❤️爆肝十八万字《python从零到精通教程》第二版,贴心保姆教你从零变大佬❤️(建议收藏),学不会找我!
文章目录
- 一、pycharm下载安装
- 二、python下载安装
- 三、pycharm上配置python
- 四、配置镜像源让你下载嗖嗖的快
-
-
- 4.1)pycharm内部配置
- 4.2)手动添加镜像源
- 4.3)永久配置镜像源
-
- 五、插件安装(比如汉化?)
-
-
- 5.1)自动补码神器第一款
- 5.2 )自动补码神器第二款
- 5.2)汉化pycharm
- 5.3)其它插件
-
- 六、美女背景
- 七、自定义脚本开头
- 八、即将开始写代码了!
- 九、python入门
- 十、python缩进
- 十一、Python注释
-
- 1)单行注释
- 2)多行注释
- 十二、Python 变量
-
- 1)变量定义理解
- 2) 变量名命名
- 3) 分配多个值
- 4)输出变量
- 5)全局变量与局部变量,全局关键字
- 6)练习题
- 十三、Python数据类型
-
- 1)置数据类型
- 2)获取数据类型
- 3)设置数据类型
- 4)设置特定数据类型
- 6)练习题
- 十四、python数字
-
- 1)整数
- 2)浮点数
- 3)虚数
- 4)类型转换
- 5)随机数
- 6)练习题
- 十五、python指定变量类型
- 十六、Python字符串
-
- 一、字符串基本使用
-
- 1)字符串理解
- 2)将字符串分配给变量
- 3)多行字符串
- 4)字符串是数组
- 5)遍历字符串
- 6)字符串长度
- 7)检查字符串
- 8)检查如果不是
- 二、切片字符串
-
- 1)切片
- 2)从头开始切片
- 3)切到最后
- 4)负索引
- 三、修改字符串
-
- 1)小写转大写
- 2)大写转小写
- 3)删除空格
- 4)替换字符串
- 5)拆分字符串
- 四、字符串连接
- 五、格式化字符串
-
- 1)format单个传参
- 2)format多个个传参
- 六、字符串的其它处理方法总结
- 七、练习题
- 十七、Python布尔值
-
-
- 1)比较
- 2)评估值和变量
- 3)布尔真值
- 4)布尔假值
- 5)函数可以返回布尔值
- 6)练习题
-
- 十八、python运算符
-
- 1)算术运算符
- 2)赋值运算符
- 十九、Python列表
-
- 一、列表基本知识
-
- 1)创建列表
- 2.列出表值
- 3.列表长度
- 4.列表项 - 数据类型
- 5.Python 集合(数组)
- 二.访问列表
-
- 1.正常索引
- 2)负索引
- 3)索引范围
- 4)负指数范围
- 5)检查是否存在
- 三、更改列表
-
- 1)单个更改
- 2)多个更改
- 3)插入列表
- 四、添加列表
-
- 1)末尾添加
- 2)指定位置添加
- 3)合并列表
- 五、删除列表
-
- 1)删除指定目标
- 2)删除指定索引
- 3)del删除指定的索引
- 4)清除列表
- 六、循环列表
-
- 1)for循环遍历
- 2)while循环遍历
- 七、列表推导式
- 八、列表排序
-
- 1)区分大小写的排序
- 2)不区分大小写的排序
- 3)倒序
- 九、复制列表
- 十、加入列表
- 十一、列表所有操作总结
- 十二、练习
- 二十、Python元组
-
- 一、元组理解
-
- 1.1)基本定义
- 1.2)元组长度
- 1.3)数据类型
- 二、访问元组
-
- 2.1)正常访问
- 2.2)负索引
- 2.3)范围性索引
- 三、更新元组
-
- 3.1)替换
- 3.2)添加项目值
- 3.3)删除项目
- 四、解包元组
- 五、循环元祖
-
- 5.1)遍历元祖
- 5.2)使用 While 循环
- 六、元组合并
- 七、练习
- 二十一、Python集合
-
- 一、集合理解
- 二、访问集合
-
- 2.1)遍历集合
- 3.2)检查是否存在
- 三、添加集合
-
- 3.1)添加项目值
- 3.2)添加集合
- 3.3)添加任何可迭代对象
- 四、移除集合项
-
- 4.1)remove方法
- 4.2)iscard() 方法
- 4.3)pop() 方法
- 4.4)clear() 方法
- 4.5)del关键字
- 五、循环集合
- 六、集合连接
-
- 6.1)普通连接
- 6.2)仅保留重复项
- 6.3)保留所有,但不保留重复项
- 七、练习
- 二十二、Python字典
-
- 一、字典理解
-
- 1.1)创建字典与访问
- 1.2)字典长度
- 1.3)数据类型
- 二、访问字典
-
- 2.1)访问键名
- 2.2)访问健值
- 三、更改字典各种方法
- 四、添加字典项各种方法
- 五、删除字典的各种方法
- 六、遍历字典
- 七、复制字典
- 八、嵌套字典
- 九、练习
- 二十三、If ... Else语句
-
- 一、if语句
- 二、缩进
- 三、elif语句
- 四.else语句
-
- 4.1基本else
- 4.2)and语句
- 4.3)or 语句
- 4.4)嵌套if语句
- 4.4)pass语句
- 二十四、while循环语句
-
- 一、基本理解
- 二、中断声明
- 三、continue 声明
- 四、else 语句
- 二十五、for循环语句
-
- 一、基本遍历
- 二、遍历字符串
- 三、中断声明
- 四、continue 声明
- 五.range() 函数
- 六.嵌套循环
- 七.pass语句
- 二十六、函数
-
- 一、创建函数与调用
- 二、参数
- 三、参数数量
- 四、任意参数,*args
- 五、关键字参数
- 七、任意关键字参数,**kwargs
- 八、默认参数值
- 九、将列表作为参数传递
- 十、返回值
- 十一、pass语句
- 二十七、lambda
- 二十八、数组
-
- 一、访问数组的元素
- 二、数组的长度
- 三、修改数组
- 四、数组的其它操作
- 二十九、Python类和对象
-
- 一、创建类
- 二、创建对象
- 三、__init__() 函数
- 四、对象方法
- 五、自参数
- 六、对象及其属性更改
- 七、pass语句
- 三十、Python继承
-
- 一、创建父类
- 二、创建子类
- 三、添加 __init__() 函数
- 四、使用 super() 函数
- 五、添加属性
- 六、添加方法
- 三十一、Python日期
-
- 一、日期输入输出
- 二、创建日期对象
- 三、strftime() 方法
- 四、其它调用方法
- 三十二、Python JSON
-
- 一.从 JSON 转换为 Python
- 三十三、异常处理
-
- 一、异常处理
- 二、else搭配
- 三、finally语句
- 四、引发异常
- 三十四、用户输入
- 三十五、格式化输入输出
- 三十六、⭐进阶python正则表达式⭐
-
- 一、Python中的正则表达式
- 二、正则表达式函数
-
- 2.1) findall() 函数
- 2.2) search() 函数
- 2.3) split() 函数
- 2.4) sub() 函数
- 三、元字符
-
- 3.1) 列表符号
- 3.2)转义符
- 3.4) 任意符号
- 3.5)开始符
- 3.6) 结束符
- 3.7 )星号符
- 3.8 )加号符
- 3.9)集合符号
- 3.10) 或符
- 四、特殊序列
-
- 4.1) 指定字符
- 4.2) 指定开头结尾
- 4.3)匹配中间字符
- 4.4)匹配数字
- 4.5) 匹配非数字
- 4.6) 空格匹配
- 4.7) 匹配非空格
- 4.8 匹配任意数字和字母
- 4.9)匹配任意非数字和字母
- 4.10) 匹配结尾
- 五、集合套装
-
- 5.1) 指定符范围匹配
- 5.2) 匹配任意范围内小写字母
- 5.3) 其它
- 六、匹配对象
-
- 6.1) span函数
- 6.2)string函数
- 6.3) group函数
- 三十七、⭐进阶数据库操作⭐
-
- 一、MySQL入门连接
- 二、MySQL创建表
- 三、MySQL插入表
- 四 、MySQL选择
- 五 、MySQL查询位置
- 六、MySQL排序
- 七、MySQL删除
- 八、MySQL更新表
- 九、MySQL限制
- 十、MySQL合并
- 十一、MySQL删除表
- 十二、SQL详细教程
- 三十八、⭐进阶Git详细教程⭐
- 三十九、⭐进阶爬虫⭐
- 三十九、⭐终极实战QQ机器人教程⭐
- 四十、⭐粉丝福利⭐
- 四十一、总结
一、pycharm下载安装
pycharm下载地址:
http://www.jetbrains.com/pycharm/download/#section=windows
下载详细步骤:
1-

2-

3-
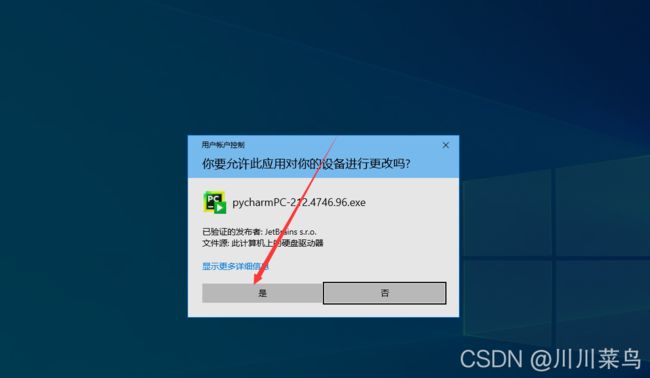
4-

5-
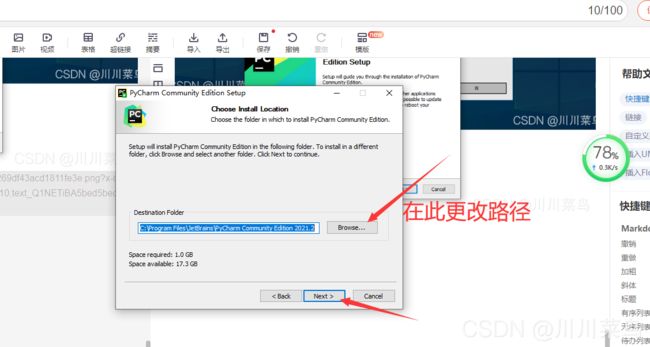
6

7-
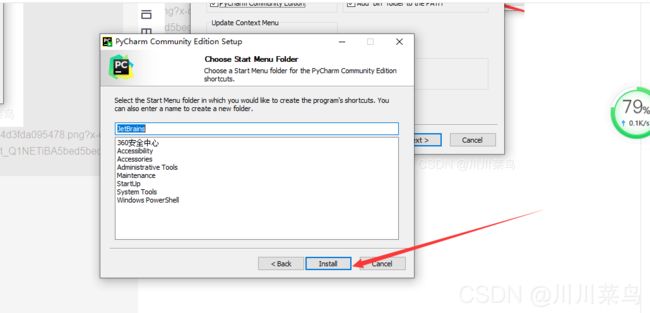
8-直接finish


二、python下载安装
9-python官网:
https://www.python.org/
进去网址后点击:
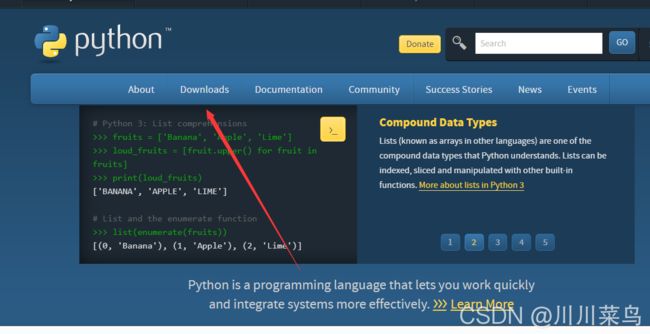
10

11-下载好后

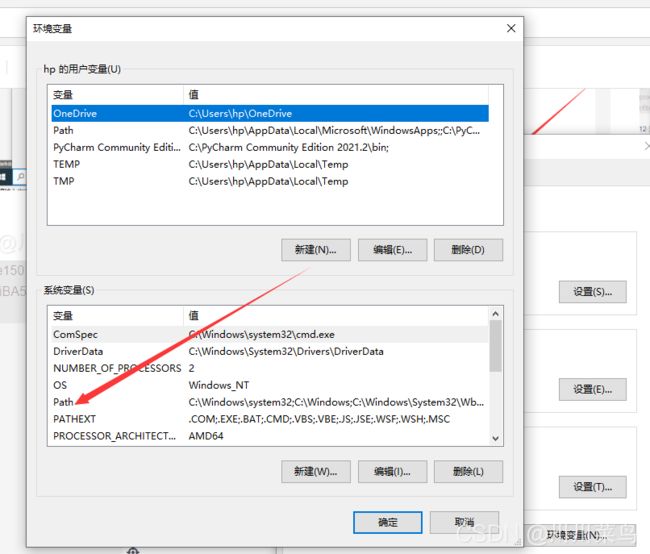
12-添加环境变量
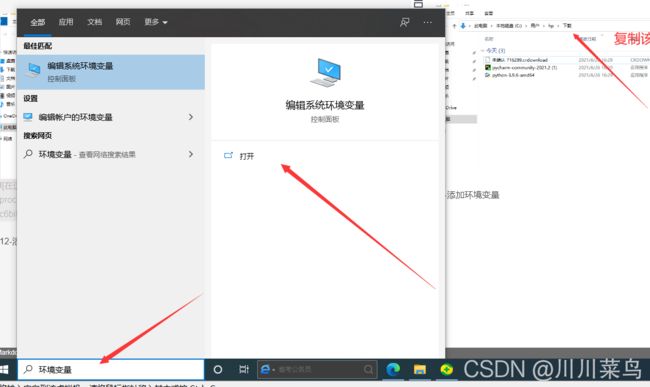



记得双击安装:

三、pycharm上配置python
13-双击桌面pycharm

随便取个名字(我取的学习),直接点击create.
遇到如下情况,则点击ok(没遇到就算了)

