
ProseMiror 作为 JS 老鹰书作者的编辑器开山之作,充分集成了 Unix 系统设计的精华,践行稳定、高性能内核设计 + 灵活的插件扩展机制,是继 CodeMirror 代码编辑器后,又一优秀的前端富文本编辑器开源项目,业界很多知名产品使用 Prosemirror 作为期内容编写核心工具,如 Confluence 等。

本文为带你实现一个生产级别的富文本编辑器系列教程的开篇,主要为对 Prosemirror 文档的提炼,讲解 Prosemirror 的核心概念,以及如何开发一个最简的编辑器。
特点
- Prosemirror 提供了一系列工具、概念来构建富文本编辑器,使用基于 WYSIWYG 的图形界面,但是试图避免这类编辑的陷阱
- 通过代码(code)完全控制文档(document),以及在文档上可以做的事情,文档是自定义的数据结构,包含你让它能有的内容,所有的更新都会经过一个中介点,你可以识别出这些更新(inspect),并作出对应的反应(react)。
- 核心库不是一个很容易使用的组件 -- 优先考虑模块性、定制性,由于简单性,未来可能有其他基于 Prosemirror 封装的更高层的编辑器出现,而 Prosemirror 更像是一个 Lego 而不是一个很匹配的汽车。
- 四个核心模块,在能够处理任何形式的编辑时是必要的,以及由核心团队维护的一系列扩展(extensions)库,类似于第三方模块,提供了非常有用的功能,但是你可以忽略它们,或是替代他们来实现类似的功能。
四个核心模块如下:
- prosemirror-model:定义了编辑器的 “文档模型”(document model),“数据结构” -- 用于描述编辑器的内容
- prosemirror-state:提供数据结构 -- 描述整个编辑器的状态(whole state),包含光标(selection)、一个合约系统(transaction system)-- 用于将一个状态变为下一个状态
- prosemirror-view:实现了用户界面组件(user interface component),接收给定的编辑器状态作为浏览器中的一个可编辑元素,处理这个元素的用户交互
- prosemirror-transform:包含以一种可记录、可重放的方式来修改文档的功能,是 state 模块里面 “合约系统” 的基础,使得重做(undo)历史、协作编辑功能变为可能
除此之外还有一些扩展库:
- 基础编辑命令(basic editing commands):prosemirror-commands
- 绑定键盘键(binding keys):prosemirror-keymap
