前言
编译优化的内容还是不少的,当然主要的内容集中在后端的编译上面,为了控制篇幅的长度所以这里选择拆分为上下两部分讲解,我们平时写的代码和实际运行时候的代码效果是完全不一样的,了解编译优化的细节是有必要的。
概述
- 了解javac的基本编译过程以及基本的处理细节
- 了解基本的前端优化手段:语法糖和泛型的实现
- 了解前后端编译的内容以及部分后端编译的内容。
Javac的编译过程
javac的工程代码并不属于java se api的一部分,同时由于jdk9的版本之后模块化被单独分离出来了,书中使用了jdk9的版本来讲解关于javac的编译过程。
准备工作
包所在的位置(jdk9):JDK_SRC_HOM E/src/jdk.comp iler/share/classes/com/sun/tools/javac
如果需要搭建一个javac的工程只要新建一个工程并且把下面路径的内容复制到工程的下面即可。
J D K SR C H O M E / l a n gt o o l s / s r c / s h a r e / c l a s s e s / c o m / s u n / *
拷贝完成之后,一个支持javac命令的工程就搭建好了
javac的编译步骤
关于javac的编译步骤基本如下,需要注意的是这里包含了jdk5版本中的注解处理器的内容:
- 准备:初始化插入式注解处理器
解析和填充符号表过程
- 词法分析
- 填充符号表
插入式注解处理器处理过程:
- 插入式注解处理器的执行阶段
分析与字节码生成(语法分析是IDE常用部分)
- 标注检查(数据分析,常量折叠优化)
- 数据流和数据分析(上下文语义分析检查)
- 解语法糖(由desagrc 方法触发)
- 字节码生成
下面是书中对于整个编译过程的一张图表演示,可以看到顺序不是固定的,而是会存在更换顺序的情况:

前端优化
注解处理器
注解处理器的步骤是在jdk5当中新增的内容,在Javac源码中,插入式注解处理器的初始化过程是在initPorcessAnnotations()方法中完成的,而它 的执行过程则是在processAnnotations()方法中完成。这个方法会判断是否还有新的注解处理器需要执 行 , 如 果 有 的 话 , 通 过 c o m . s u n . t o o l s . j a v a c . p r o c e s s i n g. J a v a c P r o c e s s i n g- E n v i r o n m e n t 类 的 d o P r o c e s s i n g( ) 方 法 来生成一个新的JavaComp iler对象,对编译的后续步骤进行处理。
语法糖
java 在升级的过程中引入了很多的语法糖写法, 比如jdk5的增强for循环和泛型,jdk7的泛型菱形标记和try-catch-resource,jdk8的lambada表达式等,这些语法糖对于jdk的易用性给予了很多支持。这里挑几个重点的升级进行描述:
泛型
泛型的启发来源于pizza的后身scala语言的作者Martin Odersky,当他捣鼓出泛型这个东西 之后,立马被java官方邀请开发java的泛型,可怜的Martin Odersky受制于java的语法限制以及向后兼容的特性,最后做出来的成果反而更加类似C#的泛型(挺讽刺的),最终的结果就到了现在java官方还在背着这个技术偷懒的债。