14-添加解释器




成功如下:
打印成功:标志配置完成

四、配置镜像源让你下载嗖嗖的快

我喜欢用清华的,所以我在这里介绍都用清华源,当然这里是一些比较好用的镜像源:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
一共有三种镜像源配置,建议你每一种都跟我一起学会。
4.1)pycharm内部配置
第一步:
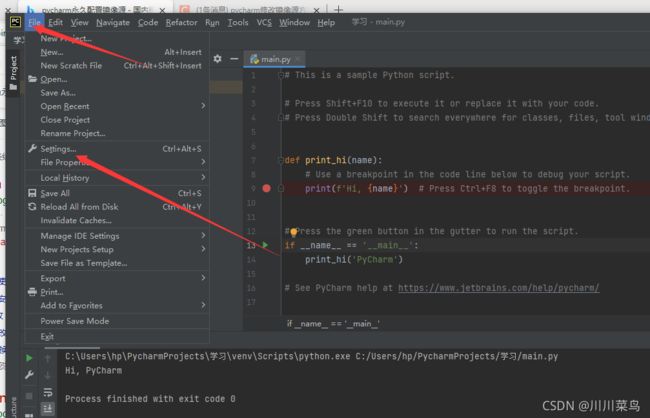
第二步:
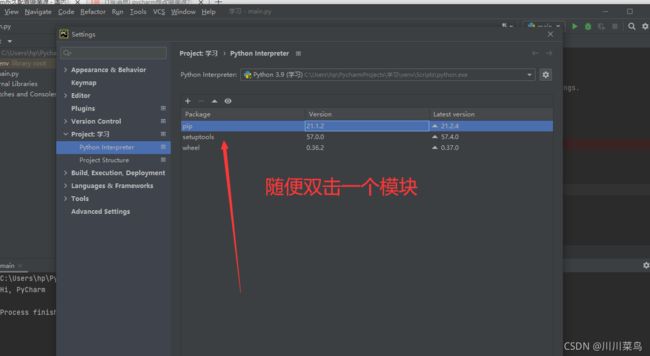
第三步:
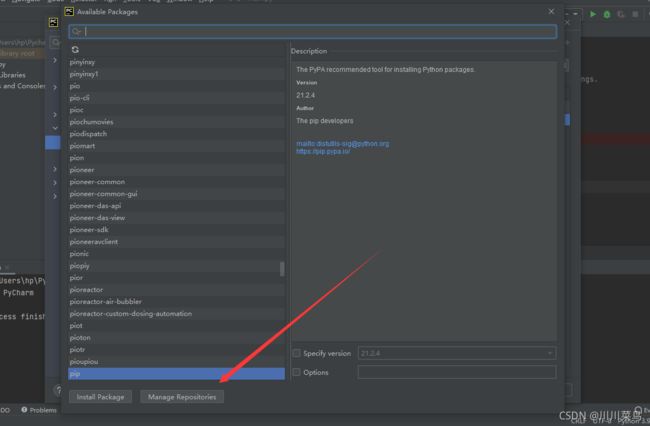

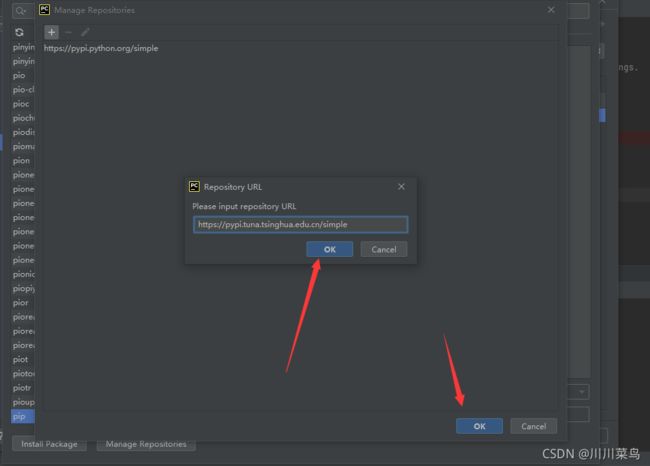
第四步:
复制上面的清华镜像源粘贴,然后okokokok
测试,遇到了这个问题:
pip : 无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。

因为我忘记给pip加环境变量了,所以加一下,一次如下:



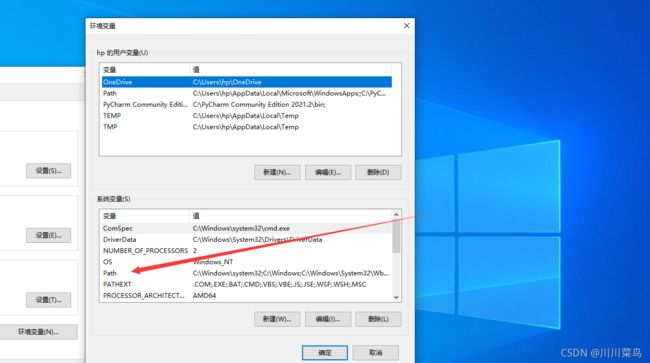
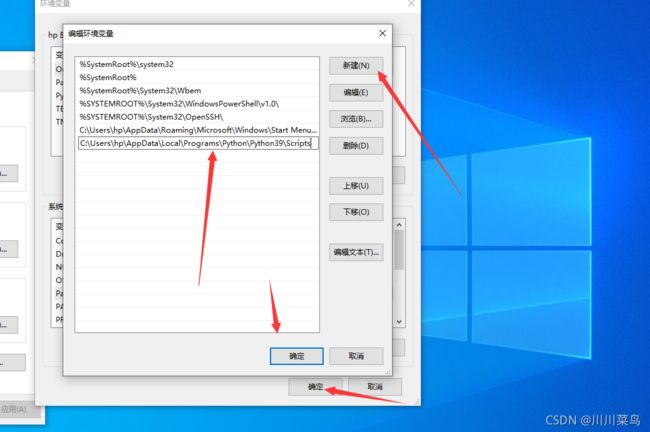
第五步:
退出pycharm,因为加了环境变量需要重启软件。我们先到cmd输入pip,如下就是配置成功了:

第六步:
重启软件后,随便装一个模块,如下:(你可以看到下载模块速度很快!)

4.2)手动添加镜像源
使用方法:
pip install 下载的模块名 -i https://pypi.tuna.tsinghua.edu.cn/simple
比如我要下载numpy这个模块,执行以下命令:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
几秒就好了:

这个方法的好处就是,你不用像其它配置一样要去配置一遍,你只需要在后面加上:
-i https://pypi.tuna.tsinghua.edu.cn/simple
4.3)永久配置镜像源
这个配置我是建议你一定要添加配置。
方法一:
到cmd执行如下命令创建pip.ini:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
返回:

然后我们把这个路径添加到系统环境变量就好了(怎么添加环境变量?跟前面给pip添加环境变量一样操作,只是路径不一样)
方法二:
如果刚刚这个命令你执行失败,你可以自己在c盘任意找个位置创建一个文件名叫做pip文件夹,在这下面下创建一个文件名pip.ini,内容为:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
然后添加到环境变量。
五、插件安装(比如汉化?)

首先个人不建议汉化,最后我再演示汉化插件。我是想要推荐一些不错的插件。
首先进入如下界面:
5.1)自动补码神器第一款
推荐使用:TabNine,当然kite也不错,你可以都安装,我是都在用。我演示一款:



弹出这个页面删了不要管:

测试:已经开始有提示了
5.2 )自动补码神器第二款
(底部扫码也可以)到我公众号:川川菜鸟 发送:kite 即可领取kite软件,无脑安装配置就饿可以了。实在不会左侧加我再给你说。

直接跳转我这一篇文章,如果你效果跟我一样,那就是成功了:
Kite神器
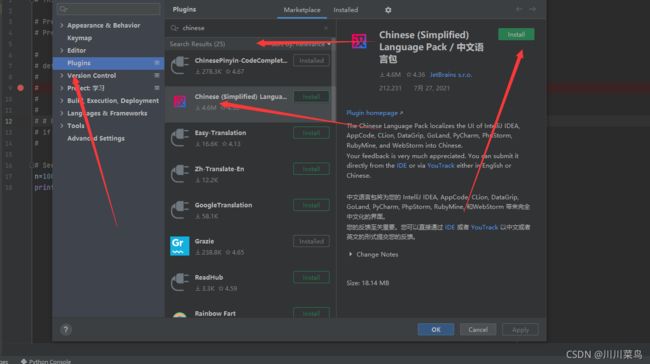
5.2)汉化pycharm
首先,个人不建议汉化,不管你英语好不好,都要去适应这个英语界面,当然你实在需要汉化,这是教程:


现在就已经全部汉化:
5.3)其它插件
如果需要下载别的插件,你可以百度搜一下pycharm有哪些好的插件,都是安装上述方式安装。
六、美女背景
你是否想要如下桌面?
教程传送门:
美女桌面背景设置
七、自定义脚本开头
你是都在先每次创建一个文件,开头都是如下?

节约版面,跳转此文:
自定义脚本开头
八、即将开始写代码了!
拥有本篇文章,意味着你拥有一本最完善的书籍,讲得比书上全,语法也会比买的书上更详细,大家要慢慢看。拥有本篇文章,你将基础无敌,从此可以有能力自学一些高级教程。作者写了好几天,实在很累,希望你三连支持。
python,言简意赅就是:通俗易懂,功能强大无比,上手快,实用强。你跟着我在这里认真学完这一篇,你一定会学会最扎实的python基础,同时我还可以提供免费辅导,作者本是一名学生,并不图有任何好处。如果需要辅导,可以加从左侧栏加群,当然仅是交流,不会有时间一直教你,只能帮助你解决一些问题,更多要靠自己。

九、python入门
软件安装我就不介绍了,大家b站搜一下python和pycharm安装安装即可,个人是推荐python和pycharm结合使用,pycharm是什么?是python的编译器,如果我们没有编译器,写代码是很困难的,而且pycharm提供了许多插件和优美的界面,使得你写代码又快又舒服,不会因为在python的IDE上写得头疼。
当然!下载软件不用到官网下,你只需要到软件管家下载即可,我也是这个公众号的忠实粉丝了。
入门第一步:打印
print("Hello, World!")
当然,你想打印别的也可以,对吧?
print('川川帅哥,我爱你')

十、python缩进
最基本的语法,我不可能在这里把所有的语法都讲一遍,但是最基本语法要说一下。在这里,我们又不得不鸣谢pycharm编译器,实在帮助我们太多了。为什么这么说?pycharm中,它会自动帮助我们完成换行,缩进等问题,不会像IDE中写代码,要自己手动,如果忘记手动就回报错,因此我是不建议只用python解释器,一定要用pycharm!
举一些例子,当然,如果你是小白,现在只会打印,大可不必着急,你只需要看看,后面我会讲到。
比如缩进问题,缩进是指代码行开头的空格。if后面的语句需要tap一下(当然,如果你用pycharm编译器,会自动tap)。
例如:
if 6 > 2:
print("六大于二")

十一、Python注释
注释可用于解释 Python 代码。注释可用于使代码更具可读性。注释可用于在测试代码时阻止执行。
1)单行注释
将需要注释的部分开头用#
例如:
#川川真帅
print('川川帅哥,我爱你')
或者这样:
print("Hello, World!") #川川真帅
你可以看到如下,这就是注释意义了,懂了吧。
2)多行注释
第一种方法(不建议,太麻烦)
#川川真帅
#川川真帅
#川川真帅
print("Hello, World!")
你也可以左键选中我们需要注释的代码,松开,按:Ctrl+/,就完成相同效果注释。
第二种方法:
把要注释的内容放到三个引号对里面。,例如:
'''
川川真帅
川川真帅
'''
print('川川帅哥,我爱你')
取消注释
左键选中我们需要取消注释的代码,松开,按:Ctrl+/
十二、Python 变量
1)变量定义理解
在 Python 中,当你给它赋值时就会创建变量:Python 没有用于声明变量的命令。变量在您第一次为其赋值时创建。
例如:
x = 5
y = "川川"
print(x)
print(y)
对于同一个变量,赋值类型不同则会发生类型的变化,例如:
x = 4 # x 现在是整形
x = "川川" # x 现在是字符串
print(x)
则打印为:

如果要指定变量的数据类型,可以通过强制转换来完成,比如:
x = str(3) # x will be '3'
y = int(3) # y will be 3
z = float(3) # z will be 3.0
那么刚刚我说到了类型,小白肯定还不知道类型是什么,怎么查看,我们来说一下如何获取类型,这里我们要用到type函数,举个例子:
x = 5
y = "川川"
print(type(x))
print(type(y))
看看返回什么:int为整形,str为字符串。这是你要背的。

可以使用单引号或双引号来声明字符串变量:
x1 = "川川真棒"
x2 = '川川真棒'
print(x1)
print(x2)
返回为:

变量名区分大小写:
a = 4
A = "川川"
print(a)
print(A)
返回为:

2) 变量名命名
变量可以有一个简短的名称(如 x 和 y)或一个更具描述性的名称(age、carname、total_volume)。Python 变量的规则:
- 变量名必须以字母或下划线字符开头
- 变量名不能以数字开头
- 变量名称只能包含字母数字字符和下划线(Az、0-9 和 _ )
- 变量名区分大小写(age、Age和AGE是三个不同的变量)
例如:
myvar = "川川"
my_var = "川川""
_my_var = "川川""
myVar = "川川""
MYVAR = "川川""
myvar2 = "川川""
命名法则:
骆驼法则:除了第一个单词外,每个单词都以大写字母开头
myNameIs = "川川"
帕斯卡法则:每个单词都以大写字母开头
MyNameIs = "川川"
蛇形法则:每个单词由下划线字符分隔
My_Name_Is = "川川"
3) 分配多个值
多个变量的多个值。
Python 允许您在一行中为多个变量赋值:
x, y, z = "川川一号", "川川二号", "川川三号"
print(x)
print(y)
print(z)
输出为:

注意:确保变量的数量与值的数量相匹配,否则你会得到一个错误。
多个变量的一个值
您可以在一行中为多个变量分配相同的值:
x = y = z = "川川菜鸟"
print(x)
print(y)
print(z)
输出为:

