【Kaggle入门练习赛】数字识别_续
首先,参考了kaggle上点赞数最高的那个kernelhttps://www.kaggle.com/yassineghouzam/introduction-to-cnn-keras-0-997-top-6,比起前一版的代码主要做了三个改动。
1.数据增强:通过对原始数据加噪获得更多的训练集
2.学习率退火:每3代若精确率没有提升,则学习率减半
3.BatchNormalization:对数据进行中心化,由于CNN层内似乎自己包括这个功能,因此分别在全连接层的前后加入中心化层
修改后得分0.99528
# -*- coding: utf-8 -*-
"""
Created on Mon Feb 18 16:30:46 2019
@author: xuefei
"""
#导入相关的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import seaborn as sns
import time
#%matplotlib inline
#固定随机数
np.random.seed(2)
from sklearn.model_selection import train_test_split
#confusion_matrix用来表示预测精度的矩阵,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别 ,所以我们希望它对角线的数据尽可能地大
from sklearn.metrics import confusion_matrix
#迭代器
import itertools
#转换为独热码
from keras.utils.np_utils import to_categorical
#序列基操
from keras.models import Sequential
#各种层
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPool2D, BatchNormalization
#RMSprop优化算法,改进了梯度下降法
from keras.optimizers import RMSprop
#数据增强的函数,图片生成器,可以批量生成数据,防止模型过拟合并提高泛化能力
from keras.preprocessing.image import ImageDataGenerator
#学习率调整,提供了一些基于训练过程中的某些测量值对学习率进行动态的下降
#当指标停止改进时降低学习率
from keras.callbacks import ReduceLROnPlateau
time_begin = time.clock()
#######################################准备数据######################################
train = pd.read_csv("D:\\学习\\研一上\\数据挖掘\\kaggle入门\\练习赛\\手写数字识别\\train.csv",engine='python')
test = pd.read_csv("D:\\学习\\研一上\\数据挖掘\\kaggle入门\\练习赛\\手写数字识别\\test.csv",engine='python')
#分离标签和特征
Y_train = train['label']
X_train = train.drop(labels = ['label'],axis = 1)
#X_train[X_train != 0] = 1
#test[test != 0] = 1
del train
#看一下标签的分布
g = sns.countplot(Y_train)
Y_train.value_counts()
#嗯,分布都差不多
#查看数据缺失情况
X_train.isnull().any().describe()
#没有缺失
#正则化:就归一化
X_train = X_train / 255
test = test / 255
#按照神经网络要求的输入归一化,行数(也就是样本个数)不变,列按照28*28这样的像素点划分
X_train = X_train.values.reshape(-1,28,28,1)
test = test.values.reshape(-1,28,28,1)
#标签编码
#把标签编成独热码,做分类而不是回归,返回是一个十维的向量
Y_train = to_categorical(Y_train,num_classes = 10)
#分开训练集和验证集
#这里有一个坑,小心使用一些不平衡的数据集,简单的随机拆分可能会导致验证过程中的评估不准确,stratify = True可以用来防止这个问题
random_seed = 2
#X_train,X_val,Y_train,Y_val = train_test_split(X_train,Y_train,test_size = 0.1,random_state = random_seed)
X_train,X_val,Y_train,Y_val = train_test_split(X_train,Y_train,test_size = 0.1,random_state = random_seed,stratify = Y_train)
#看一个样本
g = plt.imshow(X_train[0][:,:,0])
#搭建网络
model = Sequential()
#卷积层,32个卷积核,每个卷积核的大小是5*5
model.add(Conv2D(filters = 32,kernel_size = (5,5),padding = 'Same',activation = 'relu',input_shape = (28,28,1)))
model.add(Conv2D(filters = 32,kernel_size = (5,5),padding = 'Same',activation = 'relu'))
#池化层
model.add(MaxPool2D(pool_size = (2,2)))
#Dropout,我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征
model.add(Dropout(0.25))
#卷积层
model.add(Conv2D(filters = 64,kernel_size = (3,3),padding = 'Same',activation = 'relu'))