扯远了,泛型相信所有的java开发者都很熟悉了,这里不再进行单独介绍。通常情况下实现泛型有下面的两种办法:
- 泛化类型以前保持不变,平行加入泛化新类型
- 已有类型泛型化,不加入任何泛型类型。
java使用的是第二种方式,原因无他,只是因为偷懒而已,在当时如果有更多时间讨论的话选择第一种是更好的选择也会有更多的解决方案,下面来简单了解一下泛型的基本特征以及需要实现的内容:
### 类型擦除
首先,java引入了类型擦除的机制,java的泛型在初始阶段叫做裸类型(父类型),裸类型可以看作是jdk5之前的类型即不带尖括号的类型,在实现裸类型上面有两种实现方式:
- 由虚拟机进行真正的构造
- 编译时还原,在元素访问的时候类型强转。
没错,java实现的方式也是使用了第二种方式,强转的实现相比 第一种方法要简单很多,但是也会带来下面的问题:
- 原始类型的支持变麻烦,java 用自动的类型转换替代直接导致了自动拆装箱的时候效率十分的低下
- 在运行阶段无法读取到泛型的类型,java的泛型只能算是一个“伪造”泛型。
泛型的擦除机制决定了java的泛型支持更多的是服务于编译器。
注意:1. 擦除只是code字节码擦除。2. 元数据保留擦除前的信息。
### 泛化后的属性
Sinature属性::存储的是方法在字节码层面的特殊签名,属性中保存参数化的类型信息而不是原始的类型,
值类型的支持:值类型也称之为valueType也就是可以定义基础数据类型的类型。
## 条件编译的实现
条件编译可以简单理解为通过if语句这个指令进行实现,java天生不支持条件编译,但是C和C++里面却是可以完成的。
Java语言中条件编译的实现,也是Java语言的一颗语法糖,根据布尔常量值的真假,编译器将会把 分支中不成立的代码块消除掉,这一工作将在编译器解除语法糖阶段(com.sun.tools.javac.comp .Lower 类中)完成。
最后条件编译上有个历史事件就是之前所说的Shenandoah收集器被jdk官方用条件编译给抹除,导致这款收集器不被商用jdk支持,也只能在openJDK上面使用。
通过上面的内容学习和了解,可以发现前端的编译作用是比较小的,可以算是是语法糖的一部分,而后端优化就没有那么简单了,下面我们来看下后端优化是如何实现的。
后端优化
即时编译器
即使编译器的重要地位自不用说,到现在还是主流编译器的Hotspot就可以说明即时编译器的重要性,而Hotspot里面一项重要的优化就是即使编译器,在了解即时编译器之前,我们需要弄清楚下面的问题:
- 为什么解释器和即时编译器并存
- 为什么要多个编译器
- 什么时候用解释器,什么时候用即时编译器
- 哪些代码为本地代码,如何编译
- 外部如何观察结果
通过解决上面的问题,我们就可以大致了解即时编译的核心内容。
即时编译的方式:面向方法而不是面向局部代码,这种方法在字节码序列号替换的方式被称为栈上替换,方法还在栈桢的时候被编译器进行隐式替换。
为什么会并存解释器和编译器?
并不是所有的即时编译器都是用的解释器和编译器并存的模式,但是目前主流的的几款产品中基本都存在这种共存的运行模式,他有什么作用呢?首先,它可以作为一个逃生门,在通常的情况下保持正常的配合操作,但是一旦编译器忙不过来的时候或者本地代码过多的情况下,就可以使用解释器“兜底”,可以保证任何情况下总是可以正常的运行代码。正所谓男女搭配,干活不累。
为什么有多个呢?