打开一个集合
如果您在列表、元组等中有一组值。Python 允许您将值提取到变量中。这称为拆包。当然,在这里,你可能还不知道集合列表,元组是什么,没有关系,后面我会讲到。
fruits = ["apple", "banana", "cherry"]
x, y, z = fruits
print(x)
print(y)
print(z)
4)输出变量
print语句通常用于输出变量。
为了组合文本和变量,Python 使用 +字符:
x = "川川"
print("帅哥是" + x)
输出为:
![]()
您还可以使用该+字符将一个变量添加到另一个变量中:
x = "川川真"
y = "帅"
z = x + y
print(z)
返回一样:
![]()
对于数字,该+字符用作数学运算符:
x = 6
y = 10
print(x + y)
返回:
![]()
如果你尝试组合一个字符串和一个数字,Python 会给你一个错误,比如:
```c
x = 5
y = "川川"
print(x + y)
该怎么修改呢?把数字转为字符即可,则修改为:
x = 5
y = "川川"
print(str(x) + y)
成功返回:
![]()
5)全局变量与局部变量,全局关键字
在函数外部创建的变量称为全局变量。都可以使用全局变量,无论是在函数内部还是外部。当然,在这里,你可能还不知道函数是什么,后面我会讲到,大可不必慌张。
x = "川川"
def myfunc():
print("帅哥是 " + x)
myfunc()
返回为:

如果在函数内部创建同名变量,该变量将是局部变量,只能在函数内部使用。具有相同名称的全局变量将保持原样,全局且具有原始值。
x = "awesome"
def myfunc():
x = "fantastic"
print("Python is " + x)
myfunc()
print("Python is " + x)
返回为:

全局关键字
通常,当您在函数内部创建变量时,该变量是局部的,并且只能在该函数内部使用。要在函数内创建全局变量,可以使用 global关键字。
x = "帅哥"
def myfunc():
global x
x = "菜鸟"
myfunc()
print("川川" + x)
返回为:
![]()
6)练习题
- 创建一个名为的变量carname并为其赋值菜鸟。
- 创建一个名为的变量x并为其赋值60。
- 5 + 10使用两个变量x和y。显示,打印它们的总和
- 创建一个名为的变量z,x=8,y=9,分配x + y给它,并显示结果。
十三、Python数据类型

1)置数据类型
默认情况下,Python 具有以下内置数据类型,在这些类别中:
文本类型: str
数字类型: int, float, complex
序列类型: list, tuple, range
映射类型: dict
套装类型: set, frozenset
布尔类型: bool
二进制类型: bytes, bytearray, memoryview
此时你大可不必知道这些类型到底是什么,在后续的深入中,你一定会用得到,所以是需要记住的。
2)获取数据类型
您可使用以下type()函数获取任何对象的数据类型。
例如,打印变量 x 的数据类型:
x = 6
print(type(x))
我们可以看到返回为:int类型
![]()
3)设置数据类型
在 Python 中,数据类型是在为变量赋值时设置的。
例如以下例子。
str字符串:
x = "Hello World"
print(x)
print(type(x))
int整形:
x1 = 6
print(type(x1))
float浮点类型:
x2 = 6.5
print(type(x2))
complex复数类型:
x3 = 2j
print(x3)
print(type(x3))
list列表类型:
x4 = ["apple", "banana", "cherry"]
print(x4)
print(type(x4))
tuple元祖类型:
x5 = ("apple", "banana", "cherry")
print(x5)
print(type(x5))
后面还有其它一些类型,我就不以完整代码形式演示了,直接以例子形式让大家看看什么样子是什么类型,当然如果你能亲自动手像我上面的例子一样进行操作打印看一看就再好不过了。
range范围类型
x = range(6
dict字典类型
x = {
"name" : "John", "age" : 36}
set集合类型:
x = {
"apple", "banana", "cherry"}
不常用的冻结集类型:
x = frozenset({
"apple", "banana", "cherry"})
bool布尔类型:
x = True
不常用byte字节类型:
x = b"Hello"
不常用bytearray字节数组类型:
x = bytearray(5)
更有冷门到爆的memoryview内存试图类型
x = memoryview(bytes(5))
4)设置特定数据类型
我会举一些例子说明,尽量很全,大可不必担心。先举一个完整例子,后面的是一样的打印就不演示了。
强调特定x为字符串:
x = str("Hello World")
print(x)
print(type(x))
返回为:

强调x为整形:
x = int(20)
强调x为浮点:
x = float(20.5)
强调x为复数:
x = complex(1j)
强调为列表
x = list(("apple", "banana", "cherry"))
强调为元祖
x = tuple(("apple", "banana", "cherry"))
强调为范围
x = range(6)
强调为字典
x = dict(name="John", age=36)
强调为集合
x = set(("apple", "banana", "cherry"))
强调冻结集(没啥用的类型)
x = frozenset(("apple", "banana", "cherry"))
强调布尔类型
x = bool(5)
强调字节类型
x = bytes(5)
强调字节组类型
x = bytearray(5)
强调内存试图类型(又是没啥用的类型)
x = memoryview(bytes(5))
6)练习题
回答下面的问题结果为什么类型?
1-
x = 5
print(type(x))
2-
x = "Hello World"
print(type(x))
3-
x = 20.5
print(type(x))
4-
x = ["apple", "banana", "cherry"]
print(type(x))
5-
x = ("apple", "banana", "cherry")
print(type(x))
6-
x = {
"name" : "John", "age" : 36}
print(type(x))
7-
x = True
print(type(x))
十四、python数字

Python 共有三种数字类型:
- int
- float
- complex
三种类型分别对应如下例子:
x = 1 # int
y = 2.8 # float
z = 1j # complex
要验证 Python 中任何对象的类型,请使用以下type()函数:
print(type(x))
print(type(y))
print(type(z))
因此你可以运行如下代码:
x = 1 # int
y = 2.8 # float
z = 1j # complex
print(type(x))
print(type(y))
print(type(z))
1)整数
Int 或 integer,是一个整数,正负,不带小数,长度不限。
例如:
x = 1
y = 3562254887
z = -35522
print(type(x))
print(type(y))
print(type(z))
2)浮点数
浮点数或“浮点数”是包含一位或多位小数的正数或负数。
例如:
x = 1.10
y = 1.0
z = -35.59
print(type(x))
print(type(y))
print(type(z))
浮点数也可以是带有“e”的科学数字,表示 10 的幂。
例如:
x = 35e3
y = 12E4
z = -87.7e100
print(type(x))
print(type(y))
print(type(z))
3)虚数
复数写有“j”作为虚部。
x = 3+5j
y = 5j
z = -5j
print(type(x))
print(type(y))
print(type(z))
4)类型转换
比如你可以从一种类型转变成另一种同int(), float()和complex()方法。
例如:(你可以亲自运行一下)
x = 1 # int
y = 2.8 # float
z = 1j # complex
a = float(x)
b = int(y)
c = complex(x)
print(a)
print(b)
print(c)
print(type(a))
print(type(b))
print(type(c))
5)随机数
Python 有一个内置模块 random可以用来生成随机数。
示例:导入 random 模块,并显示 1 到 10之间的一个随机数:
import random
print(random.randrange(1, 11))
6)练习题
1-插入正确的语法将 x 转换为浮点数。
x = 5
x = _(x)
2-插入正确的语法以将 x 转换为整数。
x = 5.5
x = _(x)
3-插入正确的语法以将 x 转换为复数。
x = 5
x = _(x)
十五、python指定变量类型

python 中的转换是使用构造函数完成的:
- int() - 从整数文字、浮点文字(通过删除所有小数)或字符串文字(提供字符串表示整数)构造整数
- float() - 从整数文字、浮点文字或字符串文字构造浮点数(提供字符串表示浮点数或整数)
- str() - 从多种数据类型构造一个字符串,包括字符串、整数文字和浮点文字
我将每一个类型都举例子说明。
整数
x = int(1) # x will be 1
y = int(2.8) # y will be 2
z = int("3") # z will be 3
浮点
x2 = float(1) # x will be 1.0
y2 = float(2.8) # y will be 2.8
z2 = float("3") # z will be 3.0
w2 = float("4.2") # w will be 4.2
字符串
x1 = str("s1") # x will be 's1'
y1 = str(2) # y will be '2'
z1 = str(3.0) # z will be '3.0'
十六、Python字符串
一、字符串基本使用
1)字符串理解
python 中的字符串被单引号或双引号包围。'hello’与"hello"相同。您可以使用以下print()函数显示字符串文字:
print("Hello")
print('Hello')
2)将字符串分配给变量
a = "川川"
print(a)
3)多行字符串
您可以使用三个引号将多行字符串分配给变量:
a = """从前有座山,
山里有座庙
庙里有个小和尚"""
print(a)
返回如下:

或三个单引号:
a = '''从前有座山,
山里有座庙
庙里有个小和尚'''
print(a)
4)字符串是数组
Python 没有字符数据类型,单个字符只是一个长度为 1 的字符串。方括号可用于访问字符串的元素。这里用到了切片,你可以不懂。
获取位置 1 处的字符(记住第一个字符的位置为 0):
a = "Hello, World!"
print(a[1])
5)遍历字符串
循环遍历单词“chuanchuan”中的字母:
for x in "chuanchuan":
print(x)
6)字符串长度
len()函数返回字符串的长度,注意标点符号和空格也算一个长度:
a = "Hello, World!"
print(len(a))
7)检查字符串
要检查字符串中是否存在某个短语或字符,我们可以使用关键字 in。
txt = "The best things in life are free!"
print("free" in txt)
返回布尔类型(True代表有):
![]()
也可以通过if来判断是否存在:
txt = "The best things in life are free!"
if "free" in txt:
print("是的, 'free'存在.")
8)检查如果不是
检查以下文本中是否不存在“川川”:
txt = "川川就读上海交大!"
print("川川" not in txt)
因为存在,返回false:

仅在不存在“川川”时才打印:
txt = "川川就读上海交大!"
if "川川" not in txt:
print("No, '川川' 不在文档.")
因为不符合条件,所以不会打印。
二、切片字符串
1)切片
您可以使用切片语法返回一系列字符。指定开始索引和结束索引,以冒号分隔,以返回字符串的一部分。
示例:获取从位置 2 到位置 5 的字符(不包括在内):
b = "Hello, World!"
print(b[2:5])
返回为:

注意:第一个字符的索引为 0。

2)从头开始切片
示例:获取从开始到位置 5 的字符(不包括在内):
b = "Hello, World!"
print(b[:5])
返回为:
![]()
3)切到最后
通过省略结束索引,范围将到最后。
例如,获取从位置 2 到最后的字符:
b = "Hello, World!"
print(b[2:])
返回:
![]()
4)负索引
使用负索引从字符串末尾开始切片,就是从右往左看,不再是从左往右看。
例如:
b = "Hello, World!"
print(b[-5:-2])
返回为:
![]()
三、修改字符串

1)小写转大写
upper()方法以大写形式返回字符串:
a = "Hello, World!"
print(a.upper())
返回为:

2)大写转小写
lower()方法以小写形式返回字符串:
a = "Hello, World!"
print(a.lower())
返回为:
![]()
3)删除空格
空白是实际文本之前和/或之后的空间,通常您想删除这个空间。
strip()方法从开头或结尾删除任何空格:
a = " Hello, World! "
print(a.strip())
返回为:
![]()
4)替换字符串
replace()方法用另一个字符串替换一个字符串.
a = "Hello, World!"
print(a.replace("H", "J"))
返回为:
![]()
5)拆分字符串
split()方法返回一个列表,其中指定分隔符之间的文本成为列表项。split()如果找到分隔符的实例,该方法会将字符串拆分为子字符串。
例如我要将下面的字符串以逗号分隔:
a = "Hello, World!"
print(a.split(","))
返回为:
![]()
四、字符串连接
要连接或组合两个字符串,您可以使用 + 运算符。
例如,将变量a与变量b, 合并到变量中c:
a = "Hello"
b = "World"
c = a + b
print(c)
返回为:

例如要在a和b变量之间添加空格,请添加" ":
a = "Hello"
b = "World"
c = a + " " + b
print(c)
返回为:
![]()
五、格式化字符串
1)format单个传参
我们不能像这样组合字符串和数字:
#会报错
age = 20
txt =" 川川今年 " + age
print(txt)
但是我们可以通过使用format() 方法来组合字符串和数字!format()方法接受传递的参数,格式化它们,并将它们放在占位符所在的字符串中 {}。
例如,使用format()方法将数字插入字符串:
age = 20
txt = "川川今年 {}"
print(txt.format(age))
返回为:
![]()
2)format多个个传参
format() 方法接受无限数量的参数,并放置在各自的占位符中:
quantity = 20
itemno = 3000
price = 49.95
myorder = "川川今年 {}岁 买了个华为手机 {} 每个月花费 {} 元."
print(myorder.format(quantity, itemno, price))
返回为:
![]()
您可以使用索引号{0}来确保参数放置在正确的占位符中:
quantity = 20
itemno = 3000
price = 49.95
myorder = "川川今年 {2}岁 买了个华为手机 {0} 每个月花费 {1} 元."
print(myorder.format(quantity, itemno, price))
这样就会导致数字传的顺序发生了变化,看看结果就明白了:
![]()
六、字符串的其它处理方法总结
- capitalize() 将第一个字符转换为大写
- casefold() 将字符串转换为小写
- center() 返回一个居中的字符串
- count() 返回指定值在字符串中出现的次数
- encode() 返回字符串的编码版本
- endswith() 如果字符串以指定的值结尾,则返回 true
- join() 将可迭代的元素连接到字符串的末尾
- find() 在字符串中搜索指定值并返回找到它的位置
- format() 初始化字符串中的指定值
10.index() 在字符串中搜索指定值并返回找到它的位置
当然还有很多,个人感觉不是很常用,就不继续总结别的了。
七、练习题
1-使用 len 方法打印字符串的长度。
x = "Hello World"
print( )
2-获取字符串 txt 的第一个字符。
txt = "Hello World"
x =
3.获取从索引 2 到索引 4 (llo) 的字符。
txt = "Hello World"
x =
4.返回开头或结尾没有任何空格的字符串。
txt = " Hello World "
x =
提示 使用strip()
5-将 txt 的值转换为大写。
txt = "Hello World"
txt =
6-将 txt 的值转换为小写。
txt = "Hello World"
txt =
7-用 J 替换字符 H。
txt = "Hello World"
txt = txt.
8-插入正确的语法以添加年龄参数的占位符。
age = 36
txt = "My name is John, and I am "
print(txt.format(age))
提示:{}
十七、Python布尔值

布尔值表示两个值之一: True或False。在编程中,您经常需要知道表达式是否为 True或False。举一些例子就明白了。
1)比较
当您比较两个值时,将计算表达式并且 Python 返回布尔值答案:
print(10 > 9)
print(10 == 9)
print(10 < 9)
返回为:

在 if 语句中运行条件时,Python 返回 True or False:
a = 100
b = 30
if b > a:
print("b大于a")
else:
print("b不大于a")
返回为:
![]()
2)评估值和变量
bool()函数允许您评估任何值,并给您 True或False 作为返回。
例如:评估一个字符串和一个数字
print(bool("川川"))
print(bool(20))
返回为:

评估两个变量:
x = "川川"
y = 15
print(bool(x))
print(bool(y))
返回为:

3)布尔真值
True如果它具有某种内容,几乎任何值都会被评估。任何字符串都是True,空字符串除外。任何数字都是True,除了 0。任何列表、元组、集合和字典都是True,空的除外。
例如以下都会返回True:
bool("abc")
bool(123)
bool(["apple", "cherry", "banana"])
4)布尔假值
实际上,False除了空值(例如()、 []、{}、 “”、 数字 0和 值 )之外,计算为 的值 None。当然,结果为 False。
