
作者:顺达
最近夸克端智能小组在做端上的实时文档检测,即输入一张RGB图像,得到文档的四个角的关键点的坐标。整个pipelines属于关键点检测算法,因此最近对相关领域的论文进行阅读和进行了实验尝试。
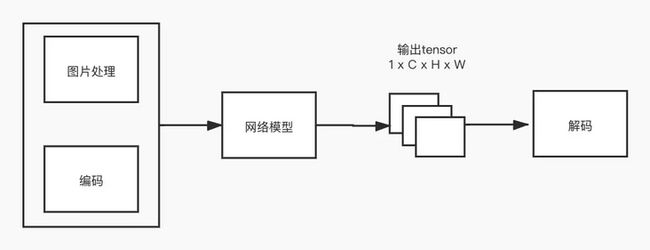
将关键点检测算法按照不同模块进行拆分,可以分成以下几个部分,每个部分都有相关的方法可以进行优化:
- 图片处理:包括数据光学增强,变换,resize,crop等操作,扩充图片的多样性;
- 编码:指的是在训练中,如何将坐标转换成所需要的label,用于监督模型的输出;
- 网络模型:指的是网络结构,可以有backbone/FPN/detection head等部分组成;
- 解码:指的是如何将模型推理的结果转换成所需要的坐标形式,如笛卡尔坐标系下的坐标。
Related Works
关键点检测中主要有两条技术方案:
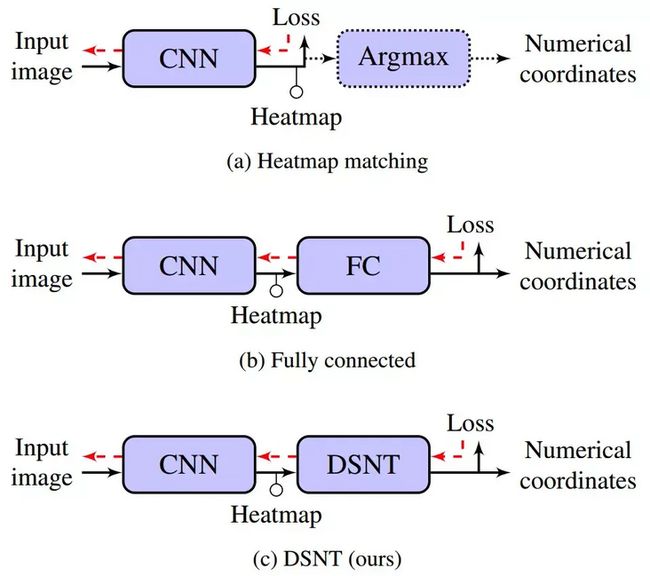
- 类似人脸检测,模型输出的结果tensor通过fc层,直接得到一维的向量,通常是归一化后关键点坐标值;
- 类似人体姿态估计,模型输出的结果tensor通过argmax等方式,获取heatmap中相应大的坐标,最后将此坐标恢复至原图坐标。
近年来,基于heatmap来进行关键点检测的方案居多,其主要原因是基于heatmap的效果要好于使用全连接层进行回归的方案。所以,我们采用的方案也是基于heatmap的,下面是近几年的一些相关论文工作。
DSNT
[1] Nibali A , He Z , Morgan S , et al. Numerical Coordinate Regression with Convolutional Neural Networks[J]. 2018.
