Spring Batch 自定义ItemReader
Spring Batch支持各种数据输入源,如文件、数据库等。然而有时也会遇到一些默认不支持的数据源,这时我们则需要实现自己的数据源————自定义ItemReader。本文通过示例说明如何自定义ItemReader。
创建自定义ItemReader
创建自定义ItemReader需要下面两个步骤:
- 创建一个实现ItemReader接口的类,并提供返回对象类型 T 作为类型参数。
- 按照下面规则实现ItemReader接口的T read()方法
read()方法如果存在下一个对象则返回,否则返回null。
下面我们自定义ItemReader,其返回在线测试课程的学生信息StuDto类型,为了减少复杂性,该数据存储在内存中。StuDto类是一个简单数据传输对象,代码如下:
@Data
public class StuDTO {
private String emailAddress;
private String name;
private String purchasedPackage;
}
下面参照一下步骤创建ItemReader:
- 创建InMemoryStudentReader 类
- 实现ItemReader接口,并设置返回对象类型为StuDto
- 类中增加List studentData 字段,其包括参加课程的学生信息
- 类中增加nextStudentIndex 字段,表示下一个StuDto对象的索引
- 增加私有initialize()方法,初始化学生信息并设置索引值为0
- 创建构造函数并调用initialize方法
- 实现read()方法,包括下面规则:如果存在下一个学生,则返回StuDto对象并把索引加一。否则返回null。
InMemoryStudentReader 代码如下:
public class InMemoryStudentReader implements ItemReader{ private int nextStudentIndex; private List studentData; InMemoryStudentReader() { initialize(); } private void initialize() { StuDto tony = new StuDto(); tony.setEmailAddress("[email protected]"); tony.setName("Tony Tester"); tony.setPurchasedPackage("master"); StuDto nick = new StuDto(); nick.setEmailAddress("[email protected]"); nick.setName("Nick Newbie"); nick.setPurchasedPackage("starter"); StuDto ian = new StuDto(); ian.setEmailAddress("[email protected]"); ian.setName("Ian Intermediate"); ian.setPurchasedPackage("intermediate"); studentData = Collections.unmodifiableList(Arrays.asList(tony, nick, ian)); nextStudentIndex = 0; } @Override public StuDto read() throws Exception { StuDto nextStudent = null; if (nextStudentIndex < studentData.size()) { nextStudent = studentData.get(nextStudentIndex); nextStudentIndex++; } return nextStudent; } }
创建好自定义ItemReader后,需要配置其作为bean让Spring Batch Job使用。下面请看如何配置。
配置ItemReader Bean
配置类代码如下:
@Configuration
public class InMemoryStudentJobConfig {
@Bean
ItemReader inMemoryStudentReader() {
return new InMemoryStudentReader();
}
}
需要增加@Configuration表明类为配置类, 增加方法返回ItemReader类型,并增加@Bean注解,实现方法内容————返回InMemoryStudentReader对象。
小结一下
本文通过示例说明如何自定义ItemReader,主要包括三个方面:
- 自定义ItemReader需实现ItemReader接口
- 实现ItemReader接口,需要指定返回类型作为类型参数(T)
- 实现接口方法read,如果存在下一个对象则返回,反之返回null
Spring Batch 之 ItemReader
重点介绍 ItemReader,如何从不同数据源读取数据;以及异常处理及重启机制。
JdbcPagingItemReader
从数据库中读取数据
@Configuration
public class DBJdbcDemoJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
@Qualifier("dbJdbcDemoWriter")
private ItemWriter dbJdbcDemoWriter;
@Autowired
private DataSource dataSource;
@Bean
public Job DBJdbcDemoJob(){
return jobBuilderFactory.get("DBJdbcDemoJob")
.start(dbJdbcDemoStep())
.build();
}
@Bean
public Step dbJdbcDemoStep() {
return stepBuilderFactory.get("dbJdbcDemoStep")
.chunk(100)
.reader(dbJdbcDemoReader())
.writer(dbJdbcDemoWriter)
.build();
}
@Bean
@StepScope