bool(False)
bool(None)
bool(0)
bool("")
bool(())
bool([])
bool({
})
返回为:

5)函数可以返回布尔值
def myFunction() :
return True
print(myFunction())
返回为:

打印“YES!” 如果函数返回 True,否则打印“NO!”:
def myFunction() :
return True
if myFunction():
print("YES!")
else:
print("NO!")
Python 也有许多返回布尔值的内置函数,如 isinstance() 函数,可用于确定对象是否属于某种数据类型
例如:检查对象是否为整数
x = 200
print(isinstance(x, int))
返回为
![]()
6)练习题
1.回答下面的语句返回值True还是False:
print(10 > 9)
2.回答下面的语句返回值True还是False:
print(10 == 9)
3.回答下面的语句返回值True还是False:
print(10 < 9)
4.回答下面的语句返回值True还是False:
print(bool("abc"))
5.回答下面的语句返回值True还是False:
print(bool(0))
十八、python运算符

1)算术运算符
自己赋值粘贴运行下就懂了!
加减法:(+ -)
a=2
b=3
c=a-b
d=a-b
print(c,d)
乘除法:(* /)
a=(50-5*6)/4
print(a)
a=8/5
print(a)
取余数(同时与除法比较)
'''/返回为float,//返回整数,%返回余数'''
a=17/3
print(a)
a=17//3
print(a)
a=5*3+2
print(a)
幂运算 (**’)
'''幂运算 **'''
# a=4**2
# b=2**3
# print(a,b)
2)赋值运算符
等于(=)
x = 5
print(x)
加等于( +=)等效: x = x +
x = 5
x += 3
print(x)
减等于(-=) 等效:x=x-
x = 5
x -= 3
print(x)
类似的我们可以得到以下不同的方式等效:
x *= 3 等效 x = x * 3
x /= 3等效 x = x / 3
x %= 3 等效 x = x % 3
x //= 3 等效 x = x // 3
x **= 3 等效 x = x ** 3
x &= 3 等效 x = x & 3
x |= 3 等效 x = x | 3
x ^= 3 等效 x = x ^ 3
x >>= 3 等效x = x >> 3
x <<= 3 等效x = x << 3

十九、Python列表
一、列表基本知识
基本形式为:
mylist = ["川川一号", "川川二号", "川川三号"]
1)创建列表
列表是使用方括号创建的:
mylist = ["川川一号", "川川二号", "川川三号"]
print(mylist)
返回:
![]()
创建新列表时也可以使用 list() 构造函数。
thislist = list(("apple", "banana", "cherry"))
print(thislist)
允许重复
由于列表已编入索引,因此列表可以包含具有相同值的项目:
thislist = ["川川一号", "川川二号", "川川三号","川川一号"]
print(thislist)
2.列出表值
列表项是有序的、可变的,并允许重复值。列表项被索引,第一项有索引[0],第二项有索引[1]等等。
单个索引
例如我要索取川川一号:
mylist = ["川川一号", "川川二号", "川川三号"]
print(mylist)
print(mylist[0])
返回:

遍历列表
for i in mylist:
print(i)
返回为:

3.列表长度
确定列表有多少项,请使用以下 len()函数:
thislist = ["川川一号", "川川二号", "川川三号","川川一号"]
print(len(thislist))
返回:
![]()
4.列表项 - 数据类型
列表项可以是任何数据类型。例如:
list1 = ["apple", "banana", "cherry"]
list2 = [1, 5, 7, 9, 3]
list3 = [True, False, False]
print(list1)
print(list2)
print(list3)
5.Python 集合(数组)
- List列表是一个有序且可变的集合。允许重复成员。
- turple元组是一个有序且不可更改的集合。允许重复成员。
- Set集合是一个无序且无索引的集合。没有重复的成员。
- dict字典是一个有序*且可变的集合。没有重复的成员。
!!!从 Python 3.7 版开始,字典才是有序的!!!
二.访问列表
1.正常索引
列表项已编入索引,您可以通过引用索引号来访问它们:
mylist = ["川川一号", "川川二号", "川川三号"]
print(mylist[0])
注意:第一项的索引为 0。
2)负索引
负索引意味着从头开始,-1指最后一项, -2指倒数第二项等。
mylist = ["川川一号", "川川二号", "川川三号"]
print(mylist[-1])
3)索引范围
mylist = ["川川一号", "川川二号", "川川三号"]
print(mylist[1:3])
4)负指数范围
mylist = ["川川一号", "川川二号", "川川三号"]
print(mylist[-3:-1])
5)检查是否存在
要确定列表中是否存在指定的项目,请使用in关键字。
例如,检查列表中是否存在“apple”:
thislist = ["apple", "banana", "cherry"]
if "apple" in thislist:
print("Yes, 'apple' is in the fruits list")
三、更改列表
1)单个更改
要更改特定位置的值,需要通过索引号:
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist[0]="川川五号"
print(mylist[0])
修改成功:
![]()
2)多个更改
索引号需要用范围表示。
mylist = ["川川一号", "川川二号", "川川三号","川川四号","川川五号"]
mylist[1:3]=["哈皮川川","憨批川川"]
print(mylist)
修改成功:
![]()
3)插入列表
insert()方法在指定的索引处插入一个项目。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.insert(2,'帅哥呀')
print(mylist)
插入成功:

四、添加列表
1)末尾添加
要将值添加到列表的末尾,请使用append() 方法:
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.append("憨批川川")
print(mylist)
添加成功:
![]()
2)指定位置添加
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.insert(2,'川川菜鸟')
print(mylist)
添加成功:
![]()
3)合并列表
要将另一个列表中的元素附加到当前列表,请使用extend()方法。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist1 = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.extend(mylist1)
print(mylist)
合并成功:
![]()
extend()方法不一定要 列表,您也可以添加任何可迭代对象(元组、集合、字典等)。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist2=("川川","菜鸟")
mylist.extend(mylist2)
print(mylist)
添加成功:
![]()
五、删除列表

1)删除指定目标
remove()方法删除指定的项目。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.remove('川川二号')
print(mylist)
删除成功:
![]()
2)删除指定索引
pop()方法删除指定的索引。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.pop(2)
print(mylist)
删除成功:
![]()
如果不指定索引,该pop()方法将删除最后一项。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.pop()
print(mylist)
删除成功:
![]()
3)del删除指定的索引
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
del mylist[0]
print(mylist)
删除成功:
![]()
该del关键字也可以完全删除列表。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
del mylist
4)清除列表
clear()方法清空列表。该列表仍然存在,但没有内容。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.clear()
print(mylist)
清空:
![]()
坚持!!!

六、循环列表
1)for循环遍历
方法一:
循环遍历列表您可以使用循环遍历列表项for 。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
for i in mylist:
print(i)
遍历成功:

方法二:遍历索引号
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
for i in range(len(mylist)):
print(mylist[i])
返回:

2)while循环遍历
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
i = 0
while i < len(mylist):
print(mylist[i])
i = i + 1
返回:

七、列表推导式
例如:根据fruits列表,您需要一个新列表,其中仅包含名称中带有字母“a”的fruits。
如果没有列表理解,您将不得不编写一个for带有条件测试的语句:
fruits = ["apple", "banana", "cherry", "kiwi", "mango"]
newlist = []
for x in fruits:
if "a" in x:
newlist.append(x)
print(newlist)
返回为:
![]()
使用列表推导式,你只需要一行代码即可!
fruits = ["apple", "banana", "cherry", "kiwi", "mango"]
newlist = [x for x in fruits if "a" in x]
print(newlist)
返回一样:
![]()
换一个例子,只接受小于 5 的数字:
newlist = [x for x in range(10) if x < 5]
print(newlist)
返回“orange”而不是“banana”:(这个不是很好理解,多想想)
fruits = ["apple", "banana", "cherry", "kiwi", "mango"]
newlist = [x if x != "banana" else "orange" for x in fruits]
print(newlist)
返回为:
![]()
八、列表排序
1)区分大小写的排序
默认情况下,该sort()方法区分大小写,导致所有大写字母都排在小写字母之前:
thislist = ["banana", "Orange", "Kiwi", "cherry"]
thislist.sort()
print(thislist)
返回:

2)不区分大小写的排序
如果你想要一个不区分大小写的排序函数,使用 str.lower 作为键函数:
thislist = ["banana", "Orange", "Kiwi", "cherry"]
thislist.sort(key = str.lower)
print(thislist)
返回:
![]()
3)倒序
reverse()方法反转元素的当前排序顺序。
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
mylist.reverse()
print(mylist)
返回为:

九、复制列表
copy()方法制作列表的副本:
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
my = mylist.copy()
print(my)
返回:
![]()
list()方法制作列表的副本:
mylist = ["川川一号", "川川二号", "川川三号","川川四号"]
my = list(mylist)
print(my)
返回为:
![]()
十、加入列表
最简单的方法之一是使用+ 运算符。
list1 = ["a", "b", "c"]
list2 = [1, 2, 3]
list3 = list1 + list2
print(list3)
返回:
![]()
稍微有意思点,连接两个列表的另一种方法是将 list2 中的所有项一个一个地附加到 list1 中:
list1 = ["a", "b" , "c"]
list2 = [1, 2, 3]
for x in list2:
list1.append(x)
print(list1)
返回:

extend() 方法,其目的是将元素从一个列表添加到另一个列表:
list1 = ["a", "b" , "c"]
list2 = [1, 2, 3]
list1.extend(list2)
print(list1)
返回:
![]()
十一、列表所有操作总结
如果你英文好可以看看,当然,这些所有操作我都讲过一遍了。

十二、练习
1-打印fruits列表中的第二项。
fruits = ["apple", "banana", "cherry"]
print( )
2-将fruits列表中的值从“apple”改为“kiwi”。
fruits = ["apple", "banana", "cherry"]
=
3-使用 append 方法将“orange”添加到fruits列表中。
fruits = ["apple", "banana", "cherry"]
4-使用插入方法将“柠檬”添加为fruits列表中的第二项。
fruits = ["apple", "banana", "cherry"]
="lemon")
5-使用 remove 方法从fruits列表中删除“banana”。
fruits = ["apple", "banana", "cherry"]
6-使用负索引打印列表中的最后一项。
fruits = ["apple", "banana", "cherry"]
print( )
7-使用索引范围打印列表中的第三、第四和第五项。
fruits = ["apple", "banana", "cherry", "orange", "kiwi", "melon", "mango"]
print(fruits[])
8-使用正确的语法打印列表中的项目数
fruits = ["apple", "banana", "cherry"]
print( )
二十、Python元组

一、元组理解
1.1)基本定义
元组用于在单个变量中存储多个项目。Tuple 是 Python 中用于存储数据集合的 4 种内置数据类型之一,其他 3 种是List、 Set和Dictionary,它们具有不同的性质和用法。元组是一个集合是有序的和不可改变的。元组是用圆括号写的。
基本形式如下:
mytuple = ("川川一号", "川川二号", "川川三号")
print(mytuple)
元组项是有序的、不可更改的,并允许重复值。元组项被索引,第一项被索引[0],第二项被索引[1]等。
允许重复举个例子:
mytuple = ("川川一号", "川川二号", "川川三号",'川川一号')
print(mytuple)
索引举个例子:
mytuple = ("川川一号", "川川二号", "川川三号")
# print(mytuple)
print(mytuple[0])
1.2)元组长度
我们还是跟列表一样,用到len函数,例子如下:
mytuple = ("川川一号", "川川二号", "川川三号",'川川一号')
# print(mytuple)
print(len(mytuple))
返回长度:
![]()
一项元组,记住逗号,不然就不是元祖了!我将两个形式读写出来,可以做一个对比:
mytuple = ("川川一号", )
print(type(mytuple))
mytuple = ("川川一号")
print(type(mytuple))
我们来看看返回什么:第一个是元祖,第二个是字符串。

1.3)数据类型
元组项可以是任何数据类型:字符串、整数和布尔数据类型.
tuple1 = ("川川一号", "川川二号", "川川三号",'川川一号')
tuple2 = (1, 8, 5, 9, 3)
tuple3 = (True, False, False)
元组可以包含不同的数据类型。
包含字符串、整数和布尔值的元组,形式如下:
tuple4 = ("川川一号", 34, True, 40, "帅哥")
使用tuple()来创建元组,形式如下:
tuple5 = tuple(("川川一号", "川川二号", "川川三号",'川川一号'))
print(tuple5)
二、访问元组
2.1)正常访问
您可以通过引用方括号内的索引号来访问元组项,比如打印第二项:
mytuple = ("川川一号", "川川二号", "川川三号")
# print(mytuple)
print(mytuple[1])
注意:第一项的索引为 0。
2.2)负索引
负索引意味着从头开始。-1指最后一项, -2指倒数第二项等。
例如打印元组的最后一项:
mytuple = ("川川一号", "川川二号", "川川三号")
print(mytuple[-1])
2.3)范围性索引
您可以通过指定范围的开始和结束位置来指定索引范围。指定范围时,返回值将是具有指定项的新元组。这里我们用到range函数,前面讲过。
返回第三、第四和第五项:
mytuple = ("川川一号", "川川二号", "川川三号",'帅哥川川','川川真棒')
print(mytuple[2:5])
注意:搜索将从索引 2(包括)开始并在索引 5(不包括)处结束。
请记住,第一项的索引为 0。
通过省略起始值,范围将从第一项开始(自己打印看看):
mytuple = ("川川一号", "川川二号", "川川三号",'帅哥川川','川川真棒')
print(mytuple[:4])
通过省略结束值,范围将继续到列表的末尾:
mytuple = ("川川一号", "川川二号", "川川三号",'帅哥川川','川川真棒')
print(mytuple[2:])
负数范围
mytuple = ("川川一号", "川川二号", "川川三号",'帅哥川川','川川真棒')
print(mytuple[-4:-1])
检查项目值是否存在
要确定元组中是否存在指定的项目,请使用in关键字:
thistuple = ("川川一号", "川川二号", "川川三号",'帅哥川川','川川真棒')
if "帅哥川川" in thistuple:
print("哈哈, '帅哥川川' 在元祖列表")
返回:
![]()
三、更新元组