model.add(Conv2D(filters = 64,kernel_size = (3,3),padding = 'Same',activation = 'relu'))
#池化层
model.add(MaxPool2D(pool_size = (2,2)))
model.add(Dropout(0.25))
model.add(BatchNormalization())
#平坦化从而在后面进行全连接
model.add(Flatten())
#256是本层的输出个数,relu是选择优先度最高的激活函数
model.add(Dense(256,activation = 'relu'))
model.add(BatchNormalization())
#防过拟合一下
model.add(Dropout(0.5))
#10维的输出,因为阿拉伯数字一共有10个,softmax是输出层的首选
model.add(Dense(10,activation = 'softmax'))
#选择优化器和退火器
#优化器及其参数的选择https://blog.csdn.net/g11d111/article/details/76639460
optimizer = RMSprop(lr = 0.001,rho = 0.9,epsilon = 1e-08,decay = 0.0)
#编译模型
#损失函数的选取似乎没有一概而论的结论,需要猜,大概也可以看看这个https://blog.csdn.net/u012193416/article/details/79520862
model.compile(optimizer,loss = 'categorical_crossentropy',metrics = ['accuracy'])
#如果在3个时期之后精度没有提高,则LR减半,这里设置的参数都是很广泛很通用的
learning_rate_reduction = ReduceLROnPlateau(monitor = 'val_acc',
#等待3代
patience = 3,
#显示输出
verbose = 1,
#三代不变就把学习率变成原来的0.5倍
factor = 0.5,
#最小的学习率是0.00001
min_lr = 0.00001
)
#迭代30次
epochs = 30
#调整时可以以32为一个单位来进行改变
batch_size = 86
#数据加强:通过对数据进行轻量级的变换来获得更多的训练样本,可以有效地防止过拟合
datagen = ImageDataGenerator(
#输入数据去中心化(按列,也就是按特征)
featurewise_center=False,
#输入数据去中心化(按行,也就是按单个样本)
samplewise_center=False,
#标准化
featurewise_std_normalization=False,
#标准化
samplewise_std_normalization=False,
#白化
zca_whitening=False,
#随机转动图片的角度,0到180
rotation_range=10,
#随机缩放的幅度
zoom_range = 0.1,
#水平随机最大偏移
width_shift_range=0.1,
#竖直随机最大偏移
height_shift_range=0.1,
#是否随机水平翻转,这个参数适用于水平翻转不影响图片语义的时候
horizontal_flip=False,
#是否随机竖直翻转
vertical_flip=False
)
datagen.fit(X_train)
#综合以上设置的所有参数,给出模型
# Fit the model
history = model.fit_generator(#生成器或Sequence的实例
datagen.flow(X_train,Y_train, batch_size=batch_size),
#迭代次数
epochs = epochs,
#评估指标
validation_data = (X_val,Y_val),
#verbose 0 =无声,1 =进度条,2 =每代一行。
verbose = 1,
#每代的个数,这里把所有的样本分成了86份(如果是model.fit的话用batch_size=batch_size是否是相同的?)
steps_per_epoch=X_train.shape[0] // batch_size,
#batch_size=batch_size,
#回调函数
callbacks=[learning_rate_reduction])
#模型评估
fig,ax = plt.subplots(2,1)
ax[0].plot(history.history['loss'],color = 'b',label = 'Training loss')
ax[0].plot(history.history['val_loss'], color='r', label="validation loss",axes =ax[0])
legend = ax[0].legend(loc='best', shadow=True)
ax[1].plot(history.history['acc'], color='b', label="Training accuracy")
ax[1].plot(history.history['val_acc'], color='r',label="Validation accuracy")
legend = ax[1].legend(loc='best', shadow=True)
#从输出验证准确度和测试准确度的关系可以看到我们没有过拟合
#查看混淆矩阵:找出模型的短板
#这个作图函数我们就当它已经封装好了
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# Predict the values from the validation dataset
Y_pred = model.predict(X_val)
# Convert predictions classes to one hot vectors
Y_pred_classes = np.argmax(Y_pred,axis = 1)
# Convert validation observations to one hot vectors
Y_true = np.argmax(Y_val,axis = 1)
