python爬虫,爬取哔哩哔哩视频
通过python爬虫实现爬取哔哩哔哩视频
-
- 通过python爬虫爬取blbl的一些视频
- 1,get_url函数
- 2,get_video函数
- 3,video_load函数
- 4,video_add_mp4函数
- 5,完整代码部分
- 6,运行结果
通过python爬虫爬取blbl的一些视频
工具:python3.6,pycharm,任意浏览器
相关库: request,re,lxml等
首先本次项目需要安装ffmpeg
这里是ffmpeg的安装教程
由于本人对爬虫也是处于刚起步状态,这篇文章我会尽可能得讲得详细(怕我以后也看不懂…)
1,get_url函数
首先,如果我们知道想要爬取视频的有效详细地址url是可以直接拿到html信息的。但是我们知道b站有个特点,每位up的视频在成功发布后,会有个唯一的特殊的编号,之前是av号,现在是bv号,这个编号就可以作为唯一标识去定位我们想要的视频。
所以现在我们有两种访问方法:1,通过地址直接访问。2,搜索它的av号或bv号,得到唯一搜索结果,拿到url,再去访问。
打开搜索界面随便搜索一下,我们可以观察到在地址中有个很明显的东西’keyword=2‘,它正好对应了我们的搜索内容,大部分网站的搜索功能都是通过这个keyword去传值。

所以我们通过去修改这个‘keyword’为av或bv号的url,就可以达到我们想要的搜索功能。
现在可以看到,当我们输入某一个完整的bv号后,只会返回给我们一个结果,而这个视频的url,就放在这个页面里,这样就很容易拿到了。

打开开发者工具,可以很容易地定位到视频标题以及它的地址的位置,这样通过xpath的标签定位就可以拿到。

现在我们定义一个get_url函数来拿到我们想要视频的url。
!!!这里注意,在pycharm运行中拷贝一个链接过来直接回车会直接去访问,所以我们需要空格一下再回车。并且这里我们重新定义了一个head2,后续会用到。
#get_url函数,选择搜索方式,
#参数:无
#作用:通过搜索返回视频的url地址
def get_url():
print('请选择你的搜索方式')
print('1:知道该视频的完整av号或者bv号')
print('2:知道视频的有效链接地址')
kind = int(input('请选择:'))
if kind == 1:
# print('kw')
kw = input('输入你需要搜索的av号或者bv号,例如 bv1i4411f7p1:')
url = 'https://search.bilibili.com/all?keyword='+kw+'&from_source=web_search'
r_search = requests.get(url =url,headers =head1)
r_search.encoding = r_search.apparent_encoding
r_search_html = r_search.text
# print(r_search_html)
tree_search = etree.HTML(r_search_html)
#href属性中存放的是一个list,且不完整,取出后与字符串'https:'拼接组成完整的url
video_url = 'https:'+str(tree_search.xpath('//*[@id="all-list"]/div[1]/div[2]/ul/li[1]/a/@href')[0])
else:
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
print('!!!注意,在从网页拷贝的链接粘贴后,按一下空格再回车')
kw = input('输入该视频的有效链接地址:')
video_url = kw
# 保持会话状态,在head中添加键值对:referer,存放上一次的会话的url,所以需要一个新的header
head2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67',
'Referer':video_url
}
return video_url,head2
2,get_video函数
现在我们打开刚刚视频的页面看看。
首先我们需要知道,b站的视频在网页中的播放分为两部分,一个音频,一个视频,它们同时工作,我们才能在网页中看到完整的视频。
在开发者工具中,ctrl+f搜索’playinfo‘,这个json串里存放哔哩哔哩视频的音频、视频信息
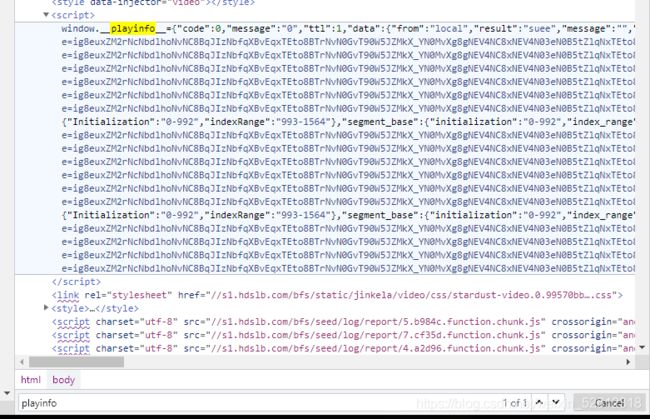
这样看起来杂乱无章,我们使用代码来让它有序些。
使用正则来定位到playinfo这里,取出这个json串。再使用json库的json_loads来帮助我们转化成更容易阅读的形式,再使用pprint.pprint再输出它。
json_data = re.findall('', r2_html)[0]
json_data = json.loads(json_data)
pprint.pprint(json_data)
现在就能很清楚地看到这个json串里面的数据。
里面包括有视频的清晰度,以及各种各样的url地址。现在我们能看到这里面有许许多多的地址,但是我们点击它会报一个403的错,错误说明这个链接是没有错的,但是我们没有权限去访问它。其实是可以访问的,但是我们没有保持视频页面的会话状态就去访问,那么服务器就会认为我们是爬虫而拒绝访问,所以在get_url函数中在head2中添加了‘Referer’,里面存放了视频的url,这样就相当于模拟了我们是先看了视频再去访问它的数据,这样才不会拒绝。

