hadoop中hive与mapreduce小文件合并优化实操(超强详解!!!)
目录
- 1-背景
-
- 1.1-造成大量小文件的原因:
- 1.2-小文件的危害:
- 2-解决方案实操
-
- 2.1-解决方案1
- 2.2-解决方案2
- 2.3-解决方案3
- 3-总结扩展
-
- 3.1-总结
- 3.2-扩展(map任务数量的准确控制)
1-背景
公司数据治理过程中,发现apache hadoop大数据环境下hdfs中有数量惊人的小文件。
如图所示为hdfs的web管理页面:
如上图所示可以看到hive中的这个表的20200630这个分区中有551个数据文件。
但是我们可以看到hdfs中的默认设置每个块大小为256M,而该表分区存储数据的每个块大小才为十几M,远远小于默认块大小,这就是小文件!
1.1-造成大量小文件的原因:
主要原因如下:
- 1.实时(流式)数据,flume,spark streaming,flink等组件生成,流式增量文件到hive(如设定几分钟生成一次文件)等。
- 2.在纯map任务下,大量的map任务;或者大量的reduce任务都会生成很多小文件块到hdfs。
1.2-小文件的危害:
首先要知道的是hdfs中的两大模块,namenode(存储文件元数据,管理读写流程)和datanode(存储数据)。
(1)对namenode的影响:
大量的元数据占用大量namenode的内存
以公司hdfs采用的是三副本策略,设置文件块大小默认为128M,
举个例子:
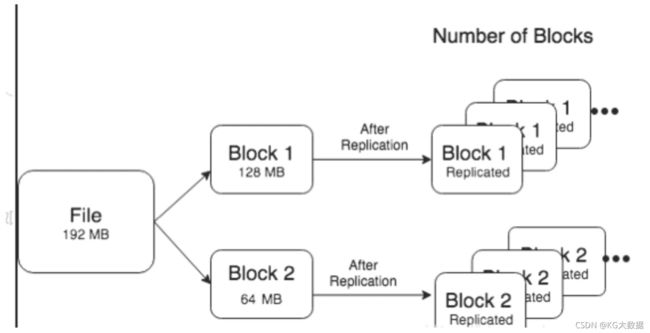
- 如图所示,一个文件192M,默认blocksize = 128M,服本数为3个,存储为两个block。
- namenode中的namespace中主要占存储对象是文件的目录个数,文件名长度,文件block数。在namenode中一个存储对象大概占用150字节的空间,存储文件占用namenode的内存空间计算公式如下:
- Memory = 150bytes * (一个文件inode + (文件的块数 * 副本数))
即当前该文件占用namenode的内存大小为:150 * (1 + (2 * 3)) = 1050bytes。
举第二个例子:

- 如图所示,同样一个192M的文件,默认blocksize = 128M,服本数为3个,存储为192个block。
- 所以当前文件存储模式下占用namenode内存为:150 * (192 + (192 * 3)) = 11520bytes。
- 总结:从以上两个例子可以看出来,同样一个文件大小不同形态的存储占用namenode的内存之比相差了109倍,所以大量的小文件会 占用大量的namenode内存,影响集群性能。
(2)对datanode的影响:
对于高负载的大数据集群,花费在寻址上的时间要比数据读取写入的时间更长(hdfs的读写流程)。
(3)对计算性能的影响:
大量的小文件(block),意味着更多的map任务调度,更多启动任务的开销,更多的任务管理开销。
2-解决方案实操
hive的官方文档解决方法截图如下:

2.1-解决方案1
`set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --官方默认值,也是当前平台默认值`
`set hive.merge.smallfiles.avgsize=16000000; (当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge)`
`set hive.merge.size.per.task=256000000; --官方默认值,也是当前平台默认值(合并文件的大小)`
`set hive.merge.mapfiles =true ; --官方默认值,也是当前平台默认值`
`set hive.merge.mapredfiles = true ; --官方默认值,也是当前平台默认值`
`drop table if exists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp;`
`create table FDM_SOR.t_fsa_bhvr_new_expo_d_tmp_tmp`
`stored as orc`
`as`
`select * from FDM_SOR.t_fsa_bhvr_new_expo_d`
`where stat_date = '20200630'`
如上代码为hive官方提供的解决小文件的办法,设置启动mao前先进行文件合并(四个参数设置)。
- 方案一测试结果为:
结果如图所示文件数量由原来的551个小文件变为438,此时文件数量是变少了,
但是还是存在有很多小于16M的小文件,如下图所示:
即使用该官方参数效果不明显!!!
