机器学习(18)-- SVM支持向量机(根据身高体重分类性别)
目录
一、基础理论
二、身高体重预测性别
1、获取数据(男女生身高体重)
2、数据处理(合并数据)
3、设置标签
4、创建分类器(支持向量机)
4-1、创建svm分类器
4-2、设置分类器属性(线性核)
5、训练
6、预测
总代码
一、基础理论
SVM本质:寻求一个最优的超平面进行分类。(分类器)
SVM核:支持很多核(这里主要使用线性核)
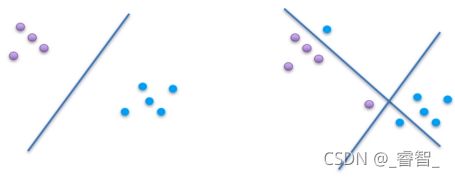
左图分类比较简单,一条线就可以分类;
但右图一条线明显无法完成分类,这时则需要多条线甚至曲线才能完成分类。
这里用的是监督学习,所以必须要有label标签(即目标值)。
二、身高体重预测性别
1、获取数据(男女生身高体重)
获取男女生身高体重(训练集、测试集)
# 训练集
girls_train = np.array([[155, 48], [159, 50], [165, 55], [158, 55], [170, 58]])
boys_train = np.array([[162, 56], [182, 68], [175, 62], [180, 72], [178, 66]])
# 测试集
girls_test = np.array([[152,46], [164,55]])
boys_test = np.array([[175,64], [182, 67]])2、数据处理(合并数据)
# 2 合并数据(并转浮点型,svm需要)
data = np.vstack((girls_train, boys_train))
data = np.array(data, dtype='float32')
print(data)
predict_data = np.vstack((girls_test, boys_test))
predict_data = np.array(predict_data, dtype='float32')
print(predict_data)3、设置标签
# 3 设置标签(监督学习的目标值)(0:负样本;1:正样本)
label = np.array([[0],[0],[0],[0],[0],[1],[1],[1],[1],[1]])4、创建分类器(支持向量机)
4-1、创建svm分类器
# 4-1 创建svm分类器
svm = cv2.ml.SVM_create()4-2、设置分类器属性(线性核)
# 4-2 设置分类器属性
svm.setType(cv2.ml.SVM_C_SVC) #svm 类型
svm.setKernel(cv2.ml.SVM_LINEAR) #设置内核:线性核(最关键)
svm.setC(0.01)5、训练
根据训练集和目标集,进行监督学习。
# 5 训练
svm.train(data, cv2.ml.ROW_SAMPLE, label)6、预测
# 6 预测
print(svm.predict(predict_data))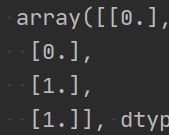
可以看到,结果预测成功,前面两个是女的(0),最后2个是男的(1),达到了想要的效果。

总代码
# SVM支持向量机(根据身高体重预测性别)
import cv2
import numpy as np
# 1 获取数据(男女生身高体重)
# 训练集
girls_train = np.array([[155, 48], [159, 50], [165, 55], [158, 55], [170, 58]])
boys_train = np.array([[162, 56], [182, 68], [175, 62], [180, 72], [178, 66]])
# 测试集
girls_test = np.array([[152,46], [164,55]])
boys_test = np.array([[175,64], [182, 67]])
# 2 合并数据(并转浮点型,svm需要)
train_data = np.vstack((girls_train, boys_train))
train_data = np.array(train_data, dtype='float32')
print(train_data)
test_data = np.vstack((girls_test, boys_test))
test_data = np.array(test_data, dtype='float32')
print(test_data)
# 3 设置标签(监督学习的目标值)(0:负样本;1:正样本)
label = np.array([[0],[0],[0],[0],[0],[1],[1],[1],[1],[1]])
# print(label)
# 4 创建分类器(支持向量机)
# 4-1 创建svm分类器
svm = cv2.ml.SVM_create()
# 4-2 设置分类器属性
svm.setType(cv2.ml.SVM_C_SVC) #svm 类型
svm.setKernel(cv2.ml.SVM_LINEAR) #设置内核:线性核(最关键)
svm.setC(0.01)
# 5 训练
svm.train(train_data, cv2.ml.ROW_SAMPLE, label)
# 训练集 标签(目标集)
# 6 预测
print(svm.predict(test_data))