- 重做历史(undo history):prosemirror-history
- 输入宏(input macros):prosemirror-inputrules
- 协作编辑(collaborative editing):prosemirror-collab
- 文档模式(document schema):prosemirror-schema-basic
- 处理列表模式:prosemirror-schema-list
- 处理拖放光标:prosemirror-gapcursor
Prosemirror 并不是以一个浏览器可加载的单一脚本文件来分发的,而是提供了一系列模块,在使用时需要借助打包工具来使用。
第一个编辑器

创建一个 Prosemirror 编辑器需要如下几个流程:
- 定义一个文档需要遵循的模式(Schema)
- 基于此模式创建编辑器的初始状态(State),这个过程会创建一个遵循上述模式的空文档(Empty document)以及一个置于文档开始位置的默认光标(Selection)
- 基于上述状态创建视图(View),并将此视图挂载到 DOM 中,这个过程会将文档状态渲染成一个可编辑的 DOM 节点,当用户打字时,会基于用户的操作生成对应的 “合约”(Transaction),合约会去更新文档状态(State),最终反应到视图(View)
根据上述的流程我们来看一个最简单的 Prosemirror 编辑器代码:
import { schema } from "prosemirror-schema-basic"
import { EditorState } from "prosemirror-state"
import { EditorView } from "prosemirror-view"
const doc = schema.node("doc", null, [
schema.node("paragraph", null, [
schema.text("hello", [schema.mark("em")]),
]),
schema.node("horizontal_rule"),
schema.node("paragraph", null, [schema.text("world")]),
]);
let state = EditorState.create({ schema })
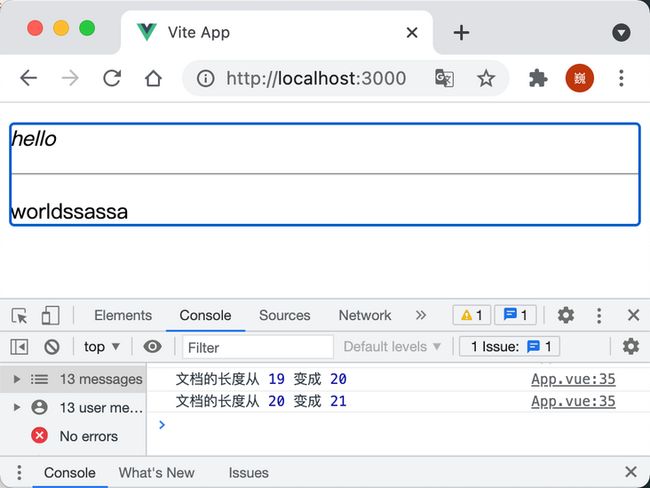
let view = new EditorView(document.body, { state })上述代码的展示效果如下:

上述的代码里很好的阐述的上述图示的流程,但是我们无法很直观的了解到状态(State)、合约(Transaction)等概念,同时现在生成的编辑器也没法处理换行之类的内容,因为 Prosemirror 的核心库是无观点的,你必须通过设置适当的条件来通知核心库处理对应的换行,后续将通过更加完善一点的例子来补齐欠缺的流程。
处理 “合约”
每当用户输入内容或以其他方式与视图(View)进行交互时,会生成对应的 “状态合约”(State Transaction),这意味着不是直接修改文档,然后隐晦的更新状态,而是每次修改都会创建一个 合约(Transaction)-- 描述对状态(State)的改动,可以被应用来创建新的状态,然后新的状态被用于更新视图。
上述的过程都是在底层默认会发生的,但是你可以通过编写插件来配置视图以拦截这个过程,例如在创建视图时添加 dispatchTransaction 的方法属性,每当合约被创建时,这个方法都会调用:
let state = EditorState.create({ schema });
let view = new EditorView(document.body, {
state,
dispatchTransaction(transaction) {
console.log(
"文档的长度从",
transaction.before.content.size,
"变成",
transaction.doc.content.size
);
let newState = view.state.apply(transaction);
view.updateState(newState);
},
});每次状态(State)更新时,都需要经过 updateState 方法,每个基础的编辑更新都会通过发起一个合约的形式来进行(dispatching a transaction),对应的展示效果如下:
插件
插件用于以各种各样的方式扩展编辑器的行为或编辑器的状态,有些插件的行为很简单,如 keymap 插件用于给键盘输入绑定动作,有些则比较复杂,例如 undo history 插件,实现了历史回退的功能,通过监听合约,然后存储一个合约的反置,以便在用户想要重做时能够实现回退。
让我们尝试将 undo/redo 插件加入到我们的编辑器中来获得回退/重做的功能:
import { undo, redo, history } from "prosemirror-history";
import { keymap } from "prosemirror-keymap";
let state = EditorState.create({
schema,
