【YOLOV5-5.x 源码解读】plots.py
目录
- 前言
- 0、导入需要的包和基本配置
- 1、Colors
- 2、plot_one_box、plot_one_box_PIL
-
- 2.1、plot_one_box
- 2.2、plot_one_box_PIL(没用到)
- 3、plot_wh_methods(没用到)
- 4、output_to_target、plot_images
-
- 4.1、output_to_target
- 4.1、plot_images
- 5、plot_lr_scheduler
- 6、hist2d、plot_test_txt、plot_targets_txt
-
- 6.1、hist2d
- 6.2、plot_test_txt
- 6.3、plot_targets_txt(没用到)
- 7、plot_labels
- 8、plot_evolution
- 9、plot_results、plot_results_overlay、butter_lowpass_filtfilt
-
- 9.1、plot_results
- 9.2、plot_results_overlay
- 9.3、butter_lowpass_filtfilt
- 10、feature_visualization
- 11、plot_study_txt(没用到)、profile_idetection(没用到)
- 总结
前言
源码: YOLOv5源码.
导航: 【YOLOV5-5.x 源码讲解】整体项目文件导航.
注释版全部项目文件已上传至GitHub: yolov5-5.x-annotations.
\qquad 这个文件都是一些画图函数,是一个工具类。代码本身逻辑并不难,主要是一些包的函数可能大家没见过。这里我总结了一些画图包的一些常见的画图函数: 【Opencv、ImageDraw、Matplotlib、Pandas、Seaborn】一些常见的画图函数。如果在下面代码中碰到不太熟的画图函数,可以查一下我的笔记或者自己百度一下。
0、导入需要的包和基本配置
import glob # 仅支持部分通配符的文件搜索模块
import math # 数学公式模块
import os # 与操作系统进行交互的模块
from copy import copy # 提供通用的浅层和深层copy操作
from pathlib import Path # Path将str转换为Path对象 使字符串路径易于操作的模块
import cv2 # opencv库
import matplotlib # matplotlib模块
import matplotlib.pyplot as plt # matplotlib画图模块
import numpy as np # numpy矩阵处理函数库
import pandas as pd # pandas矩阵操作模块
import seaborn as sn # 基于matplotlib的图形可视化python包 能够做出各种有吸引力的统计图表
import torch # pytorch框架
import yaml # yaml配置文件读写模块
from PIL import Image, ImageDraw, ImageFont # 图片操作模块
from torchvision import transforms # 包含很多种对图像数据进行变换的函数
from utils.general import increment_path, xywh2xyxy, xyxy2xywh
from utils.metrics import fitness
# 设置一些基本的配置 Settings
matplotlib.rc('font', **{
'size': 11}) # 自定义matplotlib图上字体font大小size=11
# 在PyCharm 页面中控制绘图显示与否
# 如果这句话放在import matplotlib.pyplot as plt之前就算加上plt.show()也不会再屏幕上绘图 放在之后其实没什么用
matplotlib.use('Agg') # for writing to files only
1、Colors
\qquad 这是一个颜色类,用于选择相应的颜色,比如画框线的颜色,字体颜色等等。
Colors类代码:
class Colors:
# Ultralytics color palette https://ultralytics.com/
def __init__(self):
# hex = matplotlib.colors.TABLEAU_COLORS.values()
hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
'2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
# 将hex列表中所有hex格式(十六进制)的颜色转换rgb格式的颜色
self.palette = [self.hex2rgb('#' + c) for c in hex]
# 颜色个数
self.n = len(self.palette)
def __call__(self, i, bgr=False):
# 根据输入的index 选择对应的rgb颜色
c = self.palette[int(i) % self.n]
# 返回选择的颜色 默认是rgb
return (c[2], c[1], c[0]) if bgr else c
@staticmethod
def hex2rgb(h): # rgb order (PIL)
# hex -> rgb
return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
colors = Colors() # 初始化Colors对象 下面调用colors的时候会调用__call__函数
使用起来也是比较简单只要直接输入颜色序号即可:

2、plot_one_box、plot_one_box_PIL
\qquad plot_one_box 和 plot_one_box_PIL 这两个函数都是用于在原图im上画一个bounding box,区别在于前者使用的是opencv画框,后者使用PIL画框。这两个函数的功能其实是重复的,其实我们用的比较多的是plot_one_box函数,plot_one_box_PIL几乎没用,了解下即可。
2.1、plot_one_box
\qquad 这个函数通常用在检测nms后(detect.py中)将最终的预测bounding box在原图中画出来,不过这个函数依次只能画一个框框。
plot_one_box函数代码:
def plot_one_box(x, im, color=(128, 128, 128), label=None, line_thickness=3):
"""一般会用在detect.py中在nms之后变量每一个预测框,再将每个预测框画在原图上
使用opencv在原图im上画一个bounding box
:params x: 预测得到的bounding box [x1 y1 x2 y2]
:params im: 原图 要将bounding box画在这个图上 array
:params color: bounding box线的颜色
:params labels: 标签上的框框信息 类别 + score
:params line_thickness: bounding box的线宽
"""
# check im内存是否连续
assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to plot_on_box() input image.'
# tl = 框框的线宽 要么等于line_thickness要么根据原图im长宽信息自适应生成一个
tl = line_thickness or round(0.002 * (im.shape[0] + im.shape[1]) / 2) + 1 # line/font thickness
# c1 = (x1, y1) = 矩形框的左上角 c2 = (x2, y2) = 矩形框的右下角
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
# cv2.rectangle: 在im上画出框框 c1: start_point(x1, y1) c2: end_point(x2, y2)
# 注意: 这里的c1+c2可以是左上角+右下角 也可以是左下角+右上角都可以
cv2.rectangle(im, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
# 如果label不为空还要在框框上面显示标签label + score
if label:
tf = max(tl - 1, 1) # label字体的线宽 font thickness
# cv2.getTextSize: 根据输入的label信息计算文本字符串的宽度和高度
# 0: 文字字体类型 fontScale: 字体缩放系数 thickness: 字体笔画线宽
# 返回retval 字体的宽高 (width, height), baseLine 相对于最底端文本的 y 坐标
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
# 同上面一样是个画框的步骤 但是线宽thickness=-1表示整个矩形都填充color颜色
cv2.rectangle(im, c1, c2, color, -1, cv2.LINE_AA) # filled
# cv2.putText: 在图片上写文本 这里是在上面这个矩形框里写label + score文本
# (c1[0], c1[1] - 2)文本左下角坐标 0: 文字样式 fontScale: 字体缩放系数
# [225, 255, 255]: 文字颜色 thickness: tf字体笔画线宽 lineType: 线样式
cv2.putText(im, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
这个函数一般会用在detect.py中在nms之后变量每一个预测框,再将每个预测框画在原图上如:
效果如下所示:

2.2、plot_one_box_PIL(没用到)
\qquad 这个函数是用PIL在原图中画一个框,作用和plot_one_box一样,而且我们一般都是用plot_one_box而不用这个函数,所以了解下即可。
plot_one_box_PIL函数代码:
def plot_one_box_PIL(box, im, color=(128, 128, 128), label=None, line_thickness=None):
"""
使用PIL在原图im上画一个bounding box
:params box: 预测得到的bounding box [x1 y1 x2 y2]
:params im: 原图 要将bounding box画在这个图上 array
:params color: bounding box线的颜色
:params label: 标签上的bounding box框框信息 类别 + score
:params line_thickness: bounding box的线宽
"""
# 将原图array格式->Image格式
im = Image.fromarray(im)
# (初始化)创建一个可以在给定图像(im)上绘图的对象, 在之后调用draw.函数的时候不需要传入im参数,它是直接针对im上进行绘画的
draw = ImageDraw.Draw(im)
# 设置绘制bounding box的线宽
line_thickness = line_thickness or max(int(min(im.size) / 200), 2)
# 在im图像上绘制bounding box
# xy: box [x1 y1 x2 y2] 左上角 + 右下角 width: 线宽 outline: 矩形外框颜色color fill: 将整个矩形填充颜色color
# outline和fill一般根据需求二选一
draw.rectangle(box, width=line_thickness, outline=color) # plot
# 如果label不为空还要在框框上面显示标签label + score
if label:
# 加载一个TrueType或者OpenType字体文件("Arial.ttf"), 并且创建一个字体对象font, font写出的字体大小size=12
font = ImageFont.truetype("Arial.ttf", size=max(round(max(im.size) / 40), 12))
# 返回给定文本label的宽度txt_width和高度txt_height
txt_width, txt_height = font.getsize(label)
# 在im图像上绘制矩形框 整个框框填充颜色color(用来存放label信息) [x1 y1 x2 y2] 左上角 + 右下角
draw.rectangle([box[0], box[1] - txt_height + 4, box[0] + txt_width, box[1]], fill=color)
# 在上面这个矩形中写入text信息(label) x1y1 左上角
draw.text((box[0], box[1] - txt_height + 1), label, fill=(255, 255, 255), font=font)
# 再返回array类型的im(绘好bounding box和label的)
return np.asarray(im)
3、plot_wh_methods(没用到)
\qquad 这个函数主要是用来比较 y a = e x y_a = e^x ya=ex 、 y b = ( 2 ∗ s i g m o i d ( x ) ) 2 y_b = (2 * sigmoid(x))^2 yb=(2∗sigmoid(x))2 、 y c = ( 2 ∗ s i g m o i d ( x ) ) 1.6 y_c = (2 * sigmoid(x))^{1.6} yc=(2∗sigmoid(x))1.6 这三个函数图形的。其中 y a y_a ya 是普通的yolo method, y b y_b yb 和 y c y_c yc是作者提出的powe method方法。在 https://github.com/ultralytics/yolov3/issues/168.中,作者由讨论过这个issue。作者在实验中发现使用原来的yolo method损失计算有时候会突然迅速走向无限None值, 而power method方式计算wh损失下降会比较平稳。最后实验证明 y b y_b yb 是最好的wh损失计算方式, yolov5的wh损失计算代码用的就是 y b y_b yb 计算方式 如:
yolo.py:

loss.py:

plot_wh_methods函数代码:
def plot_wh_methods():
"""没用到
比较ya=e^x、yb=(2 * sigmoid(x))^2 以及 yc=(2 * sigmoid(x))^1.6 三个图形
wh损失计算的方式ya、yb、yc三种 ya: yolo method yb/yc: power method
实验发现使用原来的yolo method损失计算有时候会突然迅速走向无限None值, 而power method方式计算wh损失下降会比较平稳
最后实验证明yb是最好的wh损失计算方式, yolov5的wh损失计算代码用的就是yb计算方式
Compares the two methods for width-height anchor multiplication
https://github.com/ultralytics/yolov3/issues/168
"""
x = np.arange(-4.0, 4.0, .1) # (-4.0, 4.0) 每隔0.1取一个值
ya = np.exp(x) # ya = e^x yolo method
yb = torch.sigmoid(torch.from_numpy(x)).numpy() * 2 # yb = 2 * sigmoid(x)
fig = plt.figure(figsize=(6, 3), tight_layout=True) # 创建自定义图像 初始化画布
plt.plot(x, ya, '.-', label='YOLOv3') # 绘制折线图 可以任意加几条线
plt.plot(x, yb ** 2, '.-', label='YOLOv5 ^2')
plt.plot(x, yb ** 1.6, '.-', label='YOLOv5 ^1.6')
plt.xlim(left=-4, right=4) # 设置x轴、y轴范围
plt.ylim(bottom=0, top=6)
plt.xlabel('input') # 设置x轴、y轴标签
plt.ylabel('output')
plt.grid() # 生成网格
plt.legend() # 加上图例 如果是折线图,需要在plt.plot中加入label参数(图例名)
fig.savefig('comparison.png', dpi=200) # plt绘完图, fig.savefig()保存图片
\qquad 其实这个函数倒不是特别重要,只是可视化一下这三个函数,看看他们的区别,在代码中也没调用过这个函数。但是了解这种新型 wh 损失计算的方式(Power Method)还是很有必要的。
4、output_to_target、plot_images
\qquad 这两个函数其实也是对检测到的目标格式进行处理(output_to_target)然后再将其画框显示在原图上(plot_images)。不过这两个函数是用在test.py中的,针对的也不再是一张图片一个框,而是整个batch中的所有框。而且plot_images会将整个batch的图片都画在一张大图mosaic中,画不下的就删除。这些都是plot_images函数和plot_one_box的区别。
4.1、output_to_target
\qquad 这个函数是用于将经过nms后的output [num_obj,x1y1x2y2+conf+cls] -> [num_obj,batch_id+class+xywh+conf]。并不涉及画图操作,而是转化predict的格式,通常放在画图操作plot_images之前。
output_to_target函数代码:
def output_to_target(output):
"""用在test.py中进行绘制前3个batch的预测框predictions 因为只有predictions需要修改格式 target是不需要修改格式的
将经过nms后的output [num_obj,x1y1x2y2+conf+cls] -> [num_obj, batch_id+class+x+y+w+h+conf] 转变格式
以便在plot_images中进行绘图 + 显示label
Convert model output to target format [batch_id, class_id, x, y, w, h, conf]
:params output: list{tensor(8)}分别对应着当前batch的8(batch_size)张图片做完nms后的结果
list中每个tensor[n, 6] n表示当前图片检测到的目标个数 6=x1y1x2y2+conf+cls
:return np.array(targets): [num_targets, batch_id+class+xywh+conf] 其中num_targets为当前batch中所有检测到目标框的个数
"""
targets = []
for i, o in enumerate(output): # 对每张图片分别做处理
for *box, conf, cls in o.cpu().numpy(): # 对每张图片的每个检测到的目标框进行convert格式
targets.append([i, cls, *list(*xyxy2xywh(np.array(box)[None])), conf])
return np.array(targets)
4.1、plot_images
\qquad 这个函数是用来绘制一个batch的所有图片的框框(真实框或预测框)。使用在test.py中,且在output_to_target函数之后。而且这个函数是将一个batch的图片都放在一个大图mosaic上面,放不下删除。
plot_images函数代码:
def plot_images(images, targets, paths=None, fname='images.jpg', names=None, max_size=640, max_subplots=16):
"""用在test.py中进行绘制前3个batch的ground truth和预测框predictions(两个图) 一起保存 或者train.py中
将整个batch的labels都画在这个batch的images上
Plot image grid with labels
:params images: 当前batch的所有图片 Tensor [batch_size, 3, h, w] 且图片都是归一化后的
:params targets: 直接来自target: Tensor[num_target, img_index+class+xywh] [num_target, 6]
来自output_to_target: Tensor[num_pred, batch_id+class+xywh+conf] [num_pred, 7]
:params paths: tuple 当前batch中所有图片的地址
如: '..\\datasets\\coco128\\images\\train2017\\000000000315.jpg'
:params fname: 最终保存的文件路径 + 名字 runs\train\exp8\train_batch2.jpg
:params names: 传入的类名 从class index可以相应的key值 但是默认是None 只显示class index不显示类名
:params max_size: 图片的最大尺寸640 如果images有图片的大小(w/h)大于640则需要resize 如果都是小于640则不需要resize
:params max_subplots: 最大子图个数 16
:params mosaic: 一张大图 最多可以显示max_subplots张图片 将总多的图片(包括各自的label框框)一起贴在一起显示
mosaic每张图片的左上方还会显示当前图片的名字 最好以fname为名保存起来
"""
if isinstance(images, torch.Tensor):
images = images.cpu().float().numpy() # tensor -> numpy array
if isinstance(targets, torch.Tensor):
targets = targets.cpu().numpy()
# 反归一化 将归一化后的图片还原 un-normalise
if np.max(images[0]) <= 1:
images *= 255
# 设置一些基础变量
tl = 3 # 设置线宽 line thickness 3
tf = max(tl - 1, 1) # 设置字体笔画线宽 font thickness 2
bs, _, h, w = images.shape # batch size 4, channel 3, height 512, width 512
bs = min(bs, max_subplots) # 子图总数 正方形 limit plot images 4
ns = np.ceil(bs ** 0.5) # ns=每行/每列最大子图个数 子图总数=ns*ns ceil向上取整 2
# Check if we should resize
# 如果images有图片的大小(w/h)大于640则需要resize 如果都是小于640则不需要resize
scale_factor = max_size / max(h, w) # 1.25
if scale_factor < 1:
# 如果w/h有任何一条边超过640, 就要将较长边缩放到640, 另外一条边相应也缩放
h = math.ceil(scale_factor * h) # 512
w = math.ceil(scale_factor * w) # 512
# np.full 返回一个指定形状、类型和数值的数组
# shape: (int(ns * h), int(ns * w), 3) (1024, 1024, 3) 填充的值: 255 dtype 填充类型: np.uint8
mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
# 对batch内每张图片
for i, img in enumerate(images): # img (3, 512, 512)
# 如果图片要超过max_subplots我们就不管了
if i == max_subplots: # if last batch has fewer images than we expect
break
# (block_x, block_y) 相当于是左上角的左边
block_x = int(w * (i // ns)) # // 取整 0 0 512 512 ns=2
block_y = int(h * (i % ns)) # % 取余 0 512 0 512
img = img.transpose(1, 2, 0) # (512, 512, 3) h w c
if scale_factor < 1: # 如果scale_factor < 1说明h/w超过max_size 需要resize回来
img = cv2.resize(img, (w, h))
# 将这个batch的图片一张张的贴到mosaic相应的位置上 hwc 这里最好自己画个图理解下
# 第一张图mosaic[0:512, 0:512, :] 第二张图mosaic[512:1024, 0:512, :]
# 第三张图mosaic[0:512, 512:1024, :] 第四张图mosaic[512:1024, 512:1024, :]
mosaic[block_y:block_y + h, block_x:block_x + w, :] = img
if len(targets) > 0:
# 求出属于这张img的target
image_targets = targets[targets[:, 0] == i]
# 将这张图片的所有target的xywh -> xyxy
boxes = xywh2xyxy(image_targets[:, 2:6]).T
# 得到这张图片所有target的类别classes
classes = image_targets[:, 1].astype('int')
# 如果image_targets.shape[1] == 6则说明没有置信度信息(此时target实际上是真实框)
# 如果长度为7则第7个信息就是置信度信息(此时target为预测框信息)
labels = image_targets.shape[1] == 6 # labels if no conf column
# 得到当前这张图的所有target的置信度信息(pred) 如果没有就为空(真实label)
# check for confidence presence (label vs pred)
conf = None if labels else image_targets[:, 6]
if boxes.shape[1]: # boxes.shape[1]不为空说明这张图有target目标
if boxes.max() <= 1.01: # if normalized with tolerance 0.01
# 因为图片是反归一化的 所以这里boxes也反归一化
boxes[[0, 2]] *= w # scale to pixels
boxes[[1, 3]] *= h
elif scale_factor < 1:
# 如果scale_factor < 1 说明resize过, 那么boxes也要相应变化
# absolute coords need scale if image scales
boxes *= scale_factor
# 上面得到的boxes信息是相对img这张图片的标签信息 因为我们最终是要将img贴到mosaic上 所以还要变换label->mosaic
boxes[[0, 2]] += block_x
boxes[[1, 3]] += block_y
# 将当前的图片img的所有标签boxes画到mosaic上
for j, box in enumerate(boxes.T):
# 遍历每个box
cls = int(classes[j]) # 得到这个box的class index
color = colors(cls) # 得到这个box框线的颜色
cls = names[cls] if names else cls # 如果传入类名就显示类名 如果没传入类名就显示class index
# 如果labels不为空说明是在显示真实target 不需要conf置信度 直接显示label即可
# 如果conf[j] > 0.25 首先说明是在显示pred 且这个box的conf必须大于0.25 相当于又是一轮nms筛选 显示label + conf
if labels or conf[j] > 0.25: # 0.25 conf thresh
label = '%s' % cls if labels else '%s %.1f' % (cls, conf[j]) # 框框上面的显示信息
plot_one_box(box, mosaic, label=label, color=color, line_thickness=tl) # 一个个的画框
# 在mosaic每张图片相对位置的左上角写上每张图片的文件名 如000000000315.jpg
if paths:
# paths[i]: '..\\datasets\\coco128\\images\\train2017\\000000000315.jpg' Path: str -> Wins地址
# .name: str'000000000315.jpg' [:40]取前40个字符 最终还是等于str'000000000315.jpg'
label = Path(paths[i]).name[:40] # trim to 40 char
# 返回文本 label 的宽高 (width, height)
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
# 在mosaic上写文本信息
# 要绘制的图像 + 要写上前的文本信息 + 文本左下角坐标 + 要使用的字体 + 字体缩放系数 + 字体的颜色 + 字体的线宽 + 矩形边框的线型
cv2.putText(mosaic, label, (block_x + 5, block_y + t_size[1] + 5), 0,
tl / 3, [220, 220, 220], thickness=tf, lineType=cv2.LINE_AA)
# mosaic内每张图片与图片之间弄一个边界框隔开 好看点 其实做法特简单 就是将每个img在mosaic中画个框即可
cv2.rectangle(mosaic, (block_x, block_y), (block_x + w, block_y + h), (255, 255, 255), thickness=3)
# 最后一步 check是否需要将mosaic图片保存起来
if fname: # 文件名不为空的话 fname = runs\train\exp8\train_batch2.jpg
# 限制mosaic图片尺寸
r = min(1280. / max(h, w) / ns, 1.0) # ratio to limit image size
mosaic = cv2.resize(mosaic, (int(ns * w * r), int(ns * h * r)), interpolation=cv2.INTER_AREA)
# cv2.imwrite(fname, cv2.cvtColor(mosaic, cv2.COLOR_BGR2RGB)) # cv2 save 最好BGR -> RGB再保存
Image.fromarray(mosaic).save(fname) # PIL save 必须要numpy array -> tensor格式 才能保存
return mosaic
这两个函数都是用在test.py函数中的:

