【DeepWalk: Online Learning of Social Representations】
整理自 https://blog.csdn.net/qq_31778495/article/details/80757478
目录
0.基本信息
1.论文简介
2.论文作者及单位
3.论文相关报告和代码开源
1.概述
2.简介
3.主要成果
4.目标问题
5.理论支持
5.0白话理解
5.1幂律分布
5.2 语言模型
6.算法介绍
6.1 算法一:短随机游走生成采样节点序列
6.2 算法二:利用word2vec中SkipGram算法生成向量
6.3优化
6.4 算法整体流程
6.5 核心代码
7.实验
7.1 多标签分类
数据集
baseline:
7.2 参数敏感性
探究参数的变化对分类性能的影响
采样频率的影响
8.应用
重点参考
0.基本信息
1.论文简介
论文题目:DeepWalk: Online Learning of Social Representations
发表时间 :2014
发表会议 : KDD
目前引用量高达:3162
2.论文作者及单位
(单位-纽约州立大学石溪分校) :

3.论文相关报告和代码开源
论文地址: https://dl.acm.org/doi/10.1145/2623330.2623732
【如何查看搜索】
1.概述
本篇论文主要介绍了如何把自然语言处理模型word2vec的方法应用到网络的节点表示中,通过word2vec的方法把网络学习为向量的潜层表示,能把网络中的联系编码到连续的向量空间中,这样网络的关系就能够很方便的通过各种统计模型来对这些网络中的联系进行各种应用。
2.简介
DeepWalk是一种用来学习图(网络)中顶点的潜在表示的一种基于简单神经网络的算法。DeepWalk 算法第一次将深度学习中的技术引入到图(网络)表示学习领域,且充分利用了图(网络)结构中的随机游走序列的信息。
普通的邻接矩阵在存储的关系很多时,纬度将变得很高,而进行矩阵分解是一个相当费时复杂的过程,因此通过矩阵分解的方法进行网络的表示学习,目前并没有应用到大尺度数据集的方案。
本文通过将已经成熟的自然语言处理模型word2vec应用到网络的表示上,做到了无需进行矩阵分解即可表示出网络中的节点的关系。
DeepWalk把对图中节点进行的一串随机游走类比于word2vec中对单词的上下文,作为word2vec算法的输入,进而把节点表示成向量。输出的结果能够被多种分类算法作为输入应用。
3.主要成果
* 通过对网络进行短随机游走生成了可以被统计模型应用的网络表示
* 所学得的表示在多标签分类任务中,性能优于已有算法。某些情况下,甚至能在训练样本较少时获得更好结果。
* 能对web-scale下的网络进行表示
4.目标问题
Deepwalk是一种将随机游走(random walk)和word2vec两种算法相结合的图结构数据挖掘算法。该算法能够学习网络的隐藏信息,能够将图中的节点表示为一个包含潜在信息的向量,如下图表示

输入:一个图的点集和边集
输出:对于(其中X是特征,Y标签集合),一般的机器学习问题,需要学习一个从X映射到Y的hypothesis。而本文的任务就是学习得到X的低维表示。摘自DeepWalk:Online Learning of Social Representations》笔记
5.理论支持
5.0白话理解
想想单词的词向量训练的时候,是不是根据文本序列,生成中心词和上下文词列表分别作为输入输出训练skipgram模型的;那么对于图来说,问题有
1)怎么生成节点序列呢?有节点序列就可以生成中心节点和上下文节点列表,就可以训练skipgram模型了!
2)并且这个节点序列一定要像文本序列一样的分布(即联系得紧密,就越能共现)deepwalk生成的节点序列就有这个特点!
那么deepwalk到底是什么呢?怎么生成节点序列呢?它真的是经典又简单。
解决:
1)随机游走,我从任意一个节点出发,随机选择和该节点有边的一个节点作为下一个节点,不断重复这个过程,就生成了一个节点序列啦!
2)用我们的意念想一想!是不是采样的节点序列多了以后,联系得越紧密的节点,就越能共现。严谨的同分布证明在paper里有,感兴趣的可以看!
5.1幂律分布
DeepWalk的主要思想来源于Word2Vec,作者首先介绍了自然语言中的词频满足统计学中的幂律分布(Power Laws),而在网络中对每个顶点进行指定深度的随机游走得到的顶点序列也同样满足幂律分布(下面算法1利用到),如下图所示。因此可以相应地将NLP中的word2vec运用在图(网络)中的顶点表示上,故而有了DeepWalk算法。

