r语言中which的使用_R语言中K邻近算法的初学者指南:从菜鸟到大神(附代码&链接)...

作者:Leihua Ye, UC Santa Barbara
翻译:陈超
校对:冯羽
本文约2300字,建议阅读10分钟
本文介绍了一种针对初学者的K临近算法在R语言中的实现方法。
本文呈现了一种在R语言中建立起KNN模型的方式,其中包含了多种测量指标。

Mathyas Kurmann拍摄,来自于Unsplash
“如果你有5分钟时间可以离开比尔·盖茨生活,我敢打赌你很富有。”
背景
在机器学习的世界里,我发现K邻近算法(KNN)分类器是最直观、最容易上手的,甚至不需要引入任何数学符号。
为了决定观测样本的标签,我们观察它的邻近样本们并把邻近样本们的标签贴给感兴趣的观测样本。当然,观察一个邻近样本可能会产生偏差和错误,KNN方法就制定了一系列的规则和流程来决定最优化的邻近样本数量,比如,检验k>1的邻近样本并且采纳取大多数的规则来决定分类。
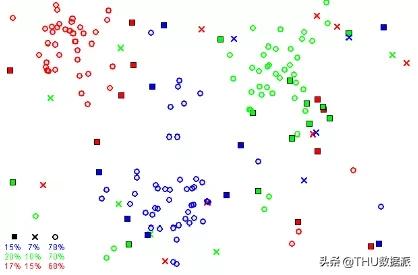
“为了决定新观测样本的标签,我们就看最邻近样本。”
距离度量
为了选择最邻近的样本,我们必须定义距离的大小。对于类别数据,有汉明距离和编辑距离。详情请见
https://en.m.wikipedia.org/wiki/Knearest_neighbors_algorithm
,本文将不会过多讨论数学问题。
什么是K折交叉验证?
在机器学习当中,交叉验证(CV)在模型选择中起着关键作用,并且拥有一系列的应用。事实上,CV有着更加直观的设计理念,并且也很直观。
简要介绍如下:
1. 将数据分成K个均匀分布的块/层
2. 选择一个块/层集作为测试集,剩下的K-1块/层作为训练集
3. 基于训练集建立ML模型
4. 仅比较测试集当中的预测值和真实值
5. 将ML模型应用到测试集,并使用每个块重复测试K次
6. 把模型的度量得分加和并求K层的平均值
如何选择K?
如同你注意到的,交叉验证比较的一点是如何为K设置值。我们记总样本量为n。从技术上来看,K可设置从1到n的任意值。
如果k=n,我们取出1个观测值作为训练集并把剩余的n-1个值作为测试集。然后在整个数据集中重复这个过程。这就叫做“留一交叉验证法” (LOOCV)。
留一交叉验证法要求较大的计算力,并且如果你的数据集过大,该法可能会无法终止。
退一步来讲,即使没有最优k值,也不能说k值越大更好。
为了选择最合适的k值,我们必须在偏差和方差之间权衡。如果k很小,我们在估计测试误差时会获得较大的偏差但方差会较小;如果k值比较大,我们的偏差会较小,方差会较大。