public JdbcPagingItemReader dbJdbcDemoReader() {
JdbcPagingItemReader reader = new JdbcPagingItemReader<>();
reader.setDataSource(this.dataSource);
reader.setFetchSize(100); //批量读取
reader.setRowMapper((rs,rowNum)->{
return Customer.builder().id(rs.getLong("id"))
.firstName(rs.getString("firstName"))
.lastName(rs.getString("lastName"))
.birthdate(rs.getString("birthdate"))
.build();
});
MySqlPagingQueryProvider queryProvider = new MySqlPagingQueryProvider();
queryProvider.setSelectClause("id, firstName, lastName, birthdate");
queryProvider.setFromClause("from Customer");
Map sortKeys = new HashMap<>(1);
sortKeys.put("id", Order.ASCENDING);
queryProvider.setSortKeys(sortKeys);
reader.setQueryProvider(queryProvider);
return reader;
}
}
Job 和 ItermWriter不是本文介绍重点,此处举例,下面例子相同
@Component("dbJdbcDemoWriter")
public class DbJdbcDemoWriter implements ItemWriter {
@Override
public void write(List items) throws Exception {
for (Customer customer:items)
System.out.println(customer);
}
}
FlatFileItemReader
从CVS文件中读取数据
@Configuration
public class FlatFileDemoJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
@Qualifier("flatFileDemoWriter")
private ItemWriter flatFileDemoWriter;
@Bean
public Job flatFileDemoJob(){
return jobBuilderFactory.get("flatFileDemoJob")
.start(flatFileDemoStep())
.build();
}
@Bean
public Step flatFileDemoStep() {
return stepBuilderFactory.get("flatFileDemoStep")
.chunk(100)
.reader(flatFileDemoReader())
.writer(flatFileDemoWriter)
.build();
}
@Bean
@StepScope
public FlatFileItemReader flatFileDemoReader() {
FlatFileItemReader reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("customer.csv"));
reader.setLinesToSkip(1);
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames(new String[]{"id","firstName","lastName","birthdate"});
DefaultLineMapper lineMapper = new DefaultLineMapper<>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper((fieldSet -> {
return Customer.builder().id(fieldSet.readLong("id"))
.firstName(fieldSet.readString("firstName"))
.lastName(fieldSet.readString("lastName"))
.birthdate(fieldSet.readString("birthdate"))
.build();
}));
lineMapper.afterPropertiesSet();
reader.setLineMapper(lineMapper);
return reader;
}
}
StaxEventItemReader
从XML文件中读取数据
@Configuration
public class XmlFileDemoJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
@Qualifier("xmlFileDemoWriter")
private ItemWriter xmlFileDemoWriter;
@Bean
public Job xmlFileDemoJob(){
return jobBuilderFactory.get("xmlFileDemoJob")
.start(xmlFileDemoStep())
.build();
}
@Bean
public Step xmlFileDemoStep() {
return stepBuilderFactory.get("xmlFileDemoStep")
.chunk(10)
.reader(xmlFileDemoReader())
.writer(xmlFileDemoWriter)
.build();
}
@Bean
@StepScope
public StaxEventItemReader xmlFileDemoReader() {