2.2-解决方案2
将set hive.merge.smallfiles.avgsize值加大,增加文件合并的Size。
代码如下:
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --官方默认值,也是当前平台默认值`
`set hive.merge.smallfiles.avgsize=256000000; --改了这个值,由默认的16Mb,改成256Mb`
`set hive.merge.size.per.task=256000000; --官方默认值,也是当前平台默认值`
`set hive.merge.mapfiles =true ; --官方默认值,也是当前平台默认值`
`set hive.merge.mapredfiles = true ; --官方默认值,也是当前平台默认值`
`drop table if exists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp;`
`create table FDM_SOR.t_fsa_bhvr_new_expo_d_tmp_tmp`
`stored as orc`
`as`
`select * from FDM_SOR.t_fsa_bhvr_new_expo_d`
`where stat_date = '20200630'`
该段代码运行结果如下:
修改set hive.merge.smallfiles.avgsize参数为256M后,生成的文件数有所减少,但是依旧存在问题,还是存在大量小于10M的小文件,方案二还是失败!
2.3-解决方案3
在执行官方给到的两个参数设置前加上split(map读取切片大小)参数设定,测试代码如下:
`set mapred.max.split.size=256000000;(每个map的最大输入文件大小)`
`set mapred.min.split.size=10000000; --公司集群默认值`
`set mapred.min.split.size.per.node=100000000;(一个节点上处理的split的最小容量),决定了多个datanode上的文件是否需要合并`
`set mapred.min.split.size.per.rack=100000000;(一个机架上处理的split的最小容量),决定了多个交换机上的文件是否需要合并`
`set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;`
`set hive.merge.mapfiles = true ;`
`set hive.merge.mapredfiles = true ;`
`set hive.merge.size.per.task = 256000000 ;`
`set hive.merge.smallfiles.avgsize=160000000 ;`
`drop table if exists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp;`
`create table FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp`
`stored as orc`
`as`
`select * from FDM_SOR.T_FSA_BHVR_NEW_EXPO_D`
`where stat_date = '20200630'`
新增三个设置map读取切片大小的参数,方可彻底解决小文件问题,结果如下所示(先上结果!):
HDFS上所存文件展示如下:
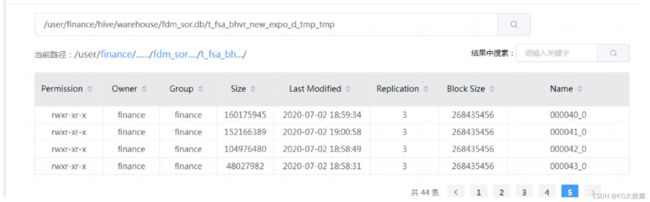
结果生成44个大文件,最小的为48M(最后一个切片)。
3-总结扩展
3.1-总结
如果只设置官方文档中给的参数设置,看上去规定了在map端结束,或者mapreduce结束之后合并文件,即如果文件平均小于smallfiles.avgsize给定的值就启动一个新的MR程序进行小文件的二次合并,关键点在于,新启动一个MR程序去合并这些文件,这个MR程序的map需要先去读取文件块的split(切片)。如果没有设置split的大小,或者设置过小,还是会产生很多maptask(该合并小文件的MR程序只有map阶段),最后依旧会产生很多小文件,所以最终方案是要配合split参数才会彻底解决小文件问题!