元组是不可更改的,这意味着一旦创建了元组,您就无法更改、添加或删除项目。但是有一些解决方法:将元组转换为列表,更改列表,然后将列表转换回元组。
3.1)替换
比如我要将下面第二个元素改为帅哥:
x = ("川川一号", "川川二号", "川川三号",'川川一号')
y = list(x)
y[1] = "帅哥"
x = tuple(y)
print(x)
返回为:

3.2)添加项目值
由于元组是不可变的,它们没有内置 append()方法,但有其他方法可以向元组添加项。
方法1:转换为列表:就像更改元组的解决方法一样,您可以将其转换为列表,添加您的项目,然后将其转换回元组。
例如:将元组转换为列表,添加“爱你”,然后将其转换回元组:
thistuple = ("川川一号", "川川二号", "川川三号",'川川一号')
y = list(thistuple)
y.append("爱你")
thistuple = tuple(y)
print(thistuple)
返回:
![]()
方法2:将元组添加到元组。您可以向元组添加元组,因此如果您想添加一个(或多个)项目,请使用该项目创建一个新元组,并将其添加到现有元组中。
例如:创建一个值为“orange”的新元组,并添加该元组
thistuple = ("川川一号", "川川二号", "川川三号",'川川一号')
y = ("爱你",)
thistuple += y
print(thistuple)
同样返回:
![]()
注意:创建只有一个item的元组时,记得在item后面加上逗号,否则不会被识别为元组。
3.3)删除项目
注意:您不能删除元组中的项目。元组是不可更改的,因此您无法从中删除项目,但您可以使用与我们用于更改和添加元组项目相同的解决方法:
示例
将元组转换为列表,删除“apple”,然后将其转换回元组:
thistuple = ("川川菜鸟", "川川二号", "川川三号",'川川一号')
y = list(thistuple)
y.remove("川川菜鸟")
thistuple = tuple(y)
print(thistuple)
或者您可以完全删除元组:该del关键字可以完全删除的元组
this = ("川川菜鸟", "川川二号", "川川三号",'川川一号')
del this
print(this)
这就会返回错误,因为这个元祖已经不在了。

四、解包元组
当我们创建一个元组时,我们通常会为其分配值。这称为“打包”元组。
包装元组:
fruits = ("apple", "banana", "cherry")
print(fruits)
但是,在 Python 中,我们也可以将值提取回变量中。这称为“解包”。
解包元组:
fruits = ("apple", "banana", "cherry")
(green, yellow, red) = fruits
print(green)
print(yellow)
print(red)
使用星号*
如果变量的数量少于值的数量,您可以*在变量名中添加一个,值将作为列表分配给变量。
将其余值分配为名为“red”的列表:
fruits = ("apple", "banana", "cherry", "strawberry", "raspberry")
(green, yellow, *red) = fruits
print(green)
print(yellow)
print(red)
如果星号被添加到另一个变量名而不是最后一个,Python 将为变量赋值,直到剩余的值数量与剩余的变量数量匹配。
添加值列表“tropic”变量:
fruits = ("apple", "mango", "papaya", "pineapple", "cherry")
(green, *tropic, red) = fruits
print(green)
print(tropic)
print(red)
五、循环元祖
5.1)遍历元祖
也就是遍历元组的意思,只要我们提到遍历,那就是for循环。
方法一:直接遍历
例子如下:遍历项目并打印值
thistuple = ("川川菜鸟", "川川二号", "川川三号",'川川一号')
for i in thistuple:
print(i)
方法二: 遍历索引号
使用range()和len()函数创建合适的可迭代对象。
thistuple = ("川川菜鸟", "川川二号", "川川三号",'川川一号')
for i in range(len(thistuple)):
print(thistuple[i])
返回都i为:

5.2)使用 While 循环
thistuple = ("川川菜鸟", "川川二号", "川川三号",'川川一号')
i = 0
while i < len(thistuple):
print(thistuple[i])
i = i + 1
六、元组合并
合并两个元祖,我们用+连接即可。
tuple1 = ("川川菜鸟", "川川二号", "川川三号",'川川一号')
tuple2 = (1, 2, 3)
tuple3 = tuple1 + tuple2
print(tuple3)
如果要将元组的内容乘以给定次数,可以使用* 运算符:
tuple1 = ("川川菜鸟", "川川二号", "川川三号",'川川一号')
tuple4=tuple1*2
print(tuple4)
返回:
![]()
count函数用于返回指定值次数:查找5出现次数
thistuple = (1, 3, 7, 8, 7, 5, 4, 6, 8, 5)
x = thistuple.count(5)
print(x)
返回:
![]()
index()找出指定值并返回它的位置:查找元祖中8位置
thistuple = (1, 3, 7, 8, 7, 5, 4, 6, 8, 5)
x = thistuple.index(8)
print(x)

七、练习
1-使用正确的语法打印fruits元组中的第一项
fruits = ("apple", "banana", "cherry")
print
2-使用正确的语法打印fruits元组中的项目数。
fruits = ("apple", "banana", "cherry")
print
3-使用负索引打印元组中的最后一项。
fruits = ("apple", "banana", "cherry")
print
4-使用一系列索引打印元组中的第三、第四和第五项。
fruits = ("apple", "banana", "cherry", "orange", "kiwi", "melon", "mango")
print(fruits[])

二十一、Python集合
一、集合理解
基本形式:
myset = {
"川川一号", "川川二号", "川川三号"}
集合是用大括号写的。
创建一个集合:
myset = {
"川川一号", "川川二号", "川川三号"}
print(myset)
返回:

注意:集合是无序的,因此您无法确定项目的显示顺序。
二、访问集合

2.1)遍历集合
您不能通过引用索引或键来访问集合中的项目。但是您可以使用循环遍历集合项for ,或者使用in关键字询问集合中是否存在指定的值 。
例如:
myset = {
"川川一号", "川川二号", "川川三号"}
for i in myset:
print(i)
返回:

3.2)检查是否存在
检查集合中是否存在“串串一号”:(显然不在)
myset = {
"川川一号", "川川二号", "川川三号"}
print('串串一号' in myset)
返回布尔值:
![]()
三、添加集合
3.1)添加项目值

创建集合后,您无法更改其项目,但可以添加新项目。要将一项添加到集合中,请使用add() 方法。
例如:添加川川菜鸟到集合中
myset = {
"川川一号", "川川二号", "川川三号"}
myset.add('川川菜鸟')
print(myset)
返回:
![]()
3.2)添加集合
要将另一个集合中的项目添加到当前集合中,请使用update() 方法。
例如将myset1添加到myset中:
myset = {
"川川一号", "川川二号", "川川三号"}
myset1 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset.update(myset1)
print(myset)
返回:
![]()
为什么?别忘了我们的集合不能重复,重复的集合会被覆盖,因此只添加了新的值进来。
3.3)添加任何可迭代对象
update()方法中的对象不一定是集合,它可以是任何可迭代对象(元组、列表、字典等)。
例如:将myset2列表加入集合myset1
myset1 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset2=['菜鸟','川川']
myset.update(myset2)
print(myset)
返回为:
![]()
四、移除集合项
4.1)remove方法
要删除集合中的项目,请使用remove()、 或discard()方法。
例如我要移除川川菜鸟:
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset4.remove('川川菜鸟')
print(myset4)
返回:
![]()
注意:如果要删除的项目不存在,remove()将引发错误。
4.2)iscard() 方法
使用以下discard() 方法删除“川川菜鸟” :
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset4.discard('川川菜鸟')
print(myset4)
返回:

注意:如果要删除的项目不存在,discard()则 不会引发错误。
4.3)pop() 方法
使用以下pop() 方法删除最后一项:
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset4.pop()
print(myset4)
返回:
![]()
注意:集合是无序的,因此在使用该pop()方法时,您不知道哪个项目被删除。
4.4)clear() 方法
clear() 方法清空集合:
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset.clear()
print(myset4)
打印为空。
4.5)del关键字
该del关键字将完全删除该集合:
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
del myset4
集合已经不存在了,因此我们不打印。
五、循环集合
for循环遍历即可
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
for i in myset4:
print(i)
返回:

六、集合连接
6.1)普通连接
您可以使用union()返回包含两个集合中所有项的新集合的方法,或将一个集合中的所有项update()插入另一个集合的方法。
方法一:使用union()方法返回一个包含两个集合中所有项目的新集合
set1 = {
"a", "b" , "c"}
set2 = {
1, 2, 3}
set3 = set1.union(set2)
print(set3)
方法二:update()方法将 set2 中的项插入到 set1 中
set1 = {
"a", "b" , "c"}
set2 = {
1, 2, 3}
set1.update(set2)
print(set1)
注意:无论union()和update() 将排除任何重复的项目。
6.2)仅保留重复项
intersection_update()方法将只保留两个集合中都存在的项目。
保留myset4和myset5重复项:
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset5 = {
"川川一号", "川川五号", "川川三号",'川川菜鸟'}
myset4.intersection_update(myset5)
print(myset4)
返回:

或者用intersection()方法将返回一个新集合,该集合仅包含两个集合中都存在的项目。
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset5 = {
"川川一号", "川川五号", "川川三号",'川川菜鸟'}
z=myset4.intersection(myset5)
print(z)
返回:
![]()

6.3)保留所有,但不保留重复项
symmetric_difference_update()方法将只保留两个集合中都不存在的元素。
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset5 = {
"川川一号", "川川五号", "川川三号",'川川菜鸟'}
z=myset4.symmetric_difference_update(myset5)
print(z)
返回:

symmetric_difference()方法将返回一个新集合,该集合仅包含两个集合中都不存在的元素。
myset4 = {
"川川一号", "川川二号", "川川三号",'川川菜鸟'}
myset5 = {
"川川一号", "川川五号", "川川三号",'川川菜鸟'}
z=myset4.symmetric_difference(myset5)
print(z)
返回:

七、练习
1-检查fruits集中是否存在“appl”。
fruits = {
"apple", "banana", "cherry"}
if "apple" fruits:
print("Yes, apple is a fruit!")
2-使用 add 方法将“orange”添加到fruits集中。
fruits = {
"apple", "banana", "cherry"}
3-使用正确的方法将多个项目(more_fruits)添加到fruits 集中。
fruits = {
"apple", "banana", "cherry"}
more_fruits = ["orange", "mango", "grapes"]
fruits.update(more_fruits)#答案
4-使用 remove 方法从fruits 集中删除“banana。
fruits = {
"apple", "banana", "cherry"}
5-使用discard方法从fruits 集中删除“香蕉”。
fruits = {
"apple", "banana", "cherry"}
二十二、Python字典
一、字典理解
基本形式:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
字典用于在键值对中存储数据值。字典是有序*、可变且不允许重复的集合。(从 Python 3.7 版开始,字典是有序的。在 Python 3.6 及更早版本中,字典是无序的。)
1.1)创建字典与访问
字典是用大括号写的,有键和值。
创建并打印字典:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
print(thisdict)
字典项是有序的、可变的,并且不允许重复。字典项以键值对的形式呈现,可以使用键名进行引用。
例如打印brand的值
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
print(thisdict["brand"])
字典不能有两个具有相同键的项目:重复值将覆盖现有值
返回:
![]()
1.2)字典长度
还是用用len函数
hisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964,
"year": 2020
}
print(len(thisdict))
1.3)数据类型
字典项中的值可以是任何数据类型:
例如:
thisdict = {
"brand": "Ford",
"electric": False,
"year": 1964,
"colors": ["red", "white", "blue"]
}
类型:dict()
打印字典的数据类型:
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
print(type(thisdict))
补充巩固:

二、访问字典

2.1)访问键名
您可以通过引用方括号内的键名来访问字典的项目:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
x = thisdict["name"]
print(x)
还有一个被调用的方法get()会给你同样的结果:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
x = thisdict["name"]
y=thisdict.get('name')
print(x)
print(y)
返回:

2.2)访问健值
keys()方法将返回字典中所有键的列表。
hisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
x = thisdict.keys()
print(x)
向原始字典添加一个新项目,并看到键列表也得到更新:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict['age']=20
print(thisdict)
返回:
![]()
获取值
values()方法将返回字典中所有值的列表。
x = thisdict.values()
items()方法将返回字典中的每个项目,作为列表中的元组。
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict['age']=20
print(thisdict)
x = thisdict.items()
print(x)
返回元祖:
![]()
要确定字典中是否存在指定的键,请使用in关键字:
hisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
if 'name' in thisdict:
print('name在字典')
返回:
![]()
三、更改字典各种方法
前面我们讲到了一部分更改内容,这里我们具体讲一下。
例如我要把川川改为川川菜鸟:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict['name'] = '川川菜鸟'
print(thisdict)
返回:
![]()
或者我们使用update()方法:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict.update({
'name':'川川菜鸟'})
print(thisdict)
效果一样:
![]()
四、添加字典项各种方法
比如我要添加一个年龄为20:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict['age']=20
print(thisdict)
返回:![]()
或者还是使用update:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict['age']=20
print(thisdict)
thisdict.update({
'age':'20岁'})
print(thisdict)
返回:
![]()
五、删除字典的各种方法

pop()方法删除具有指定键名的项。
比如我要删除地址项目:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict.pop("address")
print(thisdict)
返回:
![]()
popitem()方法删除最后插入的项目(在 3.7 之前的版本中,将删除随机项目):
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict.pop("address")