现在来定义第二个函数,get_url函数,从网页中返回视频title和存放视频和音频的两个url,共计三个元素
在这里定义了一个ss列表,里面是一些常见的符号,因为这些符号在后续的文件操作可能会导致错误,所以这里得将它们去除掉。
# get_video函数,
# 参数:网页的url
# 作用:从网页中返回视频title和存放视频和音频的两个url,共计三个元素
def get_video(url):
r2 = requests.get(url=url, headers=head1)
r2.encoding = r2.apparent_encoding
r2_html = r2.text
# 这里需要获取页面中playinfo中存放的json数据,这里存放了视频和音频文件
tree2 = etree.HTML(r2_html)
title = str(tree2.xpath('//*[@id="viewbox_report"]/h1/span/text()')[0])
#去除一些符号,避免后续文件名操作时报错
ss = ['\n', ',', '。', ' ', '—', '”', '?', '“', '(', ')', '、','|']
df = [w for w in jieba.cut(title) if w not in ss] # 去除标点符号
title = '' # 重新将除去标点的分词结果拼接
for i in df:
title = title + i
print('视频标题:"'+title+'"')
json_data = re.findall('', r2_html)[0]
json_data = json.loads(json_data)
# pprint.pprint(json_data)
'''提取音频'''
audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
# print(audio_url)
print('已提取到音频地址')
'''提取视频'''
video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
# print(video_url)
print('已提取到视频地址')
video_list = [title , audio_url , video_url]
return video_list
3,video_load函数
现在我们拿到了两个重要的url,这一步就是将它存放的数据下载下来。
#video_load函数
#参数:存放上述三个数据的列表
#作用:下载音频和视频
def video_load(video_list):
# 下载保存音频和视频两种文件,MP3格式和MP4格式
v_name = video_list[0][:5]
print('开始下载音频')
r3 = requests.get(url=video_list[1], headers=head2)
audio_data = r3.content
with open(v_name+'(audio).mp3', mode='wb') as f:
f.write(audio_data)
print('音频下载完成')
print('开始下载视频')
r4 = requests.get(url=video_list[2], headers=head2)
video_data = r4.content
with open(v_name+'(video).mp4', mode='wb') as f:
f.write(video_data)
print('视频下载完成')
r3.close()
r4.close()
return v_name
4,video_add_mp4函数
前面我们已经下载好了MP3,MP4各一个文件,这一步就将它们合并,这里我们需要使用ffmpeg,ffmpeg是专门做视频处理的工具,需要下载配置。
这里传入参数文件名,通过ffmpeg命令将MP3,MP4合并。
有关于ffmpeg的手册可以去官网查阅。
在ffmpeg命令中输出的名字似乎不能过长,所以切片,后面再更改为标题名。
#mix_video函数
#参数:文件名
#作用:合并音频和视频为原视频
def video_add_mp4(video_name):
video = video_name+"(video).mp4"
audio = video_name+"(audio).mp3"
print('开始合成')
cmd = f'ffmpeg -i {video} -i {audio} -acodec copy -vcodec copy {video_name[:8]+".mp4"}'
# print(cmd)
subprocess.call(cmd,shell=True)
'''选择是否删除原mp3、mp4文件'''
#os.remove(video)
#os.remove(audio)
os.rename(video_name[:8]+'.mp4',video_name+'.mp4') # 记得加文件后缀名
print('合成结束')
5,完整代码部分
这里可以看到我们需要的所有库。
#-*- codeing = utf-8 -*-
# @Time :21/7/12/0012 18:26
# @Author:zx
# @File :哔哩哔哩视频爬取.PY
# @sOFTWARE:PyCharm
import requests
from lxml import etree
import re
import json
import pprint
import subprocess
import os
import jieba
head1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67'
}
#get_url函数,选择搜索方式,
#参数:无
#作用:通过搜索返回视频的url地址
def get_url():
print('请选择你的搜索方式')
print('1:知道该视频的完整av号或者bv号')
print('2:知道视频的有效链接地址')
kind = int(input('请选择:'))
if kind == 1:
# print('kw')
kw = input('输入你需要搜索的av号或者bv号,例如 bv1i4411f7p1:')
url = 'https://search.bilibili.com/all?keyword='+kw+'&from_source=web_search'
r_search = requests.get(url =url,headers =head1)
r_search.encoding = r_search.apparent_encoding
r_search_html = r_search.text
# print(r_search_html)
#实例化xpath对象
tree_search = etree.HTML(r_search_html)