思路
目前,在模型输出的heatmap到数值坐标的转换中,有两种方式:
- 通过对heatmap中取argmax,得到相应最大的点,以此来转换成数值坐标。此种方式具有较好的空间泛化性,但是由于在训练中argmax是不可导的,通常使用heatmap来逼近编码的高斯热例图,这会导致损失函数与最终评价指标的不一致。其次,在推理阶段,只使用到最大响应的坐标点来计算数值坐标,而在训练阶段,所有坐标点都对损失有贡献。第三,通过heatmap转换成数值坐标,是会存在理论误差下限的;
- 通过在heatmap后接fc层,转换成数值坐标。此种方法让梯度从数值坐标回传到input中,但是结果严重依赖与数据分布(例如在训练集中,一个物体一直出现在坐标;而在测试集中,这个物体出现在右边,这样就会导致预测错误)。其次,通过fc转换,丢失了heatmap的空间信息。
针对上述的两种方案,作者兼容了这两种方案的优点(端到端优化和保持空间泛化性),提出一种可微分的方式来得到数值坐标。
具体步骤
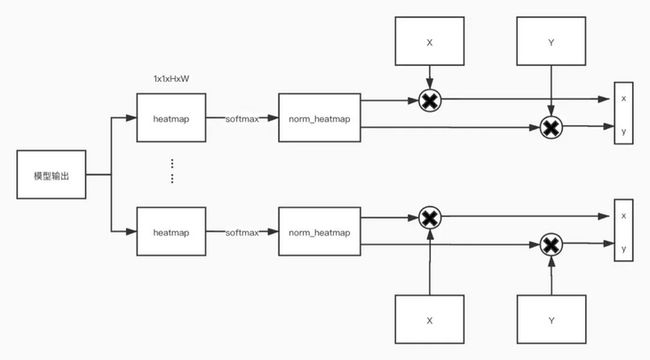
- 模型的输出1KH*W个heatmaps,其中K表示关键点的数量;
- 将每个通道的heatmap归一化,让其值都为非负且和为1,从而得到 norm_heatmap 。这么做的目的是,使用归一化后的heatmap保证了预测的坐标位于heatmap的空间范围之内。同时, norm_heatmap 也可以理解成二维离散概率密度函数;
- 生成 X 和 Y 矩阵,\( X_{(i,j)} = \frac{2j-(w+1)}{w} \), \( Y_{(i,j)} = \frac{2i-(h+1)}{h} \),分别表示x轴的索引和y轴的索引。可以理解成将图片的左上角缩放到 (-1,-1) 和右下角缩放到 (1,1) ;
- 将X 和 Y 矩阵分别与 norm_heatmap 点乘,从而得到最终的数值坐标。这么做的原因是, norm_heatmap 表示概率密度函数, X 矩阵表示索引,两者点成表示预测x的均值。通过均值来表示最终的预测的坐标,这样的好处是,a)可微分;b)理论误差下限小。

损失函数loss
dsnt模块的损失函数由Euclidean loss 和JS正则约束组成。前者用于回归坐标,后者用于约束生成的热力图更加接近高斯分布。
$$ L_{euc}(u,p) = ||p-u||_2 $$
$$ L_D(Z,p) =JS(p(c)||N(p,I))) $$
优点
- 整套模型是端到端训练的,损失函数与测试指标能对应;
- 理论误差下限很小;
- 引入 X 矩阵和 Y 矩阵,可以理解成引入先验,让模型的学习难度降低;
- 低分辨率的效果依然不错。
缺点
在实验中,发现当关键点位于图片边缘时,预测结果不好。
DARK
[1] Zhang F , Zhu X , Dai H , et al. Distribution-Aware Coordinate Representation for Human Pose Estimation[J]. 2019.
思路
作者发现将 heatmaps 解码结果,对生成最终数值坐标存在较大影响。因此研究了标准的坐标解码方式的不足,提出一种分布已知的解码方式和编码方式,来提高模型的最终效果。