Jon Tyson拍摄,来自于Unsplash
“你好邻居!快进来吧。”
R语言实现
1. 软件准备
# install.packages(“ISLR”)
# install.packages(“ggplot2”) # install.packages(“plyr”)
# install.packages(“dplyr”) # install.packages(“class”)# Load libraries
library(ISLR)
library(ggplot2)
library(reshape2)
library(plyr)
library(dplyr)
library(class)# load data and clean the dataset
banking=read.csv(“bank-additional-full.csv”,sep=”;”,header=T)##check for missing data and make sure no missing data
banking[!complete.cases(banking),]#re-code qualitative (factor) variables into numeric
banking$job=recode(banking$job,“‘admin.’=1;’blue-collar’=2;’entrepreneur’=3;’
housemaid’=4;’management’=5;’retired’=6;’self-employed’=7;’services’=8;
’student’=9;’technician’=10;’unemployed’=11;’unknown’=12”)#recode variable again
banking$marital=recode(banking$marital,“‘divorced’=1;’married’=2;’single’=3;’unknown’=4”)
banking$education=recode(banking$education,“‘basic.4y’=1;’basic.6y’=2;’basic.9y’=3;’high.school’=4;’illiterate’=5;’professional.course’=6;’university.degree’=7;’unknown’=8”)
banking$default = recode(banking$default, “‘no’=1;’yes’=2;’unknown’=3”)
banking$housing = recode(banking$housing, “‘no’=1;’yes’=2;’unknown’=3”)
banking$loan=recode(banking$loan,“‘no’=1;’yes’=2;’unknown’=3”)banking$contact=recode(banking$loan,“‘cellular’=1;’telephone’=2;”)
banking$month=recode(banking$month,“‘mar’=1;’apr’=2;’may’=3;’jun’=4;’jul’=5;’aug’=6;’sep’=7;’oct’=8;’nov’=9;’dec’=10”)
banking$day_of_week=recode(banking$day_of_week,“‘mon’=1;’tue’=2;’wed’=3;’thu’=4;’fri’=5;”)
banking$poutcome = recode(banking$poutcome,“‘failure’=1;’nonexistent’=2;’success’=3;”)#remove variable “pdays”, b/c it has no variation
banking$pdays=NULL #remove variable “duration”, b/c itis collinear with the DV
banking$duration=NULL
在加载并清空初始数据集之后,通常的做法是将变量的分布可视化,检查季节性,模式,异常值,等等。
#EDA of the DV
plot(banking$y,main="Plot 1: Distribution of Dependent Variable")
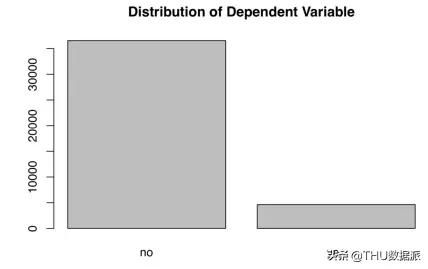
如图所示,结果变量(银行服务订阅)并不满足均匀分布,“否”比“是”多得多。
当我们尽力想正确分类标签的时候,监督学习是不太方便的。正如意料之中,如果大量的少数案例被分类为多数标签,假阳性的比率会变高。
事实上,不均匀分布可能会更偏好非参数ML分类器,在我的另一篇文章(使用5个分类器对罕见事件进行分类,https://medium.com/m/global-identity?
redirectUrl=https%3A%2F%2Ftowardsdatascience.com%2Fclassifying-rare-events-using-five-machine-learning-techniques-fab464573233)中介绍了KNN在与其他ML方法进行比较之后表现得更好。这个可能是参数和非参数模型中潜在的数学和统计假设导致的。
2. 数据分组
如上所述,我们需要将数据集进行分组,分为训练集和测试集,并采取k层交叉验证来选择最佳的ML模型。根据经验法则,我们通常使用“80-20”比:我们用80%的数据训练ML用剩余20%进行测试。而时间序列数据略有不同,我们将比例改为90%对10%。
#split the dataset into training and test sets randomly, but we need to set seed so as to generate the same value each time we run the codeset.seed(1)#create an index to split the data: 80% training and 20% test
index = round(nrow(banking)*0.2,digits=0)#sample randomly throughout the dataset and keep the total number equal to the value of index
test.indices = sample(1:nrow(banking), index)#80% training set
banking.train=banking[-test.indices,] #20% test set
banking.test=banking[test.indices,] #Select the training set except the DV
YTrain = banking.train$y
XTrain = banking.train %>% select(-y)# Select the test set except the DV
YTest = banking.test$y
XTest = banking.test %>% select(-y)
到目前为止,我们已经完成了数据准备并开始模型选择。
3. 训练模型
让我们编写一个新的函数(“calc_error_rate”)来记录错误分类率。该函数计算当使用训练集得到的预测标签与真正的结果标签不相匹配的比率。它测量了分类的正确性。
#define an error rate function and apply it to obtain test/training errorscalc_error_rate
return(mean(true.value!=predicted.value))
}
然后,我们需要另外一个函数“do.chunk()”来做k层交叉验证。该函数返回层的可能值的数据框。这一步的主要目的是为KNN选择最佳的K值。
nfold = 10
set.seed(1)# cut() divides the range into several intervals
folds = seq.int(nrow(banking.train)) %>%
cut(breaks = nfold, labels=FALSE) %>%
sampledo.chunk
train = (folddef!=chunkid)# training indexXtr = Xdat[train,] # training set by the indexYtr = Ydat[train] # true label in training setXvl = Xdat[!train,] # test setYvl = Ydat[!train] # true label in test setpredYtr = knn(train = Xtr, test = Xtr, cl = Ytr, k = k) # predict training labelspredYvl = knn(train = Xtr, test = Xvl, cl = Ytr, k = k) # predict test labelsdata.frame(fold =chunkid, # k folds
train.error = calc_error_rate(predYtr, Ytr),#training error per fold
val.error = calc_error_rate(predYvl, Yvl)) # test error per fold
}# set error.folds to save validation errors
error.folds=NULL# create a sequence of data with an interval of 10
kvec = c(1, seq(10, 50, length.out=5))set.seed(1)for (j in kvec){
tmp = ldply(1:nfold, do.chunk, # apply do.function to each fold
folddef=folds, Xdat=XTrain, Ydat=YTrain, k=j) # required arguments
tmp$neighbors = j # track each value of neighbors
error.folds = rbind(error.folds, tmp) # combine the results
}#melt() in the package reshape2 melts wide-format data into long-format data
errors = melt(error.folds, id.vars=c(“fold”,”neighbors”), value.name= “error”)
接下来的一步是为了找到使得验证错误最小化的k值。
val.error.means = errors %>%
#select all rows of validation errors
filter(variable== “val.error” ) %>%
#group the selected data by neighbors
group_by(neighbors, variable) %>%
#cacluate CV error for each k
summarise_each(funs(mean), error) %>%
#remove existing grouping
ungroup() %>%
filter(error==min(error))#the best number of neighbors
numneighbor = max(val.error.means$neighbors)
numneighbor## [20]
在使用10层交叉验证之后,最优的邻近值数为20。