在Hotspot的编译器下有两个编译器:
- C1:客户端编译器:效率高,非常快,但是质量一般
- C2:服务端编译器:质量高但是效率要低一些
编译器为什么不止一个还有多个,这又是有关历史的话题,在早期的工作模式下面,解释器会根据服务器的资源以及用户指定的匹配前端编译器处理来提高效率,所以存在多个也是可以理解的。
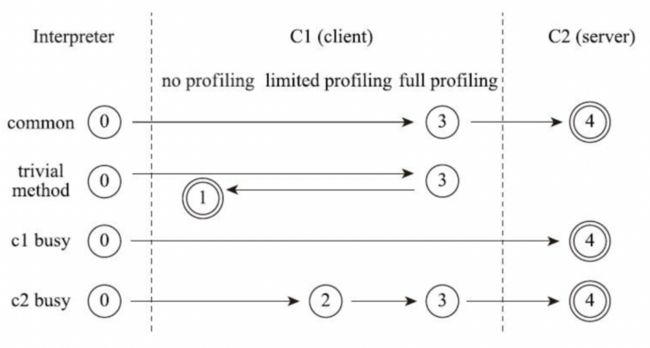
分层编译
我们不再需要了解以前的工作原理,而是要了解jdk7之后彻底实现的分层编译手段:
- 纯解释器模式:第一层
- 客户端编译器执行,开启部分监控:第二层
- 客户端编译器执行,开启完整监控:第三层
- 服务端编译为本地代码:第四层
当然上面的步骤不是完全固定的,根据实际情况会做顺序的调整,下面是书中给出的一张图:
热点代码探测
热点探测有两种方式:基于采样的热点探测(Sample Based Hot Spot Code Detection)和基于计数器的热点探测(Counter Based Hot Spot Code Detection),在HotSpot虚拟机中使用的是第二种基于计数器的热点探测方法,为了实现热点计数,HotSpot为每个方法准备了 两类计数器:方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter,“回边”的意思 就是指在循环边界往回跳转)。
热点代码探测是Hotspot又一项“灵魂”后端优化,热点代码又被称之为多次调用的代码或者多次执行循环体的代码,但是hotspot是如何判断的呢?如何获取某个方法执行多少次?以及怎么算“够久”?
首先我们先回答执行多少次的问题,hotspot使用的是两种计数器来完成:方法调用计数器和回边计数器。
而够久稍微复杂一些,方法调用和回边计数的判定方式是不一样的。下面用一个简单的列表来说明一下触发方法调用器热点代码的判定条件:
### 方法调用计数器
方法调用器:客户端编译器15000次,服务端编译器10000次
条件:回边+方法调用>=上面的阈值
注意:时间范围内的调用次数。
统计方法:半衰周期。### 回边计数器
方法调用计数器好懂一些,这里不做过多解释,下面我们补充一下回边计数器的细节,回边计数器就是指统计循环代码中执行的次数,当然不是单纯的计算循环体的执行次数,而是使用下面的公示计算:
客户端模式(默认为13995):方法调用计数器阈值(-XX: C o m p i l e T h r e s h o l d ) 乘 以 O SR 比 率 ( - X X : O n St a c k R e p l a c e P e r c e n t a ge ) 除 以 1 0 0 。 其 中 - X X : OnStackRep lacePercentage默认值为933
服务端模式(默认为10700):方法调用计数器阈值(-XX: C o m p i l e T h r e s h o l d ) 乘 以 ( O SR 比 率 ( - X X : O n St a c k R e p l a c e P e r c e n t a ge ) 减 去 解 释 器 监 控 比 率 ( - X X : InterpreterProfilePercentage)的差值)除以100。其中-XX:OnStack ReplacePercentage默认值为140,- X X : I n t e r p r e t e r P r o f i l e P e r c e n t a ge 默 认 值 为 3 3。
当回边方法触发到到阈值的时候,会触发一个叫做“栈上替换”的操作。并且回边计数器没有半衰周期的概念,当到达绝对值的条件的时候就会触发,而如果这个数字一直增长到达计数器的上限并且溢出,回边计数器会重置并且顺带把方法计数器的值为归0。最后在回边计数到达阈值的时候,会稍微降低当前回边计数器的值让下一次的代码依旧执行循环(不然栈上替换完了,循环也执行完了就没有意义了)。
## 结构图对比:
我们根据上面的描述来看下两个计数器的计算逻辑结构图:
方法调用

回边计数器

前后端编译概览

总结
本节我们讲述了javac指令的底层执行过程,以及前端优化和后端优化,前端优化主要是对于java的语法糖优化以及一项重要的优化注解生成器。在后续的文章中我们介绍了部分后端编译优化的方式,即使编译器,以及热点代码探测,在即时编译里面我们讲述了分层编译的功能。最后我们用结构图讲述了编译的内容。
写在最后
本文讲述了关于后端编译的部分,下一节将会讲述关于后端编译的另外一部分内容。