30分钟Selenium爬虫快速上手
30分钟Selenium爬虫快速上手
By GuoYL
Version 01.2021.06.18
致谢:路飞学城樵夫老师
一、爬虫概述
- 什么是爬虫?
爬⾍就是通过编写程序,分析网页源代码来爬取互联⽹上的优秀资源(图⽚, ⾳频, 视频, 数据)。
- 爬虫一定要Python吗?
编程语言只是工具,Java、C等开发语言也可以爬虫。而Python在众多编程语言中上手最快、语法最简单,并且爬虫相关的第三方支持库非常多,实现爬虫更容易。
- 是否合法?
法律是不禁止爬虫的,但是爬虫具有违法风险,恶意的爬虫影响网站的正常运营,必将受到惩罚。我们应当实时优化自己的程序,避免干扰网站的正常运行,当爬取到设计用户隐私和商业机密的内容时,一定及时终止爬取和传播。
二、浏览器元素定位和抓包
为了获取我们期望的数据,编写爬虫程序前需要先分析网页,那么如何查看网页数据呢?这里以Chrome浏览器为例,快捷键F12或者如下图所示进入开发者工具。

开发这工具中,爬虫主要用到Elements和Network两个功能,Elements帮助我们定位网页元素,查看网页代码;Network是抓包工具,查看网页请求数据和响应数据。
进入Elements我们发现HTML代码太多了,十分不利于阅读。这时我们就需要借助元素选择器,帮我们找到感兴趣的数据。选中左侧的元素选择器,然后我们的鼠标指向网页哪里,就可以在下方看到对应的代码了。

那么抓包有什么用呢?
我们进入抓包工具,刷新页面可以看到抓取到很多东西,选中XHR进行筛选,可以看到我们刚刚发送的请求包,选中后可以看到包中的数据,包括:
- Request URL:请求地址
- Request Method:
POST还是GET - Cookie:本地字符串数据信息(⽤户登录信息, 反爬的token)
- User-Agent:请求载体的身份标识
其中Cookie和User-Agent是我们在爬虫过程中模拟请求的关键信息。

三、XPath
XPath是⼀⻔在 XML ⽂档中查找信息的语⾔。⽽我们熟知的HTML恰巧属于XML的 ⼀个⼦集。 所以完全可以⽤XPath去查找html中的内容,在爬虫中应用比较广泛。
学习本章的重点是掌握XPath表达式。
1.安装lxml模块
pip install lxml
用法:
1.将要解析的html内容构造出etree对象
2.使用etree对象的xpath()方法配合xpath表达式完成对数据的提取
2.举例
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Titletitle>
head>
<body>
<ul>
<li><a href="http://www.baidu.com">百度a>li>
<li><a href="http://www.google.com">谷歌a>li>
<li><a href="http://www.sogou.com">搜狗a>li>
ul>
<ol>
<li><a href="feiji">飞机a>li>
<li><a href="dapao">大炮a>li>
<li><a href="huoche">搜狗a>li>
ol>
<div class="rou">肉夹馍div>
<div class="tang">胡辣汤div>
body>
html>
from lxml import etree
# 构建etree对象
tree = etree.parse('1.html')
三种xpath表达式
# 1.全路径查找,第一个/表示文档最开始
result = tree.xpath('/html/body/div') # 只查找body标签下的div标签
# 2.省略路径
result = tree.xpath('//div') #查找所有的div标签
# 3.使用通配符
result = tree.xpath('/html/*/div')
获取数据
# 获取文本
result = tree.xpath('/html/body/div/text()') # 获得div标签的文本信息,如 肉夹馍,胡辣汤
# 获取属性
result = tree.xpath('//*[@class=]') # 获取a标签href的属性值
条件匹配
result = tree.xpath('//div[@class="rou"]') # 只匹配具有属性class="rou"的div标签
局部解析
# 先拿到ul标签下所有的li元素
li_list = tree.xpath('//ul/li')
for li in li_list:
print(li.xpath('./a/@href'))#输出每一个a标签的href属性
四、Selenium
Selenium本事一个自动化测试工具,可以启动一个全新的浏览器,并从浏览器中提取到你想要的内容,这样我们就可以避免网站加密和反爬问题,十分方便新手快速处理绝大多数的爬虫任务。但是有一点要注意,selenium最大问题就是慢,它要启动一个第三方浏览器并等待浏览器完成渲染,这个过程是十分耗时的。
1.安装selenium库
pip install selenium
与此同时还需要下载一个浏览器驱动程序
Chrome驱动:下载地址,找到对应的版本并下载。
其他浏览器驱动请自行百度。

