flower_photos train analysis
补充思考:
flower_photos 数据量比较小,所以 simple_cnn 可以在 trainset 上拟合到 0.99,意思就是数据复杂度 < 模型复杂度
添加数据增强的本质是扩大模型见过的数据量
想要模型泛化性好,只有一个关键因素,数据量
如果让 simple_cnn 在 ImageNet 上做预训练,然后 flower_photos 上做训练,效果会更好吗?
从模型的浅层、中层、深层提取到的不同层次抽象特征来看,MobileNet 等网络无疑更加符合这个划分,此处 simple_cnn 过于简单,所以打个问号
数据集: flower_photos
- daisy: 633张图片 雏菊
- dandelion: 898张图片 蒲公英
- roses: 641张图片 玫瑰
- sunflowers: 699张图片 向日葵
- tulips: 799张图片 郁金香
数据存储在本地磁盘,读取用的是 tf.keras.preprocessing.image_dataset_from_directory(),其中的 image_size 用作 image resize,batch_size 用作 batch
最后的 train_ds = train_ds.shuffle().cache().prefetch(),这样做的目的是减少 IO blocking
下面是模型搭建的代码:
model = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.Rescaling(1. / 255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
此处把 pixel 的 rescale 放进了 Sequential,当做模型搭建的一部分,有利于模型部署
callbacks 里面用到了 ReduceLROnPlateau,Tensorboard,EarlyStopping
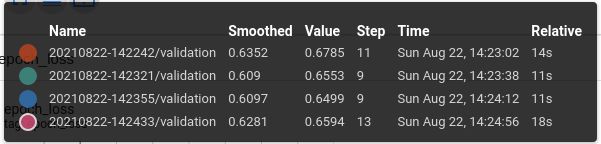
上图是训练模型四次的 log 记录图,其中 val_acc 的区间在 [0.6499, 0.6785],这个是正常现象,所以训练出来的模型准确率是会存在波动的

代码地址: https://github.com/MaoXianXin/Tensorflow_tutorial,但是需要在如上图的地方 flower dataset 这个 commit 处开一个新分支,然后找到 3.py 这个脚本,就能重复上图的实验了
因为上面的实验,准确率才 [0.6499, 0.6785],我们需要进行优化,第一个改进是添加 data augmentation,此处我们直接在模型搭建环节添加,代码如下所示
model = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.Rescaling(1. / 255),
augmentation_dict[args.key],
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
augmentation_dict[args.key],这个就是添加的 data augmentation,此处我们只添加单种,具体 data augmentation 种类如下所示
augmentation_dict = {
'RandomFlip': tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical"),
'RandomRotation': tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
'RandomContrast': tf.keras.layers.experimental.preprocessing.RandomContrast(0.2),
'RandomZoom': tf.keras.layers.experimental.preprocessing.RandomZoom(height_factor=0.1, width_factor=0.1),
'RandomTranslation': tf.keras.layers.experimental.preprocessing.RandomTranslation(height_factor=0.1, width_factor=0.1),
'RandomCrop': tf.keras.layers.experimental.preprocessing.RandomCrop(img_height, img_width),
'RandomFlip_prob': RandomFlip_prob("horizontal_and_vertical"),
'RandomRotation_prob': RandomRotation_prob(0.2),
'RandomTranslation_prob': RandomTranslation_prob(height_factor=0.1, width_factor=0.1),
}
接下来我们看下实验结果的 log 记录图

可以看到,val_acc 大于 0.6785 (未添加数据增强) 的有 RandomTranslation > RandomRotation_prob > RandomRotation > RandomFlip_prob = RandomFlip > RandomZoom > RandomTranslation_prob
从结果看来,数据增强是有效的,接下来我们进行第二个改进,更换更强的网络模型,我们这里选择 MobileNetV2
这里我们分两种情况进行实验,第一种是把 MobileNetV2 当做 feature extraction 来使用,这个要求我们 freeze 模型的 卷积部分,只训练添加进去的 top-classifier 部分,下面上代码
data_augmentation = tf.keras.Sequential([
augmentation_dict[args.key],
])
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
base_model = tf.keras.applications.MobileNetV2(input_shape=img_size,
include_top=False,
weights='imagenet')
base_model.trainable = False
inputs = tf.keras.Input(shape=img_size)
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = tf.keras.layers.Dense(num_classes)(x)
model = tf.keras.Model(inputs, outputs)
print(model.summary())
实验结果如下图所示

可以看到,准确率提升很显著,从数据增强的 0.7316 提升到了 0.8937,这主要得益于 pre-trained model 是在 ImageNet 大数据集上做过训练,提取到的特征泛化性更好
为了进一步提升模型的准确率,我们采用第二种方式,对 pre-trained model 做 fine-tune,就是在第一种方式的基础上,我们 unfreeze 部分卷积层,因为浅层的卷积提取的特征都是很基础的特征,意味着很通用,但是深层的卷积提取的特征都是和数据集高度相关的,这里我们要解决的是 flower_photos,所以可以对深层的一部分卷积做训练,以进一步提高模型的准确率
下面上代码
data_augmentation = tf.keras.Sequential([
augmentation_dict[args.key],
])
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
base_model = tf.keras.applications.MobileNetV2(input_shape=img_size,
include_top=False,
weights='imagenet')
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
inputs = tf.keras.Input(shape=img_size)
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = tf.keras.layers.Dense(num_classes)(x)
model = tf.keras.Model(inputs, outputs)
model.load_weights('./save_models')
print(model.summary())
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(
optimizer=optimizer,
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
K.set_value(model.optimizer.learning_rate, 1e-4)
这里有个特别需要注意的地方是 learning_rate 的设置,K.set_value(model.optimizer.learning_rate, 1e-4),这个地方还是我特地查看了下 learning_rate 的 log 记录图才发现的不对劲

可以看到,进行 fine-tune 的话,模型准确率进一步提升,从 0.8937 —> 0.9482
到此为止,我们实现了在 flower_photos 数据集上 val_acc = 0.9482,下一步可能会用 RandAugment 或者 Semi-supervised 来提升模型的泛化能力
代码地址: https://github.com/MaoXianXin/Tensorflow_tutorial