算法的要求较高,存在命中率的问题。最成功的一种做法是顺序预读,这一直是操作系统的标准实践。新型的预测式预读可以基于灵活的AI算法或统计,提升预读数据的命中率。
应用主动通知式预读,使用来自各个应用程序关于其未来I/O操作的提示,提示可以由应用程序显式地控制。
缓存是另一种普遍存在的性能优化技术。共享预读内存和缓存内存是一种常见的做法,这为预读和缓存之间的交互打开了大门。
预读的设计权衡
预读大小对I/O性能有很大影响,被认为是主要的预读参数。在确定预读大小值时,必须在吞吐量和延迟之间进行权衡。一般的指导原则是:预读的大小应该足够大,以提供良好的I/O吞吐量,但同时也要防止预读块过大,从而避免不必要的过长的I/O延迟。
不同的存储设备、磁盘阵列配置和工作负载具有不同的最佳预读IO大小。某些应用程序(如对I/O延迟不敏感),可以安全地使用较大的预读大小;其他应用可能对I/O延迟敏感,这时应该使用更保守的预读I/O大小。
除了吞吐量和延迟之间的权衡之外,预读命中率是另一个常见的设计考虑因素。为了保持较高的预读命中率,需要使用自适应预读大小。这是因为,即使我们确信应用程序正在进行顺序读取,我们也无法预知顺序读操作还会持续多久。例如,应用程序可能从头到尾读取一整个文件,而另一个应用程序只访问这个文件中的前两个page。
幸运的是,常见的I/O行为大多是可以推断的。首先,即将要读取的page数(不考虑文件结束的情况)和已访问的page数通常是正相关的。其次,读取的大小越大,重复的可能性就越大。因为较大的预读大小意味着研发人员要对预期的长时间预读进行优化。根据以上两条经验规则,可以估计当前访问模式重复的可能性,并据此计算自适应预读大小。
提高预读命中率是预读算法设计的一个主要目标。低命中率意味着内存和磁盘I/O资源的浪费,这样浪费是高昂和不可接受的。传统的预读算法倾向于只对严格的顺序读取进行预读。它们对预读大小采用保守策略,并采用顺序检测,以寻求较高的预读命中率。
然而,随着计算机硬件的快速发展,我们也面临着新的约束和要求。内存和磁盘的带宽和容量都有了很大的提高,但磁盘访问时间仍然很慢,并且越来越成为I/O瓶颈。因此,预读命中的好处就增加了,它增加了预读的重要性,意味着底层存储应该更主动地进行预读。
因此,即使牺牲一定的预读命中率,它也可以提高总体I/O性能。工作负载的预读命中率取决于IO模式识别和这种特定模式运行时长评估的准确性。
YRCloudFile Linux客户端预读
YRCloudFile Linux客户端预读,对接了Linux内核预读机制,专门针对顺序读的性能进行优化。
下图为用FIO测试工具,对小文件顺序读、大文件顺序读场景进行测试,在Linux客户端预读开启和关闭情况下,不同内核版本的不同性能表现。
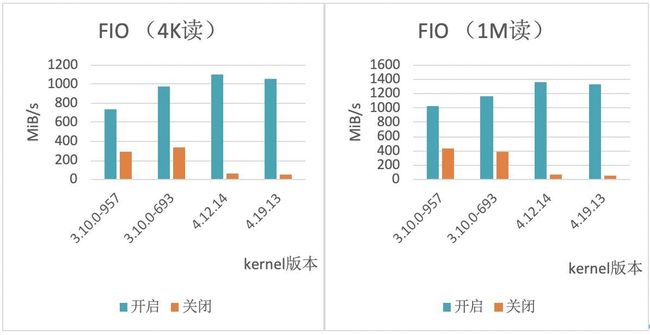
预读对4K/1M顺序读性能的影响
从实际测试数据看,YRCloudFile Linux客户端预读功能开启与否,在不同内核版本的下,顺序读性能提升2.5-20倍不等。
YRCloudFile Linux客户端预读机制很好地解决了文件顺序读速度慢、访问延迟高的问题,帮助AI应用,影视内容制作等应用轻松应对海量文件顺序读访问的性能挑战。
不可能有一种技术满足所有的需求,业务软件是单线程还是多线程、IO特点是一次写多次读还是不断追加写、是顺序读还是随机读等等。焱融技术团队通过不断的与客户的交流、碰撞,对不同场景,不同类型的应用进行分析,不断推出新的功能,让YRCloudFile更趋于成熟,帮助用户成就大数据与人工智能时代的企业核心竞争力。
参考资料
1. https://bootlin.com/pub/readahead/doc/ols2007-readahead-paper.pdf\
2. https://engineering.purdue.edu/~ychu/publications/tc07_pref.pdf\
3. https://pdfs.semanticscholar.org