plugins: [history(), keymap({ "Mod-z": undo, "Mod-y": redo })],
});
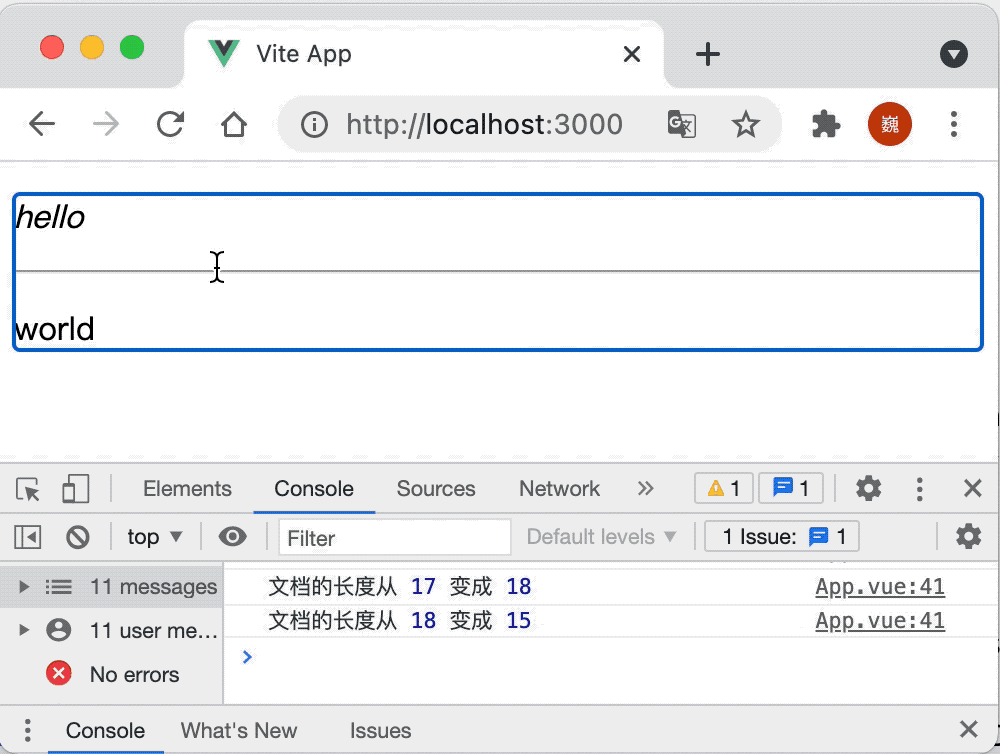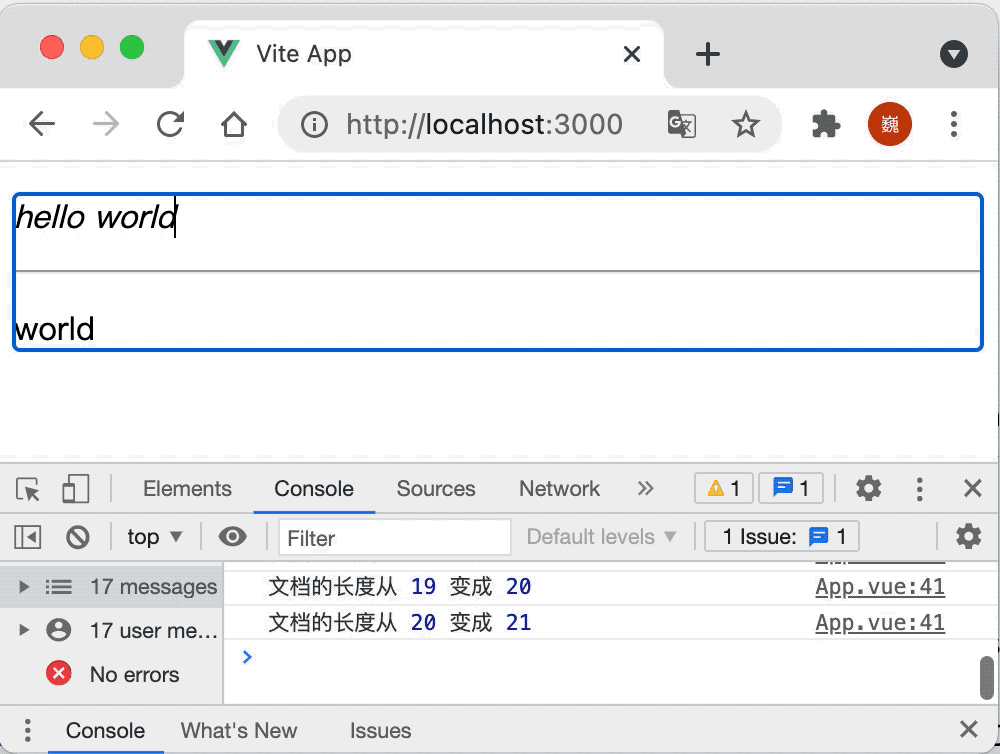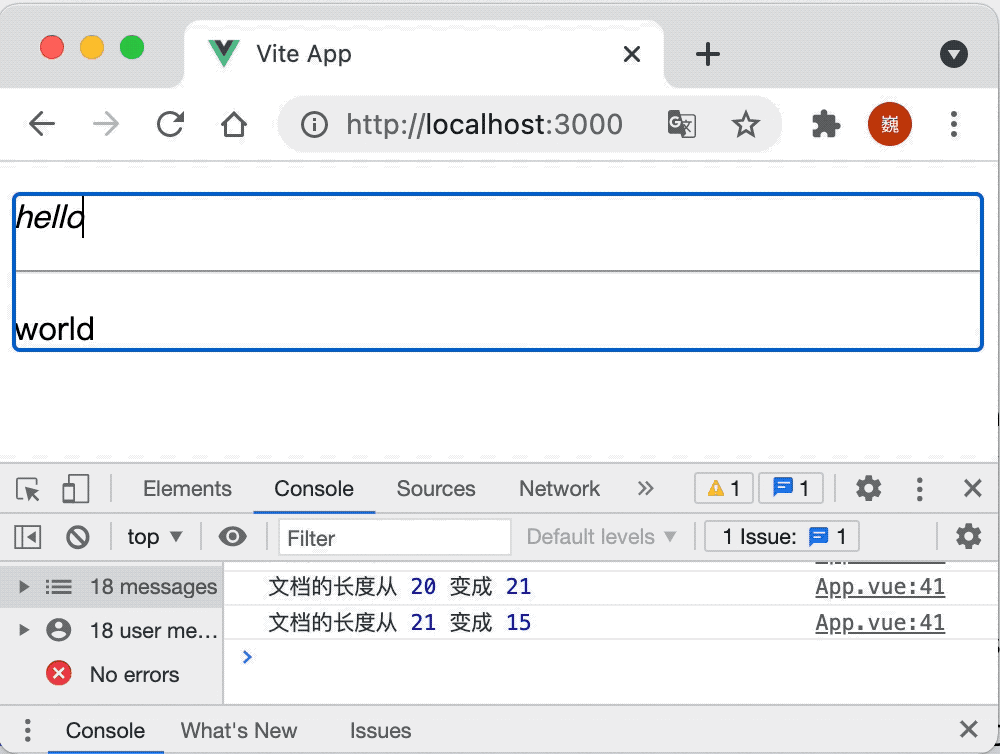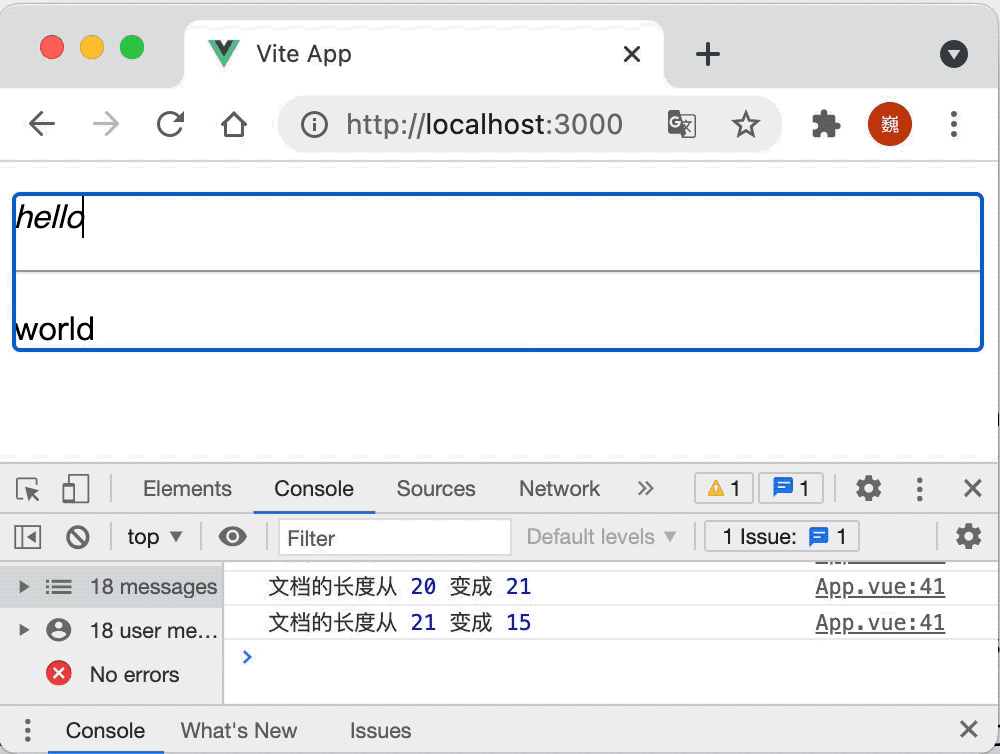
let view = new EditorView(document.body, { state });因为插件需要获取到 “状态合约”(State Transaction),所以在创建状态时,注册对应的插件,当通过打开了 “历史” 功能的状态创建视图之后,你就可以通过快捷键 “Ctrl-Z”(Mac 上 Command-Z)来回退你上次的修改。
对应的效果如下:
命令
上面提到的绑定了对应键盘键(Ctrl-Z/Mod-Z)的 undo/redo 值函数是一类被称之为命令(commands) 的特殊函数。大部分的编辑操作都能通过编写对应的命令来处理,这些命令可以绑定对应的键盘键,可以挂载到菜单栏上,或是暴露给用户使用来控制编辑器的行为。
prosemirror-commands 包提供了一系列基础的编辑命令,包含一个最小的 “键映射” 功能,处理包括你可能想要的 Enter 或 Delete 键按下需要的相应功能。
import { baseKeymap } from "prosemirror-commands";
let state = EditorState.create({
schema,
plugins: [
history(),
keymap({ "Mod-z": undo, "Mod-y": redo }),
keymap(baseKeymap),
],
});
let view = new EditorView(document.body, { state });通过添加上面的 “键映射” 插件,现在就可以处理各种 Enter、Delete 等键你预期能达到的功能了,如按 Enter 键,编辑器就会插入一个换行符或插入一个新的节点。
为了添加菜单栏,或者为了特定模式的键绑定功能,你可能需要 prosemirror-example-setup 包来帮忙,这个包提供了一系列插件来配置你的编辑器,正如它的名字一样,更多地只是应用为一个完善的例子而非生产级别的库。对于在真实世界的部署编辑器,你可能需要将它的部分替换成自定义的代码来设定你实际需要的内容。
内容