用在train.py:

执行效果test.py(target):
 执行效果test.py(predict):
执行效果test.py(predict):

5、plot_lr_scheduler
\qquad 这个函数是用来画出在训练过程中每个epoch的学习率变化情况。
plot_lr_scheduler函数代码:
def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
"""用在train.py中学习率设置后可视化一下
Plot LR simulating training for full epochs
:params optimizer: 优化器
:params scheduler: 策略调整器
:params epochs: x
:params save_dir: lr图片 保存地址
"""
optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
y = [] # 存放每个epoch的学习率
# 从optimizer中取学习率 一个epoch取一个 共取epochs个 每取一次需要使用scheduler.step更新下一个epoch的学习率
for _ in range(epochs):
scheduler.step() # 更新下一个epoch的学习率
# ptimizer.param_groups[0]['lr']: 取下一个epoch的学习率lr
y.append(optimizer.param_groups[0]['lr'])
plt.plot(y, '.-', label='LR') # 没有传入x 默认会传入 0..epochs-1
plt.xlabel('epoch')
plt.ylabel('LR')
plt.grid()
plt.xlim(0, epochs)
plt.ylim(0)
plt.savefig(Path(save_dir) / 'LR.png', dpi=200) # 保存
plt.close()
通常用于train.py中学习率设置后可视化一下:
执行效果:

6、hist2d、plot_test_txt、plot_targets_txt
6.1、hist2d
\qquad 这个函数是使用numpy工具画出2d直方图。不过好像用的不多,大多数都是调用工具包封装好的2d直方图方法,所以这个包其实只在plot_evolution函数和plot_test_txt函数中使用。
hist2d函数代码:
def hist2d(x, y, n=100):
"""用在plot_evolution和plot_test_txt
使用numpy画出2d直方图
2d histogram used in labels.png and evolve.png
"""
# xedges: 返回在start=x.min()和stop=x.max()之间返回均匀间隔的n个数据
xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
# np.histogram2d: 2d直方图 x: x轴坐标 y: y轴坐标 (xedges, yedges): bins x, y轴的长条形数目
# 返回hist: 直方图对象 xedges: x轴对象 yedges: y轴对象
hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
# np.clip: 截取函数 令目标内所有数据都属于一个范围 [0, hist.shape[0] - 1] 小于0的等于0 大于同理
# np.digitize 用于分区
xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1) # x轴坐标
yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1) # y轴坐标
return np.log(hist[xidx, yidx])
6.2、plot_test_txt
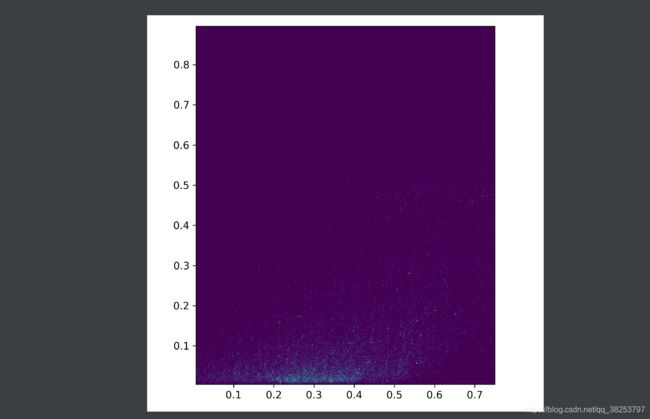
\qquad 这个函数是利用test.py中生成的test.txt文件(或者其他的*.txt文件),画出其xy直方图和xy双直方图。其实这个plot_test_txt这个函数作者并没有使用它,但是我们确实可以自己写一个脚本来执行这个函数,观察一下预测到的所有图像的目标情况(wh分布)。
plot_test_txt函数代码:
def plot_test_txt(test_dir='test.txt'):
"""可以自己写个脚本执行test.txt文件
利用test.txt xyxy画出其直方图和双直方图
Plot test.txt histograms
:params test_dir: test.py中生成的一些 save_dir/labels中的txt文件
"""
# x [:, xyxy]
x = np.loadtxt(test_dir, dtype=np.float32)
box = xyxy2xywh(x[:, 2:6]) # xyxy to xywh 这里我改了下 原来是0:4 但我发现txt中存放的是 cls+conf+xyxy
cx, cy = box[:, 0], box[:, 1] # x y
# 将figure分成1行1列 figure size=(6, 6) tight_layout=true 会自动调整子图参数, 使之填充整个图像区域
# 返回figure(绘图对象)和axes(坐标对象)
fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
# hist2d: 双直方图 cx: x坐标 cy: y坐标 bins: 横竖分为几条 cmax、cmin: 所有的bins的值少于cmin和大于cmax的不显示
ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
ax.set_aspect('equal') # 设置两个轴的长度始终相同 figure为正方形
plt.savefig('hist2d.png', dpi=300)
fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
# hist 正常直方图 cx: 绘图数据 bins: 直方图的长条形数目 normed: 是否将得到的直方图向量归一化
# facecolor: 长条形的颜色 edgecolor:长条形边框的颜色 alpha:透明度
ax[0].hist(cx, bins=600)
ax[1].hist(cy, bins=600)
plt.savefig('hist1d.png', dpi=200)
自己写个脚本使用:

hist1d.png效果(横坐标分别是w和h,纵坐标是个数):

hist2d.png效果(横坐标是x纵坐标是y):
6.3、plot_targets_txt(没用到)
\qquad 这个函数是利用targets.txt(真实框的xywh)画出其直方图。但是并没有使用这个函数,而且细心的可以发现这个函数和之后的plot_labels函数是重复的。所以这个函数就随便看看吧。
plot_targets_txt函数代码:
def plot_targets_txt():
"""没用到 和plot_labels作用重复
利用targets.txt xywh画出其直方图
Plot targets.txt histograms
"""
# x [:, xywh]
x = np.loadtxt('targets.txt', dtype=np.float32).T
s = ['x targets', 'y targets', 'width targets', 'height targets']
fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
ax = ax.ravel() # 将多维数组降位一维
for i in range(4):
ax[i].hist(x[i], bins=100, label='%.3g +/- %.3g' % (x[i].mean(), x[i].std()))
ax[i].legend() # 显示上行label图例
ax[i].set_title(s[i])
plt.savefig('targets.jpg', dpi=200)
7、plot_labels
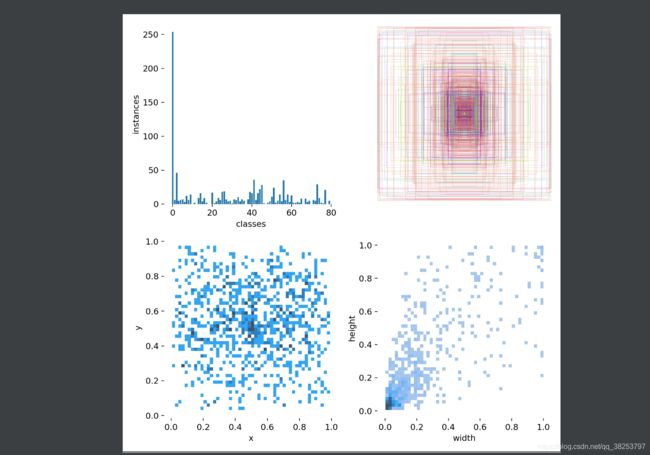
\qquad 这个函数是根据从datasets中取到的labels,分析其类别分布,画出labels相关直方图信息。最终会生成labels_correlogram.jpg和labels.jpg两张图片。labels_correlogram.jpg包含所有标签的 x,y,w,h的多变量联合分布直方图:查看两个或两个以上变量之间两两相互关系的可视化形式(里面包含x、y、w、h两两之间的分布直方图)。而labels.jpg包含了:ax[0]画出classes的各个类的分布直方图,ax[1]画出所有的真实框;ax[2]画出xy直方图;ax[3]画出wh直方图。
plot_labels函数代码:
def plot_labels(labels, names=(), save_dir=Path(''), loggers=None):
"""通常用在train.py中 加载数据datasets和labels后 对labels进行可视化 分析labels信息
plot dataset labels 生成labels_correlogram.jpg和labels.jpg 画出数据集的labels相关直方图信息
:params labels: 数据集的全部真实框标签 (num_targets, class+xywh) (929, 5)
:params names: 数据集的所有类别名
:params save_dir: runs\train\exp21
:params loggers: 日志对象
"""
print('Plotting labels... ')
# c: classes (929) b: boxes xywh (4, 929) .transpose() 将(4, 929) -> (929, 4)
c, b = labels[:, 0], labels[:, 1:].transpose()
nc = int(c.max() + 1) # 类别总数 number of classes 80
# pd.DataFrame: 创建DataFrame, 类似于一种excel, 表头是['x', 'y', 'width', 'height'] 表格数据: b中数据按行依次存储
x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
# 1、画出labels的 xywh 各自联合分布直方图 labels_correlogram.jpg
# seaborn correlogram seaborn.pairplot 多变量联合分布图: 查看两个或两个以上变量之间两两相互关系的可视化形式
# data: 联合分布数据x diag_kind:表示联合分布图中对角线图的类型 kind:表示联合分布图中非对角线图的类型
# corner: True 表示只显示左下侧 因为左下和右上是重复的 plot_kws,diag_kws: 可以接受字典的参数,对图形进行微调
sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200) # 保存labels_correlogram.jpg
plt.close()
# 2、画出classes的各个类的分布直方图ax[0], 画出所有的真实框ax[1], 画出xy直方图ax[2], 画出wh直方图ax[3] labels.jpg
matplotlib.use('svg') # faster
# 将整个figure分成2*2四个区域
ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
# 第一个区域ax[1]画出classes的分布直方图
y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
# [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # update colors bug #3195
ax[0].set_ylabel('instances') # 设置y轴label
if 0 < len(names) < 30: # 小于30个类别就把所有的类别名作为横坐标
ax[0].set_xticks(range(len(names))) # 设置刻度
ax[0].set_xticklabels(names, rotation=90, fontsize=10) # 旋转90度 设置每个刻度标签
else:
ax[0].set_xlabel('classes') # 如果类别数大于30个, 可能就放不下去了, 所以只显示x轴label
# 第三个区域ax[2]画出xy直方图 第四个区域ax[3]画出wh直方图
sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
# 第二个区域ax[1]画出所有的真实框
labels[:, 1:3] = 0.5 # center xy
labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000 # xyxy
img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255) # 初始化一个窗口
for cls, *box in labels[:1000]: # 把所有的框画在img窗口中
ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
ax[1].imshow(img)
ax[1].axis('off') # 不要xy轴
# 去掉上下左右坐标系(去掉上下左右边框)
for a in [0, 1, 2, 3]:
for s in ['top', 'right', 'left', 'bottom']:
ax[a].spines[s].set_visible(False)
plt.savefig(save_dir / 'labels.jpg', dpi=200)
matplotlib.use('Agg')
plt.close()
# 打印日志 loggers
for k, v in loggers.items() or {
}:
if k == 'wandb' and v:
v.log({
"Labels": [v.Image(str(x), caption=x.name) for x in save_dir.glob('*labels*.jpg')]}, commit=False)
这个函数一般会用在train.py的载入数据datasets和labels后,统计分析labels相关分布信息:

labels_correlogram.jpg执行效果:
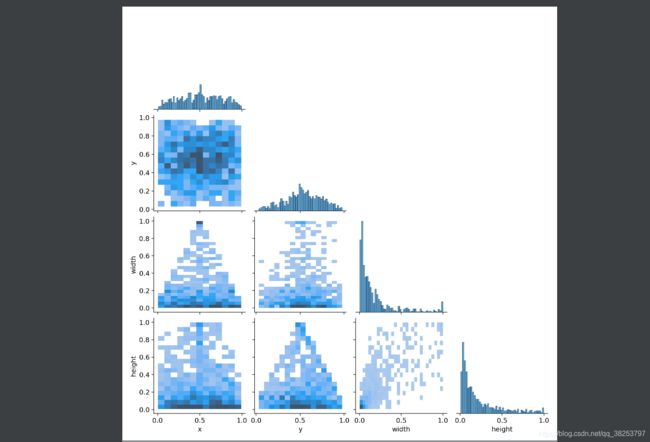
labels.jpg执行效果:
8、plot_evolution
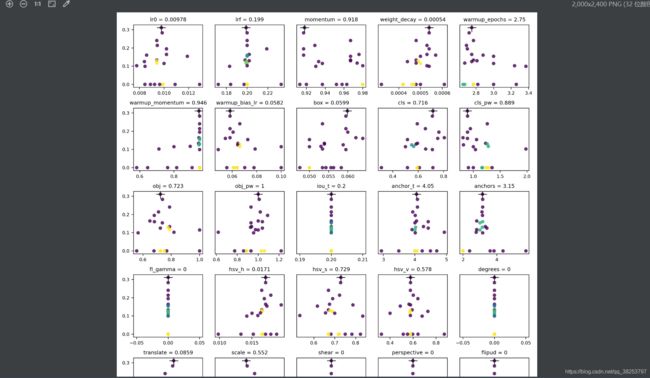
\qquad 这个函数用于超参进化的最后阶段,负责画出每个超参进化的结果。最终会生成evolve.png,里面是每个超参的进化情况以及相对应的mAP的散点图,每5个超参一行,并且会用 ‘+’ 标注好最佳mAP对应的超参值。且每个散点图会输出最佳mAP对应的每个超参的最佳超参。而且plot_evolution也调用了上面的hist2d函数。
plot_evolution函数代码:
def plot_evolution(yaml_file='data/hyp.finetune.yaml', save_dir=Path('')):
"""用在train.py的超参进化算法后,输出参超进化的结果
超参进化在每一轮都会产生一系列的进化后的超参(存在yaml_file) 以及每一轮都会算出当前轮次的7个指标(evolve.txt)
这个函数要做的就是把每个超参在所有轮次变化的值和maps以散点图的形式显示出来,并标出最大的map对应的超参值 一个超参一个散点图
:params yaml_file: 'runs/train/evolve/hyp_evolved.yaml'
"""
with open(yaml_file) as f:
hyp = yaml.safe_load(f) # 导入超参文件
# evolve.txt中每一行为一次进化的结果
# 每行前七个数字(P, R, mAP, F1, test_losses(GIOU, obj, cls)) 之后为hyp
x = np.loadtxt('evolve.txt', ndmin=2)
f = fitness(x) # 得到所有进化轮次后得到的加权形式的map
# weights = (f - f.min()) ** 2 # for weighted results
plt.figure(figsize=(10, 12), tight_layout=True)
matplotlib.rc('font', **{
'size': 8}) # 设置matplotlib参数 font_size: 8
for i, (k, v) in enumerate(hyp.items()):
y = x[:, i + 7] # y=当前超参在每一轮进化后的值
# mu = (y * weights).sum() / weights.sum() # best weighted result
mu = y[f.argmax()] # 得到加权map最大的epoch时的超参(认为这个超参为所有轮次的最佳超参)
plt.subplot(6, 5, i + 1) # 假设有30个参数 6行5列 一个部分画一个图
# 画出每个超参变化的散点图 x: x坐标为当前超参每一轮进化后的值y y: y坐标为所有进化轮次后得到的加权形式的map
# c: 色彩或颜色 cmap: Colormap实例 alpha: edgecolors: 边框颜色
plt.scatter(y, f, c=hist2d(y, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
# 在当前小图上再画出最佳map时对应的超参 大大的 '+' 做记号
plt.plot(mu, f.max(), 'k+', markersize=15)
plt.title('%s = %.3g' % (k, mu), fontdict={
'size': 9}) # limit to 40 characters
if i % 5 != 0: # 一行只能画5个小图
plt.yticks([])
print('%15s: %.3g' % (k, mu)) # 输出最佳超参
plt.savefig(save_dir / 'evolve.png', dpi=200) # 保存evolve.png
print('\nPlot saved as evolve.png')
这个函数通常会用在train.py的超参进化算法后,输出参超进化的结果:

函数执行效果evolve.png:
9、plot_results、plot_results_overlay、butter_lowpass_filtfilt
\qquad 这三个函数都是用来对result.txt中的各项指标进行可视化的,但是plot_results是将一个指标画在折线图上(共10个折线图),而 plot_results_overlay要做的是将原先的10个显示的指标,两个两个进行对比画在同一个折线图上(共5个折线图)。最后的butter_lowpass_filtfilt函数
9.1、plot_results
\qquad 这个函数是将训练后的结果 results.txt 中相关的训练指标画出来。
\qquad result.txt中一行的元素分别有:当前epoch/总epochs-1 、当前的显存容量mem、box回归损失、obj置信度损失、cls分类损失、训练总损失、真实目标数量num_target、图片尺寸img_shape、Precision、Recall、[email protected]、[email protected]:0.95、测试box回归损失、测试obj置信度损、测试cls分类损失。
\qquad 在result.txt中画出的指标有:训练回归损失Box、训练置信度损失Objectness、训练分类损失Classification、Precision、Recall、验证回归损失 val Box、验证置信度损失val Objectness、验证分类损失val Classification、[email protected]、[email protected]:0.95。
plot_results函数代码:
def plot_results(start=0, stop=0, bucket='', id=(), save_dir=''):
"""'用在训练结束, 对训练结果进行可视化
画出训练完的 results.txt Plot training 'results*.txt' 最终生成results.png
:params start: 读取数据的开始epoch 因为result.txt的数据是一个epoch一行的
:params stop: 读取数据的结束epoch
:params bucket: 是否需要从googleapis中下载results*.txt文件
:params id: 需要从googleapis中下载的results + id.txt 默认为空
:params save_dir: 'runs\train\exp22'
"""
# 建造一个figure 分割成2行5列, 由10个小subplots组成
fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
ax = ax.ravel() # 将多维数组降为一维
s = ['Box', 'Objectness', 'Classification', 'Precision', 'Recall',
'val Box', 'val Objectness', 'val Classification', '[email protected]', '[email protected]:0.95'] # titles
if bucket:
# files = ['https://storage.googleapis.com/%s/results%g.txt' % (bucket, x) for x in id]
files = ['results%g.txt' % x for x in id]
c = ('gsutil cp ' + '%s ' * len(files) + '.') % tuple('gs://%s/results%g.txt' % (bucket, x) for x in id) # cmd指令
os.system(c) # 使用cmd指令从googleapis中下载results*.txt
else:
# 不从网盘上下载就直接从文件目录中模糊查找 如files=[WindowsPath('runs/train/exp22/results.txt')]
files = list(Path(save_dir).glob('results*.txt')) # 搜索save_dir目录下类似'results*.txt'文件名的文件
assert len(files), 'No results.txt files found in %s, nothing to plot.' % os.path.abspath(save_dir)
# 读取files文件数据进行可视化
for fi, f in enumerate(files):
try:
# files 原始一行: epoch/epochs - 1, memory, Box, Objectness, Classification, sum_loss, targets.shape[0], img_shape, Precision, Recall, [email protected], [email protected]:0.95, Val Box, Val Objectness, Val Classification
# 只使用[2, 3, 4, 8, 9, 12, 13, 14, 10, 11]列 (10, 1) 分布对应 =>
# [Box, Objectness, Classification, Precision, Recall, Val Box, Val Objectness, Val Classification, [email protected], [email protected]:0.95]
results = np.loadtxt(f, usecols=[2, 3, 4, 8, 9, 12, 13, 14, 10, 11], ndmin=2).T # (10, 1)
n = results.shape[1] # number of rows 1
# 根据start(epoch)和stop(epoch)读取相应的轮次的数据
x = range(start, min(stop, n) if stop else n)
for i in range(10): # 分别可视化这10个指标
y = results[i, x]
if i in [0, 1, 2, 5, 6, 7]:
y[y == 0] = np.nan # loss值不能为0 要显示为np.nan
# y /= y[0] # normalize
# label = labels[fi] if len(labels) else f.stem
ax[i].plot(x, y, marker='.', linewidth=2, markersize=8) # 画子图
# ax[i].plot(x, y, marker='.', label=label, linewidth=2, markersize=8)
ax[i].set_title(s[i]) # 设置子图标题
# if i in [5, 6, 7]: # share train and val loss y axes
# ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
except Exception as e:
print('Warning: Plotting error for %s; %s' % (f, e))
# ax[1].legend()
fig.savefig(Path(save_dir) / 'results1.png', dpi=200) # 保存results.png
这个函数会用在train.py训练结束后对训练结果进行可视化:

执行结果result1.png:

9.2、plot_results_overlay
\qquad 这个函数还是将result.txt文件中的各项指标进行可视化,不过将原先的10个折线图减为5个折线图, train和val两两相对比。
plot_results_overlay函数代码:
def plot_results_overlay(start=0, stop=0):
"""可以用在train.py或者自写一个文件
画出训练完的 results.txt Plot training 'results*.txt' 而且将原先的10个折线图缩减为5个折线图, train和val相对比
Plot training 'results*.txt', overlaying train and val losses
"""
s = ['train', 'train', 'train', 'Precision', '[email protected]', 'val', 'val', 'val', 'Recall', '[email protected]:0.95'] # legends
t = ['Box', 'Objectness', 'Classification', 'P-R', 'mAP-F1'] # titles
# 遍历每个模糊查询匹配到的results*.txt
for f in sorted(glob.glob('results*.txt') + glob.glob('../../Downloads/results*.txt')):
# files 原始一行: epoch/epochs - 1, memory, Box, Objectness, Classification, sum_loss, targets.shape[0], img_shape, Precision, Recall, [email protected], [email protected]:0.95, Val Box, Val Objectness, Val Classification
# 只使用[2, 3, 4, 8, 9, 12, 13, 14, 10, 11]列 (10, 1) 分布对应 =>
# [Box, Objectness, Classification, Precision, Recall, Val Box, Val Objectness, Val Classification, [email protected], [email protected]:0.95]
results = np.loadtxt(f, usecols=[2, 3, 4, 8, 9, 12, 13, 14, 10, 11], ndmin=2).T # (10, 1)
n = results.shape[1] # number of rows 1
# 根据start(epoch)和stop(epoch)读取相应的轮次的数据
x = range(start, min(stop, n) if stop else n)
# 建造一个figure 分割成1行5列, 由5个小subplots组成 [Box, Objectness, Classification, P-R, mAP-F1]
fig, ax = plt.subplots(1, 5, figsize=(14, 3.5), tight_layout=True)
ax = ax.ravel() # 将多维数组降为一维
# 分别可视化这5个指标 [Box, Objectness, Classification, P-R, mAP-F1]
for i in range(5):
for j in [i, i + 5]: # 每个指标都要读取train(i) + val(i+5)两个值
y = results[j, x]
ax[i].plot(x, y, marker='.', label=s[j])
# y_smooth = butter_lowpass_filtfilt(y) # y抖动太大就取一个平滑版本
# ax[i].plot(x, np.gradient(y_smooth), marker='.', label=s[j])
ax[i].set_title(t[i]) # 设置子图标题
ax[i].legend() # 设置子图图例legend
ax[i].set_ylabel(f) if i == 0 else None # add filename
fig.savefig(f.replace('.txt', '.png'), dpi=200) # 保存result.png
这个函数可以放在plot_results下面,也可以自己写一个:

执行结果result.py:

9.3、butter_lowpass_filtfilt
\qquad 这个函数是为了防止在训练时有些指标非常的抖动,导致画出来很难看,比如下面这种情况:
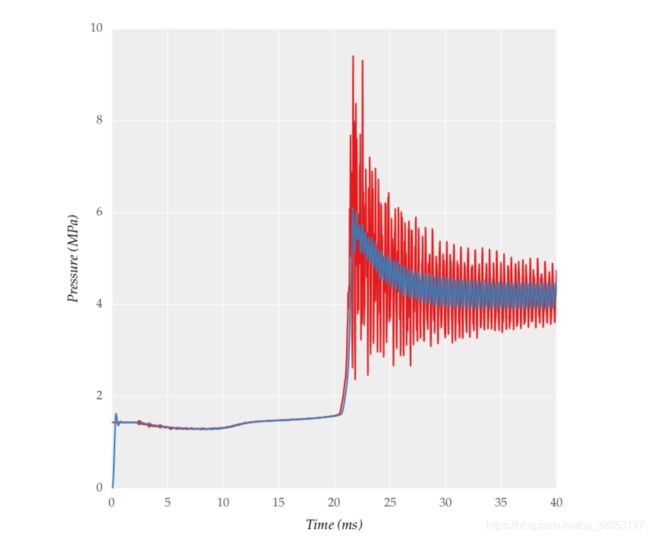
红色部分真实值非常抖动,画出来很难看,那我们就对它进行一个平滑处理,取它的一个近似值。
butter_lowpass_filtfilt函数代码:
def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
"""
当data值抖动太大, 就取data的平滑曲线
"""
from scipy.signal import butter, filtfilt
# https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
def butter_lowpass(cutoff, fs, order):
nyq = 0.5 * fs
normal_cutoff = cutoff / nyq
return butter(order, normal_cutoff, btype='low', analog=False)
b, a = butter_lowpass(cutoff, fs, order=order)
return filtfilt(b, a, data) # forward-backward filter
\qquad 这部分的代码是用在上面plot_results_overlay函数里面的,不过它是注释掉的,如果发现自己训练的结果发生上面的那种抖动情况,大家可以打开注释,或者任意调用这个函数达到一种平滑效果。这个函数代码我是每有看的,感兴趣可以自己读读,就几行应该不难。
10、feature_visualization
\qquad 这个函数是用来可视化feature map的,而且可以实现可视化网络中任意一层的feature map。
函数代码:
def feature_visualization(x, module_type, stage, n=64):
"""用在yolo.py的Model类中的forward_once函数中 自行选择任意层进行可视化该层feature map
可视化feature map(模型任意层都可以用)
:params x: Features map [bs, channels, height, width]
:params module_type: Module type
:params stage: Module stage within model
:params n: Maximum number of feature maps to plot
"""
batch, channels, height, width = x.shape # batch, channels, height, width
if height > 1 and width > 1:
project, name = 'runs/features', 'exp'
save_dir = increment_path(Path(project) / name) # increment run
save_dir.mkdir(parents=True, exist_ok=True) # make save dir
plt.figure(tight_layout=True)
# torch.chunk: 与torch.cat()原理相反 将tensor x按dim(行或列)分割成channels个tensor块, 返回的是一个元组
# 将第2个维度(channels)将x分成channels份 每张图有三个block batch张图 blocks=len(blocks)=3*batch
blocks = torch.chunk(x, channels, dim=1)
n = min(n, len(blocks)) # 总共可视化的feature map数量
for i in range(n):
feature = transforms.ToPILImage()(blocks[i].squeeze()) # tensor -> PIL Image
ax = plt.subplot(int(math.sqrt(n)), int(math.sqrt(n)), i + 1) # 根号n行根号n列 当前属于第i+1张子图
ax.axis('off')
plt.imshow(feature) # cmap='gray' 可视化当前feature map
f = f"stage_{
stage}_{
module_type.split('.')[-1]}_features.png"
print(f'Saving {
save_dir / f}...')
plt.savefig(save_dir / f, dpi=300)
通常这个函数是把他放在yolo.py的Model类中的forward_once函数中:

自己可以在if中选择要查看的任意一层feature map。
原图:
执行效果:

11、plot_study_txt(没用到)、profile_idetection(没用到)
\qquad 剩下的这两个函数是没什么用的,plot_study_txt是test.py中opt.task == 'study’时评估yolov5系列和yolov3-spp各个模型在各个尺度下的指标并可视化,但是其实我们几乎用不到这里。另外一个函数profile_idetection完全没用到。所以这两个函数不看也可以。
def plot_study_txt(path='', x=None):
"""没用到
Plot study.txt generated by test.py
"""
plot2 = False # plot additional results
if plot2:
ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
# for f in [Path(path) / f'study_coco_{x}.txt' for x in ['yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
for f in sorted(Path(path).glob('study*.txt')):
y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
x = np.arange(y.shape[1]) if x is None else np.array(x)
if plot2:
s = ['P', 'R', '[email protected]', '[email protected]:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
for i in range(7):
ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
ax[i].set_title(s[i])
j = y[3].argmax() + 1
ax2.plot(y[5, 1:j], y[3, 1:j] * 1E2, '.-', linewidth=2, markersize=8,
label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
'k.-', linewidth=2, markersize=8, alpha=.25, label='EfficientDet')
ax2.grid(alpha=0.2)
ax2.set_yticks(np.arange(20, 60, 5))
ax2.set_xlim(0, 57)
ax2.set_ylim(30, 55)
ax2.set_xlabel('GPU Speed (ms/img)')
ax2.set_ylabel('COCO AP val')
ax2.legend(loc='lower right')
plt.savefig(str(Path(path).name) + '.png', dpi=300)
def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
"""没用到
Plot iDetection '*.txt' per-image logs
"""
ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
files = list(Path(save_dir).glob('frames*.txt'))
for fi, f in enumerate(files):
try:
results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
n = results.shape[1] # number of rows
x = np.arange(start, min(stop, n) if stop else n)
results = results[:, x]
t = (results[0] - results[0].min()) # set t0=0s
results[0] = x
for i, a in enumerate(ax):
if i < len(results):
label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
a.set_title(s[i])
a.set_xlabel('time (s)')
# if fi == len(files) - 1:
# a.set_ylim(bottom=0)
for side in ['top', 'right']:
a.spines[side].set_visible(False)
else:
a.remove()
except Exception as e:
print('Warning: Plotting error for %s; %s' % (f, e))
ax[1].legend()
plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
总结
\qquad 这个文件的代码主要是一些画图用的工具函数,和我们目标检测的主要流程其实没用什么关系。比较重要的函数有:plot_one_box、output_to_target、plot_images、plot_labels、plot_evolution、plot_results、plot_results_overlay、feature_visualization等。
–2021.08.02 22:14