StaxEventItemReader reader = new StaxEventItemReader<>();
reader.setResource(new ClassPathResource("customer.xml"));
reader.setFragmentRootElementName("customer");
XStreamMarshaller unMarshaller = new XStreamMarshaller();
Map map = new HashMap<>();
map.put("customer",Customer.class);
unMarshaller.setAliases(map);
reader.setUnmarshaller(unMarshaller);
return reader;
}
}
MultiResourceItemReader
从多个文件读取数据
@Configuration
public class MultipleFileDemoJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
@Qualifier("flatFileDemoWriter")
private ItemWriter flatFileDemoWriter;
@Value("classpath*:/file*.csv")
private Resource[] inputFiles;
@Bean
public Job multipleFileDemoJob(){
return jobBuilderFactory.get("multipleFileDemoJob")
.start(multipleFileDemoStep())
.build();
}
@Bean
public Step multipleFileDemoStep() {
return stepBuilderFactory.get("multipleFileDemoStep")
.chunk(50)
.reader(multipleResourceItemReader())
.writer(flatFileDemoWriter)
.build();
}
private MultiResourceItemReader multipleResourceItemReader() {
MultiResourceItemReader reader = new MultiResourceItemReader<>();
reader.setDelegate(flatFileReader());
reader.setResources(inputFiles);
return reader;
}
@Bean
public FlatFileItemReader flatFileReader() {
FlatFileItemReader reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("customer.csv"));
// reader.setLinesToSkip(1);
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames(new String[]{"id","firstName","lastName","birthdate"});
DefaultLineMapper lineMapper = new DefaultLineMapper<>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper((fieldSet -> {
return Customer.builder().id(fieldSet.readLong("id"))
.firstName(fieldSet.readString("firstName"))
.lastName(fieldSet.readString("lastName"))
.birthdate(fieldSet.readString("birthdate"))
.build();
}));
lineMapper.afterPropertiesSet();
reader.setLineMapper(lineMapper);
return reader;
}
}
异常处理及重启机制
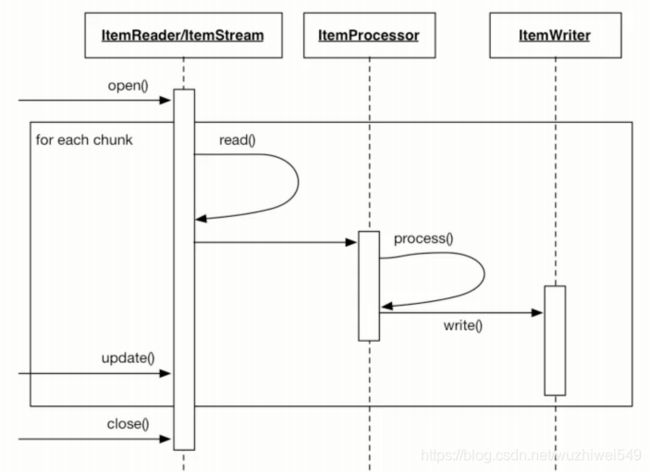
对于chunk-oriented step,Spring Batch提供了管理状态的工具。如何在一个步骤中管理状态是通过ItemStream接口为开发人员提供访问权限保持状态的组件。这里提到的这个组件是ExecutionContext实际上它是键值对的映射。map存储特定步骤的状态。该ExecutionContext使重启步骤成为可能,因为状态在JobRepository中持久存在。
执行期间出现错误时,最后一个状态将更新为JobRepository。下次作业运行时,最后一个状态将用于填充ExecutionContext然后
可以继续从上次离开的地方开始运行。
检查ItemStream接口:
将在步骤开始时调用open()并执行ExecutionContext;
用DB填充值; update()将在每个步骤或事务结束时调用,更新ExecutionContext;
完成所有数据块后调用close();
下面我们构造个例子
准备个cvs文件,在第33条数据,添加一条错误名字信息 ;当读取到这条数据时,抛出异常终止程序。
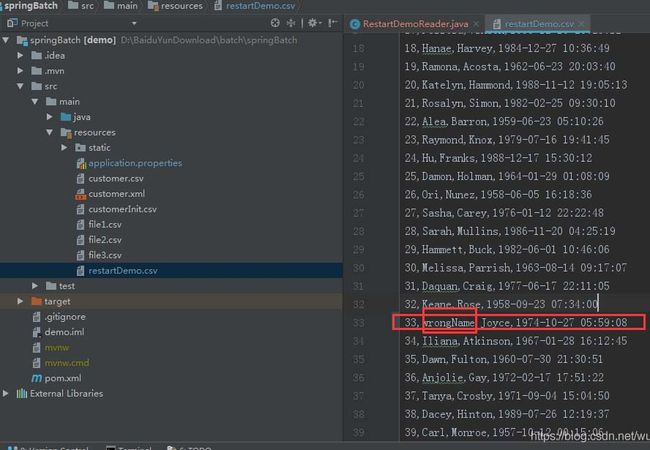
ItemReader测试代码
@Component("restartDemoReader")
public class RestartDemoReader implements ItemStreamReader {
private Long curLine = 0L;
private boolean restart = false;
private FlatFileItemReader reader = new FlatFileItemReader<>();
private ExecutionContext executionContext;
RestartDemoReader
public () {
reader.setResource(new ClassPathResource("restartDemo.csv"));