文档(Document)的状态通常保存在它对应的 doc 属性下,状态通常是一个只读的数据结构,通过一堆层级节点来代表文档,类似浏览器端的 DOM 。一个简单的文档(Document)可能包含一个 doc ,然后这个 doc 包含两个 paragraph 节点,每个 paragraph 节点又各自包含一个 text 节点。
当初始化状态时,你可以给予它一个初始的文档(Document),在这种情况下,schema 字段就为可选的,因为能从这个初始的文档中提取出对应的 schema 。
// html
import {DOMParser} from "prosemirror-model"
import {EditorState} from "prosemirror-state"
import {schema} from "prosemirror-schema-basic"
let content = document.getElementById("content")
let state = EditorState.create({
doc: DOMParser.fromSchema(schema).parse(content)
})
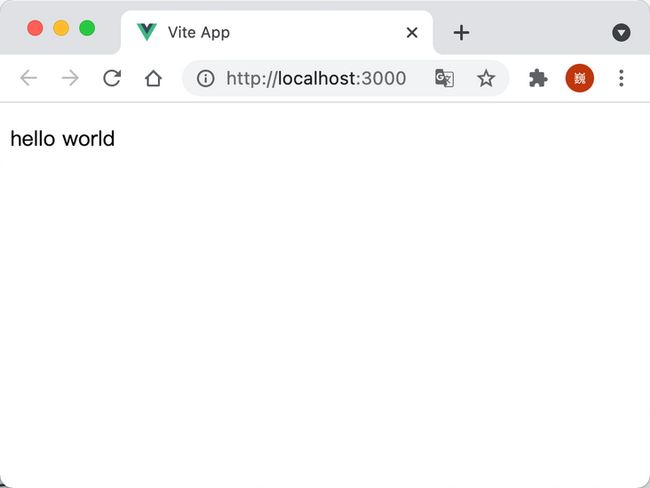
let view = new EditorView(document.getElementById("root"), { state });上述代码通过解析 id 为 content 的 DOM 内容来初始化编辑器的状态,接收 schema 提供的信息,告诉 DOMParser 在解析时,对应的 DOM 节点如何映射为 Schema 里面的元素,最终会解析成一颗类似如下的节点树:
{
"type": "doc",
{},
[
{
"type": "paragraph",
{},
[
{
"type": "text",
{ "text": "hello world" }
}
]
}
]
}上述代码运行的效果如下,即将一个隐藏的 DOM 节点的内容解析为了编辑器的初始内容 “Hello World”。
文档
Prosemirror 通过一套自定义的数据结构来代表内容文档,因为文档是接下来要讲解的编辑器其他组成部分的的基石内容,所以了解文档是如何工作的有利于理解接下来的内容。
结构
一个 Promseirror 文档是一个包含一个或多个子节点的节点,类似浏览器的 DOM,所以它也是类树状的,可递归的,但是 Prosemirror 的文档和 DOM 在存 “内联” 内容时是不太一样的。
在 HTML 中,一个段落 p 标签被表示为一棵树,类似如下这样:
This is strong text with emphasis