print(thisdict)
thisdict.popitem()
print(thisdict)
返回:
![]()
del关键字删除与指定键名称的项目:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
del thisdict['name']
print(thisdict)
返回:
![]()
del关键字也可以删除字典完全:
del thisdict
clear()方法清空字典:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
thisdict.clear()
print(thisdict)
返回空:
![]()
六、遍历字典
将字典中的所有键名,一一打印出来:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
for x in thisdict:
print(x)
一一打印字典中的所有值:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
for x in thisdict:
print(thisdict[x])
返回:

您还可以使用该values()方法返回字典的值:
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
for x in thisdict.values():
print(x)
您可以使用该keys()方法返回字典的键:
hisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
for x in thisdict.keys():
print(x)
返回:

使用以下 方法循环遍历keys和valuesitems():
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
for x, y in thisdict.items():
print(x, y)
返回:

七、复制字典
用copy()函数
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
mydict=thisdict.copy()
print(mydict)
内置dict()函数
thisdict = {
"name": "川川",
"address": "上海",
"year": 2000
}
mydict=dict(thisdict)
print(mydict)
效果都一样:

八、嵌套字典
创建一个包含三个字典的字典:
myfamily = {
"child1" : {
"name" : "Emil",
"year" : 2004
},
"child2" : {
"name" : "Tobias",
"year" : 2007
},
"child3" : {
"name" : "Linus",
"year" : 2011
}
}
print(myfamily)
返回:
![]()
创建三个字典,然后创建一个包含其他三个字典的字典:
child1 = {
"name" : "Emil",
"year" : 2004
}
child2 = {
"name" : "Tobias",
"year" : 2007
}
child3 = {
"name" : "Linus",
"year" : 2011
}
myfamily = {
"child1" : child1,
"child2" : child2,
"child3" : child3
}
print(myfamily)
效果一样:
![]()
九、练习
1-使用get方法打印汽车字典的“model”键的值。
car = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
print
2-将“year”值从 1964 更改为 2020。
car = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
3-将键/值对 “color” : “red” 添加到汽车字典中。
car = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
4-使用 pop 方法从汽车字典中删除“model”。
car = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
5-使用clear方法清空car字典。
car = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}

二十三、If … Else语句
Python 支持数学中常见的逻辑条件:
- 等于:a == b
- 不等于:a != b
- 小于:a < b
- 小于或等于:a <= b
- 大于:a > b
- 大于或等于:a >= b
一、if语句
a = 33
b = 200
if b > a:
print("b 大于 a")
返回:

注意:if后面要有冒号
在这个例子中,我们使用两个变量a和b,它们用作 if 语句的一部分来测试b是否大于a。由于a是33,而b是200,我们知道 200 大于 33,所以我们打印到屏幕上“b 大于 a”。
二、缩进
Python 依靠缩进(行首的空格)来定义代码中的范围。为此,其他编程语言通常使用大括号。
If 语句,没有缩进(会引发错误):
a = 33
b = 200
if b > a:
print("b 大于 a")
三、elif语句

如果前面的条件是不正确的,那就试试这个条件。
例如:
a = 33
b = 33
if b > a:
print("b 大于 a")
elif a == b:
print("a 等于b")
返回:
![]()
在这个例子中a等于b,所以第一个条件不成立,但elif条件成立,所以我们打印到屏幕“a 和 b 相等”
四.else语句
4.1基本else
在其他关键字捕获任何未通过前面的条件抓获。
a = 200
b = 33
if b > a:
print("b 大于 a")
elif a == b:
print("a 等于b")
else:
print("a 小于 b")
返回:
![]()
在这个例子中a大于b,所以第一个条件不成立,elif条件也不成立,所以我们转到else条件并打印到屏幕“a 小于 b”。
你也可以有一个else没有 elif:
a = 200
b = 33
if b > a:
print("b 大于 a")
else:
print("b 小于 a")
4.2)and语句
测试 if a是否大于 b,并且 if c 大于a:
a = 200
b = 33
c = 500
if a > b and c > a:
print("两种条件都满足")
4.3)or 语句
测试 if a是否大于 b,或 if a 大于c:
a = 200
b = 33
c = 500
if a > b or a > c:
print("At least one of the conditions is True")
4.4)嵌套if语句
x = 41
if x > 10:
print("Above ten,")
if x > 20:
print("and also above 20!")
else:
print("but not above 20.")
4.4)pass语句
if语句不能为空,但如果您出于某种原因有一个if没有内容,pass语句请放入该语句以避免出错。
a = 33
b = 200
if b > a:
pass
二十四、while循环语句
一、基本理解
使用while循环,只要条件为真,我们就可以执行一组语句。
例如:只要 i 小于 6 就打印 i
i = 1
while i < 6:
print(i)
i += 1
返回为:

注意:记住要限制 i,否则循环将永远持续下去。
二、中断声明

使用break语句,即使 while 条件为真,我们也可以停止循环:
例如当 i 为 3 时退出循环:
i = 1
while i < 6:
print(i)
if i == 3:
break
i += 1
返回:

三、continue 声明
使用continue语句,我们可以停止当前的迭代,并继续下一个:
i = 0
while i < 6:
i += 1
if i == 3:
continue
print(i)
返回:可以并没有打印3

四、else 语句
使用else语句,当条件不再为真时,我们可以运行一次代码块:
一旦条件为假,打印一条消息:
i = 1
while i < 6:
print(i)
i += 1
else:
print("i is no longer less than 6")

二十五、for循环语句
一、基本遍历
使用for循环,我们可以执行一组语句,对列表、元组、集合等中的每个项目执行一次。
例如:打印水果列表中的每个水果
fruits = ["apple", "banana", "cherry"]
for x in fruits:
print(x)
二、遍历字符串
例如循环遍历单词“banana”中的字母:
for x in "banana":
print(x)
三、中断声明
使用break语句,我们可以在循环遍历所有项目之前停止循环.
例如当x是“banana”时退出循环:
fruits = ["apple", "banana", "cherry"]
for x in fruits:
print(x)
if x == "banana":
break
当x是“banana”时退出循环,但这次中断出现在打印之前:
fruits = ["apple", "banana", "cherry"]
for x in fruits:
if x == "banana":
break
print(x)
就会返回只有applr:
![]()
四、continue 声明
使用continue语句,我们可以停止循环的当前迭代,并继续下一个:
不要打印banana:
fruits = ["apple", "banana", "cherry"]
for x in fruits:
if x == "banana":
continue
print(x)
五.range() 函数
要循环一组代码指定的次数,我们可以使用range()函数,的范围()函数返回由1个数字,通过默认从0开始,并递增的顺序(缺省),并结束在指定次数。
例如:
for x in range(6):
print(x)
返回:

注意 range(6)不是 0 到 6 的值,而是 0 到 5 的值。
range函数默认被1至递增序列,但是有可能通过增加第三参数指定增量值:range(2,30,3)
六.嵌套循环
嵌套循环是循环内的循环。“内循环”将在“外循环”的每次迭代中执行一次。
为每个fruits打印每个形容词:
adj = ["red", "big", "tasty"]
fruits = ["apple", "banana", "cherry"]
for x in adj:
for y in fruits:
print(x, y)
返回:

七.pass语句
for循环不能为空,但如果由于某种原因有一个for没有内容的循环,请放入pass语句以避免出错。
for x in [0, 1, 2]:
pass
二十六、函数

一、创建函数与调用
在 Python 中,函数是使用def 关键字定义的:
def my_function():
print("Hello from a function")
调用函数
要调用函数,请使用函数名称后跟括号:
def my_function():
print("川川菜鸟")
my_function()
返回:
![]()
二、参数
信息可以作为参数传递给函数。参数在函数名后的括号内指定。您可以根据需要添加任意数量的参数,只需用逗号分隔它们。
下面的示例有一个带一个参数 (fname) 的函数。当函数被调用时,我们传递一个名字,在函数内部使用它来打印全名:
def my_function(fname):
print(fname + " 菜鸟")
my_function("川川")
my_function("川川吗")
my_function("憨批")
返回:

三、参数数量
默认情况下,必须使用正确数量的参数调用函数。这意味着如果您的函数需要 2 个参数,则必须使用 2 个参数调用该函数,不能多也不能少。
例如此函数需要 2 个参数,并获得 2 个参数:
def my_function(fname, lname):
print(fname + " " + lname)
my_function("川川", "菜鸟")
返回:
![]()
四、任意参数,*args

如果您不知道将传递给函数的参数有多少,请*在函数定义中的参数名称前添加一个。这样,该函数将接收一个参数元组,并可以相应地访问这些项目。
如果参数数量未知,则*在参数名称前添加一个:
def my_function(*kids):
print("川川帅哥 " + kids[2])
my_function("名字", "性别", "菜鸟")
返回:
![]()
五、关键字参数
您还可以使用key = value语法发送参数。这样,参数的顺序就无关紧要了。
def my_function(child3, child2, child1):
print("最帅的是 " + child3)
my_function(child1 = "大白", child2 = "小白", child3 = "猪猪侠")
返回:

短语关键字参数在 Python 文档中通常缩写为kwargs。
七、任意关键字参数,**kwargs
如果您不知道有多少关键字参数将被传递到您的函数中,请**在函数定义中的参数名称之前添加两个星号。这样,该函数将接收一个参数字典,并可以相应地访问这些项目.
例如:
def my_function(**kid):
print("它的名字是 " + kid["lname"])
my_function(fname = "菜鸟", lname = "川川")
返回:
![]()
八、默认参数值
如果我们不带参数调用函数,它使用默认值:
def my_function(country = "Norway"):
print("I am from " + country)
my_function("Sweden")
my_function("India")
my_function()
my_function("Brazil")
返回:

九、将列表作为参数传递
例如,如果你发送一个 List 作为参数,当它到达函数时它仍然是一个 List:
def my_function(food):
for x in food:
print(x)
fruits = ["apple", "banana", "cherry"]
my_function(fruits)
返回:

十、返回值
要让函数返回值,请使用以下return 语句:
def my_function(x):
return 5 * x
print(my_function(3))
print(my_function(5))
print(my_function(9))
十一、pass语句
function定义不能为空,但如果您出于某种原因有一个function没有内容的定义,请放入pass语句中以避免出错。
def myfunction():
pass
二十七、lambda

lambda 函数是一个小的匿名函数。一个 lambda 函数可以接受任意数量的参数,但只能有一个表达式。
语法:
lambda arguments : expression
执行表达式并返回结果:
示例将 10 添加到 argument a,并返回结果:
x = lambda a : a + 10
print(x(5))
返回:
![]()
Lambda 函数可以接受任意数量的参数。
例将参数a与参数 相乘b并返回结果:
x = lambda a, b : a * b
print(x(5, 6))
返回:
![]()
把参数a、 b和c并返回结果:
x = lambda a, b, c : a + b + c
print(x(5, 6, 2))
返回:
![]()
假设您有一个接受一个参数的函数定义,并且该参数将乘以一个未知数:
def myfunc(n):
return lambda a : a * n
使用该函数定义来创建一个函数,该函数始终将您发送的数字加倍:
def myfunc(n):
return lambda a : a * n
mydoubler = myfunc(2)
print(mydoubler(11))
使用相同的函数定义来创建一个始终将您发送的数字增加三倍的函数:
def myfunc(n):
return lambda a : a * n
mytripler = myfunc(3)
print(mytripler(11))
二十八、数组

Python 没有对数组的内置支持,但可以使用Python 列表代替。
例如:
chuan = ["川川", "菜鸟", "帅哥"]
一、访问数组的元素
您可以通过引用索引号来引用数组元素。例如:
chuan = ["川川", "菜鸟", "帅哥"]
te=chuan[0]
print(te)
修改数组:
chuan = ["川川", "菜鸟", "帅哥"]
chuan[0]='高富帅'
print(chuan)
返回:![]()
二、数组的长度
用len函数。
例如:
chuan = ["川川", "菜鸟", "帅哥"]
chuan[0]='高富帅'
# print(chuan)
print(len(chuan))
三、修改数组
补充一点:循环数组元素,您可以使用for in循环遍历数组的所有元素。
例如:
chuan = ["川川", "菜鸟", "帅哥"]
for i in chuan:
print(i)
添加数组元素
使用append函数(跟列表一样)
chuan = ["川川", "菜鸟", "帅哥"]
chuan.append('上海')
print(chuan)
返回:
![]()
删除数组元素
您可以使用该pop()方法从数组中删除一个元素。(注意起始位置是0)
例如删除第二个元素:
chuan = ["川川", "菜鸟", "帅哥"]
chuan.pop(1)
print(chuan)
返回:
![]()
您还可以使用该remove()方法从数组中删除一个元素。
chuan = ["川川", "菜鸟", "帅哥"]
chuan.pop(1)
print(chuan)
chuan.remove('帅哥')
print(chuan)
返回:

注意:列表的remove()方法只删除指定值的第一次出现。
四、数组的其它操作

二十九、Python类和对象

Python 类/对象。Python 是一种面向对象的编程语言。Python 中的几乎所有东西都是一个对象,有它的属性和方法。类就像一个对象构造函数,或者是创建对象的“蓝图”。
一、创建类
要创建一个类,请使用关键字class。
例如:创建一个名为 MyClass 的类,其属性名为 x
class MyClass:
x = 5
print(MyClass)
二、创建对象
现在我们可以使用名为 MyClass 的类来创建对象。
例如创建一个名为 p1 的对象,并打印 x 的值:
class MyClass:
x = 5
p1 = MyClass()
print(p1.x)
返回:
![]()
三、init() 函数
上面的例子是最简单形式的类和对象,在现实生活应用程序中并没有真正有用。要理解类的含义,我们必须了解内置的 init() 函数。所有类都有一个名为 init() 的函数,它总是在类被初始化时执行。使用 init() 函数为对象属性赋值,或在创建对象时需要执行的其他操作。
例如创建一个名为 Person 的类,使用 init() 函数为 name 和 age 赋值:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
p1 = Person("川川菜鸟", 20)
print(p1.name)
print(p1.age)
返回:

注意:init()每次使用该类创建新对象时都会自动调用该函数。
四、对象方法
让我们在 Person 类中创建一个方法。
例如插入一个打印问候语的函数,并在 p1 对象上执行它:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def myfunc(self):
print("我的名字是 " + self.name)
p1 = Person("川川菜鸟", 20)
p1.myfunc()
返回:

五、自参数
self参数是对类当前实例的引用,用于访问属于该类的变量。它不必命名self,您可以随意调用它,但它必须是类中任何函数的第一个参数:
class Person:
def __init__(mysillyobject, name, age):
mysillyobject.name = name
mysillyobject.age = age
def myfunc(abc):
print("我的名字是 " + abc.name)
p1 = Person("川川菜鸟", 20)
p1.myfunc()
跟使用self效果一样
![]()
六、对象及其属性更改
替换
例如修改年龄为21
class Person:
def __init__(mysillyobject, name, age):
mysillyobject.name = name
mysillyobject.age = age
def myfunc(abc):
print("我的名字是 " + abc.name)
p1 = Person("川川菜鸟", 20)
p1.age = 21
print(p1.age)
返回:
![]()
删除对象属性
例如从 p1 对象中删除 age 属性:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def myfunc(self):
print("Hello my name is " + self.name)
p1 = Person("John", 36)
del p1.age
print(p1.age)#没有了自然打印报错
删除对象
比如删除对象p1
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def myfunc(self):
print("Hello my name is " + self.name)
p1 = Person("John", 36)
del p1
print(p1)#对象都不在了肯定报错
七、pass语句
class定义不能为空,但如果您出于某种原因有一个class没有内容的定义,请放入pass语句中以避免出错。
class Person:
pass
三十、Python继承

继承允许我们定义一个从另一个类继承所有方法和属性的类。父类是被继承的类,也称为基类。子类是从另一个类继承的类,也称为派生类。
一、创建父类
任何类都可以是父类,因此语法与创建任何其他类相同:
这里创建一个名为Person、 firstname和lastname属性的类,以及一个printname方法:
class Person:
def __init__(self, fname, lname):
self.firstname = fname
self.lastname = lname
def printname(self):
print(self.firstname, self.lastname)
x = Person("川川", "菜鸟")
x.printname()
返回:
![]()
二、创建子类
创建从另一个类继承功能的类,请在创建子类时将父类作为参数发送。
例如:创建一个名为 的类Student,它将继承该类的属性和方法Person
class Student(Person):
pass
注意: pass 当您不想向类添加任何其他属性或方法时,请使用关键字。
现在 Student 类具有与 Person 类相同的属性和方法。使用Student类创建对象,然后执行printname方法:
class Person:
def __init__(self, fname, lname):
self.firstname = fname
self.lastname = lname
def printname(self):
print(self.firstname, self.lastname)
class Student(Person):
pass
x = Student("川川", "菜鸟")
x.printname()
返回还是一样
![]()
三、添加 init() 函数
到目前为止,我们已经创建了一个继承父类的属性和方法的子类。我们想将__init__()函数添加到子类(而不是pass关键字)。
注意:init()每次使用该类创建新对象时都会自动调用该函数。
例如:将__init__()函数添加到 Student类中
class Student(Person):
def __init__(self, fname, lname):
添加__init__()函数后,子类将不再继承父类的__init__()函数。注:孩子的__init__() 功能覆盖父母的继承 init()功能。为了保持父__init__() 函数的继承,添加对父函数的调用__init__():
class Person:
def __init__(self, fname, lname):
self.firstname = fname
self.lastname = lname
def printname(self):
print(self.firstname, self.lastname)
class Student(Person):
def __init__(self, fname, lname):
Person.__init__(self, fname, lname)
x = Student("川川", "菜鸟")
x.printname()
这样效果一样:
![]()
四、使用 super() 函数
Python 还有一个super()函数可以让子类继承其父类的所有方法和属性:
class Person:
def __init__(self, fname, lname):
self.firstname = fname
self.lastname = lname
def printname(self):
print(self.firstname, self.lastname)
class Student(Person):
def __init__(self, fname, lname):
super().__init__(fname, lname)
x = Student("川川", "菜鸟")
x.printname()
一样返回:
![]()
通过使用该super()函数,您不必使用父元素的名称,它会自动从其父元素继承方法和属性。
五、添加属性
添加一个属性调用graduationyear到 Student类:
class Person:
def __init__(self, fname, lname):
self.firstname = fname
self.lastname = lname
def printname(self):
print(self.firstname, self.lastname)
class Student(Person):
def __init__(self, fname, lname):
super().__init__(fname, lname)
self.graduationyear = 2021
x = Student("川川", "菜鸟")
print(x.graduationyear)
返回:
![]()
年份2019应该是一个变量,并Student在创建学生对象时传递给 类。为此,请在 init() 函数中添加另一个参数。
添加year参数,并在创建对象时传递正确的年份:
class Person:
def __init__(self, fname, lname):
self.firstname = fname
self.lastname = lname
def printname(self):
print(self.firstname, self.lastname)
class Student(Person):
def __init__(self, fname, lname, year):
super().__init__(fname, lname)
self.graduationyear = year
x = Student("川川", "菜鸟", 2021)
print(x.graduationyear)
返回一样为2021
六、添加方法
添加一个调用welcome到 Student类的方法:
class Person:
def __init__(self, fname, lname):
self.firstname = fname
self.lastname = lname
def printname(self):
print(self.firstname, self.lastname)
class Student(Person):
def __init__(self, fname, lname, year):
super().__init__(fname, lname)
self.graduationyear = year
def welcome(self):
print("Welcome", self.firstname, self.lastname, "to the class of", self.graduationyear)
x = Student("川川", "菜鸟", 2021)
x.welcome()
返回
![]()
三十一、Python日期

Python 中的日期不是它自己的数据类型,但我们可以导入一个名为的模块datetime来处理日期作为日期对象。
一、日期输入输出
导入 datetime 模块并显示当前日期:
import datetime
x = datetime.datetime.now()
print(x)
返回:
![]()
日期输出
当我们执行上面示例中的代码时,结果将是:2021-08-25 05:36:01.704218
日期包含年、月、日、小时、分钟、秒和微秒。
回工作日的年份和名称:
import datetime
x = datetime.datetime.now()
print(x.year)
print(x.strftime("%A"))
返回:

二、创建日期对象
要创建日期,我们可以使用模块的datetime()类(构造函数) datetime。本datetime()类需要三个参数来创建日期:年,月,日。
import datetime
x = datetime.datetime(2021, 8, 25)
print(x)
返回
![]()
datetime()类也需要参数的时间和时区(小时,分钟,秒,微秒,tzone),但它们是可选的,并且具有一个默认值0,(None对时区)。
三、strftime() 方法
该datetime对象具有将日期对象格式化为可读字符串的方法。该方法被调用strftime(),并采用一个参数 format,来指定返回字符串的格式。
例如显示月份名称:
import datetime
x = datetime.datetime(2011, 8, 25)
print(x.strftime("%B"))
返回

四、其它调用方法
实在太多,不能一一演示,大家自己看下。


三十二、Python JSON
JSON 是一种用于存储和交换数据的语法。JSON 是文本,用 JavaScript 对象表示法编写。
Python 有一个名为 的内置包json,可用于处理 JSON 数据。
导入 json 模块:
import json
一.从 JSON 转换为 Python
如果您有 JSON 字符串,则可以使用json.loads()方法对其进行解析 。
结果将是一个Python 字典。
例如:
import json
# some JSON:
x ='{ "name":"川川", "age":20, "city":"上海"}'
# 解析x
y = json.loads(x)
#会返回字典
print(y["age"])
返回:
![]()
如果您有 Python 对象,则可以使用json.dumps()方法将其转换为 JSON 字符串。
import json
# x为字典
x = {
"name": "John",
"age": 30,
"city": "New York"
}
# 转为json
y = json.dumps(x)
# 结果为json字符串
print(y)
print(type(y))
返回为
![]()
三十三、异常处理
try块可让您测试代码块的错误。except块可让您处理错误。finally无论 try- 和 except 块的结果如何,该块都允许您执行代码。
一、异常处理
例如该try块将产生异常,因为x未定义:
try:
print(x)
except:
print("An exception occurred")
返回![]()
由于 try 块引发错误,因此将执行 except 块。如果没有 try 块,程序将崩溃并引发错误。
二、else搭配
else如果没有出现错误,您可以使用关键字来定义要执行的代码块:
try:
print("Hello")
except:
print("Something went wrong")
else:
print("Nothing went wrong")
返回:

三、finally语句
finally如果指定了该块,则无论 try 块是否引发错误,都将执行该块。
例如:
try:
print(x)
except:
print("Something went wrong")
finally:
print("The 'try except' is finished")
返回:

这对于关闭对象和清理资源很有用。
例如尝试打开并写入不可写的文件:
try:
f = open("demofile.txt")
f.write("Lorum Ipsum")
except:
print("Something went wrong when writing to the file")
finally:
f.close()
程序可以继续,而无需打开文件对象。
四、引发异常
要抛出(或引发)异常,请使用raise关键字。
例如如果 x 小于 0,则引发错误并停止程序:
x = -1
if x < 0:
raise Exception("Sorry, no numbers below zero")
返回:

该raise关键字用于引发异常。您可以定义要引发的错误类型以及要打印给用户的文本。
例如如果 x 不是整数,则引发 TypeError:
x = "hello"
if not type(x) is int:
raise TypeError("Only integers are allowed")
返回

三十四、用户输入

实在太简单了,就是使用一个input(),将输入后的值传递给另一个变量,相当于动态赋值、
例如:
username = input("你叫什么名字:")
print("名字叫: " + username)
返回:

三十五、格式化输入输出
讲解在注释里面,每一小段为一部分(我实在懒得打字了,实在不会左侧加群问我)
'''在字符串开头的引号/三引号前添加 f 或 F 。在这种字符串中,可以在 { 和 } 字符之间输入引用的变量'''
# year = 2021
# event = 'Referendum'
# a=f'Results of the {year} {event}'
# print(a)
'''str.format() 该方法也用 { 和 } 标记替换变量的位置a 这种方法支持详细的格式化指令'''
# yes_votes = 42_572_654
# no_votes = 43_132_495
# percentage = yes_votes / (yes_votes + no_votes)
# a='{:-5} YES votes {:1.1%}'.format(yes_votes, percentage)#调整{
}内部感受下
# print(a)
'''只想快速显示变量进行调试,可以用 repr() 或 str() 函数把值转化为字符串。'''
# s = 'Hello, world.'
# print(str(s))#str() 函数返回供人阅读的值
# print(repr(s))#repr() 则生成适于解释器读取的值
# print(str(1/7))
# hellos = repr('hello')
# print(hellos)
'''7.1.1. 格式化字符串字面值'''
'''格式化字符串字面值 (简称为 f-字符串)在字符串前加前缀 f 或 F,通过 {expression} 表达式,把 Python 表达式的值添加到字符串内'''
'''下例将 pi 舍入到小数点后三位'''
# import math
# print(f'The value of pi is approximately {math.pi:.3f}.')
'''在 ':' 后传递整数,为该字段设置最小字符宽度,常用于列对齐'''
# table = {
'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}
# for name, phone in table.items():
# print(f'{name:10} ==> {phone:10d}')
'''7.1.2. 字符串 format() 方法'''
# print('We are the {} who say "{}!"'.format('knights', 'Ni'))
'''花括号及之内的字符(称为格式字段)被替换为传递给 str.format() 方法的对象。花括号中的数字表示传递给 str.format() 方法的对象所在的位置。'''
# print('{0} and {1}'.format('spam', 'eggs'))
# print('{1} and {0}'.format('spam', 'eggs'))
'''使用关键字参数名引用值。'''
# print('This {food} is {adjective}.'.format(food='spam', adjective='absolutely horrible'))
'''位置参数和关键字参数可以任意组合'''
# print('The story of {0}, {1}, and {other}.'.format('Bill', 'Manfred',
# other='Georg'))
'''用方括号 '[]' 访问键来完成'''
# table = {
'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
# print('Jack: {0[Jack]:d}; Sjoerd: {0[Sjoerd]:d}; ''Dcab: {0[Dcab]:d}'.format(table))
'''也可以用 '**' 符号,把 table 当作传递的关键字参数。'''
# print('Jack: {Jack:d}; Sjoerd: {Sjoerd:d}; Dcab: {Dcab:d}'.format(**table))
'''生成一组整齐的列,包含给定整数及其平方与立方'''
# for x in range(1, 11):
# print('{0:2d} {1:3d} {2:4d}'.format(x, x * x, x * x * x))
'''7.1.3. 手动格式化字符串'''
# for x in range(1, 11):
# print(repr(x).rjust(2), repr(x * x).rjust(3), end=' ')
# print(repr(x * x * x).rjust(4))
'''7.1.4. 旧式字符串格式化方法'''
# import math
# print('The value of pi is approximately %5.3f.' % math.pi)
'''7.2. 读写文件¶'''