**关键:**将下载后的驱动解压到 python.exe同目录或放在程序所在文件夹,推荐放在pyhon.exe同文件夹中。
2.基础案例
from selenium.webdriver import Chrome
# 创建浏览器对象
web = Chrome() # 如果你的浏览器驱动放在了解释器⽂件夹
#web = Chrome(executable_path="chromedriver") # 如果你的浏览器驱动放在了项⽬⾥.
# 打开百度并输出网页title
web.get('http://www.baidu.com')
print(web.title)
3.配合XPath使用
案例:爬取拉勾网Python工程师招聘信息
3.1 准备工作
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
web = Chrome()
web.get('http://lagou.com')

3.2 点击按钮
要想点击城市按钮,就需要结合前两章学习的HTML定位和XPath啦。
这里可以借助Chrome开发者工具快速获得XPath,但是请注意,拷贝的XPath容易出错,尤其遇到页面内iframe问题,应当检查拷贝结果。

# 找到a元素
beijing = web.find_element_by_xpath('//*[@id="changeCityBox"]/ul/li[1]/a')
# 点击
beijing.click()
3.3 键盘指令
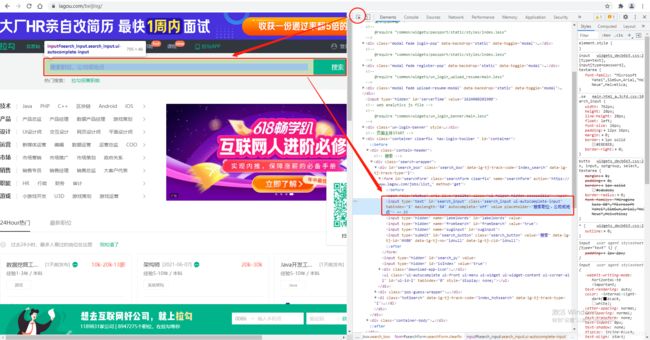
要想搜索我们期望的数据,应该怎么做:
- ⼈的过程: 找到⽂本框输⼊"python",点击"搜索"按钮.。
- Selenium的过程: 找到⽂本框输⼊"python",点击"搜索"按钮。
那么Selenium是怎么完成这些动作呢?
# 第一种:输入python,再点击搜索
web.find_element_by_xpath('//*[@id="search_input"]')
web.find_element_by_xpath('//*[@id="search_button"]').click()
# 第二种:通过输入回车执行搜索
web.find_element_by_xpath('//*[@id="search_input"]').send_keys('python', Keys.ENTER)
3.4 多元素信息提取
搜索结果中将所有的招聘信息展示成一个列表,我们该如何把列表中所有的数据都爬下来?

Selenium提供了方法find_elements_by_xpath,可以方便地一次性获取多个符合条件的元素。
li_list = web.find_elements_by_xpath('//*[@id="s_position_list"]/ul/li')
# 直接拷贝XPath结果是//*[@id="s_position_list"]/ul/li[1],[1]是ul下li标签的序号,从1开始,我们要获取所有li标签,所以讲定位序号去除
# 局部解析
for li in li_list:
price = li.find_element_by_xpath('./div[1]/div[1]/div[2]/div/span').text
print(price) # 打印薪资
3.5 窗口跳转
需求:获取岗位招聘的详细信息。
人为地操作是通过点击招聘条目,进入到详情页。这时我们发现浏览器为我们新启了一个标签页,那么我们怎么获取到新网页的数据呢?
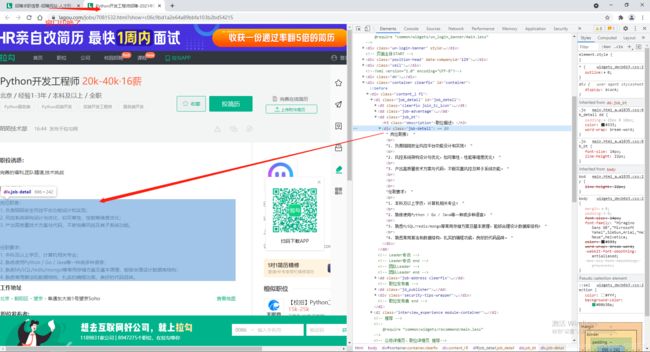
# 局部解析
for li in li_list:
# 找到详情页url并打开
item_url = li.find_element_by_xpath('./div[1]/div[1]/div[1]/a/h3').click()
time.sleep(1)
# 将窗口移动到最后一个标签页
web.switch_to.window(web.window_handles[-1])
job_details = web.find_element_by_xpath('//*[@id="job_detail"]/dd[2]/div').text
print(job_details)
time.sleep(1)
# 关闭详情页
web.close()
web.switch_to.window(web.window_handles[-1])