上述 HTML 的包含关系为如下层级:

而在 Prosemirror 里面,内联内容被建模为一个扁平序列,标签被作为元属性附加在节点上,形如如下关系:

这种方式更像我们期望操作文本的方式,它使得我们通过在字符串中的偏移量来表示位置而非树中的层级路径,使得拆分文本、修改内容的样式操作变得更容易,而不需要执行别扭的树操作。
这意味着每个文档只有一个有效表示,具有相同 “标记”(Mark) 的相邻文本节点总会被合并,同时不允许空文本节点存在,“标记” 出现的顺序由模式(Schema)决定。
所以一个 Prosemirror 文档就是一个块节点树,大多数的叶子节点为文本块 -- 包含文本的块节点,叶子块也可以是空节点,例如一个 。
节点(Node)对象包含一系列属性,代表它们在文档(Document)中承担的角色:
isBlock和isInline方法可以告诉你给定的某个节点是 块(block) 还是内联(inline)节点isInlineContent是如果期望内联节点作为内容,返回trueisTextblock则针对块节点包含内联内容时,返回trueisLeaf代表某个节点不能包含任何内容
所以一个传统的 paragraph 节点会返回文本块 textblock ,blockquote 可能会返回一个包含其他 block 的 block ,而 text 、images 都是 leaf nodes ,
“模式”(schema )可以为文档指定更加准确的限制,如即便一个节点允许块内容存在,但是不代表所有类型的块都可以作为其内容存在。

身份与持久化
另一个 Prosemirror 文档与 DOM 树不同的点在于 -- 文档对象代表节点行为的方式,在 DOM 中,节点是可突变的对象,通过一个身份来表示,这代表一个节点只能出现在一个父节点下面,在内容更新时,此节点对象被突变了。
在 Prosemirror 中,另一方面,节点是简单的值,就像数字 3 就是数字 3 一样,3 可以同时出现在很多数据结构中,它没有一个指向当前所属父节点的链接,如果你给它加 1,你就获得了一个新的数字 4,而没有改变之前的 3。
所以,Prosemirror 文档也是如此,它们不会改变,但是能用于初始值来计算被修改的文档片段,它们也不知道当前所属那份数据结构中,但是能同时属于多份数据结构,或是在一份数据结构中出现多次,它们是值,不是有状态的对象。
这意味着,每次你更新一份文档,你获得一份新的文档值,这份新文档会共享原文档所有没有改变的子节点,这使得创建新文档相对廉价,不会很耗时。