Nick Youngson
4. 一些模型的度量
#training error
set.seed(20)
pred.YTtrain = knn(train=XTrain, test=XTrain, cl=YTrain, k=20)
knn_traing_error
knn_traing_error
[1] 0.101214
训练误差为0.1。
#test error
set.seed(20)
pred.YTest = knn(train=XTrain, test=XTest, cl=YTrain, k=20)
knn_test_error
knn_test_error
[1] 0.1100995
测试误差为0.11。
#confusion matrixconf.matrix = table(predicted=pred.YTest, true=YTest)

基于以上的混淆矩阵(confusion matrix),我们可以计算以下的值并且准备好画出ROC曲线。
Accuracy = (TP +TN)/(TP+FP+FN+TN)
TPR/Recall/Sensitivity = TP/(TP+FN)
Precision = TP/(TP+FP)
Specificity = TN/(TN+FP)
FPR = 1 — Specificity = FP/(TN+FP)
F1 Score = 2*TP/(2*TP+FP+FN) = Precision*Recall /(Precision +Recall)
# Test accuracy ratesum(diag(conf.matrix)/sum(conf.matrix))[1] 0.8899005# Test error rate1 - sum(drag(conf.matrix)/sum(conf.matrix))[1] 0.1100995
你可能会注意到,测试正确率+测试错误率=1,我也提供了多种方法来计算每个值。
# ROC and AUC
knn_model = knn(train=XTrain, test=XTrain, cl=YTrain, k=20,prob=TRUE)prob
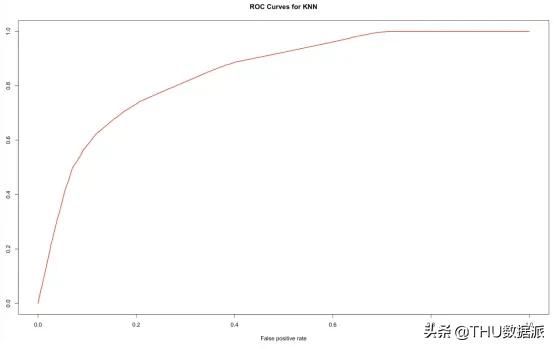
综上所述,我们学习了什么是KNN并且在R语言当中建立了KNN模型。更重要的是,我们已经学到了K层交叉验证法背后的机制以及如何在R语言中实现交叉验证。
作者简介:
雷华·叶(@leihua_ye)是加州大学圣巴巴拉分校的博士生。他在定量用户体验研究、实验与因果推理、机器学习和数据科学方面有5年以上的研究和专业经验。
原文标题:
Beginner’s Guide to K-Nearest Neighbors in R: from Zero to Hero
原文链接:
https://www.kdnuggets.com/2020/01/beginners-guide-nearest-neighbors-r.html
编辑:于腾凯
校对:谭佳瑶
译者简介

陈超,北京大学应用心理硕士在读。本科曾混迹于计算机专业,后又在心理学的道路上不懈求索。越来越发现数据分析和编程已然成为了两门必修的生存技能,因此在日常生活中尽一切努力更好地去接触和了解相关知识,但前路漫漫,我仍在路上。
—完—
关注清华-青岛数据科学研究院官方微信公众平台“ THU数据派 ”及姊妹号“ 数据派THU ”获取更多讲座福利及优质内容。