'''最常用的参数有两个: open(filename, mode)'''
# f = open('workfile', 'w')
'''
第一个实参是文件名字符串第二个实参是包含描述文件使用方式字符的字符串。
mode 的值包括 'r' ,表示文件只能读取;'w' 表示只能写入(现有同名文件会被覆盖);
'a' 表示打开文件并追加内容,任何写入的数据会自动添加到文件末尾。'r+' 表示打开文件进行读写。
mode 实参是可选的,省略时的默认值为 'r'。
'''
# with open('workfile') as f:
# read_data = f.read()
# print(read_data)
# f.close()#如果没有使用 with 关键字,则应调用 f.close() 关闭文件,即可释放文件占用的系统资源。
# with open('workfile') as f:
# a=f.read()
# print(a)
# f.close()
'''f.readline() 从文件中读取单行数据'''
# with open('workfile') as f:
# a=f.readline()
# b=f.readline()
# c=f.readline()
# print(a,b,c)
# for i in f:
# print(i)
# f.close()
'''从文件中读取多行时,可以用循环遍历整个文件对象'''
# with open('workfile') as f:
# for line in f:
# print(line, end='')
# f.close()
'''f.write(string) 把 string 的内容写入文件,并返回写入的字符数。'''
# with open('workfile','w') as f:
# f.write('This is a test\n')
# f.close()
'''写入其他类型的对象前,要先把它们转化为字符串(文本模式)或字节对象(二进制模式)'''
# with open('workfile','a') as f:
# value = ('the answer', 42)
# s = str(value)
# f.write(s)
# f.close()
# f = open('workfile', 'rb+')
# f.write(b'0123456789abcdef')
# print(f.read())
# print(f.seek(5))
# print(f.read(1))
'''7.2.2. 使用 json 保存结构化数据'''
# import json
# a=json.dumps([1, 'simple', 'list'])
# print(a)
'''dumps() 函数还有一个变体, dump() ,它只将对象序列化为 text file '''
#如果 f 是 text file 对象
# json.dump(x, f)
#要再次解码对象,如果 f 是已打开、供读取的 text file 对象
# x = json.load(f)
© 2021 GitHub, Inc.
三十六、⭐进阶python正则表达式⭐

Python 有一个名为 的内置包re,可用于处理正则表达式。导入re模块:
import re
一、Python中的正则表达式
导入re模块后,您可以开始使用正则表达式。
例如:搜索字符串以查看它是否以“The”开头并以“Spain”结尾:
import re
txt = "The rain in Spain"
x = re.search("^The.*Spain$", txt)
if x:
print("匹配成功!")
else:
print("匹配失败")
运行:

当然,你现在看不懂这个例子,既然手把手教学,并不会教大家一步登天。
二、正则表达式函数
2.1) findall() 函数
该findall()函数返回一个包含所有匹配项的列表。
例如:打印所有匹配项的列表
import re
txt = "川川菜鸟啊菜鸟啊"
x = re.findall("菜鸟", txt)
print(x)
运行返回:

该列表按找到的顺序包含匹配项。如果未找到匹配项,则返回一个空列表:
import re
txt = "菜鸟并不菜"
x = re.findall("川川", txt)
print(x)
if (x):
print("匹配成功了哟")
else:
print("找不到这个呀!")
运行返回:

2.2) search() 函数
该search()函数在字符串中搜索匹配项,如果有匹配项,则返回一个Match 对象。如果有多个匹配项,则只返回匹配项的第一次出现。
例如:搜索字符串中的第一个空白字符:
import re
txt = "菜鸟 呢"
x = re.search("\s", txt)
print("第一个空格字符位于位置:", x.start())
运行结果:

如果未找到匹配项,None则返回该值:
import re
txt = "天上飞的是菜鸟"
x = re.search("川川", txt)
print(x)
返回:

2.3) split() 函数
该split()函数返回一个列表,其中的字符串在每次匹配时被拆分。
例如:在每个空白字符处拆分
import re
txt = "菜鸟 学 python"
x = re.split("\s", txt)
print(x)
运行返回:
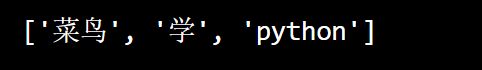
您可以通过指定maxsplit 参数来控制出现次数
例如:仅在第一次出现时拆分字符串:
import re
#Split the string at the first white-space character:
txt = "飞起来 菜鸟 们"
x = re.split("\s", txt, 1)
print(x)
返回:

2.4) sub() 函数
该sub()函数用您选择的文本替换匹配项。
例如:用只替换就
import re
txt = "学python就找川川菜鸟"
x = re.sub("就", "只", txt)
print(x)
运行:

您可以通过指定count 参数来控制替换次数 :
例如替换前 2 次出现:
import re
txt = "学python就就就川川菜鸟"
x = re.sub("就", "只", txt,2)
print(x)
返回:

三、元字符

3.1) 列表符号
[] 用于一组字符
例如:#按字母顺序查找“a”和“m”之间的所有小写字符
import re
txt = "apple chuanchuan "
#按字母顺序查找“a”和“m”之间的所有小写字符
x = re.findall("[a-m]", txt)
print(x)
运行:
![]()
3.2)转义符
** 表示特殊序列(也可用于转义特殊字符)
例如匹配所有数字:
import re
txt = "我今年20岁了"
#查找所有数字字符
x = re.findall("\d", txt)
print(x)
运行返回:
![]()
3.4) 任意符号
. 可以任何字符(换行符除外)。
例如:搜索以“he”开头、后跟两个(任意)字符和一个“o”的序列
import re
txt = "hello world"
#搜索以“he”开头、后跟两个(任意)字符和一个“o”的序列
x = re.findall("he..o", txt)
print(x)
运行返回:

3.5)开始符
^符号用于匹配开始。
import re
txt = "川川菜鸟 飞起来了"
x = re.findall("^川", txt)
if x:
print("哇,我匹配到了")
else:
print("哎呀,匹配不了啊")
运行:

3.6) 结束符
$ 符号用于匹配结尾,例如:匹配字符串是否以“world”结尾
import re
txt = "hello world"
#匹配字符串是否以“world”结尾
x = re.findall("world$", txt)
if x:
print("匹配成功了耶")
else:
print("匹配不到哦")
运行:

3.7 )星号符
- 星号符用于匹配零次或者多次出现。
import re
txt = "天上飞的是菜鸟,学python找川川菜鸟!"
#检查字符串是否包含“ai”后跟 0 个或多个“x”字符:
x = re.findall("菜鸟*", txt)
print(x)
if x:
print("匹配到了!")
else:
print("气死了,匹配不到啊")
运行:

3.8 )加号符
+ 用于匹配一次或者多次出现
例如:检查字符串是否包含“菜鸟”后跟 1 个或多个“菜鸟”字符:
import re
txt = "飞起来了,菜鸟们!"
#检查字符串是否包含“菜鸟”后跟 1 个或多个“菜鸟”字符:
x = re.findall("菜鸟+", txt)
print(x)
if x:
print("匹配到了!")
else:
print("烦死了,匹配不到")
运行:

3.9)集合符号
{} 恰好指定的出现次数
例如:检查字符串是否包含“川”两个
import re
txt = "川川菜鸟并不菜!"
#检查字符串是否包含“川”两个
x = re.findall("川{2}", txt)
print(x)
if x:
print("匹配到了两次的川")
else:
print("匹配不到啊,帅哥")
返回:

3.10) 或符
| 匹配两者任一
例如:匹配字符串菜鸟或者是我了
import re
txt = "菜鸟们学会python了吗?串串也是菜鸟啊!"
x = re.findall("菜鸟|是我了", txt)
print(x)
if x:
print("匹配到了哦!")
else:
print("匹配失败")
运行:

四、特殊序列

4.1) 指定字符
\A : 如果指定的字符位于字符串的开头,则返回匹配项。
例如:匹配以菜字符开头的字符
import re
txt = "菜鸟在这里"
x = re.findall("\A菜", txt)
print(x)
if x:
print("是的匹配到了")
else:
print("匹配不到")
运行:

4.2) 指定开头结尾
\b 返回指定字符位于单词开头或结尾的匹配项 (开头的“r”确保字符串被视为原始字符串)。
例如:匹配爱开头
import re
txt = "爱你,川川"
x = re.findall(r"\b爱", txt)
print(x)
if x:
print("匹配到了")
else:
print("匹配不到")
运行:

又例如:匹配川结尾
import re
txt = "爱你,川川"
x = re.findall(r"川\b", txt)
print(x)
if x:
print("匹配到了")
else:
print("匹配不到")
运行:

4.3)匹配中间字符
\B 返回存在指定字符但不在单词开头(或结尾)的匹配项 (开头的“r”确保字符串被视为“原始字符串”)
比如我匹配菜鸟:
import re
txt = "我是菜鸟我是菜鸟啊"
#检查是否存在“ain”,但不是在单词的开头:
x = re.findall(r"\菜鸟", txt)
print(x)
if x:
print("匹配到了嘛!!")
else:
print("匹配不到哇!")
运行:

但是你匹配结尾就会返回空,比如我匹配鸟:
import re
txt = "川川菜鸟"
#检查是否存在“鸟”,但不是在单词的末尾:
x = re.findall(r"鸟\B", txt)
print(x)
if x:
print("匹配到了哦")
else:
print("找不到")
运行:

4.4)匹配数字
\d 返回字符串包含数字(0-9 之间的数字)的匹配项。
例如:
import re
txt = "我今年20岁了啊"
#检查字符串是否包含任何位数(0-9的数字)
x = re.findall("\d", txt)
print(x)
if x:
print("哇哇哇,匹配到数字了")
else:
print("找不到哦")
运行:

4.5) 匹配非数字
\D 返回字符串不包含数字的匹配项
例如:
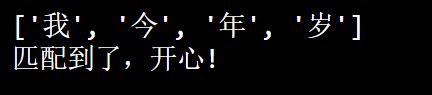
import re
txt = "我今年20岁"
#匹配任何非数字符号
x = re.findall("\D", txt)
print(x)
if x:
print("匹配到了,开心!")
else:
print("匹配不到,生气")
运行:
4.6) 空格匹配
\s 返回一个匹配字符串包含空白空间字符的匹配项。
例如:
import re
txt = "我 是 川 川 菜 鸟"
#匹配任何空格字符
x = re.findall("\s", txt)
print(x)
if x:
print("匹配到了")
else:
print("匹配不到啊")
运行:

4.7) 匹配非空格
\S 返回字符串不包含空格字符的匹配项
import re
txt = "菜鸟是 我 了"
#匹配任意非空字符
x = re.findall("\S", txt)
print(x)
if x:
print("匹配到了!")
else:
print("匹配不到啊")
运行:

4.8 匹配任意数字和字母
返回一个匹配,其中字符串包含任何单词字符(从 a 到 Z 的字符,从 0 到 9 的数字,以及下划线 _ 字符)
例如:
import re
txt = "菜鸟啊 是串串呀"
#在每个单词字符(从a到z的字符,0-9的数字)返回匹配项,以及下划线_字符):
x = re.findall("\w", txt)
print(x)
if x:
print("匹配到了啊")
else:
print("匹配不到哇")
运行:

4.9)匹配任意非数字和字母
返回字符串不包含任何单词字符的匹配项,在每个非单词字符中返回匹配(不在A和Z之间的字符。“!”,“?”空白位等)
例如:
import re
txt = "菜鸟 是 我嘛?我不信!!"
#在每个非单词字符中返回匹配(不在A和Z之间的字符。“!”,“?”空白位等):
x = re.findall("\W", txt)
print(x)
if x:
print("匹配到了!")
else:
print("匹配不到啊")
运行:

4.10) 匹配结尾
\Z 如果指定的字符位于字符串的末尾,则返回匹配项。
例如:
import re
txt = "川川是菜鸟啊"
x = re.findall("啊\Z", txt)
print(x)
if x:
print("匹配到了哦!")
else:
print("匹配不到")

五、集合套装
5.1) 指定符范围匹配
例如集合:[arn]
import re
txt = "The rain in Spain"
x = re.findall("[arn]", txt)
print(x)
if x:
print("匹配到了!")
else:
print("匹配不到")
5.2) 匹配任意范围内小写字母
返回任何小写字符的匹配项,按字母顺序在 a 和 n 之间。
例如:
import re
txt = "hello wo r l d"
x = re.findall("[a-n]", txt)
print(x)
if x:
print("匹配到了!")
else:
print("匹配不到")
运行:

5.3) 其它
同样的道理,依次其它情况如下:
[^arn] 返回除 a、r 和 n 之外的任何字符的匹配项
[0123] 返回存在任何指定数字(0、1、2 或 3)的匹配项
[0-9] 返回 0 到 9 之间任意数字的匹配项
[0-5][0-9] 返回 00 到 59 中任意两位数的匹配项
[a-zA-Z] 按字母顺序返回 a 和 z 之间的任何字符的匹配,小写或大写
[+] 在集合中,+, *, ., |, (), $,{} 没有特殊含义,所以 [+] 的意思是:返回字符串中任意 + 字符的匹配项。这个我i举个例子:
import re
txt = "5+6=11"
#检查字符串是否有任何 + 字符:
x = re.findall("[+]", txt)
print(x)
if x:
print("匹配到了")
else:
print("匹配不到")
运行:

六、匹配对象
匹配对象是包含有关搜索和结果的信息的对象。注意:如果没有匹配,None将返回值,而不是匹配对象。
直接举个例子:
执行将返回匹配对象的搜索
import re
#search() 函数返回一个 Match 对象:
txt = "hello world"
x = re.search("wo", txt)
print(x)
运行:

Match 对象具有用于检索有关搜索和结果的信息的属性和方法:
span()返回一个包含匹配开始和结束位置的元组。
string返回传递给函数的字符串
group()返回字符串中匹配的部分

6.1) span函数
例如:打印第一个匹配项的位置(开始和结束位置)。正则表达式查找任何以大写“S”开头的单词:
import re
#搜索单词开头的大写“S”字符,并打印其位置
txt = "The rain in Spain"
x = re.search(r"\bS\w+", txt)
print(x.span())
运行:
6.2)string函数
例如:打印传递给函数的字符串
import re
#返回字符串
txt = "The rain in Spain"
x = re.search(r"\bS\w+", txt)
print(x.string)
6.3) group函数
例如:打印字符串中匹配的部分。正则表达式查找任何以大写“S”开头的单词
import re
#搜索单词开头的大写“w”字符,并打印该单词:
txt = "hello world"
x = re.search(r"\bw\w+", txt)
print(x.group())
运行:

注意:如果没有匹配,None将返回值,而不是匹配对象。
三十七、⭐进阶数据库操作⭐
一、MySQL入门连接
节约版面,跳转本文:数据库连接
二、MySQL创建表
节约版面,跳转本文:数据库创建表
三、MySQL插入表
节约版面,跳转本文:数据库插入表
四 、MySQL选择
节约版面,跳转本文:数据库插入表
五 、MySQL查询位置
节约版面,跳转本文:数据库位置定位
六、MySQL排序
节约版面,跳转本文:数据库排序
七、MySQL删除
节约版面,跳转本文:数据库操作删除
八、MySQL更新表
节约版面,跳转本文:数据库更新表
九、MySQL限制
节约版面,跳转本文:数据库的限制输出
十、MySQL合并
节约版面,跳转本文:数据库表的合并
十一、MySQL删除表
节约版面,跳转本文:数据库删除表
十二、SQL详细教程
前面的部分操作中都用到了SQL语句,在掌握基本python基础情况下,你必须数SQL,节约版面,跳转本文:三万字SQL详细教程
三十八、⭐进阶Git详细教程⭐
GIt详细教程
三十九、⭐进阶爬虫⭐
目前专栏还不够完善,但也有一些内容,后续我会更新。节约版面,跳转专栏:
爬虫教程案例
三十九、⭐终极实战QQ机器人教程⭐
节约版面,跳转本文:QQ机器人制作教程
更多源码与教程请看机器人专栏,节约版面,跳转本专栏:
QQ机器人专栏
四十、⭐粉丝福利⭐
参与我发起的活动,并加入铁杆粉丝群,都有机会领取纸质版的python书籍一本,我付费,包邮放心。本片活动送这本书,为什么送这本书?这本书专注于Python数据分析与可视化操作中实际用到的技术。相比大而全的书籍资料,本书能让读者尽快上手,开始项目开发。

参与方式:
- 左侧加入我的粉丝群,联系群主(就是我)进入铁杆群
- 三连截图
四十一、总结
本篇文章在前面写过的文章之上有过修改,加入了数据库与机器人实战教程,为什么我要出这么完整的文章而不是一篇一篇出呢?考虑到小白会看系列文章容易看糊涂,因此我在这里总结为一篇,保证任何人都可以从零到基础扎实。至此,python基础教程全部这一篇全部讲完了,希望大家支持三联一下。

私人粉丝群,非诚勿扰:970353786
python学习问题加入大家庭一起交流学习,一起加油!创作实在不容易,希望能帮助到你学习,给我三连一下吧。