这带来了很多优点,它让编辑器在更新时处于一个中间状态变得不可能,因为带有新文档的新状态能够立即交换,同时使得可以更容易的以某种数学方式推理文档,如果值在不受控制的不断变化,那么上述推理是很难的。这同时使得协作编辑变为可能,通过比较它上次绘制在屏幕上的文档与当前的文档,使得 Prosemirror 能够运行一个非常高效的 DOM 更新算法。
因为节点是以普通 JS 对象表示的,明确 冻结(freezing) 对象的属性会影响性能,所以实际上也可以修改这些对象,但是这样做是不被支持的,会使得编辑器崩溃,因为在多份数据结构中总是有共享的部分,所以要当心别这样做!同时也要注意不要修改节点对象中的对象或数组,如对象用于存储节点属性,对象用于放置孩子节点,
数据结构
文档的对象结构类似如下形式:

每个节点都通过 Node 类的实例来表示,通过 type 标记,通过 type 了解节点的名称,合法的属性,等等。Node 的 type (或 Mark 的 type)每份 Schema 创建一次,并了解它们属于那份 Schema。
节点的内容(content)以 Fragment 的实例存储,Fragment 包含一系列 Node,及其节点没有、或不允许有内容,这个字段都会以共享的空 fragment 来填充。
有些节点还需要包含属性(attrs),是存储在节点里面的额外值,例如,一个图片节点可能通过这个字段存储 alt 文本或图片的 url 。
除此之外,内联节点还包含一系列的标记(mark ),比如加粗(em)或者成为一个连接(link),这些都被放在一个 Mark 实例的数组里。
一个完整的文档(Document)就是一个节点(Node),文档的内容通过顶层节点的孩子节点表示,一般来说,文档包含一系列块节点,有一些包含内联内容的文本块,但是顶层节点也可能是文本块本身,这时文档就只包含内联内容。
什么地方允许什么样的节点都是由文档的模式(schema)决定的,为了创建节点,你必须遵守模式,例如用 node 和 text 的方法来创建节点时:
import {schema} from "prosemirror-schema-basic"
// (The null arguments are where you can specify attributes, if necessary.)
let doc = schema.node("doc", null, [
schema.node("paragraph", null, [schema.text("One.")]),
schema.node("horizontal_rule"),
schema.node("paragraph", null, [schema.text("Two!")])