# compute the confusion matrix
confusion_mtx = confusion_matrix(Y_true, Y_pred_classes)
# plot the confusion matrix
plot_confusion_matrix(confusion_mtx, classes = range(10))
errors = (Y_pred_classes - Y_true != 0)
Y_pred_classes_errors = Y_pred_classes[errors]
Y_pred_errors = Y_pred[errors]
Y_true_errors = Y_true[errors]
X_val_errors = X_val[errors]
def display_errors(errors_index,img_errors,pred_errors, obs_errors):
""" This function shows 6 images with their predicted and real labels"""
n = 0
nrows = 2
ncols = 3
fig, ax = plt.subplots(nrows,ncols,sharex=True,sharey=True)
for row in range(nrows):
for col in range(ncols):
error = errors_index[n]
ax[row,col].imshow((img_errors[error]).reshape((28,28)))
ax[row,col].set_title("Predicted label :{}\nTrue label :{}".format(pred_errors[error],obs_errors[error]))
n += 1
# Probabilities of the wrong predicted numbers
Y_pred_errors_prob = np.max(Y_pred_errors,axis = 1)
# Predicted probabilities of the true values in the error set
true_prob_errors = np.diagonal(np.take(Y_pred_errors, Y_true_errors, axis=1))
# Difference between the probability of the predicted label and the true label
delta_pred_true_errors = Y_pred_errors_prob - true_prob_errors
# Sorted list of the delta prob errors
sorted_dela_errors = np.argsort(delta_pred_true_errors)
# Top 6 errors
most_important_errors = sorted_dela_errors[-6:]
# Show the top 6 errors
display_errors(most_important_errors, X_val_errors, Y_pred_classes_errors, Y_true_errors)
#从结果来看我觉得这不是我网络的错,因为我自己都觉得那些被分错的图片长得不太正常
#预测做结论
# predict results
results = model.predict(test)
# select the indix with the maximum probability
results = np.argmax(results,axis = 1)
results = pd.Series(results,name="Label")
submission = pd.concat([pd.Series(range(1,28001),name = "ImageId"),results],axis = 1)
submission.to_csv("D:\\学习\\研一上\\数据挖掘\\kaggle入门\\练习赛\\手写数字识别\\cnn_mnist_datagen.csv",index=False)
time_end = time.clock()
print(time_end - time_begin)
下面的问题是如何进一步提高网络性能。我按照排名查看了Leaderboard上分享了kernel的几位大佬。其中一位兄台https://www.kaggle.com/couronne/drop-the-dropout,他的网络是这样的:

这不是我等凡人可以触及的领域,溜了溜了。
另一位兄台https://www.kaggle.com/cdeotte/25-million-images-0-99757-mnist的网络和大家的都差不多,但是他总共训练了30遍网络,其中包括15个使用了退火算法的和15个没有使用退火算法的,每次训练都重新用sklearn那个包生成训练集和验证集,最后综合这30遍的结果进行预测。想法很令人佩服,结果也很好,但是我的设备应对不了那么大规模的运算,所以也没有考虑。
贡献了kernel的排名第一的这位兄台https://www.kaggle.com/genesis16/digit-recogniser-using-cnn-in-keras-top-3的网络看起来平平无奇

难道是其中某个参数设置的特别巧妙?我仔细阅读了他的代码,发现玄机在这里。
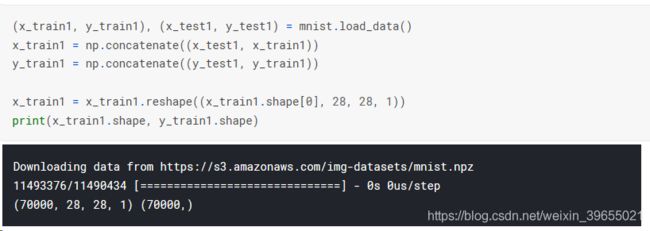
这位大佬下载了来自sklearn的官方minsit数据包,也就是说他的训练集比别人多出三倍以上,训练结果自然直冲云霄。话说回来,我们做数据增强不就是为了获得更多的训练集吗?这种做法比较tricky,且可能的问题是kaggle用来测试的数据已经包括在我们下载的训练集里了,但是无疑能想到这个思路就是卓越,人家获得了很好的成绩。
为了测试一下,我在前面粘贴的代码里也扩充了一下数据集,网络结构和参数没有做任何修改,程序运行时间增加成了原来的差不多2倍,得分0.998,排名直接杀进前3%,这些分享kernel的大佬真的牛逼……
P.S. 原文作者说他跑了2个半小时,但是我只跑了4分钟。有一个性能不错的显卡真好。