ZNBase 是开放原子开源基金会旗下的首个分布式数据库项目,由浪潮大数据团队开源并捐赠。本文将介绍 ZNBase 的存储架构,以及 ZNBase 技术团队在其 KV 存储引擎基础上所做的优化实践。
ZNBase 整体存储架构
云溪数据库 ZNBase 采用分层架构,分为计算层与存储层,其总体架构如下图所示:

在 OLTP 场景下,当开发人员向集群发送 SQL 语句时,数据最终会以键值对 KV 的形式对存储层进行读写。每个 ZNBase 节点启动时,至少会包含一个存储节点。存储层默认采用 KV 存储引擎 RocksDB 负责存储数据。每个存储实例都可能包含多个 Range,Range 是最底层的 KV 数据单元。Range 使用 Raft 一致性协议在集群间进行复制。
为了支持 HTAP 场景,ZNBase 的行存数据会通过 Raft Learner 同步到列存引擎,存储层还扩展了矢量接口,通过列式存储、计算下推、多节点并行计算满足业务应用的 AP 需求。另外存储层还扩展了时序接口,可以进行时序数据管理。
接下来将着重介绍 ZNBase 存储层架构中的 KV 存储集群。
RocksDB 引擎
ZNBase 的存储层默认采用 RocksDB 来存储数据。RocksDB 是由 Facebook 开源的高性能 KV 存储引擎,读写数据可以是任意字节流,其官方架构如图所示,是一种 LSM-Tree 的实现:

RocksDB 写入流程如下:
1、以 batch 形式先顺序写入 WAL 文件用于故障恢复
2、再写入内存中的 Memtable,Memtable 默认以 SkipList 形式存储
3、Memtable 写满一定大小,默认 64MB,会转为不可变的 Immutable。
4、异步线程会将 Immutable 刷到磁盘 L0 层,变为 SST 文件。
5、磁盘中使用多层来管理 SST 文件,通过合并过程将上层的 SST 文件落到下层,在合并过程中会进行 GC 清理。
由此可见,RokcsDB 最新的数据是在内存或者上层的 SST 文件里,所以读取时优先读取 Memtable 和 Immutable,再依此读取各层文件。刚写入的热数据,可以更快被读到。另外 RocksDB 还提供了 Block Cache 进行读缓存。
RocksDB 本身是一个 LSM-Tree 架构的高速 KV 存储引擎,读写都会尽量使用内存。RocksDB 提供原子的批量写入、快照等功能,方便上层实现事务控制。基于 RocksDB 也支持高度安全的 AES 算法对存储在磁盘上的数据加密,这样即使磁盘被窃取,磁盘里的数据也无法被访问。
由于 RocksDB 采用 LSM-Tree 架构,同样也存在一定的问题。比如在大数据量下有比较高的读放大、写放大、空间放大,性能衰减也比较厉害。为了提高 ZNBase 在海量数据下的性能表现,ZNBase 团队结合浪潮的硬件优势,开发了使用 SPDK 驱动在专用硬件 ZNS SSD 上进行软硬件融合的存储引擎;另外为了更有效的利用内存,获得更快的读写速度,在大内存场景下也开发了准内存引擎的实现。
SPDK + ZNS SSD
固态硬盘(SSD)正在迅速扩展它在数据中心中的份额,相较于传统存储介质,新的闪存介质具有性能,耗电,机架空间等等方面的优势。
而浪潮自研的 ZNS SSD,在容量、寿命、成本、易用性、性能等方面实现飞跃式提升。ZNS SSD 即分区命名空间固态硬盘,可以将 FTL(Flash Translation Layer)暴露给用户以充分发挥 SSD 性能。ZNS 技术针对云场景应用,主适用于大容量空间存储的数据,例如高清视频、图像等。ZNBase 与 ZNS SSD 集成,通过智能数据部署可以实现更好的空间运⽤,获得降低一倍以上的写放大;文件可根据生命周期进行数据分区隔离,实现最低化垃圾回收;SST 文件可根据 LSM 分层进行清晰化冷热数据分离,提升访问效率;最小化的写放大可提升读取性能,减少合并成本和垃圾回收开销;理论上,ZNS SSD 可带来 15% 的性能提升和 10% 的成本收益。