])索引
Prosemirror 节点支持两类索引 -- 可以被当做树处理,使用偏移来获取到某个节点,或者被当做一个扁平的 token 序列处理。
对于第一种方式你可以做类似对单一节点交互时对 DOM 可以做的操作,通过 child 和 childCount 直接获取孩子节点,编写递归函数来扫描整份文档,如果你只想看所有的节点,那么用 descendants 或 nodesBetween 就可以了。
第二种方式在处理文档中特定位置时非常有用,它使得文档中任意位置都可以通过数字表示 -- token 序列中的索引,这些 token 不实际作为对象存储在内存中,它们仅仅是一个计算约定,但是文档的树形结构,以及每个节点知道其实际的节点大小,所以通过位置获取变得成本很低。
- 文档的开始,在第一个内容之前,位置为 0
- 进入或离开一个非叶子节点(例如:包含内容)被计算为一个 token,所以一个以 paragraph 开头的文档,paragraph 的开头被记为位置 1
- 文本节点里面的每个字符被计算为一个 token,如果文档开头的 paragraph 包含单词
hi,h后的位置为 2 ,在h之后,i后的位置是 3,然后整个 paragraph 结束之后的位置为 4 - 不可包含内容的叶子节点如 images,也算作一个 token
所以,如果你有一个如下的文档,通过 HTML 表示类似这样:
One
Two
带上位置的 token 序列图类似如下这样:

每个节点有一个 nodeSize 属性,来告诉你整个节点的大小,你也可以通过 .content.size 获取节点内容的大小。需要注意的是,对于最外部的文档节点,开闭 token 不会当做文档的一部分处理,因为你无法将光标放在文档外,所以文档的大小使用 doc.content.size 表示,而不是 doc.nodeSize 表示。
手动的解释上述的位置需要很多的计算,你可以通过调用 Node.resolve 来获取此位置更多描述的数据结构,这个数据结构将会告诉你这个位置的父节点是什么,它在父节点里面的偏移量,父节点有哪些祖先节点,以及一些其他的信息。
注意对于每个 childCount 属性,都要区分孩子索引、文档方面的位置、以及节点的本地偏移量(优势也用于在递归函数中表示一个当前正在被处理的节点中的位置)。
切片
为了处理 复制-粘贴,或者 拖拽-放置 等功能,聊一聊文档的切片就很有必要了 -- 例如两个位置之间的内容,这样的切片与一个完整的节点或片段不同,在切片中,有些节点的 start 和 end 位置是 “开” 着的。
例如,如果你选择的内容从一段中间到另一段中间,你选择的这个切片就有两段内容在里面,第一段内容在开始位置是 “开” 着的,第二段内容在结束位置也是 “开” 着的,然而如果你选中整个 paragraph 节点,你会选中一个 “闭” 节点。这种情况下,“开” 节点里面的内容就违反了 “模式” 限制,如果将其作为节点的全部内容对待,但是有些必要的节点落在了 “切片” 之外。
Slice 数据结构被用于代表上述切片,它存储在两侧都为 “开深度” 的片段,你可以在节点上使用 slice 方法来从文档中切断一段 “切片”。
// doc 包含两段内容,包含文本 "a" 和 "b"
let slice1 = doc.slice(0, 3); // 第一段内容
console.log(slice1.openStart, slice1.openEnd); // → 0 0
let slice2 = doc.slice(1, 5); // 从第一段开始到第二段结束
console.log(slice2.openStart, slice2.openEnd); // → 1 1修改
因为节点和片段都是持久化的,你应该永远都不要突变它们。如果你处理了一份文档(一个节点、或一个片段),这个文档对应的对象将会保持不变。
大多数情况下,使用 transformation 来更新文档,而不会直接与节点打交道,这也会带来关于改动的记录,这对于文档是整个编辑器状态的一部分来说是很有必要的。
如果你想手动的更新一份文档,在 Node 和 Fragment 类型上也有一些便利的帮助方法,为了创建和更新整个文档的版本,你会常使用到 Node.replace 方法,它会将给定范围的文档用一个新内容的切片来替换。为了浅更新文档,你可以使用 copy 方法,这会创建带有新内容的相似节点。Fragment 也有很多更新方法,如 replaceChild 、和 append 。
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
喜欢的话别忘了 分享、点赞、收藏 三连哦~。
欢迎关注公众号 程序员巴士,一辆有趣、有范儿、有温度的程序员巴士,涉猎大厂面经、程序员生活、实战教程、技术前沿等内容,关注我,交个朋友。