标准的坐标解码过程是,获得模型的 heatmaps 后,通过argmax找到最大响应点 m 和第二大响应点 s ,以此来计算最终的响应点 p :
$$ p=m+0.25\frac{s-m}{\left \| s-m \right \|_2} $$
这个公式意味着最大响应点向第二大响应点偏移0.25个像素,这么做的目的是补偿量化误差。然后把响应点映射回原图:
$$ \hat{p} = \lambda p $$
这也说明, heatmap 中最大响应点并不是与原图的关键点精确对应,只是大概位置。
基于上面的痛点,作者基于分布已知的前提(高斯分布),提出新的解码方式,解决如何从 heatmap 中得到精确的位置,最小化量化误差。同时,提出了配套的编码方式
具体步骤
解码
假设输出的 heatmap 符合高斯分布,那么 heatmap 就可以用下面函数表示
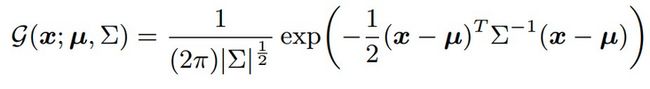
其中\( \mu \)表示关键点映射到 heatmap 的位置。我们需要求\( \mu \)的位置,因此将函数g转换成最大似然函数
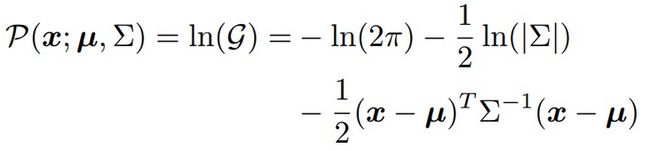
对\( P(\mu ) \)进行泰勒展开
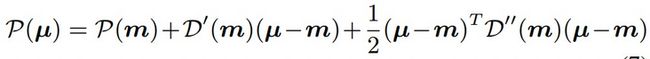
其中,m表示在热力图中最大响应的位置。而\( \mu \)在热力图对应的是极点,存在以下性质
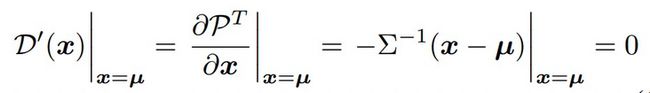
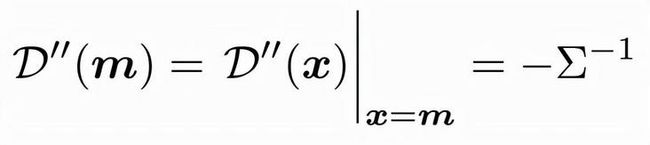
结合上述公式,可以得到
因此,为了得到 heatmap 中\( \mu \)的位置,可以通过 heatmap 的一阶导数与二阶导数求得。这步的作用是通过数学的方法来说明该移动距离。
前面提及了假设输出的 heatmap 符合高斯分布,实际情况是不符合的,实际可能是多峰,因此需要对 heatmap 进行调制,让其尽量满足这个前提。具体做法是用高斯核函数来平滑 heatmap ,同时为了保证幅值一致,要进行归一化。
$$ {h}'=K\circledast h $$
$$ {h}'=\frac{{h}'-min({h}')}{max({h}')-min({h}')}*max(h) $$
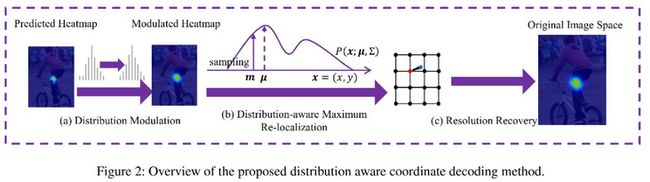
综上所述,步骤是:
- 对 heatmap 使用高斯核来调制,并且缩放;
- 求一阶导数和二阶导数,来得到\( \mu \);
- 将\( \mu \)映射回原图。
编码
编码指的是将关键点映射到 heatmap 上,并且生成高斯分布。
之前工作的做法是现对坐标进行下采样,然后将点进行量化(floor,ceil,round),最后使用量化后的坐标生成高斯函数。
因为量化是不可导的,存在量化误差,因此,作者提出不进行量化,使用float来生成高斯函数,这样就能生成无偏 heatmap 。
UDP
[1] Huang J , Zhu Z , Guo F , et al. The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation[J]. 2019.