由于 SSD 本身的物理特性,其数据的访问相较于传统介质来说已经非常快了,而性能的瓶颈就是出在计算机与设备连接的接口和协议上面。举个直观的例子,我们从北京乘飞机到美国,按照现在的飞行速度,在天上需要 13 个小时。这种情况下,安检的时间,过海关的时间,候机的时间,加起来 3 个小时,相对于总共的 13+3=16 个小时也不算长。设想如果现在飞机的飞行速度提高了 100 倍,飞行时间从 13 小时缩短至 10 分钟,这时 3 个小时的地面手续流程就显得很没有效率了。换言之,在存储硬件性能高速发展的今天,存储软件协议栈的性能和效率在存储整体系统中的地位越来越重要。
SPDK ( Storage performance development kit ) 由 Intel 发起,提供了一组用于编写高性能、可伸缩、用户态存储应用程序的工具和库。SPDK 的基础是用户态、轮询、异步、无锁 NVMe 驱动,提供了从用户空间应用程序到 NVMe 设备的零拷贝、高度并行的访问。
NVMe 的全称是 Non-Volatile Memory Express,如果翻译过来就是非易失性内存主机控制器接口规范,是一种新型的存储设备接口规范,用于定义硬件接口和传输协议,拥有比传统 SATA SSD 的 AHCI 标准更高的读写性能。我们可以把 NVMe 看做一个硬件进步推动软件革新需求的例子,随着后续更快的存储介质投入市场,这种推动力将更为急迫。
SPDK 项目也是一种硬件进步推动软件革新的产物,其目标就是能够把硬件平台的计算、网络、存储的最新性能进展充分发挥出来。那么 SPDK 是如何工作的?它超高的性能实际上来自于两项核心技术:第一个是用户态运行,第二个是轮询模式驱动。
首先,将设备驱动代码运行在用户态,是和运行在“内核态”相对而言的。把设备驱动移出内核空间避免了内核上下文切换与中断处理,从而节省了大量的 CPU 负担,允许更多的指令周期用在实际处理数据存储的工作上。无论存储算法复杂还是简单,也无论进行去重(deduplication),加密(encryption),压缩(compression),还是简单的块读写,更少的指令周期浪费意味着更好的整体性能。
其次,传统的中断式 IO 处理模式,采用的是被动的派发式工作,有 IO 需要处理时就请求一个中断,CPU 收到中断后才进行资源调度来处理 IO。举一个出租车的例子做类比,传统磁盘设备的 IO 任务就像出租车乘客,CPU 资源被调度用来处理 IO 中断就像出租车。当磁盘速度远慢于CPU 时,CPU 中断处理资源充沛,中断机制是能对这些 IO 任务应对自如的。这就好比是非高峰时段,出租车供大于求,路上总是有空车在扫马路,乘客随时都能叫到车。然而,在高峰时段,比如周五傍晚在闹市区叫车(不用滴滴或者专车),常常是看到一辆车溜溜的近前来,而后却发现后座已经有乘客了。需要等待多久,往往是不可预知的。相信你一定见过在路边滞留,招手拦车的人群。同样,当硬盘速度上千倍的提高后,将随之产生大量 IO 中断,Linux 内核的中断驱动式 IO 处理(Interrupt Driven IO Process)就显得效率不高了。
而在轮询模式驱动下,数据包和块得到迅速派发,等待时间最小化,从而达到低延时、更一致的延时(抖动变少)、更好的吞吐量的效果。
当然,轮询模式驱动并不是在所有的情况下都是最高效的 IO 处理方式。对于低速的 SATA HDD,PMD 的处理机制不但给 IO 性能带来的提升不明显,反而浪费了 CPU 资源。
准内存引擎