3.7 下拉框处理
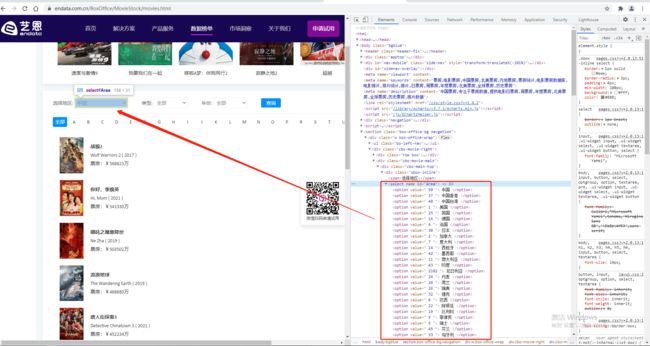
from selenium.webdriver import Chrome
from selenium.webdriver.support.select import Select
import time
web = Chrome()
web.get('https://www.endata.com.cn/BoxOffice/MovieStock/movies.html')
sel = Select(web.find_element_by_xpath('//*[@id="Area"]'))
# 根据索引选择
sel.select_by_index(3)
# 根据option文字选择
sel.select_by_visible_text('中国香港')
# 根据option的value属性选择
sel.select_by_value(' 50 ')
3.7 iframe处理
网页中经常遇到页面嵌套的情况,在一个html中嵌套一个iframe,需要格外注意!!
# 找到那个iframe
iframe = web.find_element_by_xpath('//*[@id="player_iframe"]')
# 进入到iframe
web.switch_to.frame(iframe)
val = web.find_element_by_xpath('/html/body/div[4]').get_attribute("value")
这是一个常见问题, 需要格外注意!!!!
3.8 无头浏览器
上面的案例中,访问页面需要将网页展示出来,受到电脑性能和网络性能的影响,本地执行程序会在网页元素没加载成功时就开始搜索元素,过程十分缓慢且可能引起报错,所以案例中会加入time.sleep(1)进行等待。此外,我们也可以通过无头浏览器访问的方式,减去网页渲染的时间,帮助提升爬虫效率。
from selenium.webdriver.chrome.options import Options
# 准备⽆头浏览器配置信息
opt = Options()
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
web = Chrome(options=opt) # 将⽆头信息进⾏配置
web.get('https://www.baidu.com/')
web.title
4.更多元素获取方式
除了上节通过XPath的方式定位元素,Selenium为我们提供了更多的定位方式,下面展示的只是一部分。
# 通过id属性
web.find_element_by_id()
# 通过name属性
web.find_element_by_name()
# 通过class属性
web.find_element_by_class_name()
# 通过css选择器
web.find_element_by_css_selector()
# 通过链接属性
web.find_element_by_link_text()
/’)
web.title
## 4.更多元素获取方式
除了上节通过XPath的方式定位元素,Selenium为我们提供了更多的定位方式,下面展示的只是一部分。
```python
# 通过id属性
web.find_element_by_id()
# 通过name属性
web.find_element_by_name()
# 通过class属性
web.find_element_by_class_name()
# 通过css选择器
web.find_element_by_css_selector()
# 通过链接属性
web.find_element_by_link_text()