思路
作者从数据处理和坐标表示下手,以此来提高性能。作者发现,目前的数据处理方式是存在偏差的,特别是flip时,会与原数据不对齐;其次坐标表征也存在统计误差。这两个问题共同导致结果存在偏差。因此提出了一种数据处理方式unbiased data processing,解决图像转换和坐标转换带来的误差。
具体步骤
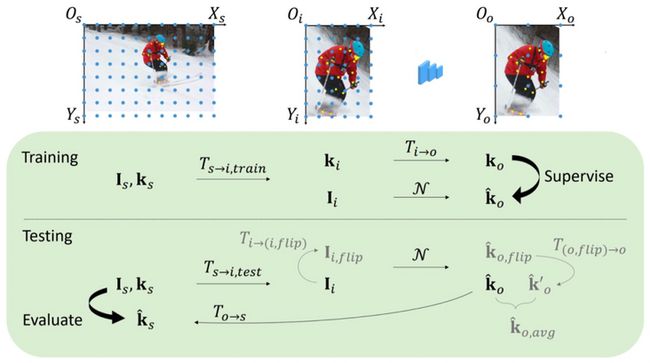
Unbiased Coordinate System Transformation
在测试中,通常使用翻转后的\( {k}'_{o,flip} \)与原始的\( {k}'_o \)进行叠加,来得到最终的预测结果。但是\( {k}'_o \)与\( {\hat{k}}'_o \)并不一致,存在偏差。可以看到翻转后的 heatmap 不与原来的 heatmap 对齐,会产生误差,与分辨率有关。

因此作者建议使用 unit length 来代替图片长度:\( w=w^p-1 \)。这样翻转后的 heatmap 就对齐了。

Unbiased Keypoint Format Transformation
无偏的关键点转换方式应该是可逆的,即\( k=Decoding(Enoding(k)) \)。因此,作者提出了两种方式:
- Combined classification and regression format
借鉴了目标检测中anchor的方式,假设需要预测的关键点\( k=(m,n) \),则将其转换成如下。其中C表示关键点的位置范围,X和Y表示需要预测的offset。最终解码就是在热力图C上取到argmax,然后对X与Y的热力图上拿到对应位置的offset,最后进行相加得到数值坐标。
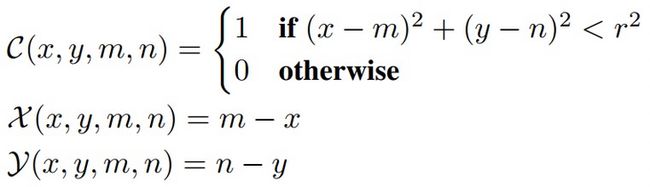
- Classification format
与DARK方式一致,即使用泰勒展开来逼近真实位置。
AID
[1] Huang J , Zhu Z , Huang G , et al. AID: Pushing the Performance Boundary of Human Pose Estimation with Information Dropping Augmentation[J]. 2020.
贡献点

对于关键点检测,外观信息与约束信息同样重要。而以往的工作通常是过拟合外观信息,而忽略了约束信息。因此,本文希望通过information drop,可理解成掩膜,来强调约束信息。约束信息有利于在该关键点被遮挡时,预测出其准确位置。
而以往工作没有使用到information drop的原因是,使用该数据增强手段后指标下降。作者就通过实验,发现information drop是有助于提高模型精度的,但需要修改响应的训练策略:
- 加倍训练次数;
- 先使用没有mask的来训练,得到一个比较好的模型后,再把mask手段加入继续训练。
RSN
[1] Cai Y , Wang Z , Luo Z , et al. Learning Delicate Local Representations for Multi-Person Pose Estimation[J]. 2020.
贡献点
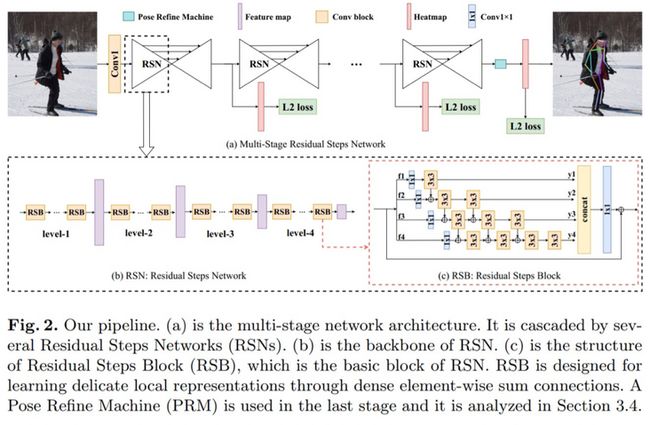
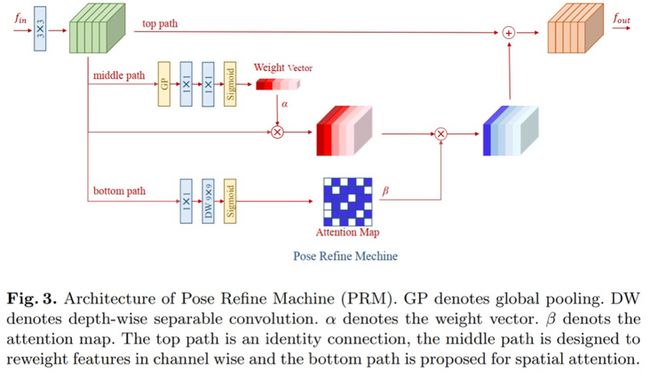
本文是2019年coco关键点检测冠军的方案。其本文的主要思想是,最大程度聚合具有相同空间尺寸的特征,以此来获得丰富的局部信息,局部信息有利于产生更加准确的位置。因此提出了RSN网络,如下图一所示。从图来看,即融合不同感受野特征。RSN的输出包含了low-level准确的空间信息与high-level语义信息,空间信息有助于定位,语义信息有助于分类。但是这两类信息给最终预测带来的影响权重是不一致的,需要使用到PRM模块来平衡,RPM模块本质就是一个通道注意力和空间注意力模块。
Lite-HRNet
[1] Yu C , Xiao B , Gao C , et al. Lite-HRNet: A Lightweight High-Resolution Network[J]. 2021.