除了采用 SPDK+ZNSSD 软硬件结合的存储引擎以外,为了更有效的利用内存,获得更快的读写速度,ZNBase 在大内存场景下还开发了准内存引擎的实现。
准内存引擎开发的背景源自 RocksDB 的一些局限性:
1.WAL 的单线程写模式,不能充分发挥高速设备的性能优势;
2.读操作时,有可能需要查找 level 0 层的多个文件及其他层的文件,这也造成了很大的读放大。尤其是当纯随机写入后,读几乎是要查询 level0 层的所有文件,导致了读操作的低效。
3.针对第 2 点问题,RocksDB 中依据 level 0 层文件的个数来做前台写流控及后台合并触发,以此来平衡读写的性能。这又导致了性能抖动及不能发挥高速介质性能的问题。
4.合并流程难以控制,容易造成性能抖动及写放大。
近年来,随着动态随机存储器(DRAM)容量的上升和单位价格的下降,使大量数据在内存中的存储和处理成为可能。相对于磁盘,内存的数据读写速度要高出几个数量级,将数据保存在内存中相比从磁盘上访问能够极大地提高应用的性能。
针对这一理念,准内存引擎设计原则如下:
1.数据尽量存放在内存中,充分利用内存的读写性能。
2.基于索引与数据分离存储的思想,索引常驻内存。数据可以根据内存容量,将部分存储到持久化存储设备中。
3.提升 cpu cache 命中率,通过数据块的重构(拆解、扩容、缩容)将 Key 相邻的 KV 数据在内存空间中也相邻,以提升 key 值遍历的速度。
4.使用异步落盘机制,保证平滑的 IO 速率,消除 IO 瓶颈。
基于 ART 索引的检索机制,保证数据访问速度。ART 算法使用基于乐观锁的的同步机制,读操作不阻塞,写操作使用版本信息的 CAS 原子操作以及重试机制。
由于已通过 Raft Log 实现数据的故障恢复,可以去除 WAL 写入过程。
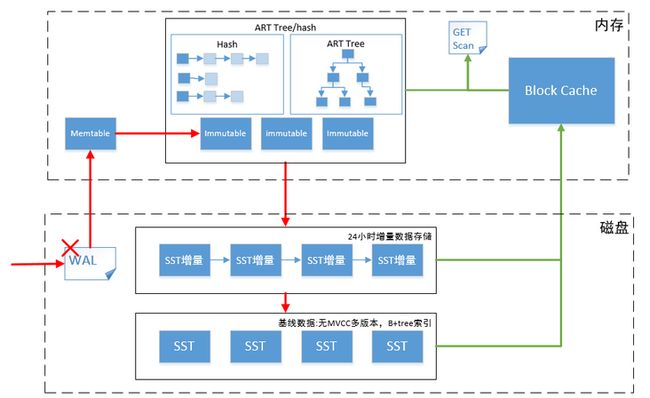
准内存引擎总体处理流程如下:
- 新插入的数据存放在 内存临时区中的 Memtable 以及 Immutable 中。
- 异步线程 Mem-Flush 将 Immutable 中的数据转存到内存存储区。
- 内存存储区会尽可能占用更多的内存空间,用于存放数据。使用 ART 算法索引这些数据。
- 内存存储区内存空间即将不足时,启用 L1-Flush 后台线程清理内存存储区中的数据。
- L1-Flush 后台线程,将该内存存储区中所有的 KV 数据以及范围删除数据进行落盘。由于数据量大且数据有序,因此,直接落盘到 L1 层。落盘前需要保证 L1 层无文件。落盘完成后,创建 L1 层文件向下合并的任务。
准内存引擎采用 ART 算法作为主索引的实现,可以进行快速的范围查找,辅助使用 Hash 索引方便进行 Get 查询。之所以使用 ART 算法,是因为其在读写方面性能均优于 B+树、红黑树、二叉树,可比肩哈希表,而 ART 算法比哈希表的优势是 ART 算法可按顺序遍历所有数据。

参见论文:The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases
总结
本文为大家介绍了 ZNBase 基于 RocksDB 的存储引擎架构,以及 ZNBase 团队针对 RocksDB 的局限性,通过开发软硬件结合的 SPDK+ZNS SSD 存储引擎、大内存场景下的准内存引擎,大大提高了存储引擎的读写性能。
关于 ZNBase 的更多详情可以查看:
官方代码仓库:https://gitee.com/ZNBase/zn-kvs
ZNBase 官网:http://www.znbase.com/
对相关技术或产品有任何问题欢迎提 issue 或在社区中留言讨论。同时欢迎广大对分布式数据库感兴趣的开发者共同参与 ZNBase 项目的建设。
联系邮箱:[email protected]