#href属性中存放的是一个list,且不完整,取出后与字符串'https:'拼接组成完整的url
video_url = 'https:'+str(tree_search.xpath('//*[@id="all-list"]/div[1]/div[2]/ul/li[1]/a/@href')[0])
else:
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
print('!!!注意,在从网页拷贝的链接粘贴后,按一下空格再回车')
kw = input('输入该视频的有效链接地址:')
video_url = kw
# 保持会话状态,在head中添加键值对:referer,存放上一次的会话的url,所以需要一个新的header
head2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67',
'Referer':video_url
}
return video_url,head2
# url1,head2 = get_url()
# print(url1,head2)
# get_video函数,
# 参数:网页的url
# 作用:从网页中返回视频title和存放视频和音频的两个url,共计三个元素
def get_video(url):
r2 = requests.get(url=url, headers=head1)
r2.encoding = r2.apparent_encoding
r2_html = r2.text
# 这里需要获取页面中playinfo中存放的json数据,这里存放了视频和音频文件
tree2 = etree.HTML(r2_html)
title = str(tree2.xpath('//*[@id="viewbox_report"]/h1/span/text()')[0])
#去除一些符号,避免后续文件名操作时报错
ss = ['\n', ',', '。', ' ', '—', '”', '?', '“', '(', ')', '、','|']
df = [w for w in jieba.cut(title) if w not in ss] # 去除标点符号
title = '' # 重新将除去标点的分词结果拼接
for i in df:
title = title + i
print('视频标题:"'+title+'"')
json_data = re.findall('', r2_html)[0]
json_data = json.loads(json_data)
#pprint.pprint(json_data)
'''提取音频'''
audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
# print(audio_url)
print('已提取到音频地址')
'''提取视频'''
video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
# print(video_url)
print('已提取到视频地址')
video_list = [title , audio_url , video_url]
return video_list
#这里使用一个列表来存放:1,标题,2:音频地址, 3:视频地址
# video_list = get_video(url1)
# print(video_list)
#video_load函数
#参数:存放上述三个数据的列表
#作用:下载音频和视频
def video_load(video_list):
# 下载保存音频和视频两种文件,MP3格式和MP4格式
v_name = video_list[0][:5]
print('开始下载音频')
r3 = requests.get(url=video_list[1], headers=head2)
audio_data = r3.content
with open(v_name+'(audio).mp3', mode='wb') as f:
f.write(audio_data)
print('音频下载完成')
print('开始下载视频')
r4 = requests.get(url=video_list[2], headers=head2)
video_data = r4.content
with open(v_name+'(video).mp4', mode='wb') as f:
f.write(video_data)
print('视频下载完成')
r3.close()
r4.close()
return v_name
# video_name = video_load(video_list)
#mix_video函数
#参数:文件名
#作用:合并音频和视频为原视频
def video_add_mp4(video_name):
video = video_name+"(video).mp4"
audio = video_name+"(audio).mp3"
print('开始合成')
cmd = f'ffmpeg -i {video} -i {audio} -acodec copy -vcodec copy {video_name[:8]+".mp4"}'
# print(cmd)
subprocess.call(cmd,shell=True)
'''选择是否删除原mp3、mp4文件'''
# os.remove(video)
# os.remove(audio)
os.rename(video_name[:8]+'.mp4',video_name+'.mp4') # 记得加文件后缀名
print('合成结束')
if __name__ == "__main__":
# get_url函数,选择搜索方式,
# 参数:无
# 作用:通过搜索返回视频的url地址和后续需要的header
url1, head2 = get_url()
# get_video函数,
# 参数:网页的url
# 作用:从网页中返回视频title和存放视频和音频的两个url,共计三个元素
video_list = get_video(url1)
# video_load函数
# 参数:存放上述三个数据的列表
# 作用:下载音频和视频
video_name = video_load(video_list)
# mix_video函数
# 参数:文件名
# 作用:合并音频和视频为原视频
video_add_mp4(video_name)
6,运行结果
这里展示get_url函数的两种情况
1,使用bv号搜索:

2,详细链接:

至此,你就可以在当前目录下看到你下载的视频,关于路径是可以根据自己的需求来更换的。在video_add_mp4函数中你可以选择是否删除之前的两个文件。
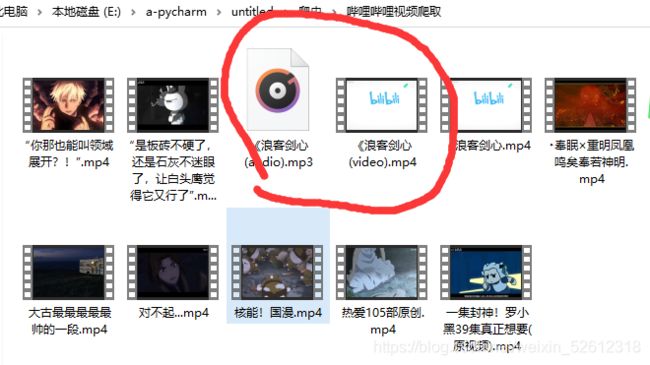
现在,你就可以在b站下载视频了,我不能保证所有的视频都可以下载,首先什么会员专享、番剧之类的就不可以,这里主要是针对up主的原创视频。