5.2 语言模型

6.算法介绍
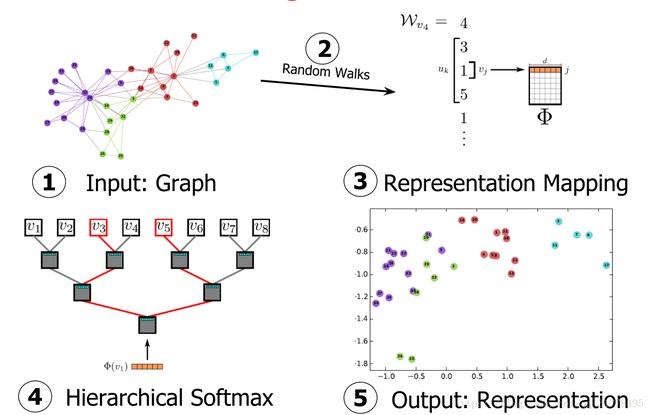
该算法主要分为随机游走和生成表示向量两个部分。首先利用随机游走算法(Random walk)从图中提取一些顶点序列;然后借助自然语言处理的思路,将生成的定点序列看作由单词组成的句子,所有的序列可以看作一个大的语料库(corpus),最有利用自然语言处理工具word2vec将每一个顶点表示为一个维度为d的向量。
整个算法主要分为两部分
1、随机游走采样节点序列:RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件(语料库)。
2、使用skip-gram modelword2vec学习表达向量:获取足够数量的节点访问序列(语料库)后,使用skip-gram model 进行向量学习。
具体步骤即
①构建同构网络,从网络中的每个节点开始分别进行Random Walk 采样,得到局部相关联的训练数据; ②对采样数据进行SkipGram训练,将离散的网络节点表示成向量化,最大化节点共现,使用Hierarchical Softmax来做超大规模分类的分类器
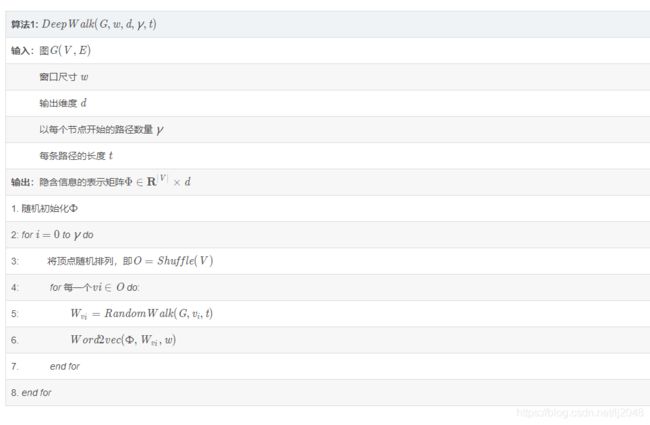
6.1 算法一:短随机游走生成采样节点序列



将输入的图的点集进行随机打乱(Shuffle()函数),然后输入到SkipGram算法中进行表示学习,翻译成中文,如下:
6.2 算法二:利用word2vec中SkipGram算法生成向量
Skip-Gram Modeling是一种基于神经网络结构的Word2Vec模型,主要利用Word2Vec的思想将Random Walks中拿到的随机游走的顶点序列作为语料库,训练神经网络模型,进而学习每个顶点的向量表示。


6.3优化
另外针对该目标函数在大规模图网络场景下面临的计算复杂度,作者提出了一种优化方法叫Hierarchical Softmax(树结构)。使得目标函数的计算时间复杂度从O(V)降到了O(logV) 。另外作者还给出了并行计算框架下的实现范例,具体可以参考原论文。