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames(new String[]{"id", "firstName", "lastName", "birthdate"});
DefaultLineMapper lineMapper = new DefaultLineMapper<>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper((fieldSet -> {
return Customer.builder().id(fieldSet.readLong("id"))
.firstName(fieldSet.readString("firstName"))
.lastName(fieldSet.readString("lastName"))
.birthdate(fieldSet.readString("birthdate"))
.build();
}));
lineMapper.afterPropertiesSet();
reader.setLineMapper(lineMapper);
}
@Override
public Customer read() throws Exception, UnexpectedInputException, ParseException,
NonTransientResourceException {
Customer customer = null;
this.curLine++;
//如果是重启,则从上一步读取的行数继续往下执行
if (restart) {
reader.setLinesToSkip(this.curLine.intValue()-1);
restart = false;
System.out.println("Start reading from line: " + this.curLine);
}
reader.open(this.executionContext);
customer = reader.read();
//当匹配到wrongName时,显示抛出异常,终止程序
if (customer != null) {
if (customer.getFirstName().equals("wrongName"))
throw new RuntimeException("Something wrong. Customer id: " + customer.getId());
} else {
curLine--;
}
return customer;
}
/**
* 判断是否是重启job
* @param executionContext
* @throws ItemStreamException
*/
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
this.executionContext = executionContext;
if (executionContext.containsKey("curLine")) {
this.curLine = executionContext.getLong("curLine");
this.restart = true;
} else {
this.curLine = 0L;
executionContext.put("curLine", this.curLine.intValue());
}
}
@Override
public void update(ExecutionContext executionContext) throws ItemStreamException {
System.out.println("update curLine: " + this.curLine);
executionContext.put("curLine", this.curLine);
}
@Override
public void close() throws ItemStreamException {
}
}
Job配置
以10条记录为一个批次,进行读取
@Configuration
public class RestartDemoJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
@Qualifier("flatFileDemoWriter")
private ItemWriter flatFileDemoWriter;
@Autowired
@Qualifier("restartDemoReader")
private ItemReader restartDemoReader;
@Bean
public Job restartDemoJob(){
return jobBuilderFactory.get("restartDemoJob")
.start(restartDemoStep())
.build();
}
@Bean
public Step restartDemoStep() {
return stepBuilderFactory.get("restartDemoStep")
.chunk(10)
.reader(restartDemoReader)
.writer(flatFileDemoWriter)
.build();
}
}
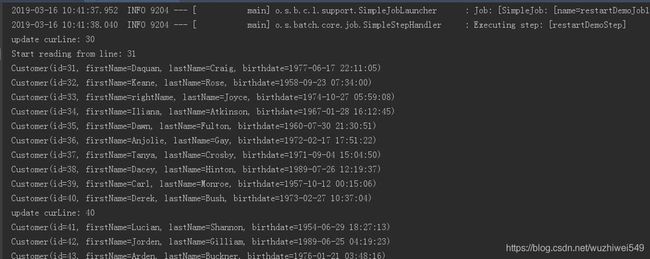
当我们第一次执行时,程序在33行抛出异常异常,curline值是30;
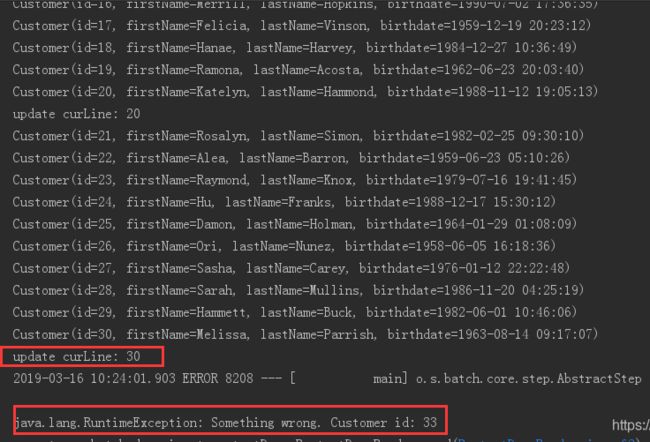
这时,我们可以查询数据库 batch_step_excution表,发现curline值已经以 键值对形式,持久化进数据库(上文以10条数据为一个批次;故33条数据异常时,curline值为30)

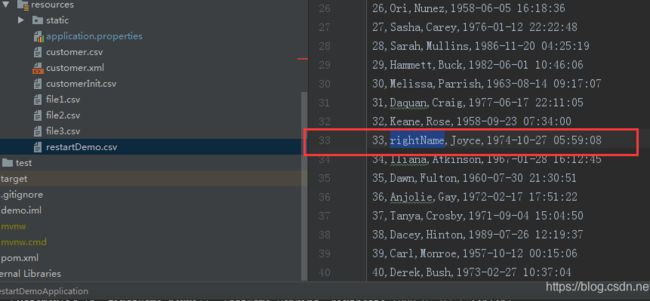
接下来,我们更新wrongName,再次执行程序;
程序会执行open方法,判断数据库step中map是否存在curline,如果存在,则是重跑,即读取curline,从该批次开始往下继续执行;
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。