贡献点
本文出了一个高效的高分辨率网络,是HRNet的轻量化版本,通过将ShuffleNet中的shuffle block引入到HRNet中。同时发现shuffleNet中大量使用了pointwise convolution(11卷积),是计算瓶颈,因此引入contional channel weight来取代shuffle block中的11卷积。网络的整体结构如下图所示。在模型中一致保留高分辨率特征,并不断融合high-level特征。
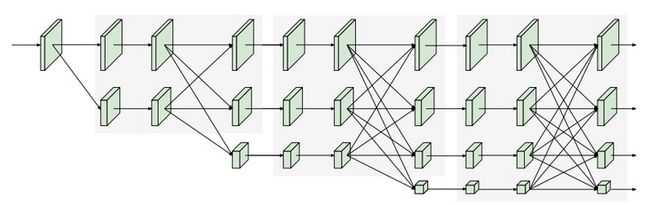
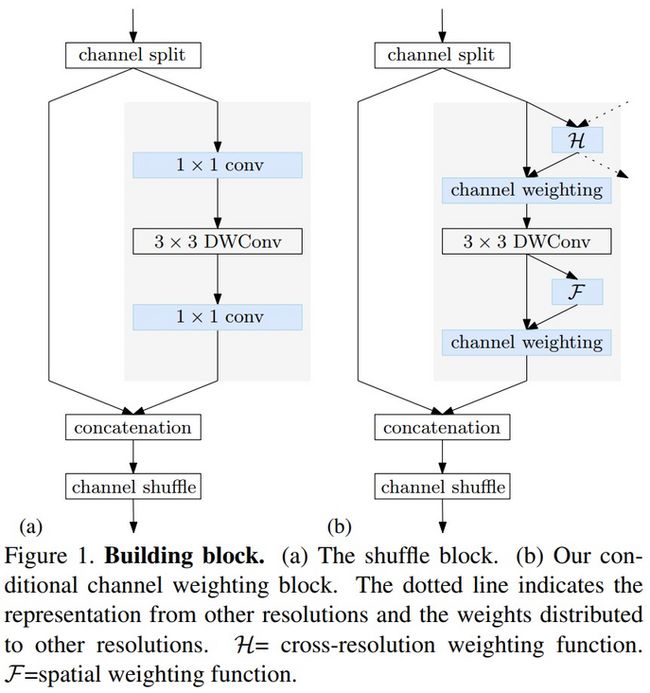
在前面提及到的contional channel weight如下所示。左边是ShuffleNet中的shuffle block,右图是contional channel weight。可以看到,采用新模块来取代了1*1的卷积,实现跨stage信息交流与局部信息交流。其具体做法包含了Cross-resolution weight computation和Spatial weight computation。这两个模块的本质是注意力机制。
实验优化结果
模型结构
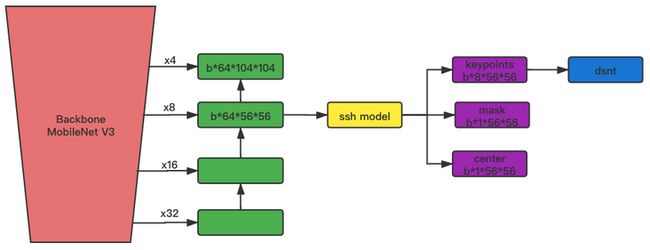
本次模型借鉴了CenterNet/RetiaFace/DBFace中的相关工作。本次的使用了dsnt的方案。主要原因是:需要运行在端上,实时性是首要考虑因素。dsnt在低分辨率的优势明显。
MobileNet v3使用small版本,FPN中使用 Nearest Upsample + conv + bn + Relu 来进行上采样。在训练时使用了 keypoints , mask 和 center 分支;而预测时,只使用到了 keypoints 分支。
优化策略
在本次实验中,使用到了以下几种优化策略:
- 使用 mask 与 center 分支来辅助学习。其中mask表示文档的掩膜,center表示文档的中心点;
- 使用deep Supervise。使用4倍下采样特征图与8倍下采样特征图来进行训练,使用相同的loss函数来监督这两层;
- dsnt中对边缘点的效果不佳,因此,对图片进行padding,让点不再位于图片边缘;
- 数据增强策略,除了常规的光学扰动增强外,还对图片进行random crop、random erase和random flip等操作;