6.4 算法整体流程
6.5 核心代码
可以通过并行的方式加速路径采样,在采用多进程进行加速时,相比于开一个进程池让每次外层循环启动一个进程,我们采用固定为每个进程分配指定数量的num_walks的方式,这样可以最大限度减少进程频繁创建与销毁的时间开销。
deepwalk_walk方法对算法1伪代码中第6行,_simulate_walks对应算法1伪代码中第3行开始的外层循环。最后的Parallel为多进程并行时的任务分配操作。
此代码参考 https://zhuanlan.zhihu.com/p/56380812
def deepwalk_walk(self, walk_length, start_node):
walk = [start_node]
while len(walk) < walk_length:
cur = walk[-1]
cur_nbrs = list(self.G.neighbors(cur))
if len(cur_nbrs) > 0:
walk.append(random.choice(cur_nbrs))
else:
break
return walk
def _simulate_walks(self, nodes, num_walks, walk_length,):
walks = []
for _ in range(num_walks):
random.shuffle(nodes)
for v in nodes:
walks.append(self.deepwalk_walk(alk_length=walk_length, start_node=v))
return walks
results = Parallel(n_jobs=workers, verbose=verbose, )(
delayed(self._simulate_walks)(nodes, num, walk_length) for num in
partition_num(num_walks, workers))
walks = list(itertools.chain(*results))7.实验
7.1 多标签分类
数据集
- BlogCatalog [39] is a network of social relationships provided by blogger authors. The labels represent the topic categories provided by the authors.
- Flickr [39] is a network of the contacts between users of the photo sharing website. The labels represent the
interest groups of the users such as ‘black and white photos’. - YouTube [40] is a social network between users of the popular video sharing website. The labels here
represent groups of viewers that enjoy common video genres
baseline:
* SpectralClustering
* Modularity
* EdgeCluster
* wvRN
* Majority
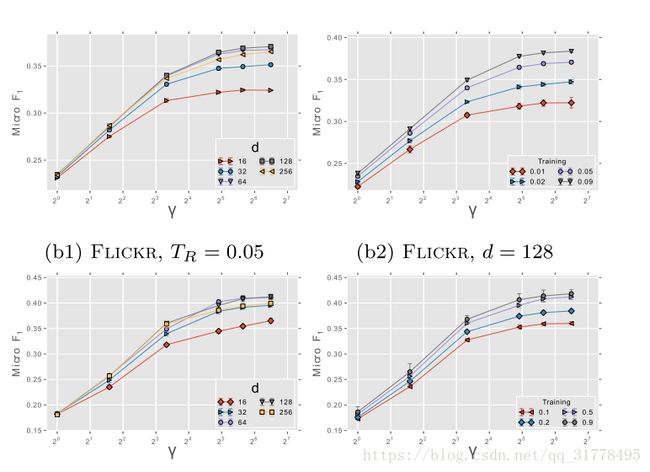
7.2 参数敏感性
探究参数的变化对分类性能的影响
* 隐含表示的空间的纬度(d)和训练速率的变化。(a1和a3)
* 每个顶点的纬度和游走数量(Y)的变化。(a2和a4)
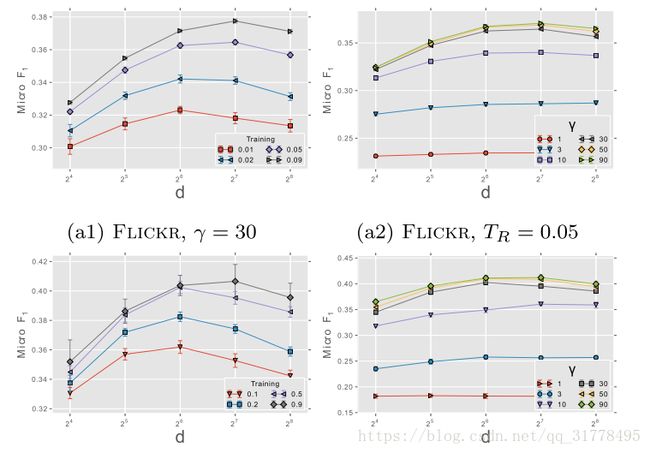
采样频率的影响
8.应用
通过DeepWalk我们可以学习得到所有顶点的连续性特征表示,然后利用这些特征,我们可以做聚类,异常检测,半监督分类等。由于SkipGram的特性,窗口内相邻的顶点会得到相似的一般表示,因此,利用DeepWalk学习到的网络特征进行无监督聚类,可以得到效果比较好的社区发现结果,通常可以在风控场景下用来做群组分析。以上就是DeepWalk的全部内容。
重点参考
论文链接: http://www.perozzi.net/publications/14_kdd_deepwalk.pdf
作者的slide:http://www.perozzi.net/publications/14_kdd_deepwalk-slides.pdf
作者视频报告:https://www.bilibili.com/video/av55742327/
代码实现:https://github.com/phanein/deepwalk
作者网站:http://www.perozzi.net/projects/deepwalk/
重点讲解分析参考
https://zhuanlan.zhihu.com/p/56380812
https://zhuanlan.zhihu.com/p/56380812
https://zhuanlan.zhihu.com/p/68328470?utm_source=wechat_session
https://www.jianshu.com/p/f3c64579a7ec
详细翻译
https://blog.csdn.net/alanlala/article/details/100854979
数学部分的详细翻译见(论文的问题定义第二部分+学习社会表示第三部分)
https://www.jianshu.com/p/bff937ed1a64
关于Word2vec的方法详情请见各大博客,例如http://shomy.top/2017/07/28/word2vec-all/和https://blog.csdn.net/itplus/article/details/37969519