3.2-扩展(map任务数量的准确控制)
首先最先要看当前的文件存储格式是否存在压缩,所谓压缩就是降低磁盘的占用量,提高数据传输效率。
工作中比较常见的hdfs数据压缩格式如下所示:
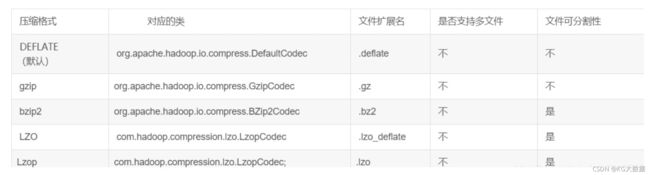
(1)首先查看当前hive表是否开启压缩
`hive> set io.compression.codecs; --配置了哪些压缩算法`
`io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.BZip2Codec`
`hive> set hive.exec.compress.output;`
`hive.exec.compress.output=true --是否开启压缩`
`hive> set mapreduce.output.fileoutputformat.compress.codec; --使用的压缩算法`
`mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec`
可以看到本台机器上hive目前开启了压缩,使用的压缩是hive中自带的默认压缩算法(DEFLATE)。
详细举例:
- 有两张表,
- 大表company_liquidation_fgeics_company_ar_d,158749566行,文件总大小4.4G,存储个数22个文件,每个大小200Mb左右。
- 小表t_fgeics_company_liquidation_d_tmp,总共1979375 行,文件大小50.7Mb,存储个数2个文件,大小50Mb以内。
`[finance@hadoop-client13-prd ~]$ hadoop fs -du -h hdfs://xxxxx/user/finance/hive/warehouse/fdm_tmp.db/company_liquidation_fgeics_company_ar_d`
`206.7 M hdfs://xxxxx/user/finance/hive/warehouse/fdm_tmp.db/company_liquidation_fgeics_company_ar_d/000000_0.deflate`
`[finance@hadoop-client13-prd ~]$ hadoop fs -du -h hdfs://xxxxx/user/finance/hive/warehouse/fdm_tmp.db/t_fgeics_company_liquidation_d_tmp`
`36.4 M hdfs://xxxxx/user/finance/hive/warehouse/fdm_tmp.db/t_fgeics_company_liquidation_d_tmp/000000_0.deflate`
`14.3 M hdfs://xxxxx/user/finance/hive/warehouse/fdm_tmp.db/t_fgeics_company_liquidation_d_tmp/000001_0.deflate
运行如下图所示的代码并结果展示如下:
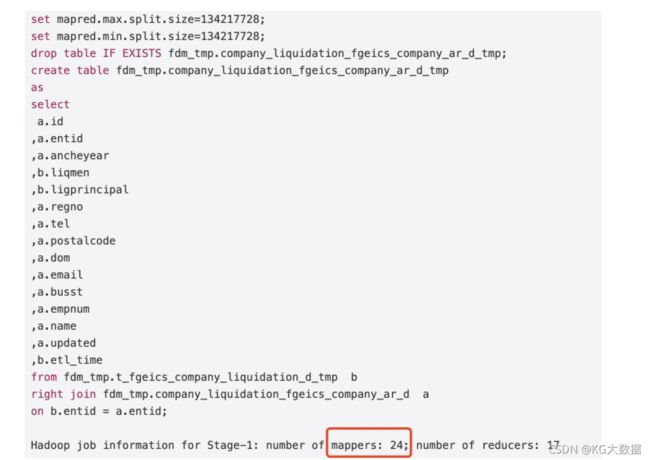
结果分析:hive启动了24个map函数,17个reduce函数。在hadoop中,一般默认的split切片小于等于blocksize(128Mb),如果是小文件的话(未进行小文件的合并)则每个小文件启动一个map函数。而实际在hive中,并不是split的大小要小于等于blocksize,而是可以远大于blocksize。比如这里,4.4G文件表,按128Mb切片算的话,至少实际需要35个map,而实际只需要24个,平均每个map处理了187Mb的文件;原因就是该表文件启动了压缩,且是hive的默认配置压缩,因为该压缩不可切分,原本两个表存储了24个压缩文件,所以maptask在读取文件的时候就只读了24个压缩文件。
小扩展:虽然压缩文件(不可切分的压缩形式)不支持切片,但是支持合并,举个例子:
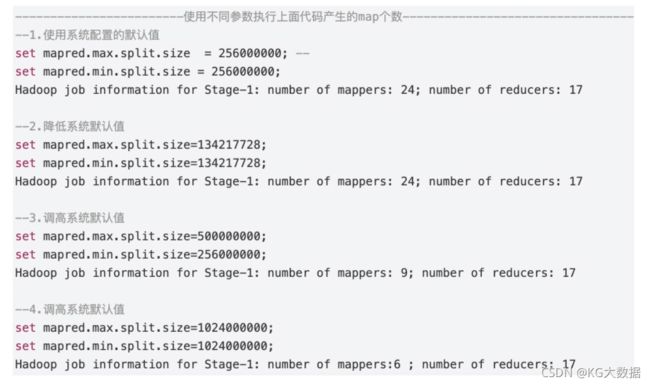
- 测试2调低了split大小,但是运行结果map数并没有增加,因为当前压缩不支持切分。
- 测试3和四调高了split参数,map数减少,说明了当前压缩支持合并。
如果hive处理的文件是压缩模式,且压缩模式不支持文件切分,那么这个时候我们只能通过控制参数来减少map个数,而不能通过配置参数来增加map个数,所以Hive对于压缩不可切分文件的调优有限。
举个例子(当前两张表取消压缩模式):

同样是上面那个4.4g文件,我们这个时候让其为非压缩模式,发现这个时候文件总大小为23.4G,存储为22个文件,平均每个文件大小都在1.1G左右。上代码:
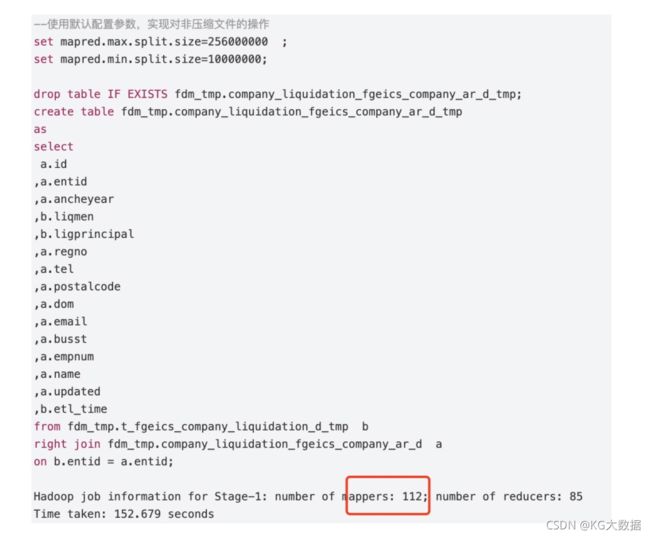
如代码所示一共启动了112个map,符合参数的设置结果set mapred.max.split.size=256000000 ; 23.4*1024/112=187Mb<256000000,符合代码最开头的split的参数设置。
测试二:

如图所示,将上面默认的参数对应调小,运行同样上面的代码,看map数是否有增加? 很显然,我们通过设置max.split.size的值实现了增加map个数的功能。这里map的个数由122个数变成了199个,平均每个map处理数据120Mb左右。但是运行时间却变慢了很多,时间由153s变成了243s。
测试三:

如图所示,将上面的默认参数增加,运行同样的代码,结果虽然我们将maxsplitsize设置的特别大,但是对应map的个数并没有对应的成倍减少,如果按最大值算应该在20多个map,而实际不是这样。这说明,光设置最大值是没有用的,这只是一个峰值,还有对应的设置最小值,此时的结果就对应了上面参数设置,此时还要设定每个节点,每个机架上处理的最小split容量。
测试四(终极答案):
如图所示最后决定精确控制map数的决定性条件是mapred.min.split.size.per.rack。
结论:控制map个数是由以下四个参数起作用,这四个参数的优先级为
min.size.per.rack >= min.size.per.node >= min.split.size >= max.split.size !!