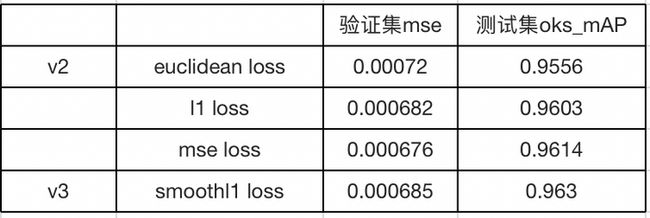
- 进行loss函数尝试工作,对于关键点分支的loss,尝试过 euclidean loss , l1 loss , l2 loss 和 smoothl1 loss ,最终 smoothl1 loss 的效果最佳。
评价指标
- MSE
用于在训练中评价验证集的均方误差。
$$ mse = \frac{\sum |d_i - \hat{d_i}|_2^2}{N} $$
- oks-mAP
oks用于评估预测与真实关键点之间的相似度,mAP的评估方式类似coco[0.5:0.05:0.95]的评价方式,这里取[0.99:0.001:0.999]。其中,oks进行一定变换,\( d_{p,i} \)表示点的欧式距离,$S_p$表示该四边形的面积。
$$ oks_{p,i} =e^{-\frac{d_{p,i}^2}{2S_p}} $$
- 耗时
耗时指的是在红米8上,用MNN推理框架跑模型的平均时间。
实验结果
先构建一个baseline,baseline的模型为 moblieNet v3 + fpn + ssh module + keypoints 分支 + dsnt ,其中,都没有使用上述优化策略,使用4倍下采样特征图作为输出。
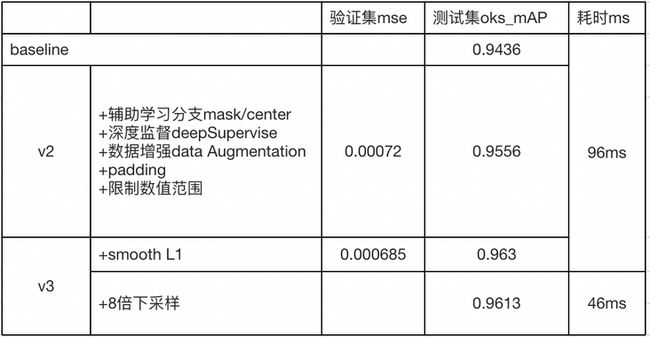
在v2版本中替换不同的loss函数。
此外,还尝试过其他无效的tricks:
- 辅助任务有利于提高模型的指标,因此还加入了edge的分支来辅助学习。实验下来,加入该分支反而损害模型的指标。可能原因是edge是利用gt关键点来生成的,可能某些edge并不是对应文档真正的边缘;
- 现阶段是预测文档的4个角,因此在增加4个点来进行预测,分别是4条边的中心点,所以模型一共预测8个关键点。实验结果显示,指标也下降了。
Demo 演示
总结
综上所述,在端上的文档关键点检测领域中,目前尝试下来,是基于heatmap+dsnt的方案较优,oks-mAP的指标有提升空间。但是,对比使用fc层进行回归坐标的方式,基于heatmap的方案中存在一个不足是:无法根据文档的约束信息,来预测图片外的关键点坐标。此方案的不足,会导致文档内容的缺失,摆正效果不佳的情况。因此,后续需要弥补此不足。

如何高效开发端智能算法?MNN 工作台 Python 调试详解
关注我们,每周 3 篇移动技术实践&干货给你思考!